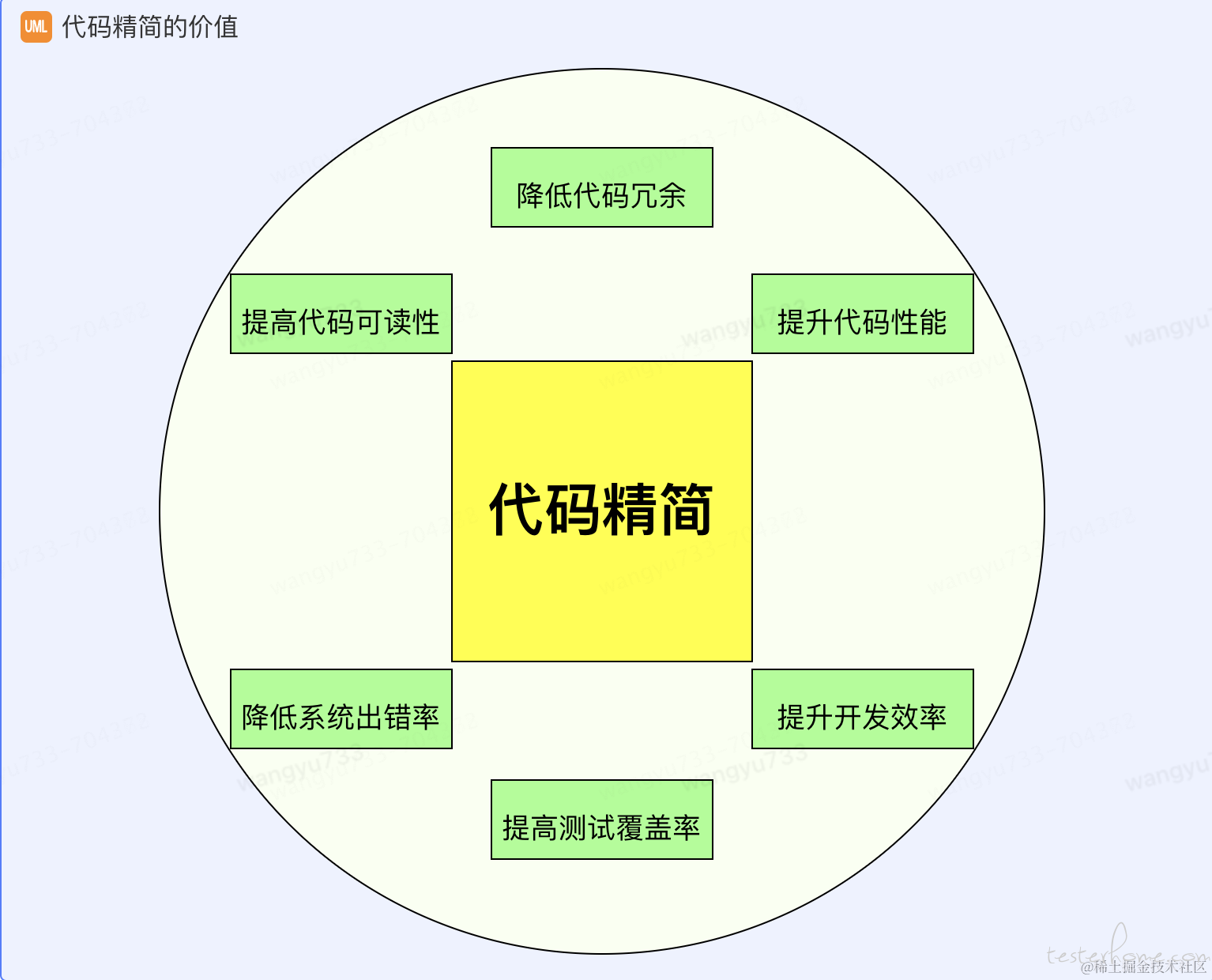
在大型软件系统中,随着业务的发展和变迁,部分代码线上已经废弃或者出现冗余,由于种种原因没有被及时删除和治理,随之而来的是代码维护成本提升。
代码精简的价值如上图所示,并由此成为服务治理的一个重要方向,在业界头部企业也有对应的治理项目谷歌【死神】项目,用机器人大规模删除代码:二十多年积累了数十亿行,已删除 5%C++ 代码, 其主要思路是通过程序自动识别代码否正在运行,并将识别结果和原因提交给工程师处理。
•无引用的变量、代码块、方法、类
•被注释的代码
•无流量的僵尸代码:已下线的功能、已被重构的历史代码等
•存量代码治理:采用关停并转(应用维度或者功能模块维度)、使用动态观测工具和静态分析工具识别无效代码和重复代码、代码重构等多个手段进行组合治理
•增量代码治理:利用 jacoco+ 集成测试,识别增量代码的无效部分,随着集成测试 case 越来越丰富也可以辅助用来做存量代码治理与保障系统稳定性。superJacoco 就是这种方案的代表产物,其背景是在实际项目测试过程中,case 的设计经常会出现以下问题:
1.开发同学写了大量单测,一直重复执行一段代码逻辑,少数场景或异常代码逻辑并未执行到;
2.测试同学设计的测试用例经过反复评审,仍然有未覆盖到的异常场景,出现漏测情况;
3.接口自动化测试 case 作为日常回归手段,无法确定是否覆盖所有代码逻辑,其可靠性无法评估。
基于团队现状,应用集成 jacoco 并结合集成测试,可一举多得:
•沉淀的集成测试项目可用于后续保障应用稳定性
•集成测试单独触发的 jacoco 快照,可用于针对性的解决代码精简的范围
•检验测试用例的覆盖范围
单元测试是白盒测试,测试团队的自动化测试(系统测试)属于黑盒测试,集成测试介于两者之间属于灰盒测试。集成测试是保障服务稳定性的重要手段,最佳路径是 TDD,需要建设对应的团队文化和工作流程。
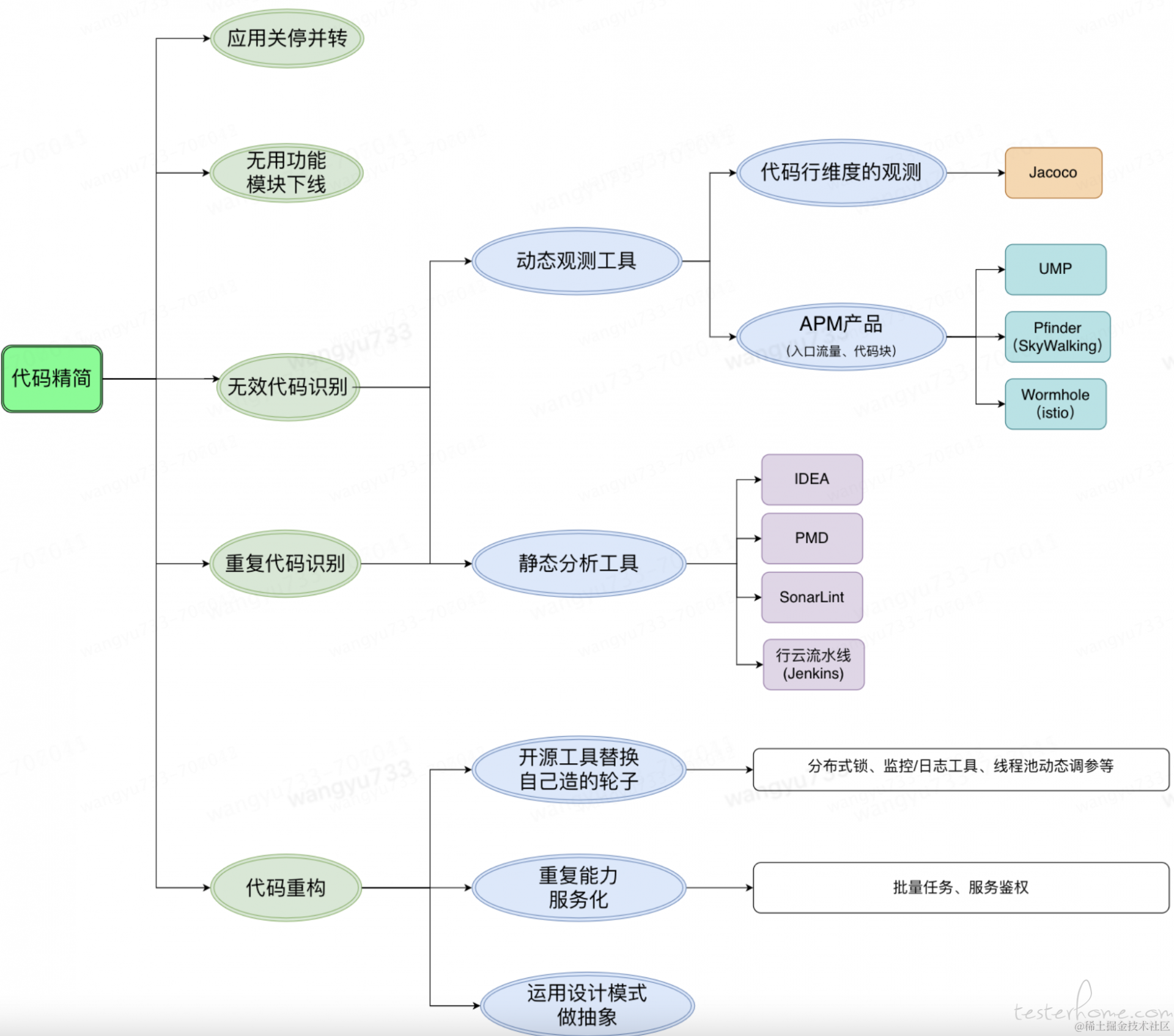
笔者总结了如下 5 种方案用于代码精简的生产实践:
•利用 jacoco 观测线上代码覆盖情况
•APM 产品观测代码块执行情况, UMP(京东内部自研传统报警监控系统)+Pfinder(京东内部自研全链路追踪产品,同 SkyWalking)
•利用静态代码扫描识别无引用的变量、代码块、方法、类
•jacoco + APM 产品组合观测线上流量 + 静态代码扫描
•集成测试 + jacoco 实现精准测试
长期来看,无效代码/重复代码识别可以往平台化/自动化的方向发展:
•平台化: 无侵入的收集代码覆盖率数据,和环境无缝对接,收集自定义时间段代码全量/增量覆盖率,并提供可视化报表,以及支撑精准测试落地。比如:Sonar(静态)、SuperJacoco
•自动化: 将冗余代码识别整合到 CI/CD 流程中,设置相应的审核/卡点机制。此环节比较出名的工具有:jenkins、hudson 等,我们可以自定义行云流水线,和流水线原子来落地
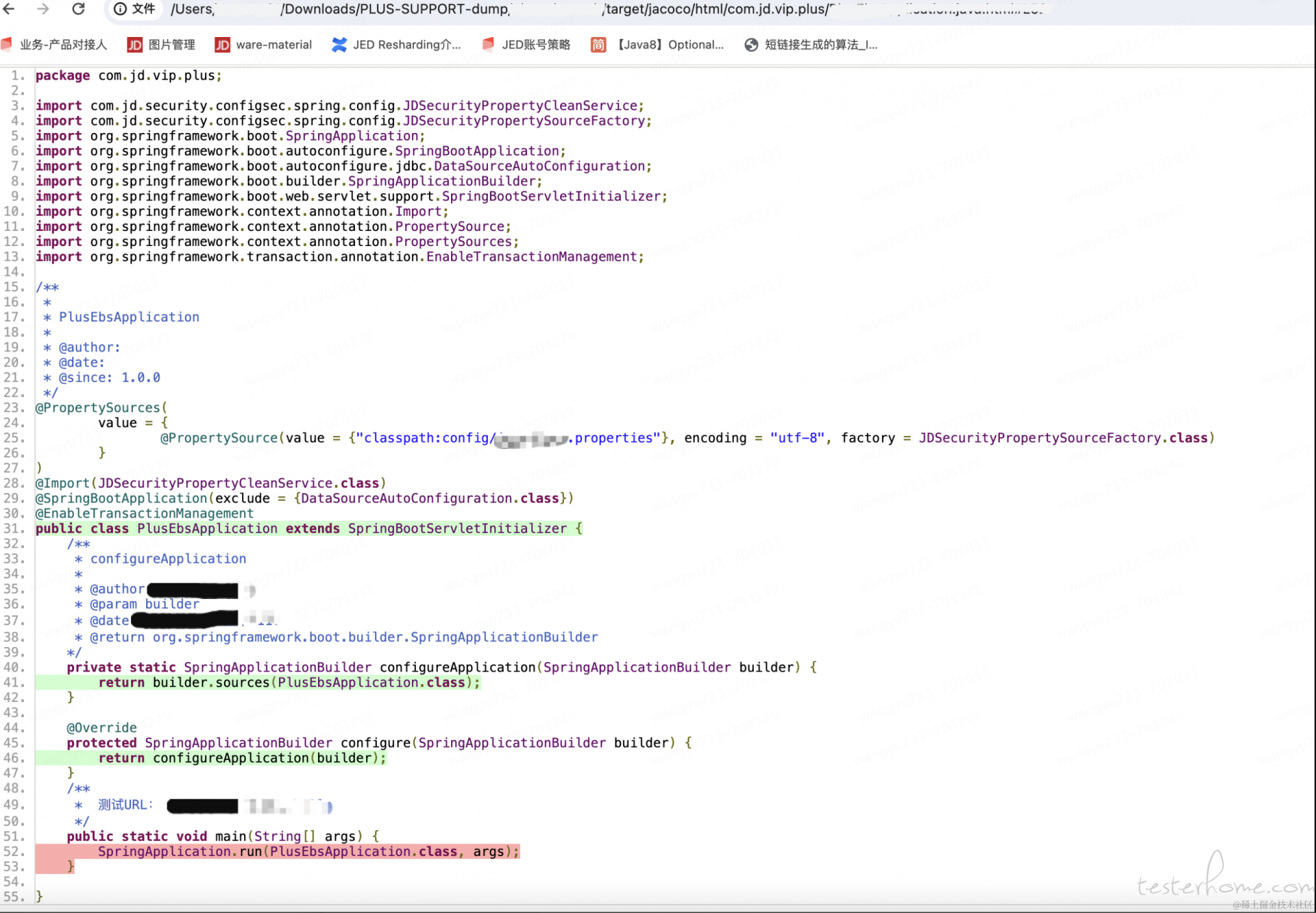
通过 JavaAgent 方式无侵入的接入 Jacoco,可监控到代码级别是否被执行的情况。参考资料 JaCoCo 助您毁灭线上僵尸代码,共有 3 个工具:
•原生 Jacoco 接入
•京东行云流水线集成(二开 Jacoco)
•滴滴开原方案 Super-Jacoco
1.在工程内的 pom 中引入 jar 依赖
<dependency>
<groupId>org.jacoco</groupId>
<artifactId>org.jacoco.ant</artifactId>
<version>0.8.3</version>
</dependency>
<dependency>
<groupId>org.apache.ant</groupId>
<artifactId>ant</artifactId>
<version>1.9.9</version>
</dependency>
1.在工程内增加 http 接口,用于通过 ant 执行 dump task 生成 Dump Coverage 文件
@RestController
@RequestMapping("/coverage")
public class CoverageController {
@PostMapping("dump")
@NoCheckMenuPermission
public Result<Boolean> dumpCoverageFile() {
DumpTask dumpTask = new DumpTask();
// dump文件地址
dumpTask.setDestfile(new File("/xxxxx/xxxxx/coverage/code-cover.exec"));
// 多次dump追加形式
dumpTask.setAppend(true);
// 选一个空闲接口即可
dumpTask.setPort(8800);
// 默认本机
dumpTask.setAddress("127.0.0.1");
dumpTask.execute();
return Result.succeed(true);
}
}
1.程序启动引入 jacoco 的 javaAgent
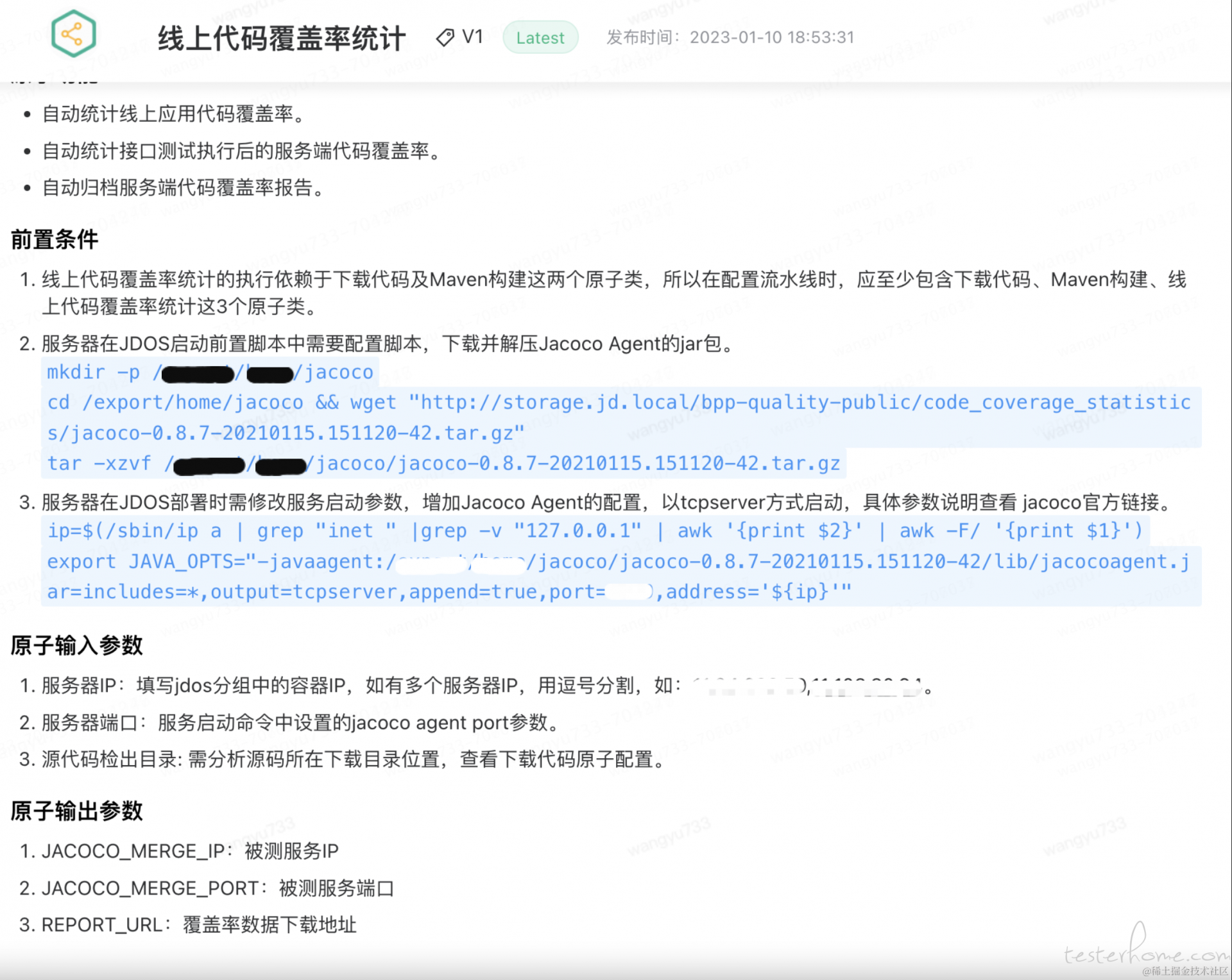
在服务端需要 jacocoagent 增强的 jar 包,获取方式有两种:
•在服务端中解压 org.jacoco.agent 这个 jar 获取 jacocoagent
jar -xvf $BASEDIR/lib/org.jacoco.agent-0.8.3.jar
•直接将 jacocoagent 上传至 oss, wget 命令拉取到服务本地
wget "http://storage.jd.local/bpp-quality-public/code_coverage_statistics/jacoco-0.8.7-20210115.151120-42.tar.gz"
java 应用启动添加如下参数:
includes 为需要监控的代码包路径
-javaagent:$BASEDIR/bin/jacocoagent.jar=includes=com.jdwl.*,output=tcpserver,port=8840,address=127.0.0.1 -Xverify:none
1.dump 文件分析
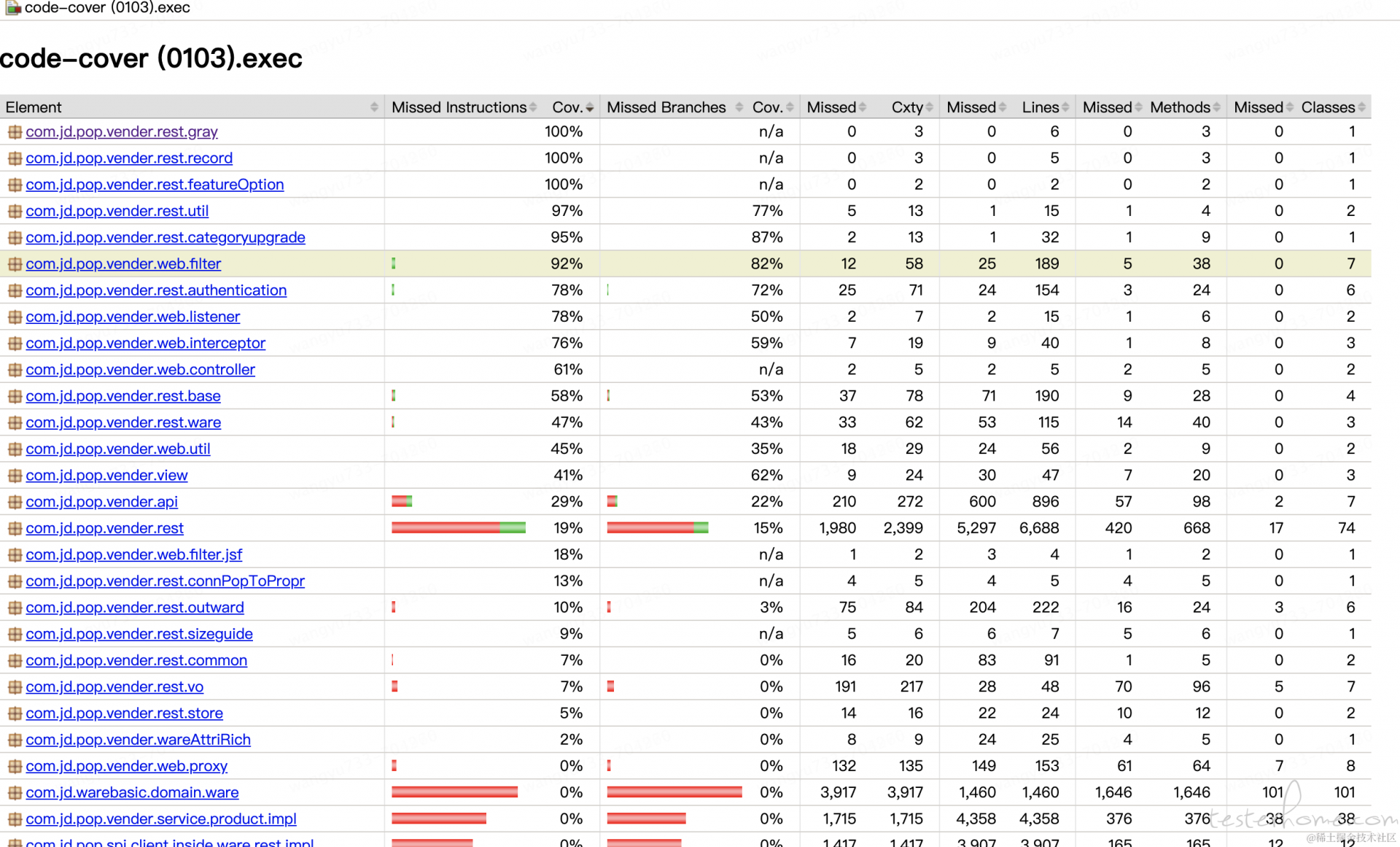
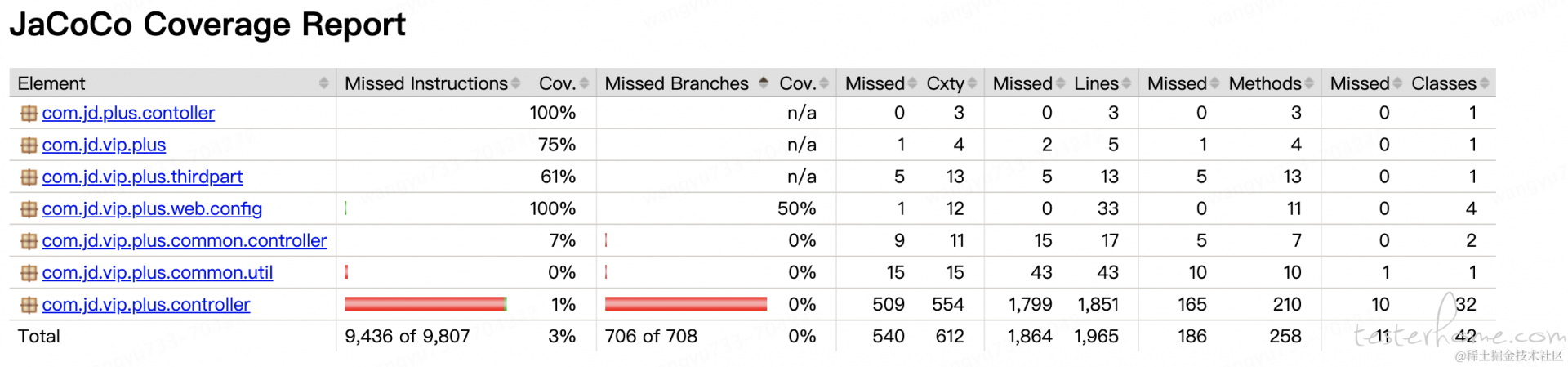
请求应用 "coverage" http 接口,并下载 "code-cover.exec" 文件到本地,打开 idea -> run -> show coverage data 选择对应的 exec 文件即可获取服务端的代码覆盖情况。效果如下图所示:
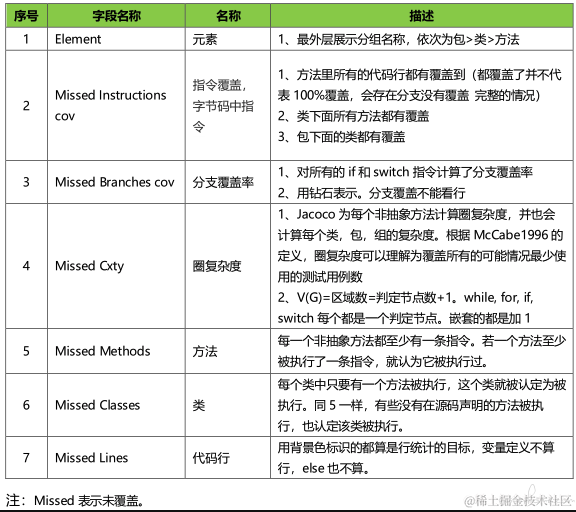
缺点:
•源码层面集成(maven 依赖、HTTP 接口触发数据采集)
•没有体现代码执行频次/执行时间
•监控数据是单机的,没有全局看板
•线上发布较长时间后结合代码实际执行命中情况进行清理
优点:
•不需要侵入业务代码,可识别到代码行级别是否被执行到
原子输出如下:
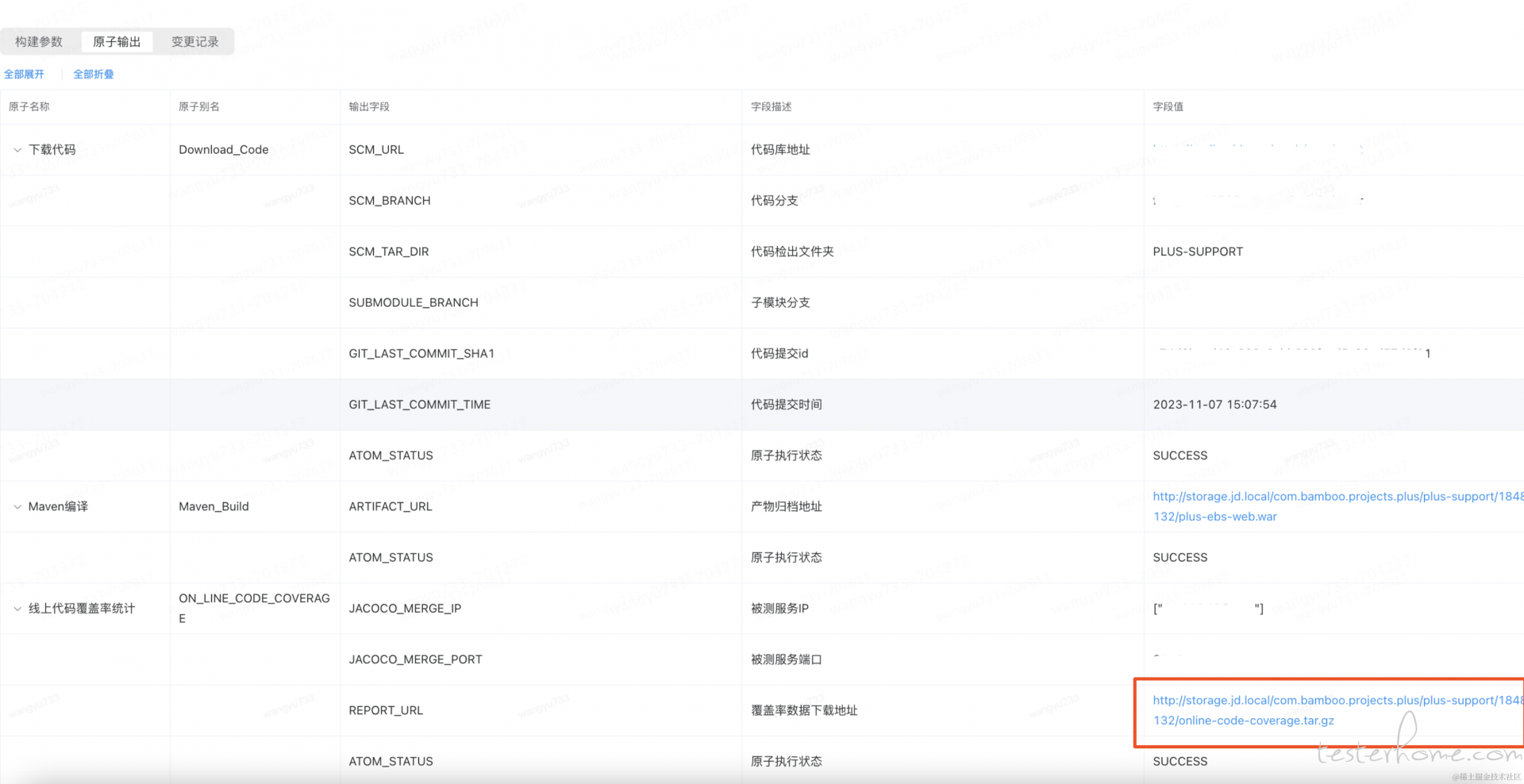
缺点:
•没有体现代码执行频次/执行时间
•线上发布较长时间后,结合代码实际执行命中情况进行清理
优点:
•对比原生 Jacoco 接入,无需源码层面集成(比如:maven 依赖、HTTP 接口触发数据采集)
•监控数据是全局看板(可以配置多个 IP 进行采集合并)
•不需要侵入业务代码,可识别到代码行级别是否被执行到
开源工具:https://github.com/didi/super-jacoco/tree/master#readme
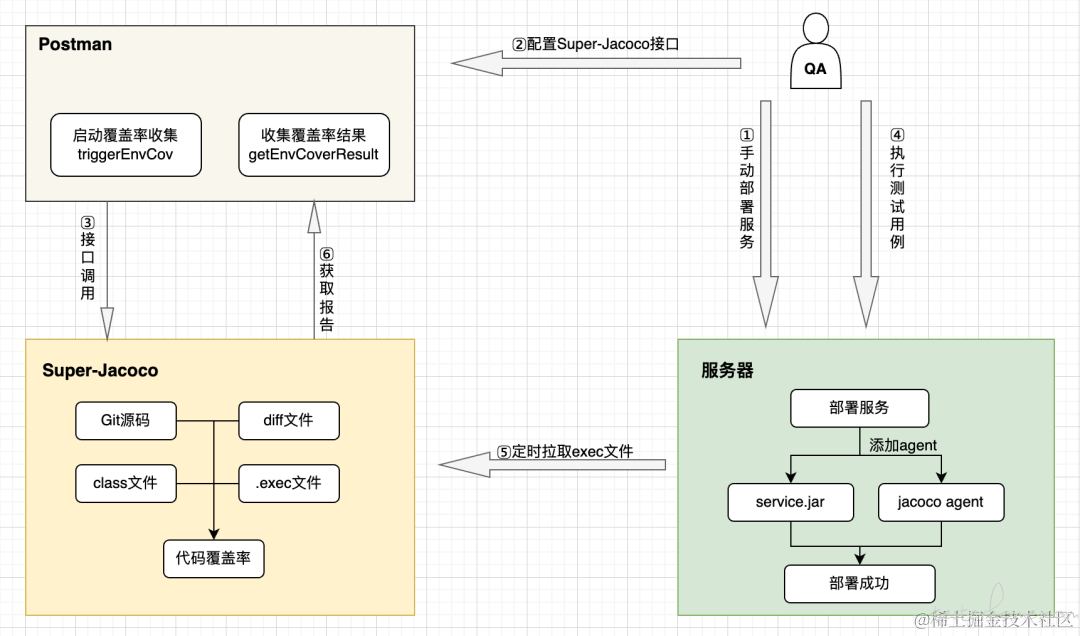
Super-Jacoco 是基于 Jacoco、git 二次开发打造的一站式 JAVA 代码全量/diff 覆盖率收集平台,能够低成本、无侵入的收集代码覆盖率数据;Super-Jacoco 除了支持 JVM 运行时间段的覆盖率收集外;还能够和环境无缝对接,收集服务端自定义时间段代码全量/增量覆盖率;并提供可视化的 html 覆盖率报表,协助覆盖率分析,支撑精准测试落地。
•无需对开发代码做任何改造,只需在服务启动命令中添加 javaagent 即可。
•依托于 Super-Jacoco,基于 Jacoco、Git 二次开发,收集两个版本间增量代码差异。
•用户执行测试用例,用例执行过程中 Jacoco 会记录代码覆盖情况。
•生成可视化的 HTML 覆盖率报告,协助用例覆盖情况精准分析。
部署参考文档:https://blog.csdn.net/meifannao789456/article/details/121738716
缺点:没有体现代码执行频次/执行时间,但用于精准测试场景,可不用关心这两个问题。
使用 APM 产品(Application performance monitoring,应用程序性能监控)对应用流量入口(HTTP,JSF,MQ)或者代码块维度进行监控,筛选出一定时间内没有流量的代码进行治理,为提高效率可结合静态代码分析工具,清理无引用的的代码。
HTTP 流量观测
可使用 UMP、PFinder 来观测
JSF 流量观测
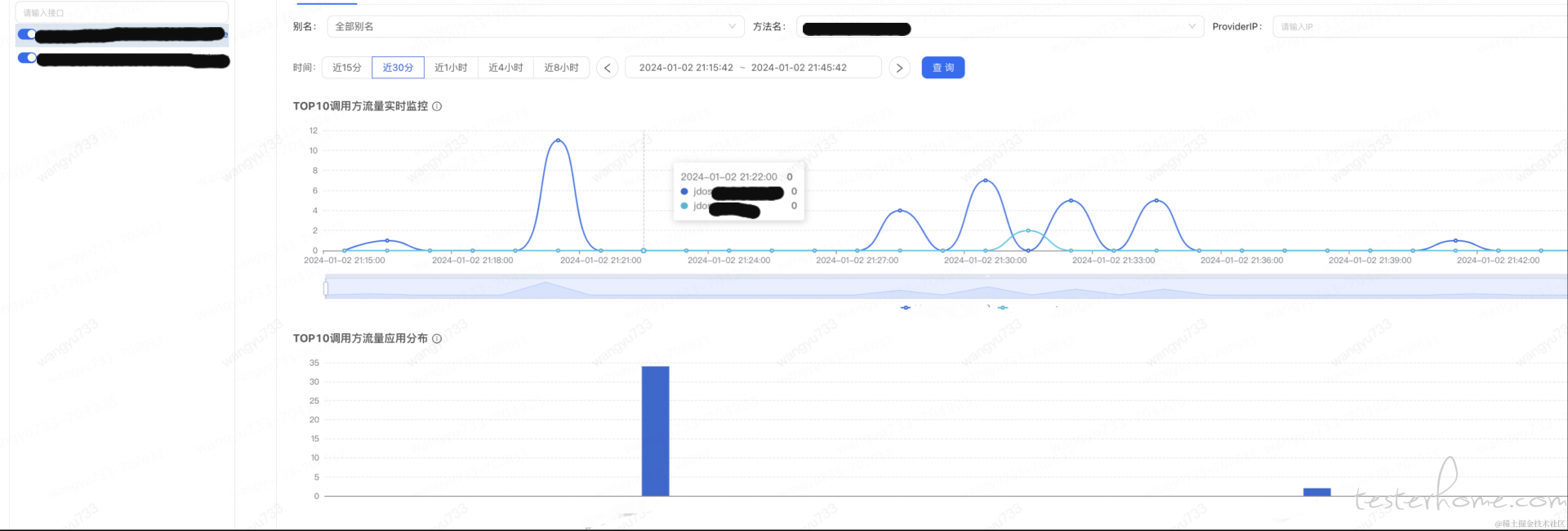
可根据业务现状,利用 UMP、泰山 JSF 流量观测 、PFINDER、SideCar 对 JSF 流量进行监控。推荐JSF 流量观测,无须接入,效果如下,可具体到方法层面流量情况,并能反应客户端信息:
MQ 流量观测
可根据业务现状,利用 UMP、PFINDER、SideCar 对 MQ 流量进行监控,推荐 SideCar 方案 wormhole https://taishan.jd.com/wormhole/overview , 无侵入,无 MQ 版本限制,且接入成本低。
监控粒度:可以通过编码方式最小监控到代码块级别,目前主要应用于方法级别的监控
接入方式:集成 UMP SDK,需要编写代码实现对关注业务的监控,多应用于一般业务代码、AOP 切面
可监控范围:可通过多种形式的代码集成方式,可对任意维度流量进行监控
优点:可控性强,很灵活,存量应用大部分已接入
缺点:有一定代码耦合度,增量观测需要编写代码
监控粒度:最小可以通过编码方式监控到代码块级别,在全链路追踪中,最小的可观测单元是 span(跨度),目前默认情况下 pfinder 的 span 主要用于定义跨容器通信的网络节点。
接入方式:有两种方式,
•通过 javaAgent 方式无侵入的集成,最小只能监控到方法级别
•通过 javaAgent + SDK 的方式集成,通过编码方式最小可监控到代码块级别,但是每个应用的自定义 SPAN 有数量限制, 示例如下:
//自定义metric
public static final MetricPlan<Histogram> TIMED_PLAN = PfinderContext.getMetricRegistry()
.histogram("XXXXXXXX")
.tagKeys("client_sign") //
.build();
MethodExecutionWatcher watcher = PFinderUtils.TIMED_PLAN.ofTagValues(new String[]{"newPop"}).watcher();
try{
....
} catch (Exception e) {
watcher.fault();
throw e;
} finally {
watcher.close();
}
效果如图:
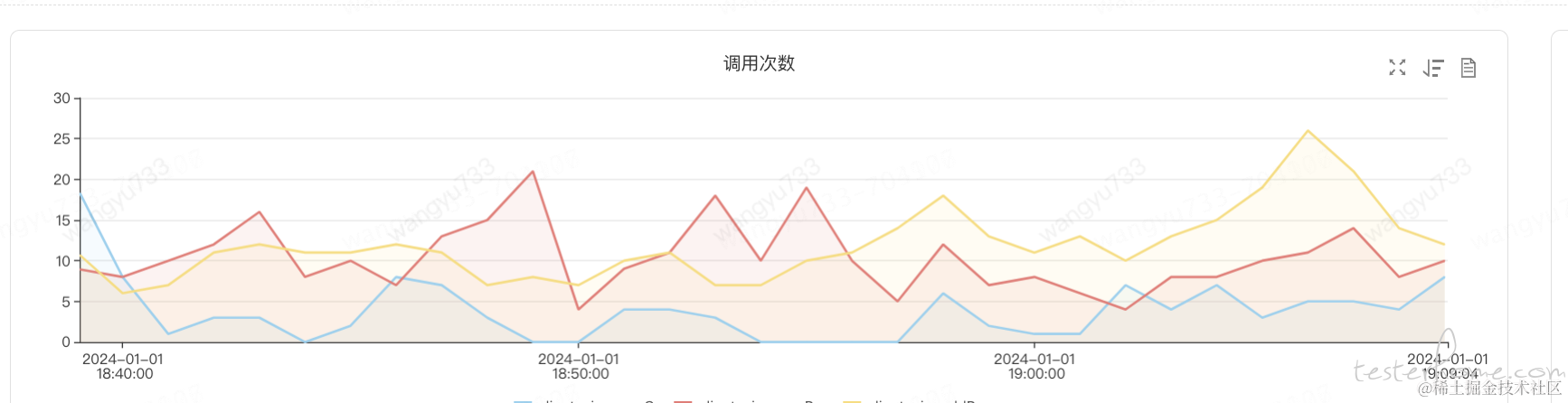
可监控范围:可通过监控代码耦合和注解方式进行集成,可对 HTTP,JSF,MQ,数据库等流量进行监控
优点:有一定灵活性,全链路追踪 trace 上默认有很多关键 span,可自定义 metric, 存量应用大部分已接入
缺点:代码块观测需要编写代码,有一定代码耦合度,且自定义 span 有数量限制
公司内部已整体采用了 kubernetes 作为 容器编排 paas 底座,并参考 Istio 自研了 SideCar 容器产品 wormhole https://taishan.jd.com/wormhole/overview,可用于应用观测、服务治理、混沌演练。
监控粒度:东西流量网络端点——JSF 接口/MQ/http,HTTP 由于数据规模过大,目前只存储到 POD 端口级别的监控数据
接入方式:利用 k8s 服务编排,无侵入接入业务系统,由于公司内部 k8s 版本问题,部分分组不支持
可监控范围:JSF 接口/MQ ,监控示例如下:
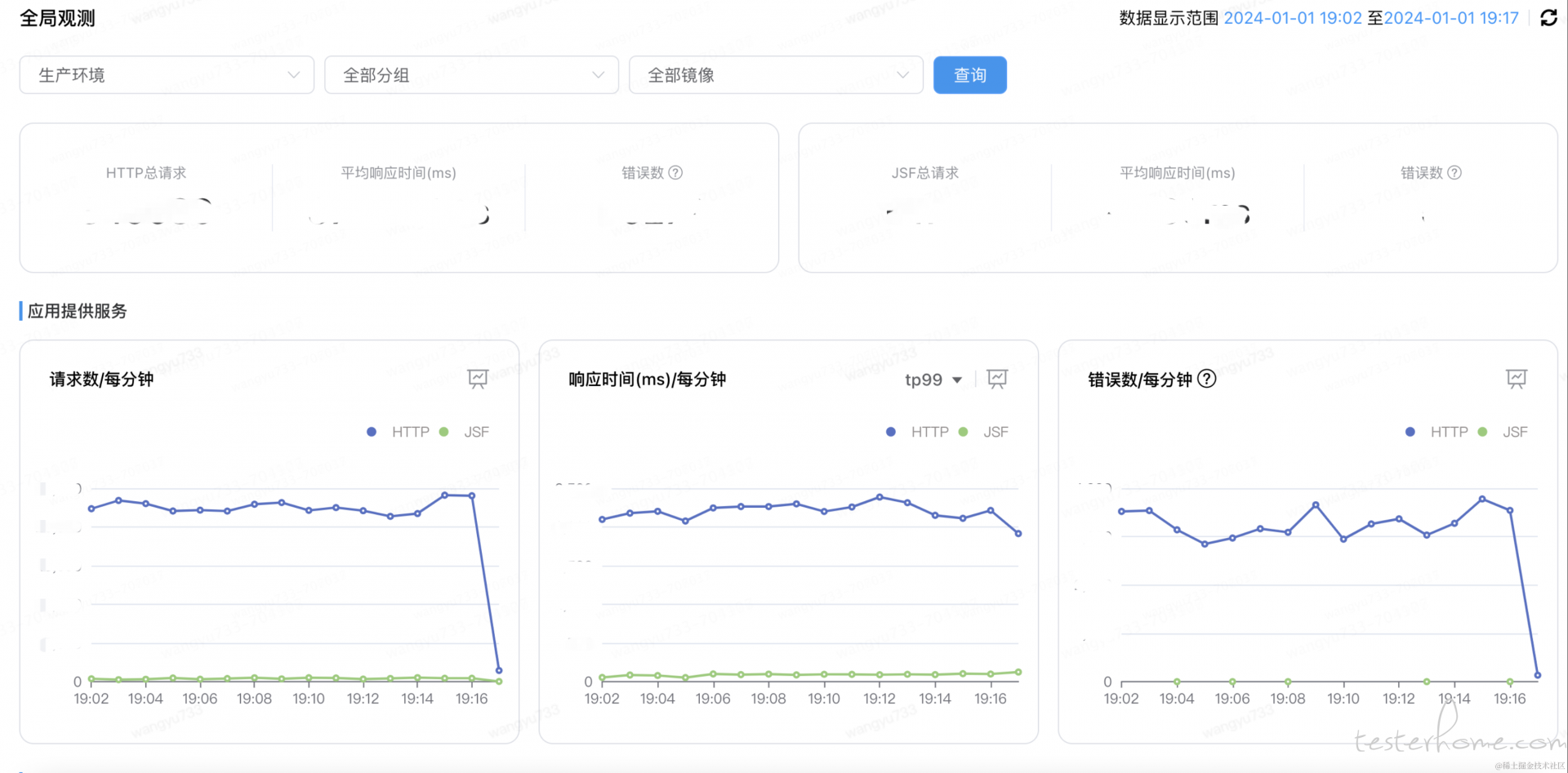
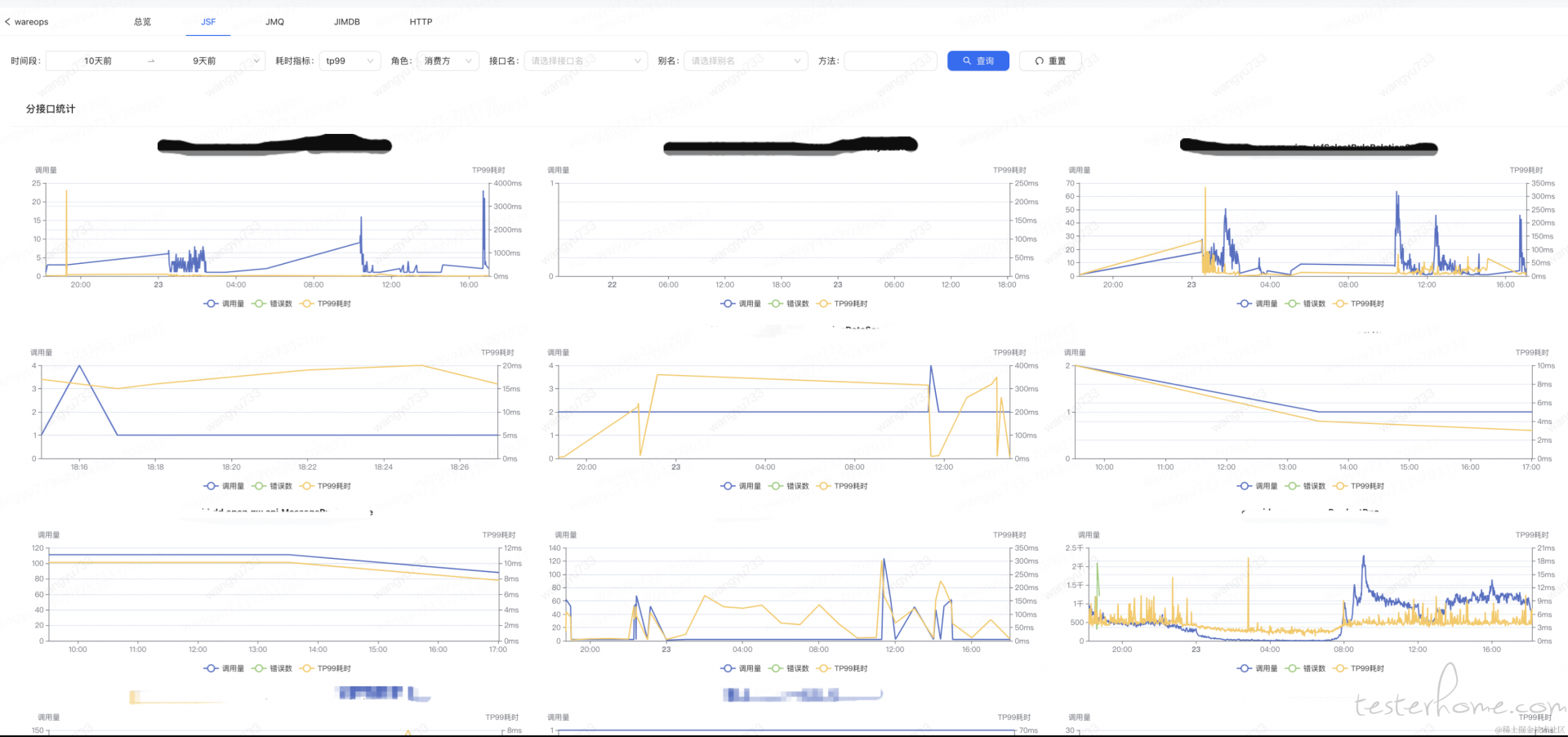
优点:无侵入,以应用为中心的观测方式比较全面
缺点:JSF 监控粒度到接口级别,HTTP 监控到端口级别
借助 IDEA 自带的代码审查功能、PMD、SonarLint 等工具对代码进行静态检测,从代码精简的角度出发,可以识别的问题如下:
•DEAD CODE(僵尸代码识别)
•REPEAT CODE(重复代码)
利用静态分析工具寻找悬挂引用点,这种方案的缺陷:
•无法找到通过反射机制得到的引用点。
•存在继承体系的情况下,静态扫描无法有效识别悬挂引用点。
IntelliJ IDEA 具有强大、快速和灵活的静态代码分析功能。可以发现多种情况的代码效率低下。每当你遇到一些无法访问的代码、未使用的代码、非本地化的字符串、未解决的方法、内存泄漏甚至拼写问题 - 你就会发现代码检查很有用。
4.1.1 示例
代码审查相关功能在 Code 菜单这里(如下图)。两条灰色的线条将这几项归为一类:
点击 OK 运行,在 problem 视窗里可以看到 “有问题” 的代码:
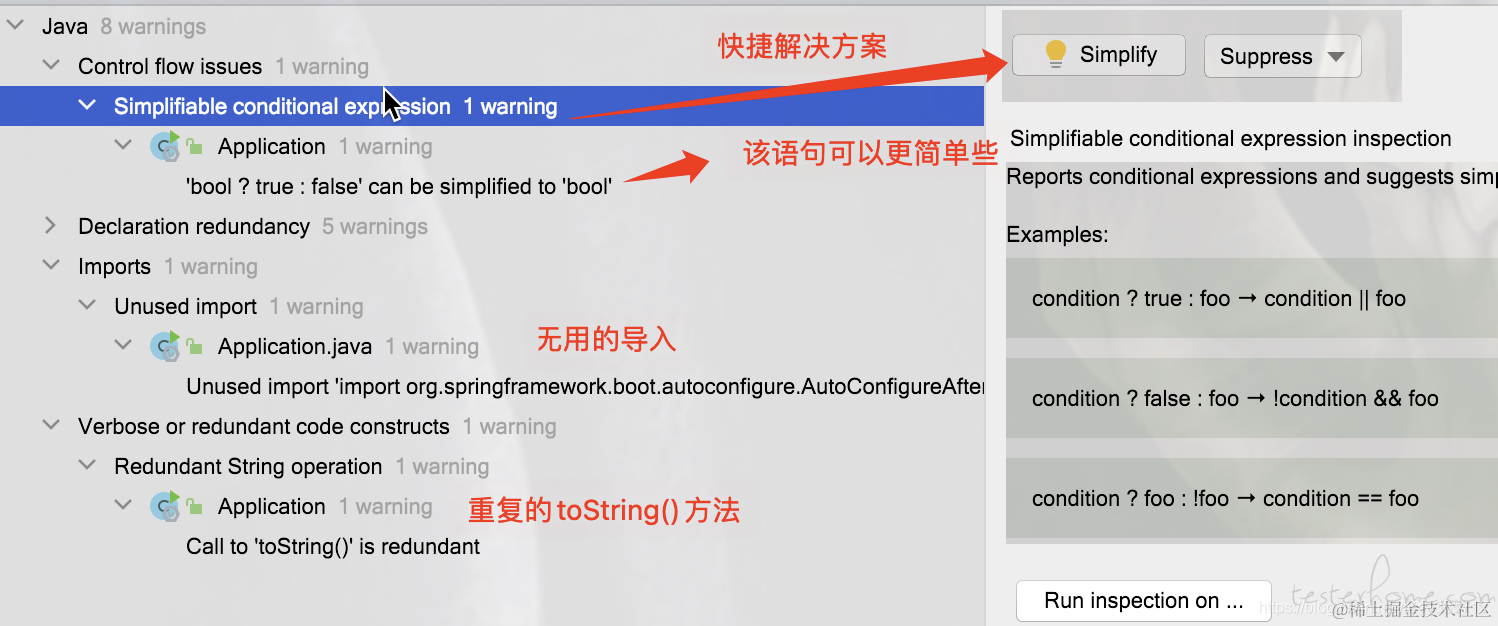
经过审查,本工程里的 “坏味道” 代码就在 problem 视窗指出了。如图,IDEA 针对性的提供了便捷的一键处理按钮,你可以快速处理, IDEA 静态扫描问题清单 。
自动检查清除冗余资源
自动检查清除冗余资源详细功能 Name 对应 Idea 中 Preferences—>Editors—>Inspections 中所有内容
1、清理无效类 Run Inspection by Name:Empty Class

2、查看未使用方法 Run Inspection by Name:Unused declaration
包含了项目里面声明了没用使用过的变量,方法和类
对于检测的内容,idea 提供四种解决方案
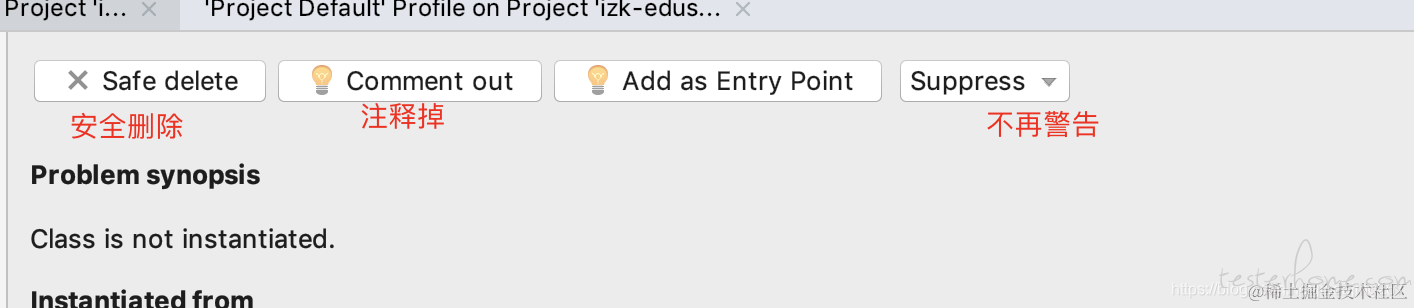
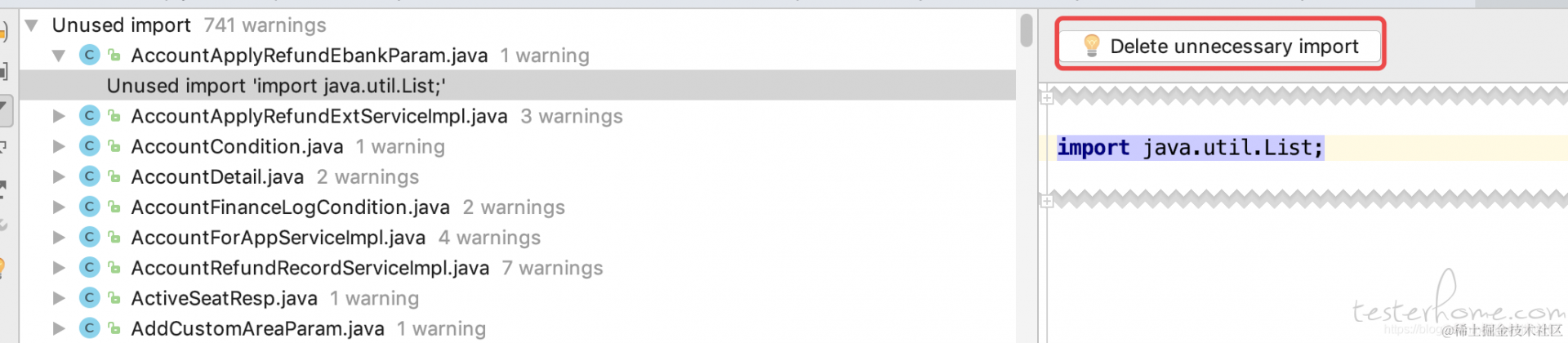
3、查看类中有未使用引用 Run Inspection by Name:Unused import
IntelliJ IDEA 搜索重复项
1.执行以下操作之一:
◦在主菜单上选择 分析 | 查找重复项(Analyze | Locate Duplicates)。
◦在编辑器或项目工具窗口的上下文菜单中选择分析 | 找到重复命令(Locate Duplicates)。
2.在 "指定代码复制分析范围" 对话框中,指定分析范围(整个项目、当前文件、未提交的文件(对于版本控制下的项目)或某些自定义范围)。此外,您还可以将测试源包含在分析中。
3.单击 “确定”,准备就绪。
4.在 “代码复制分析设置” 对话框中,请执行以下操作:单击 “确定”。
1.选择要在其中执行分析的语言。
2.对于每种语言,请检查选项以定义分析的首选项。
3.例如,您可以选择请求相同的代码片段匹配被视为重复项,或者指定一个特定的限制,以下的代码结构不被认为是重复的(以避免报告if源代码中的每个构造)。
5.在 “重复” 工具窗口,浏览搜索结果。
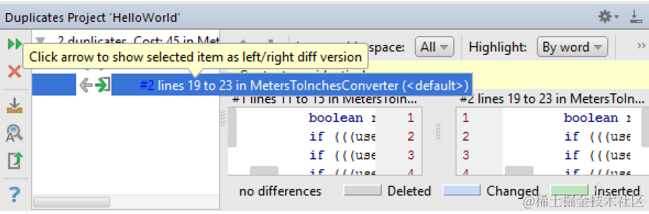
•在工具窗口的左窗格中查看重复项列表。
•查看右窗格中找到的重复项之间的差异。使用箭头按钮将所选副本放在差异查看器的其中一个部分,并比较代码片段。
•导航到编辑器中的重复项,使用 “跳转到源” 或 “显示重复上下文” 菜单的源命令。
•通过单击并在 "提取方法" 对话框中指定方法名称和参数来消除源代码中的重复项。这个程序类似于提取方法重构,唯一的区别是,在重复分析的情况下,重复的代码块被自动找到。
IntelliJ IDEA 动态检测重复项
IntelliJ IDEA 可以动态查找重复的内容。这是由检查 一般 | 重复的代码((General | Duplicated Code))。
如果您偶然发现一个现有的副本,或者通过编写或粘贴代码创建一个副本,您将立即知道:
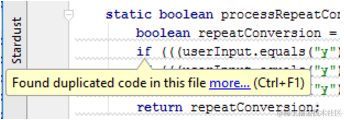
检查伴随着快速修复,它使您能够导航到检测到的重复项,或在 "查找工具" 窗口中查看所有这些副本:
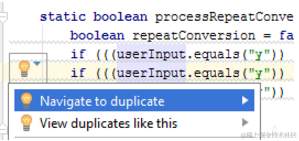
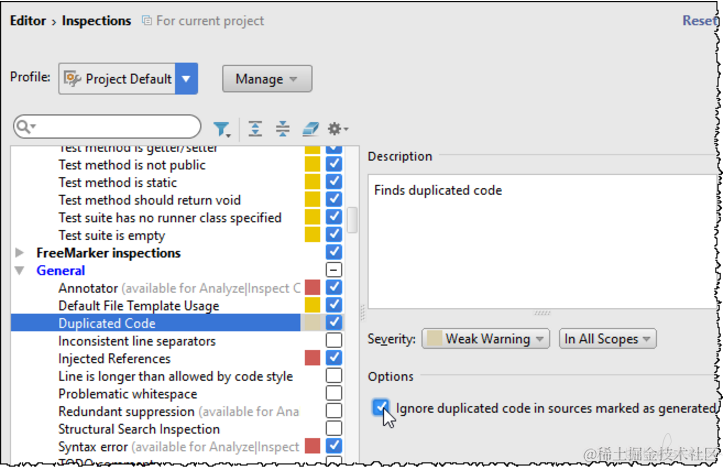
请注意,IntelliJ IDEA 有助于避免在生成的源中找到重复项。
为此,选中该复选框可忽略在 "检查设置" 页中标记为 "生成的源" 中的重复代码:
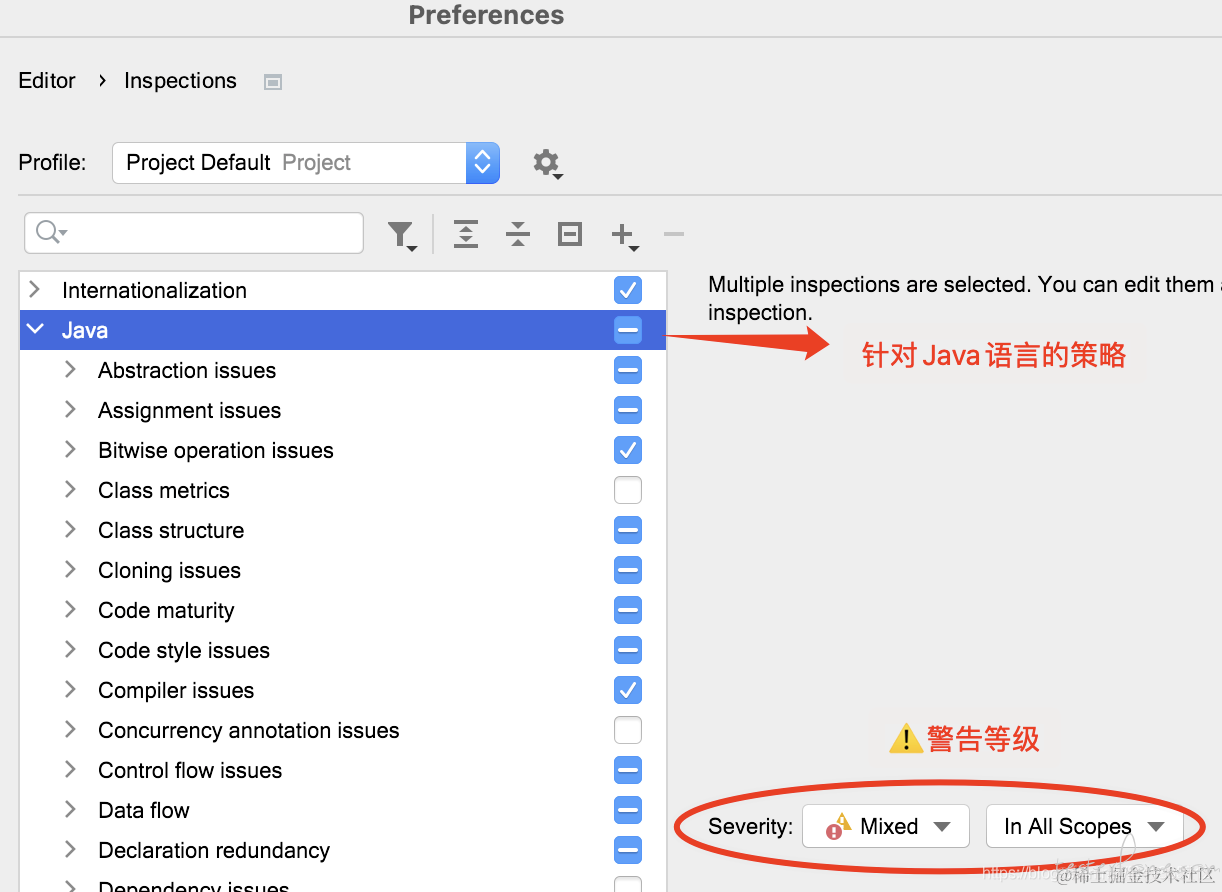
代码审查的策略
IDEA 怎么知道这是坏味道代码的?遵照什么规则?显然,一切都是 “有法可依”,它在这:设置 -> Editor -> Inspections
PMD 侧重面向安全编码规则,且具备一定的数据流分析和路径分析能力,能力比 CheckStyle 稍微强点,并且 PMD 支持自定义规则,PMD 可以直接使用的规则包括以下内容:
•未使用的代码(Dead code) :未使用的变量、参数、私有方法等
•复杂的表达式:不必须的 if 语句、可被 while 替代的 for 循环
•重复的代码:拷贝/粘贴代码意味着拷贝/粘贴 bugs
•循环体创建新对象:尽量不要在循环体内实例化新对象
安装步骤
IDEA 通过 File > Settings > Plugins > Marketplace 搜索 “PMD”,按照提示进行安装,然后重启即可
配置检测规则
通过 File > Settings > Other Settings > PMD 可以打开检测规则的设置界面:
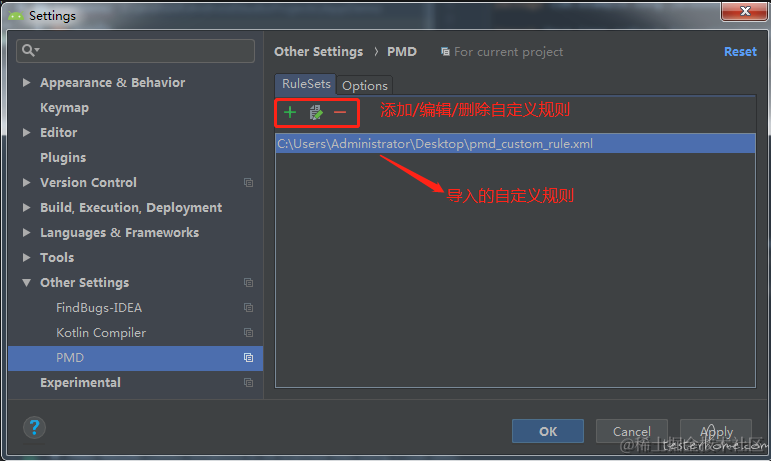
在 “RuleSets(规则设置)” 界面可以管理自定义的检测规则。因为在实际工作中,可能需要根据实际情况自定义检测规则,就可以通过这里导入,如果要使用它,需要在启动 PMD 进行检测时选择该自定义规则。
点击 “Options” 选项卡,在其中可以配置一些检测规则选项:
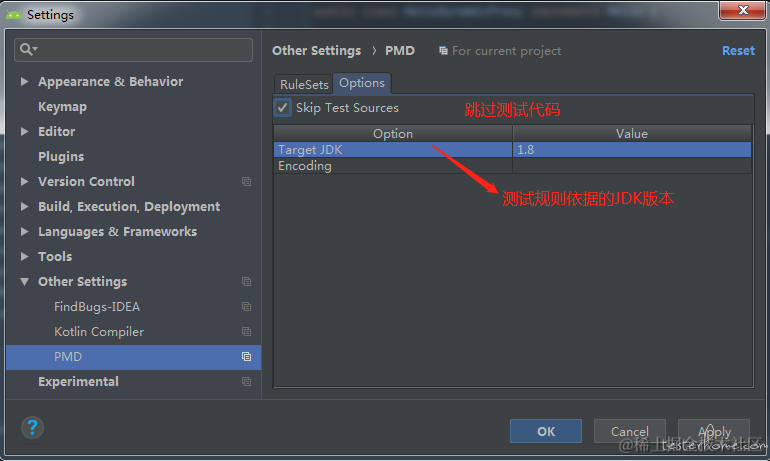
其中重点需要留意的是 “Skip TestSource” 这一项,选择上述选项后可以将其过滤掉。
运行方式
(1)从 Tools 菜单中启动:
通过 Tools > Run PMD 可以看到如下的界面,如果通过该方式启动,扫描的范围就是整个项目中的文件了。
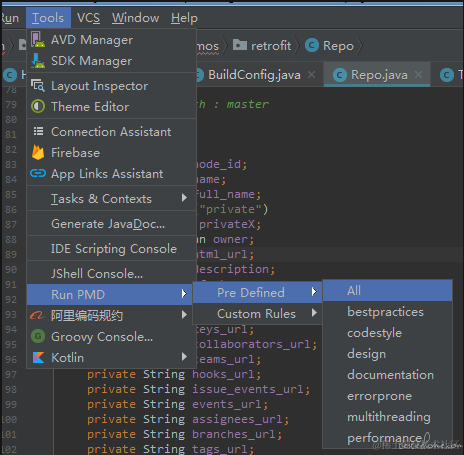
•Pre Defined:预定义的规则,也就是插件自带的检测规则。后面展开的列表中列出了所有的规则列表,想扫描哪一种类型的问题,点击即可。其中 “All” 表示使用所有的规则。
•Custom Rules:自定义的检测规则,PMD 允许用户根据需要自定义检查规则,默认这里是不可点击的,需要在设置中导入自定义规则文件后方可选择。
(2)从右键菜单中启动:
在文件或者编辑器中点击右键,也可以看到 “Run PMD” 选项,如果通过该方式启动, 检测范围取决于鼠标或光标当前所选中的区域。
运行结果
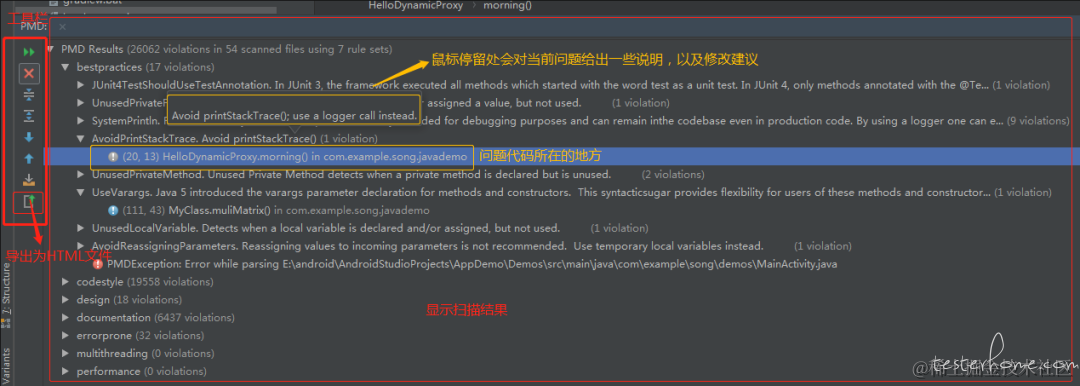
运行后会出现如上所示的面板,左边工具栏,鼠标停留在上面会提示其功能;右边显示了检测结果,当点击具体某一问题项时,会跳转到对应的源码中。
Maven 提供了 PMD 项目报告插件,能让用户生成静态代码分析审查报告
POM 配置:
<project>
...
<reporting>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-pmd-plugin</artifactId>
<version>3.21.0</version>
<configuration>
<rulesets>
<ruleset>/rulesets/java/braces.xml</ruleset>
<ruleset>/rulesets/java/naming.xml</ruleset>
</rulesets>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
执行 PMD 检查:
mvn site
生成的文件为 target/site 目录下的 pmd.html 文件
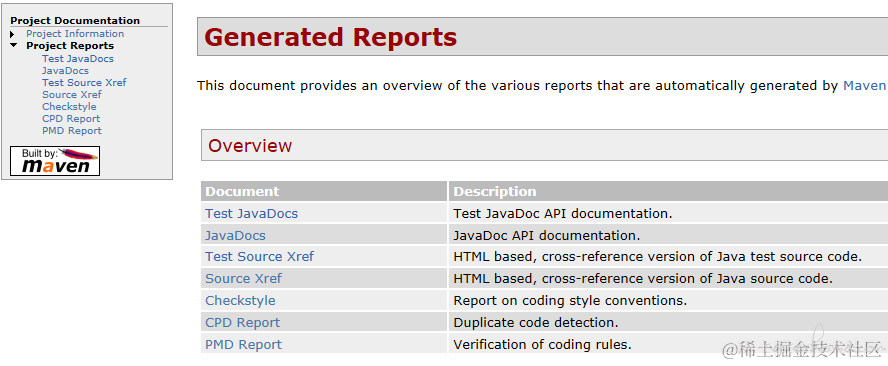
Files
com/baeldung/pmd/Cnt.java
Violation Line
Avoid short class names like Cnt 1–10
Avoid using short method names 3
Avoid variables with short names like b 3
Avoid variables with short names like a 3
Avoid using if...else statements without curly braces 5
Avoid using if...else statements without curly braces 7
Sonar 不仅关注常规静态 BUG,还关注到了如代码质量、包与包、类与类之间的依赖情况,代码耦合情况,类、方法、文件的复杂度,代码中是否包含大量复制粘贴的代码,关注的是项目代码整体的健康情况。sonar 有两种使用方式:插件和客户端,sonar 的插件名称为 sonarLint,可用于集中式卡点。
安装步骤
通过 File > Settings > Plugins > Marketplace 搜索 “SonarLint”,按照提示进行安装,然后重启即可
使用说明
右键项目或者文件进行如上图所示操作,执行之后可以看到如下信息,如果代码中有不合理的地方会在 report 中显示,同时点击错误的地方在右边会给出建议的修改供参考。
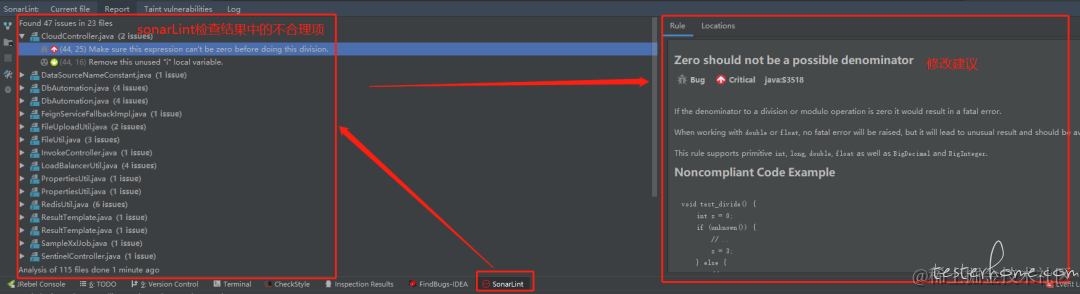
配置 SonarLint 服务端
配置 Sonar 服务器
sonarLint 插件的使用场景是自用自审,但 sonar 也提供了平台版本,使用场景则是他审,sonar 平台的搭建就不在这篇文章介绍了,感兴趣的读者可以自己上网查看,我们这里主要介绍如何在 sonarLint 插件中配置关联 sonar 平台服务器的工程,进行本地检查:
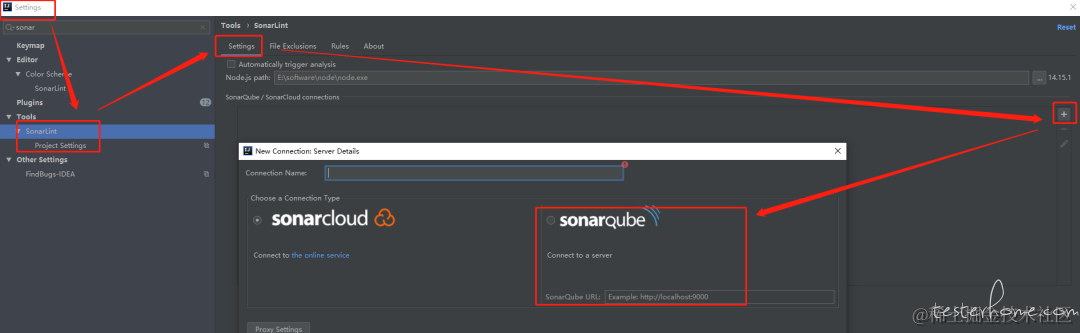
点击新增按钮,输入Configuration Name,配置sonarlint 服务器的地址,然后下拉框选择 Login/Password,输入 sonarlint服务器的账号密码
具体 Sonar 工程配置
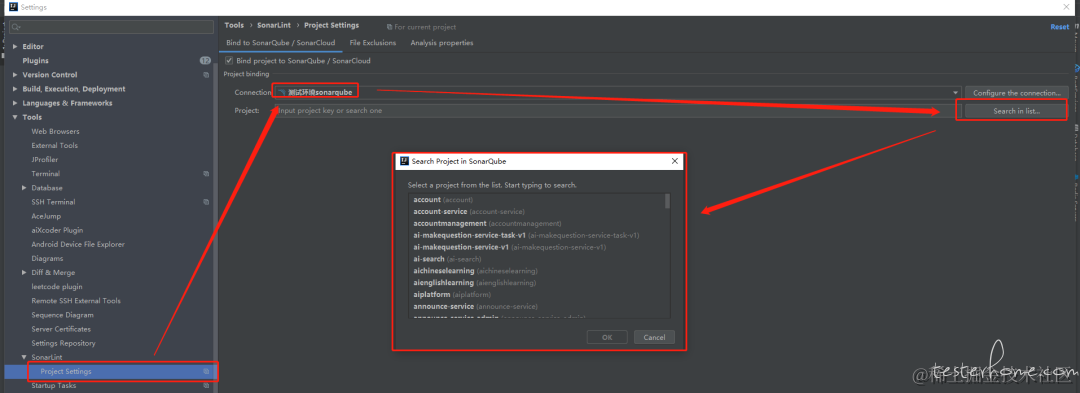
配置完服务器之后,需要针对具体工程进行配置,点击 connection下拉框,选择上面配置好的服务器连接,然后点击 Search in list,找到对应的工程:
使用 SonarLint 检查
配置完上面两步之后,接下来就可以选择要进行检查的类或者目录进行 sonarlint 检查了(跟第 3 点的使用方式一致),同时,在 commit 代码的时候,勾选 “Perform Sonarlint analysis”,会针对你要提交的代码进行 sonarlint 检查

