倒排索引是什么?为什么 es、hbase、doris、starrocks 都有倒排索引?
倒排索引(英文:Inverted Index),是一种索引方法,常被用于全文检索系统中的一种单词文档映射结构。现代搜索引擎绝大多数的索引都是基于倒排索引来进行构建的,这源于在实际应用当中,用户在使用搜索引擎查找信息时往往只输入信息中的某个属性关键字,如一些用户不记得歌名,会输入歌词来查找歌名;输入某个节目内容片段来查找该节目等等。面对海量的信息数据,为满足用户需求,顺应信息时代快速获取信息的趋势,聪明的开发者们在进行搜索引擎开发时对这些信息数据进行逆向运算,研发了 “关键词——文档” 形式的一种映射结构,实现了通过了物品属性信息对物品进行映射,可以帮助用户快速定位到目标信息,极大地降低了信息获取难度。倒排索引又叫反向索引,它是一种逆向思维运算,是现代信息检索领域里面最有效的一种索引结构。
倒排表:posting list : int 有序数组,存储匹配某个 item 的所有的 id,使用 roaring bitmaps,frame of reference 压缩算法,具体算法可以自行百度,
倒排索引 词项字典 term dictionary :
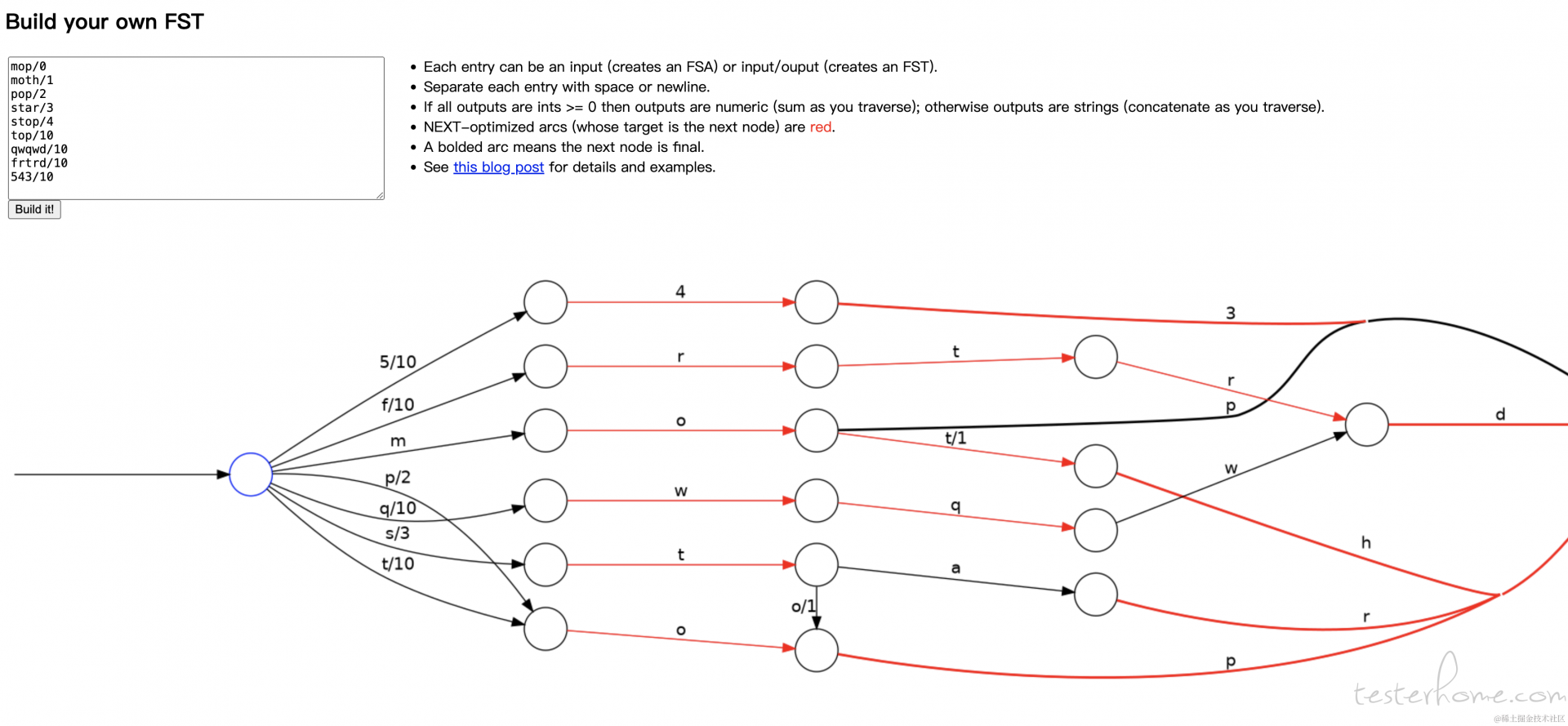
词项索引 term index : 极大的节约内存,使用 fst 压缩算法,最大可达 20 倍,,性能不如 hashmap,但也很不错
使用 fst 算法将词项字段和词项索引存储在内存中,由于压缩倍率大,十亿个词项字典进行 fst 解析之后,存储在内存中也就 1G 大小,fst 是如何将词项字典和词项索引进行映射的呢? 由于所有英文,或者中文进行解析之后,最终都是有 26 个英文字母对应,由于 fst 算法能复用后缀和前缀,因此极大节约了结构树的长度,使得最终存储在内存中,相比普通 tree 存储节省了内存。下图所示:
