
自知是人外有人,天外有天,相信对于 Log4j2 的异步日志打印早有老师或者同学已是熟稔于心,优化配置更是信手拈来,为了防止我在这里啰里八嗦的班门弄斧,我先将谜底在此公布:log4j2.asyncQueueFullPolicy=Discard & log4j2.discardThreshold=ERROR,这两个 Log4j2 配置在强依赖的 RPC 服务方系统或中间件系统出现问题且业务流量巨大时,对系统的快速止血和影响范围的控制有奇效。要问为什么如此配置,是否还有高手?请见下文分晓。
在2023年12月15日这 “普通” 的一天午后 14 点 25 分,我们收到了来自 UMP 的报警,接口服务可用率直接从 100% 干到了 0.72%(该服务会直接影响到订单接单的相关流程,对客户体验有着重大影响)。我们顺藤摸瓜,并配合其他的服务监控定位到是强依赖系统出现了故障,导致其服务高度不可用,因此赶紧联系相关系统同事进行问题排查和处理。
大概 14:33 左右,服务端系统同事反馈已经机器扩容完成,由以下截图可见,确实在 14:32 左右服务可用率开始有抬头趋势,但是至此问题却并未终结,在 14:36 服务可用率开始急转直下(错误日志内容除了服务响应超时,服务端线程池满等异常以外,同时还收到了无服务的异常以及其他不相关服务调用的超时异常)。服务端系统同事反馈新扩容机器仅有极少数流量流入,如此 “意外之喜” 是我们没想到的,其后续排查和问题定位的过程分析也是该文成文的主要原因。最终我们通过操作客户端机器重启,服务得以完全恢复。
图 2-1 服务端系统问题初现

图 2-2 客户端服务监控可用率再次骤降
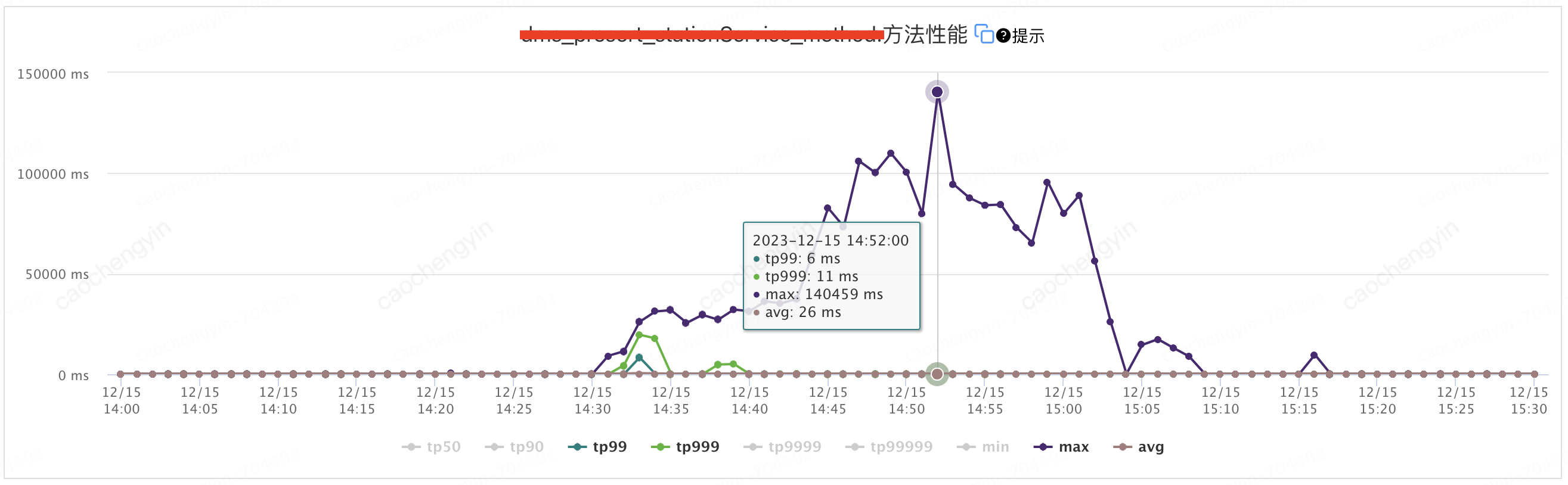
图 2-3 客户端服务监控 TP 指标
系统 JDK 和相关依赖版本信息:
1.JDK:1.8.0_191
2.JSF:1.7.4-HOTFIX-T8
3.SLF4J-API:1.7.25
4.LOG4J-SLF4J-IMPL:2.18.0-jdsec.rc2
5.LOG4J2:2.18.0-jdsec.rc2
6.DISRUPTOR:3.4.2
1.为何服务可用率恢复到了一定程度后又掉下来了?
2.为何一个服务方的服务出现问题后,其他服务方的服务却也受到了影响?
3.服务超时控制为何没有起作用?
4.服务端出现问题为何需要客户端执行重启操作?
如果上面的问题解决不了,大概我晚上睡觉的时候一掀开被窝也全是“为何”了,带着这些问题我们便开始了如下排查过程。
排查客户端机器是否出现由于 GC 导致的 STW(stop the world)
由以下截图可见 Young GC 次数确有所升高(猜测应该有较多大对象产生),Full GC 并未触发;堆内存,非堆内存的使用率处于正常水平;CPU 使用率有所飙高且线程数略有增加,但是尚处于正常可接受范围内,目前看来问题时间段内机器的 JVM 指标并不能提供太多的定位线索。

图 4-1-1 客户端服务器 Young GC 和 Full GC 情况
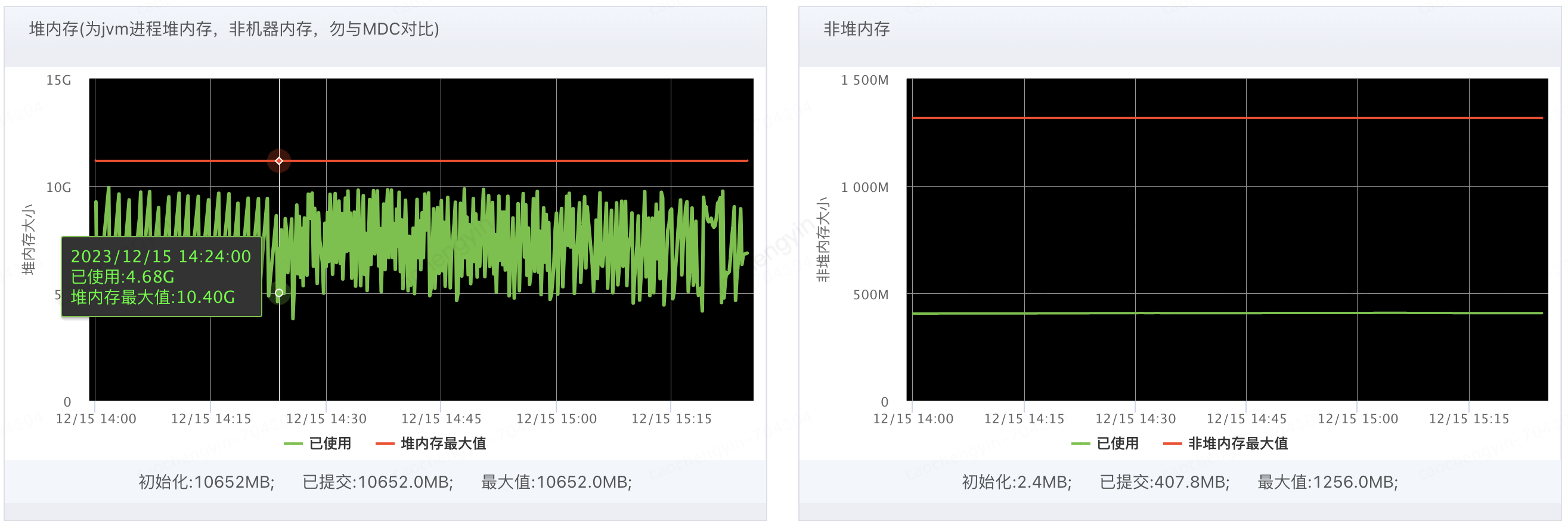
图 4-1-2 客户端服务器堆内存和非堆内存情况
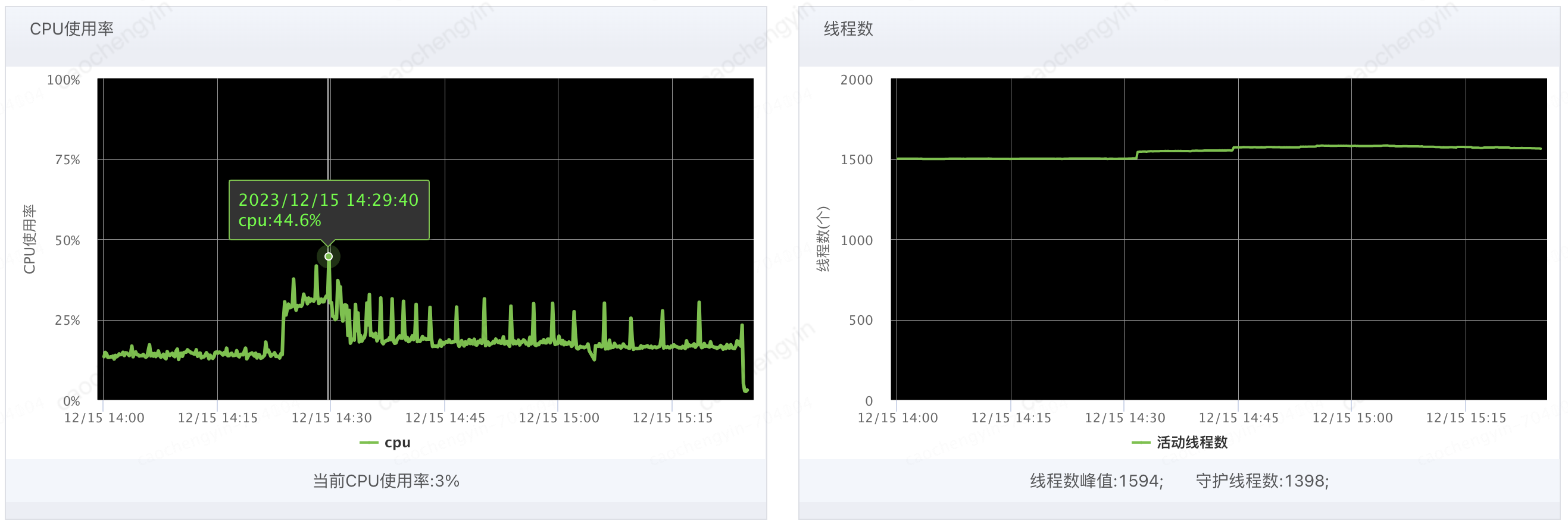
图 4-1-3 客户端服务器 CPU 使用率和线程数情况
排查客户端机器磁盘情况,看是否存在日志阻塞的情况
通过以下截图可见,磁盘使用率,磁盘繁忙,磁盘写速度等磁盘指标看起来也尚属正常,由此暂时推断该问题与日志的相关性并不大。
注:这对我们后来问题排查的方向造成了误导,将罪魁祸首给很快排除掉了,其实再仔细看一下磁盘使用率的截图,在相对较短的时间内磁盘使用率却有了明显的增长,这是出现了 “精英怪” 呀,不过即便如此,目前也仅仅是猜测,并无充足的证据来支持定罪,接下来的排查才是重量级)
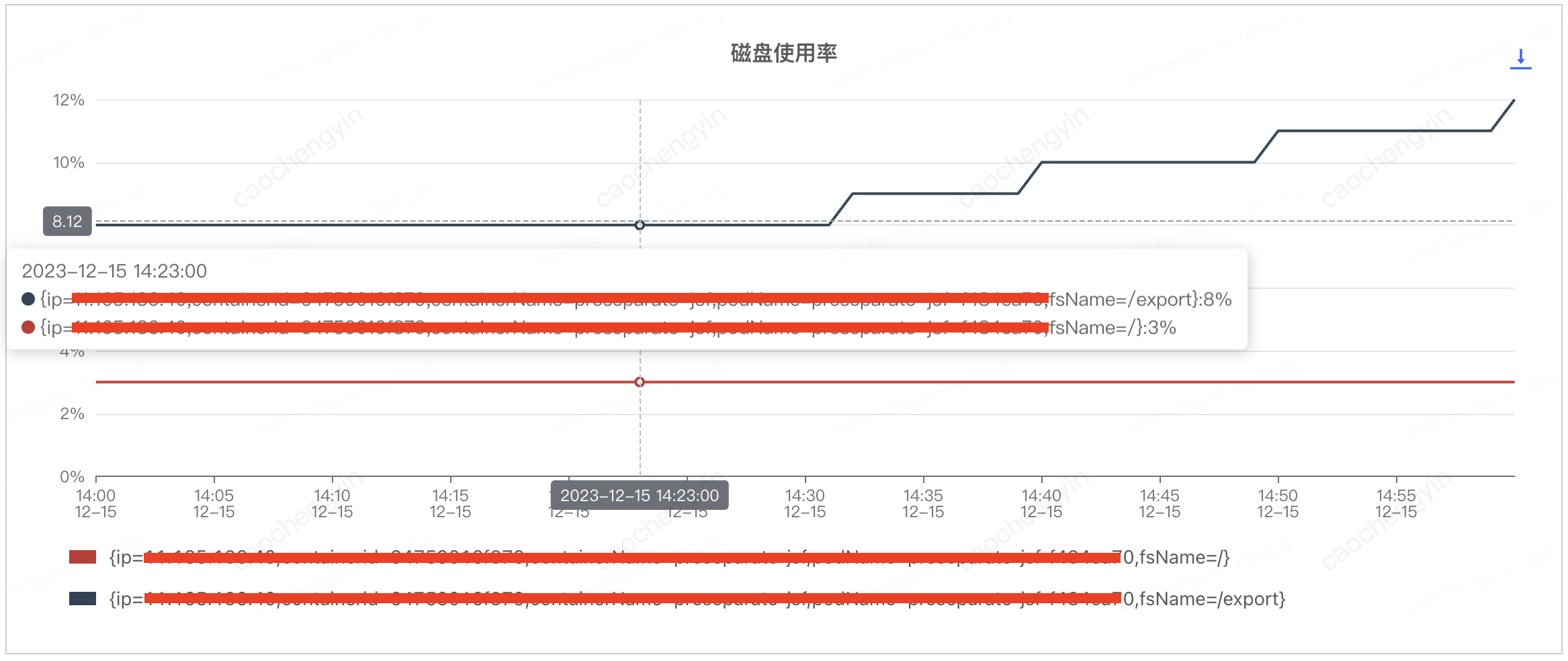
图 4-2-1 客户端服务器磁盘使用率情况
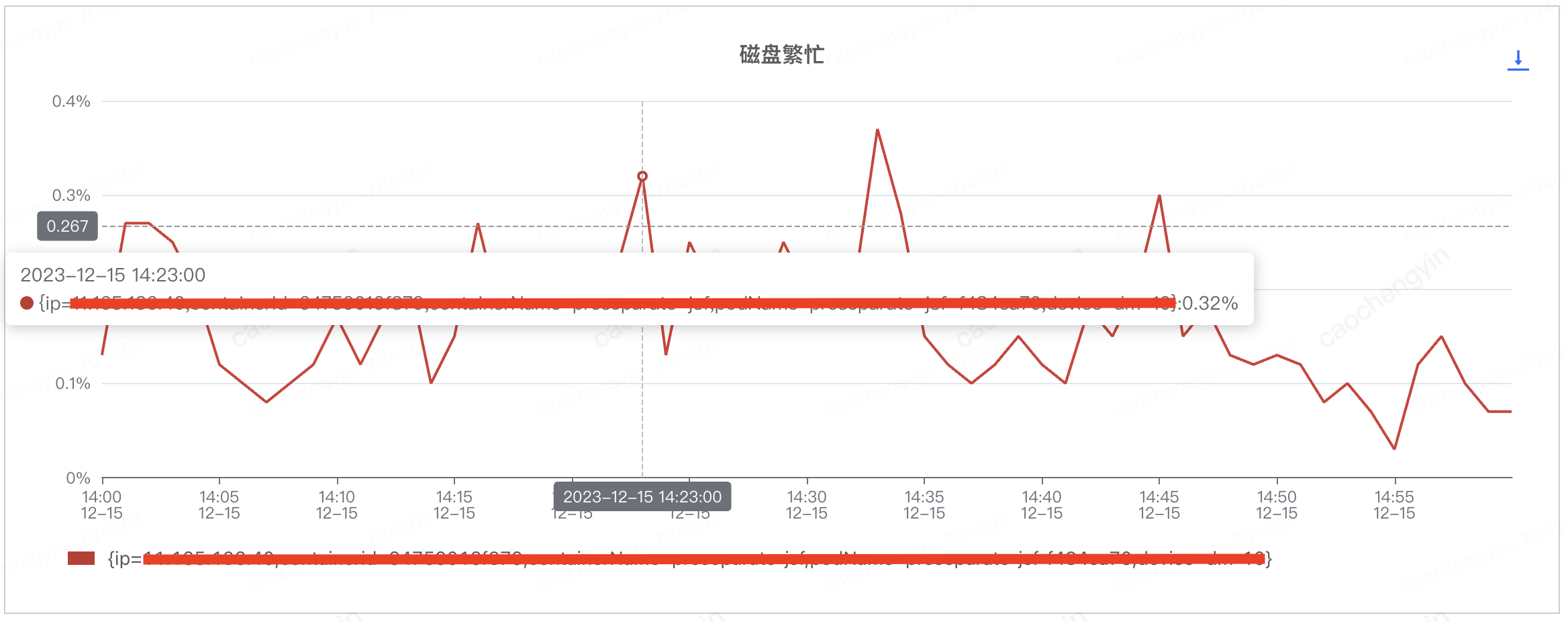
图 4-2-2 客户端服务器磁盘繁忙情况
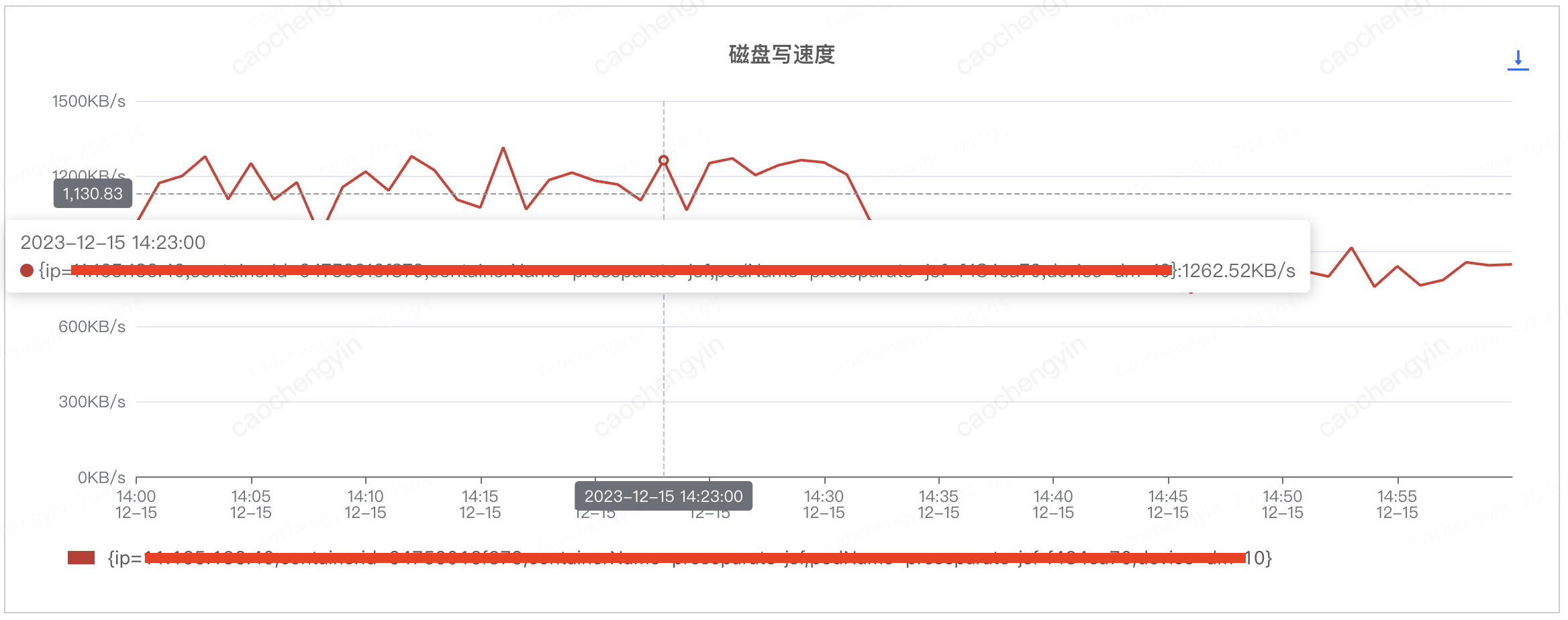
图 4-2-3 客户端服务器磁盘写速度情况
查看问题时间段内客户端机器的内存状况(jmaq -dump)
通过JSF-CLI-WORKER关键字我们可以定位到 JSF 客户端线程状态,通过以下截图可以看出,JSF 客户端线程虽然在执行不同的服务处理流程,但是都在执行 WARN/ERROR 日志打印的时候卡在了 enqueue 环节。
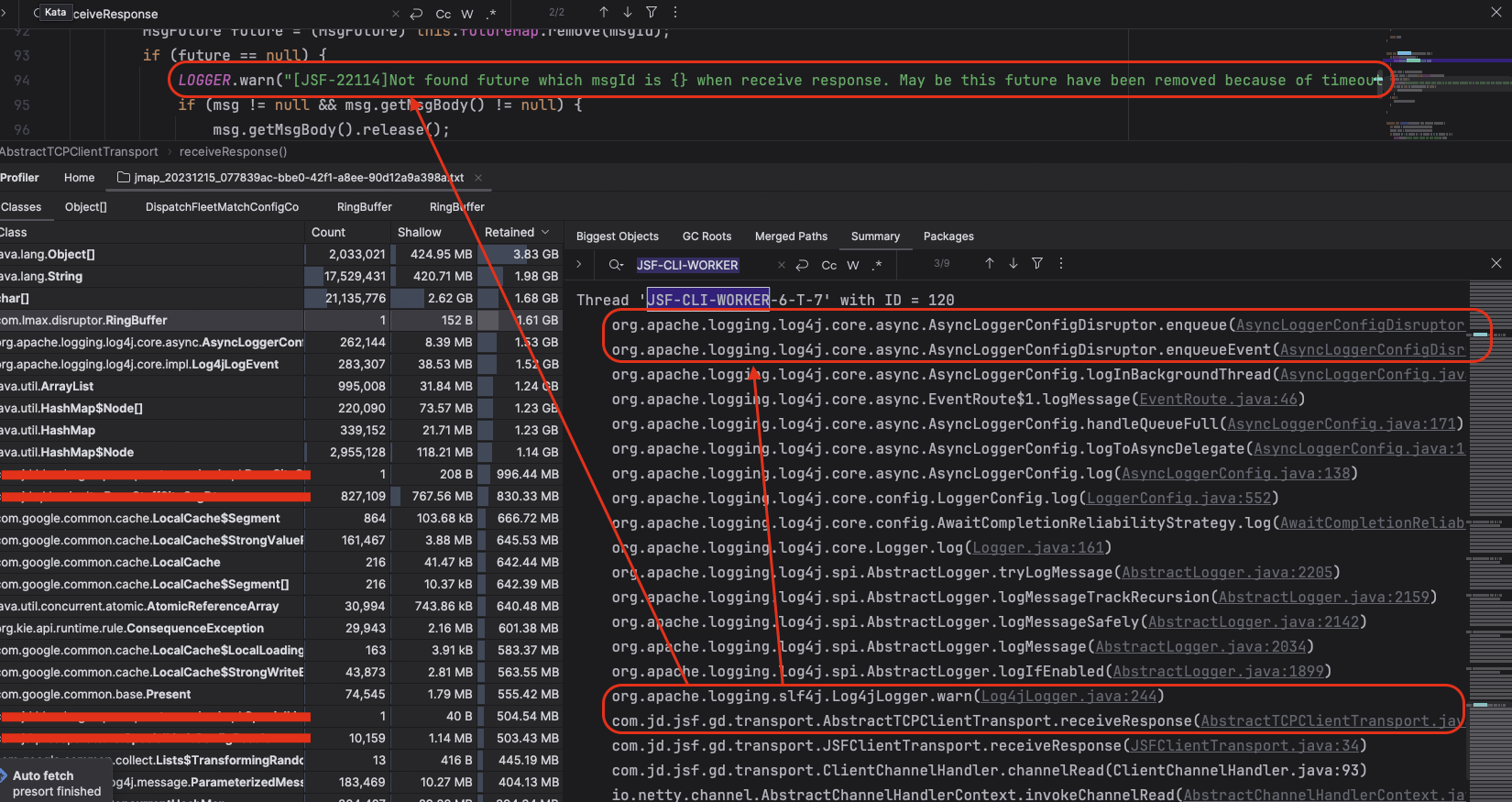
图 4-3-1 JSF 客户端线程状态 1
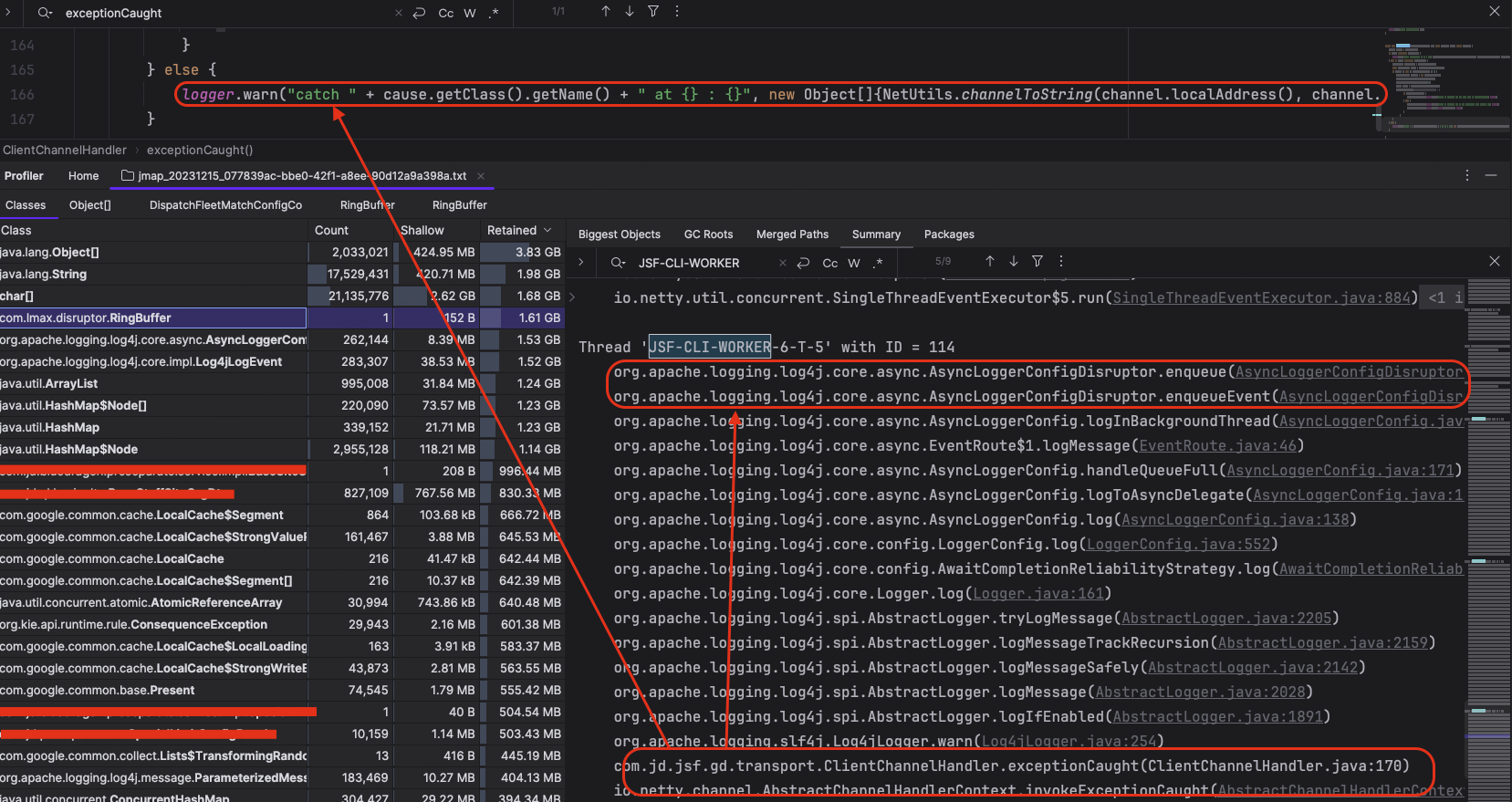
图 4-3-2 JSF 客户端线程状态 2
下面让我们来分析一下源码,具体看一下 enqueue 到底干了什么?
// enqueue源码分析
// 代码位置org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor#enqueue 363
private void enqueue(final LogEvent logEvent, final AsyncLoggerConfig asyncLoggerConfig) {
// synchronizeEnqueueWhenQueueFull() 是与另外一个要和大家分享的开关配置(AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull)有关,该配置用于指定当日志异步打印使用的RingBuffer满了以后,将多个日志线程的队列写入操作通过锁(queueFullEnqueueLock)调整为同步
if (synchronizeEnqueueWhenQueueFull()) {
// 同步锁:private final Object queueFullEnqueueLock = new Object();
synchronized (queueFullEnqueueLock) {
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
}
} else {
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
}
}
由上述源码我们不妨大胆的假设一下:JSF 的客户端线程由于日志打印被阻塞而导致功能出现异常。那么顺着这个思路,我们就顺藤摸瓜,看看 RingBuffer 里面到底存了啥。聚光灯呢?往这打!
当我们找到 RingBuffer 的时候,不禁倒吸一口凉气,这小小 RingBuffer 居然有 1.61GB 之巨,让我们更近一步到 RingBuffer 的 entries 里面看看,到底是什么样的压力让 RingBuffer の💩竟如此干燥!
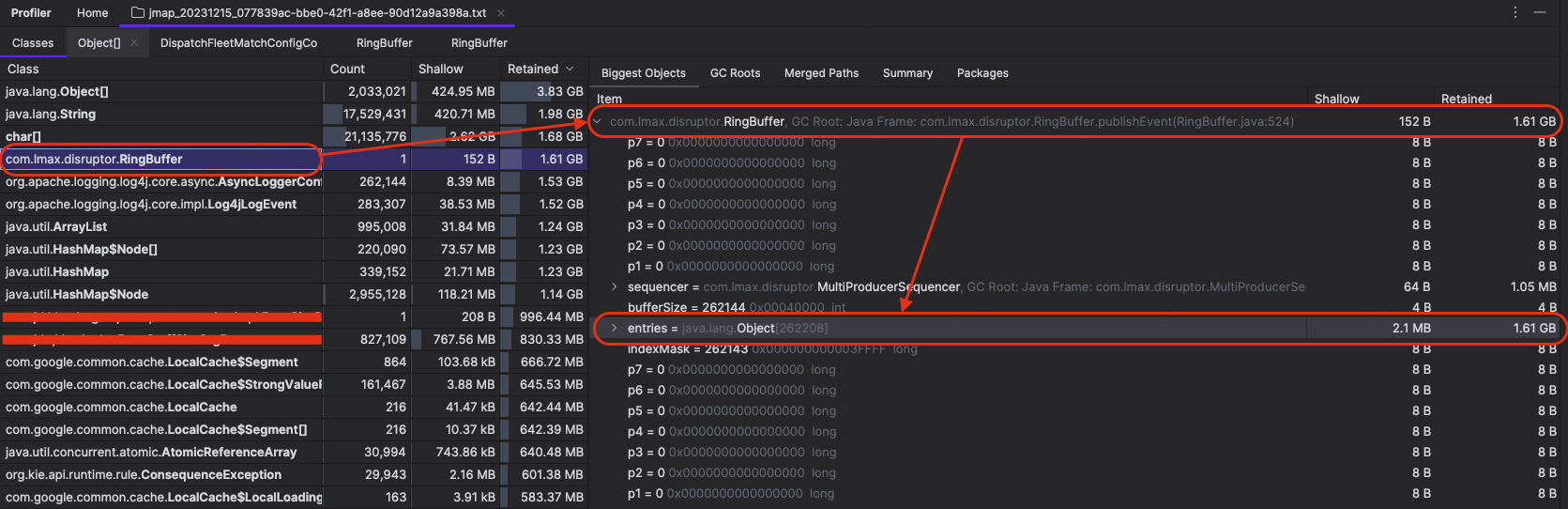
图 4-3-3 RingBuffer 的内存情况
(RingBuffer 的 entries 里面都是 Log4jEventWrapper,该 Wrapper 用于存储一些 RingBuffer 事件在执行的时候所需的必要信息)
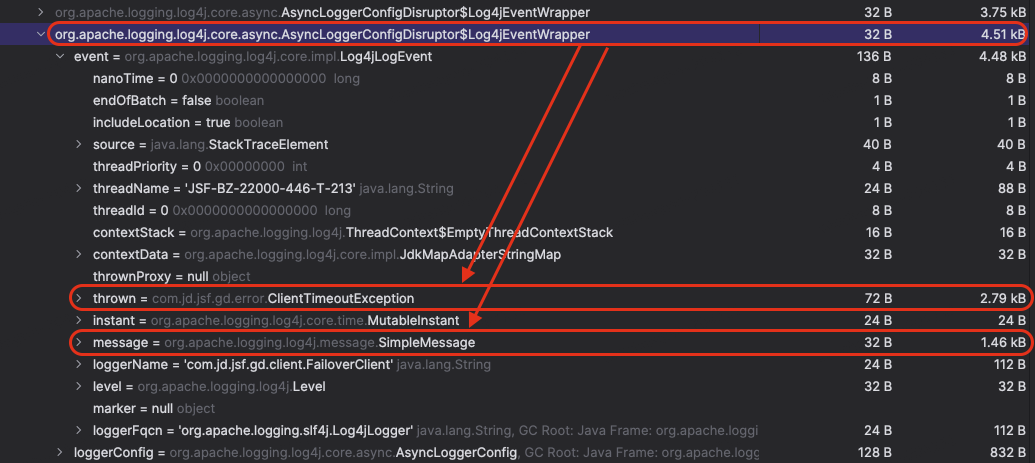
图 4-3-4 RingBufferLog4jEventWrapper 1
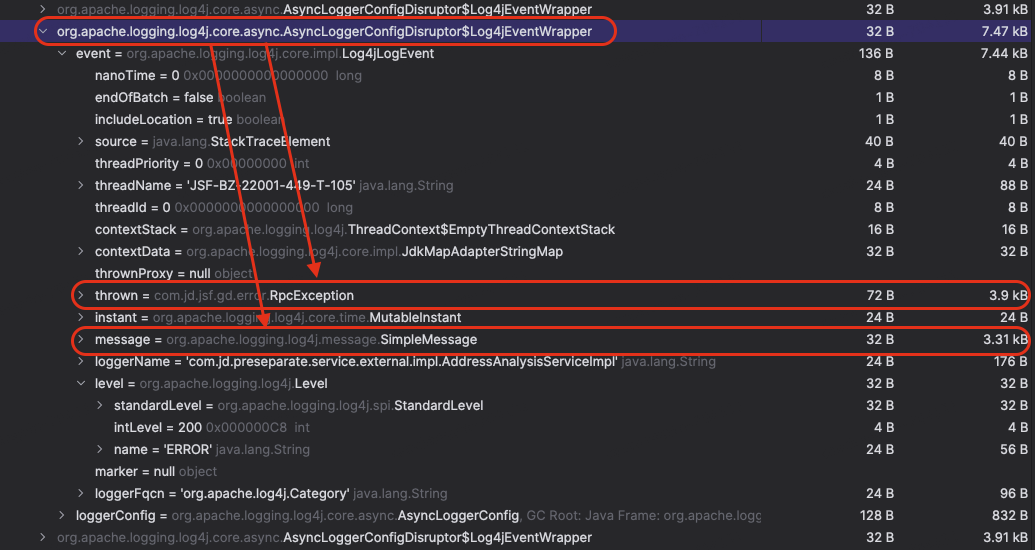
图 4-3-5 RingBufferLog4jEventWrapper 2
在遍历 entries 过程中,我们看到基本上日志级别都是 WARN 和 ERROR,并且含有大量的堆栈信息。排查到这个地方,综合以前了解到的 Log4j2 异步日志打印的相关知识(具体内容我会在下文压测过程说明完成后附上),我们基本上可以确定是当服务端系统出现问题时,生成的大量堆栈信息需要通过 WARN 和 ERROR 日志打印出来,RingBuffer 被填满以后,又触发了锁竞争,由于等待的线程较多,系统中多个业务线程由并行变成了串型,并由此带来了一系列的连锁反应。至此也引出了本文的两位主角【log4j2.asyncQueueFullPolicy】&【log4j2.discardThreshold】。
log4j2.asyncQueueFullPolicy用于指定当日志打印队列被打满的时候,如何处理尚无法正常打印的日志事件,如果不指定的话,默认(Default)是阻塞,建议使用丢弃(Discard)。
log4j2.discardThreshold用于配合 log4j2.asyncQueueFullPolicy 使用,指定哪些日志级别及以下的日志事件可以执行丢弃操作,默认为 INFO,建议使用 ERROR。
排查到这里我们已经定位到日志生产的量的确比较多。但是如果日志打印出现了瓶颈,日志生产的多是一方面,另一方面还要看日志消费的情况是怎样的,如果消费的性能足够高的话,那么即便是日志生产的多,也不会造成日志打印的瓶颈。
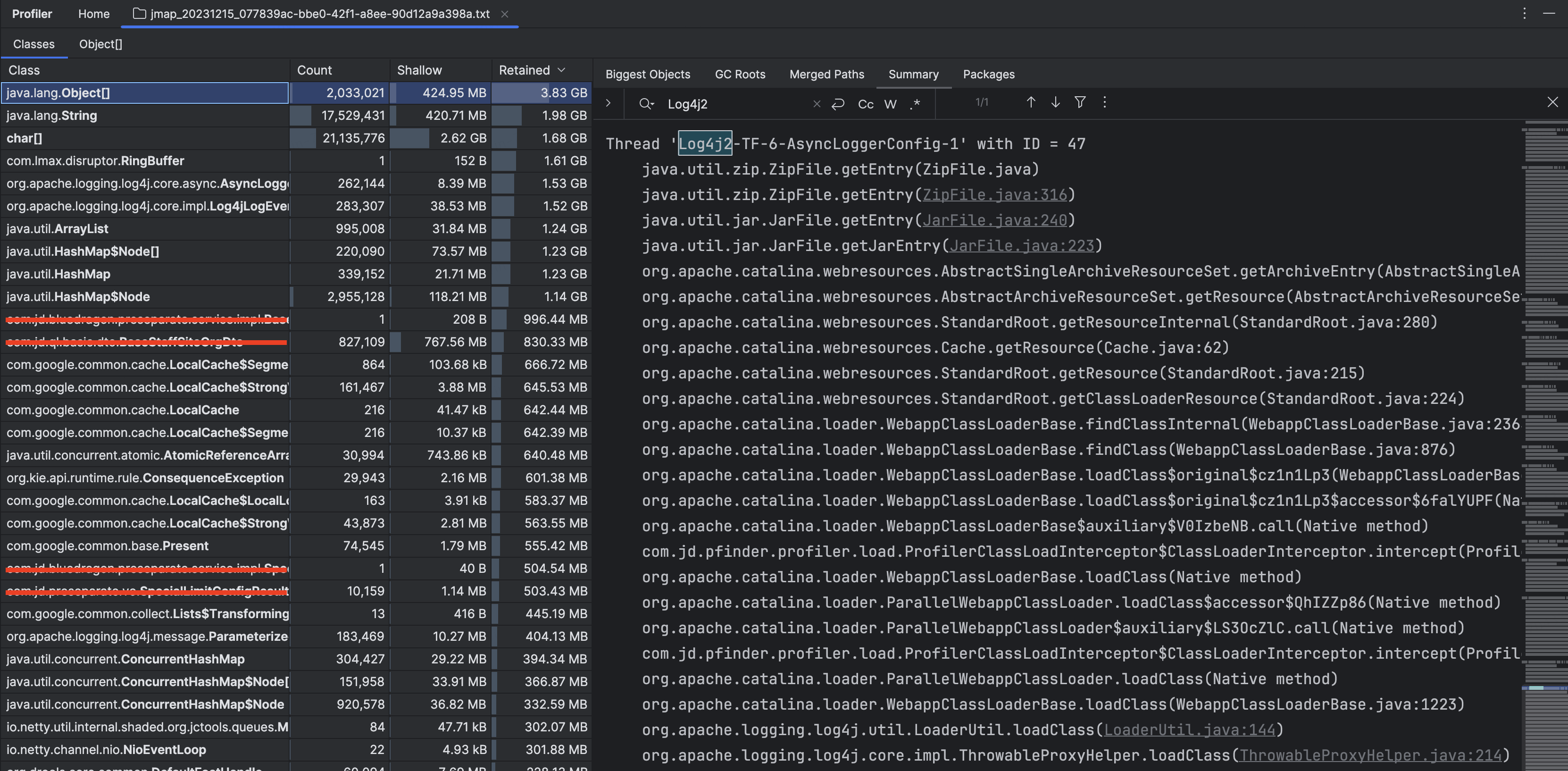
图 4-3-6 Log4j2 日志消费线程状态
比较遗憾的是,我虽然找到了日志消费和日志文件写入的相关线程,但是并不能够足以支持我对于问题时间段内日志的消费出现了瓶颈进行定论。因为我 dump 出的内存信息并未统计出线程在问题时间段内写文件操作的执行次数,想以此来和日常进行比较,看是否是有较大的增量。(抑或是有方法,但是我没找到?我使用的是 IDEA Profiler,如果您有好兵器,请不吝赐教🙏。)
氛围都已经烘托到这个地步了,就此打住可就有些不解风情了,不妨我们用针对性的压测来验证一下我们的想法。
(复现场景)
1.持续性大流量请求到服务端,直至将服务端压垮一段时间(该流程持续时间较长,以下截图仅从服务端机器开始出现问题前较近时间开始截取);
2.服务端启动扩容操作(一倍扩容);
3.服务端操作问题机器下线;
4.若客户端调用服务监控可用率等指标长时间未恢复,则执行客户端重启操作;
5.验证客户端调用服务端服务是否已经恢复,服务端扩容机器流量是否正常。
6.调整日志丢弃级别,重复上述流程进行进行相同流程重复压测(出现问题时客户端系统已经配置 log4j2.asyncQueueFullPolicy=Discard,故此仅将日志丢弃级别作为压测变量)
注:上述 3、4、5 操作并不会持续太长时间,因为流量基本保持不变,如果持续压力会再次将服务端扩容机器打垮,本次压测仅用于验证在服务端扩容以后,客户端机器无法正常请求到服务端新扩容机器的问题,故仅验证客户端能够正常请求到新扩容机器且客户端调用服务短时间内可自行恢复,即视为达到压测目标。
// 日志配置
log4j2.discardThreshold=INFO
压测结果:日志丢弃级别使用 INFO 时, 服务端操作问题机器下线后,客户端调用服务监控可用率长时间无法恢复到 100%,重启客户端机器后恢复;
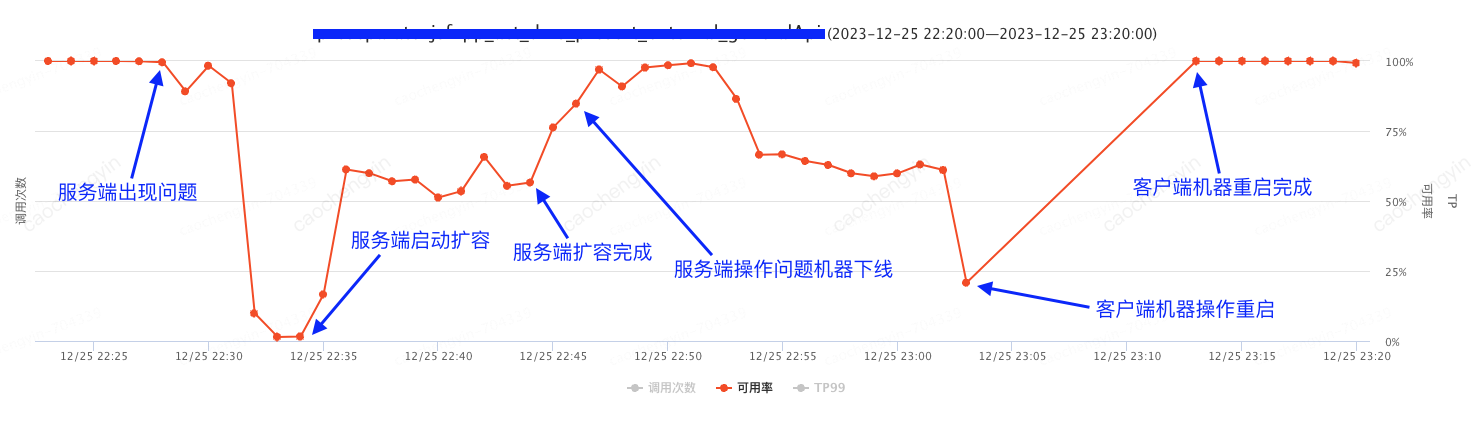
图 5-2-1 压测过程可用率情况

图 5-2-2 压测过程可用率 +TP99+ 调用次数综合情况
// 日志配置
log4j2.discardThreshold=WARN
压测结果:日志丢弃的级别调整到 WARN 后,客户端无需操作,大概 3 分钟左右服务可用率恢复到 95% 左右,大概 8 分钟后可用率恢复至 100%;
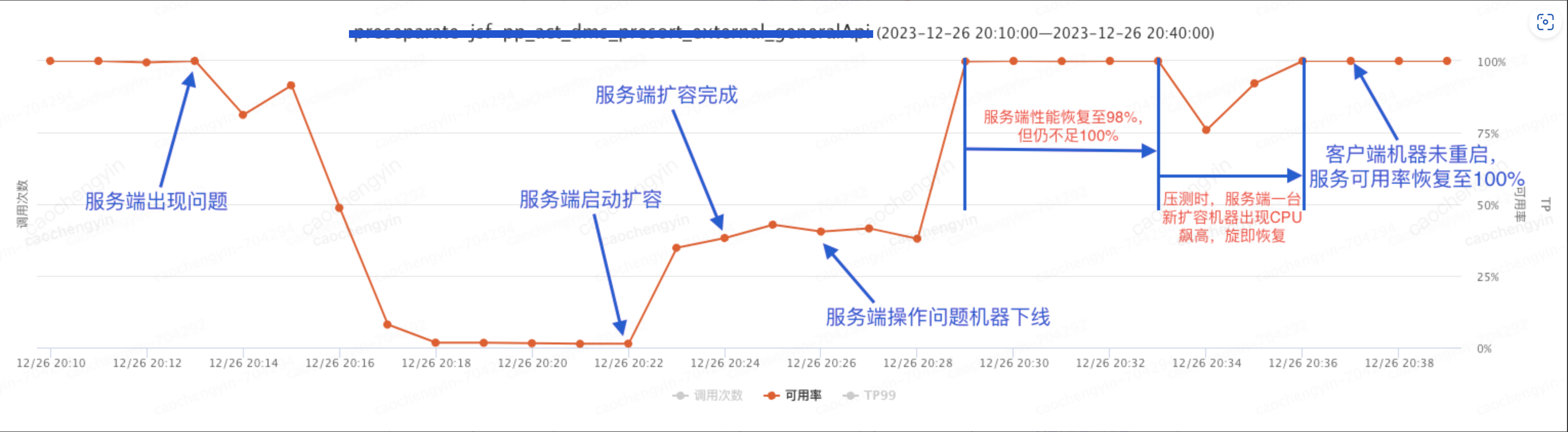
图 5-3-1 压测过程可用率情况
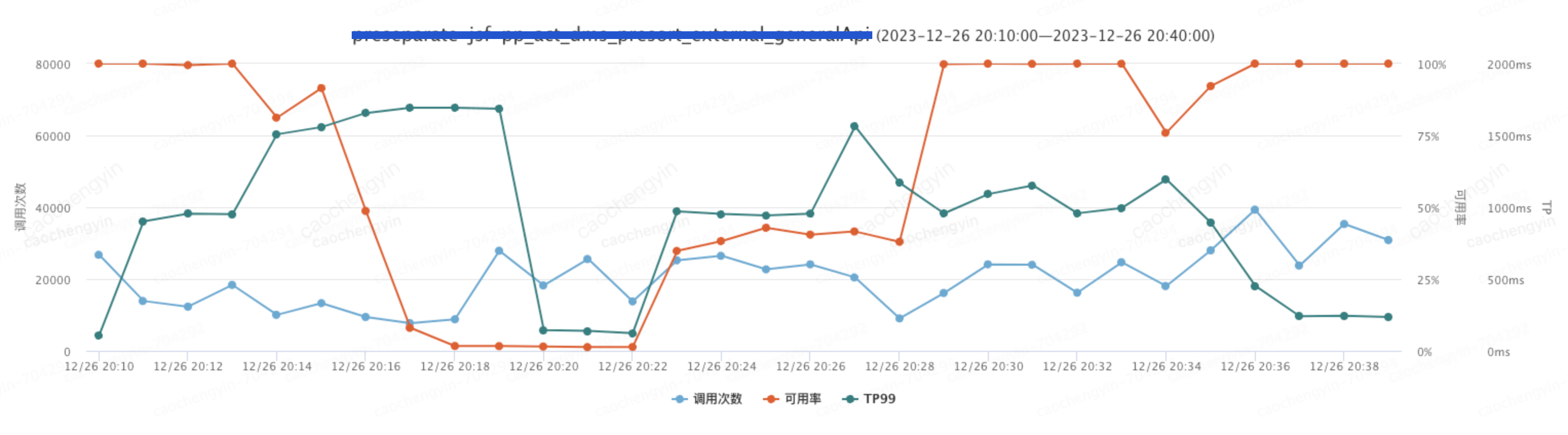
图 5-3-2 压测过程可用率 +TP99+ 调用次数综合情况
// 日志配置
log4j2.discardThreshold=ERROR
压测结果:日志丢弃的级别调整到 ERROR 后,客户端无需操作,在 2 分钟左右服务可用率即可恢复至 100%。
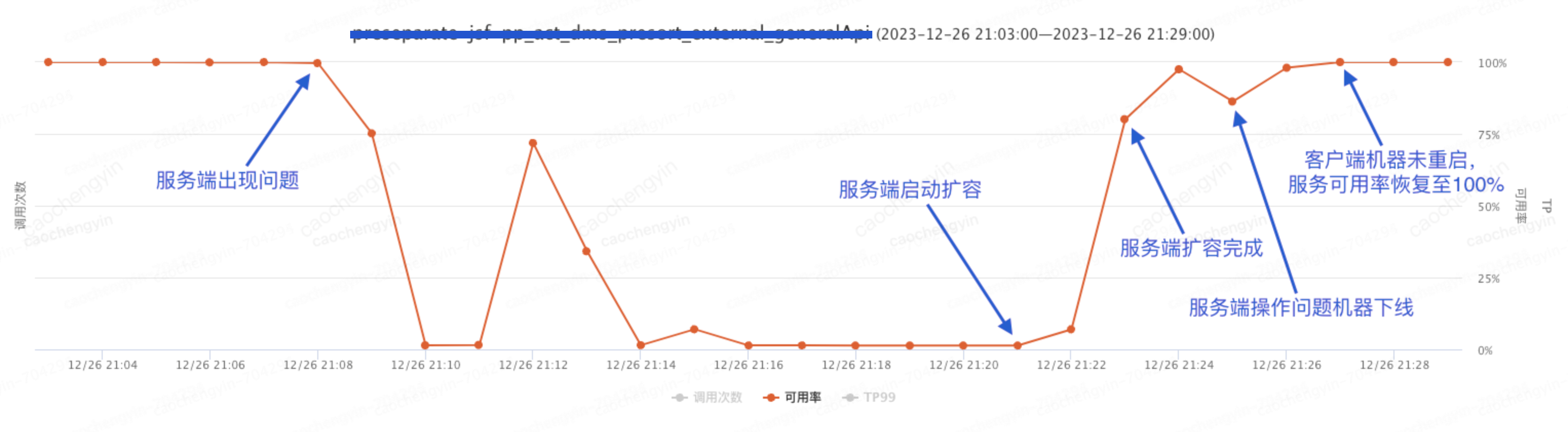
图 5-4-1 压测过程可用率情况
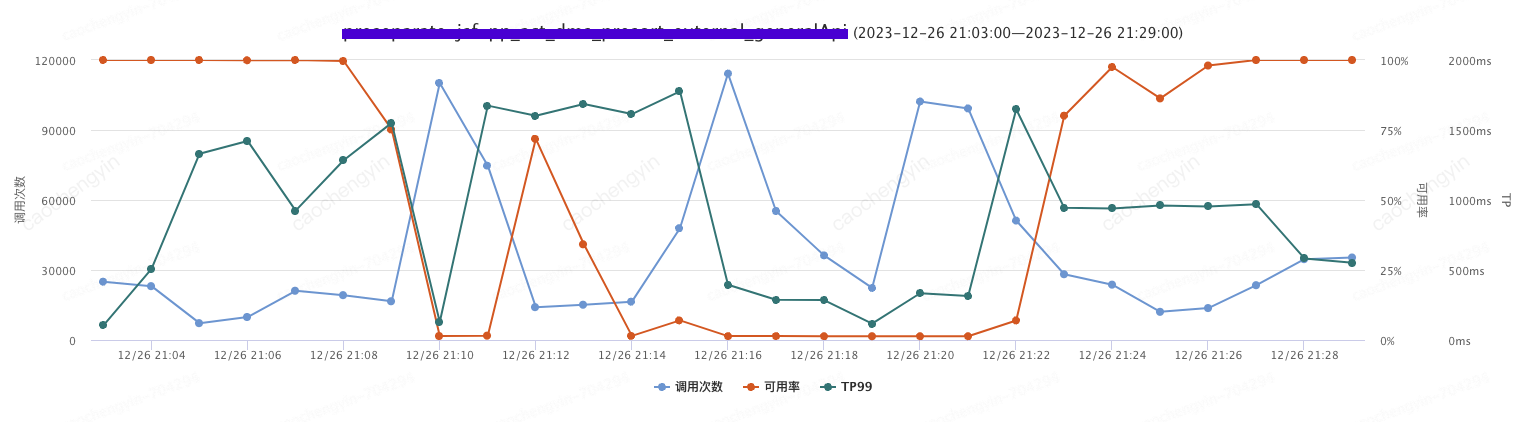
图 5-4-2 压测过程可用率 +TP99+ 调用次数综合情况
// 日志配置
log4j2.discardThreshold=FATAL
压测结果:日志丢弃的级别调整到了 FATAL 后,客户端无需操作,在 2 分钟左右服务可用率即可恢复至 100%,效果与 ERROR 基本相同。
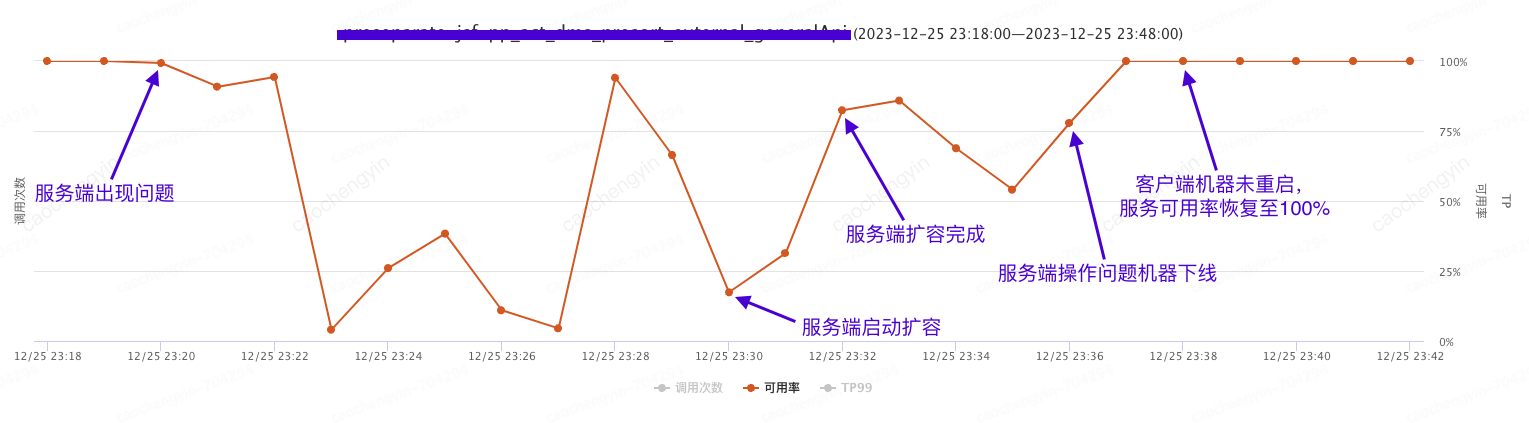
图 5-5-1 压测过程可用率情况
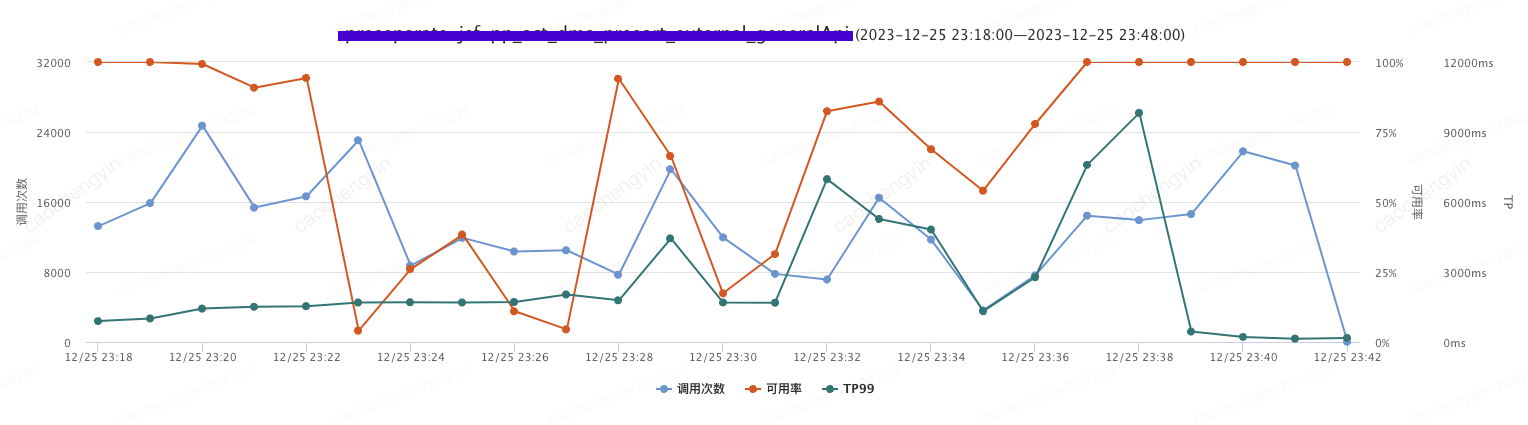
图 5-5-2 压测过程可用率 +TP99+ 调用次数综合情况
下面我们通过一副示意简图来简单介绍一下 Log4j2 使用 Disruptor 的 RingBuffer 进行异步日志打印的基本原理。
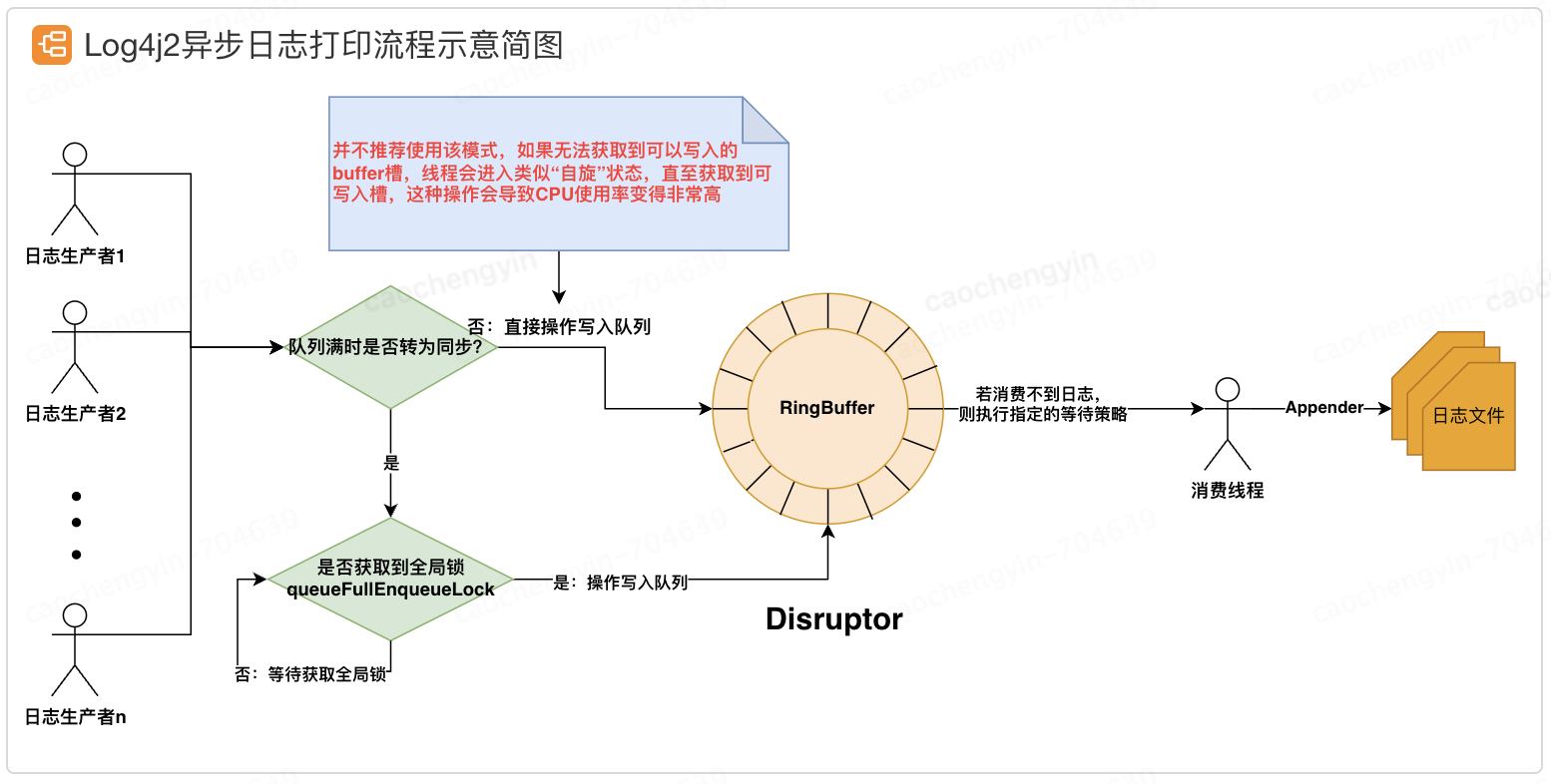
图 5-6-1 Log4j2 异步日志打印流程示意简图
| 配置名称 | 默认值 | 描述 |
| RingBuffer 槽位数量:log4j2.asyncLoggerConfigRingBufferSize(同步&异步混合使用)| 256 * 1024(garbage-free 模式下默认为 4*1024)| RingBuffer 槽位数量,最小值为 128,在首次使用的时候进行分配,并固定大小 |
| 异步日志等待策略:log4j2.asyncLoggerConfigWaitStrategy(同步&异步混合使用)| Timeout (建议设置为 Sleep) | Block:I/O 线程使用锁和条件变量等待可用的日志事件,建议在 CPU 资源重要程度大于系统吞吐和延迟的情况下使用该种策略; Timeout:是 Block 策略的一个变体,可以确保如果线程没有被及时唤醒(awit())的话,线程也不会卡在那里,可以以一个较小的延迟(默认 10ms)恢复; Sleep:是一种自旋策略,使用纳秒级别的自旋交叉执行 Thread.yield() 和 LockSupport.parkNanos(),该种策略可以较好的平衡系统性能和 CPU 资源的使用率,并且对程序线程影响较小。 Yield:相较于 Sleep 省去了 LockSupport.parkNanos(),而是不断执行 Thread.yield() 来让渡 CPU 使用权,但是会造成 CPU 一直处于较高负载,强烈不建议在生产环境使用该种策略 |
| RingBuffer 槽位数量:log4j2.asyncLoggerRingBufferSize(纯异步)| 256 * 1024(garbage-free 模式下默认为 4*1024)| RingBuffer 槽位数量,最小值为 128(2 的指数),在首次使用的时候进行分配,并固定大小 |
| 异步日志等待策略:log4j2.asyncLoggerWaitStrategy(纯异步)| Timeout (建议设置为 Sleep) | Block:I/O 线程使用锁和条件变量等待可用的日志事件,建议在 CPU 资源重要程度大于系统吞吐和延迟的情况下使用该种策略; Timeout:是 Block 策略的一个变体,可以确保如果线程没有被及时唤醒(awit())的话,线程也不会卡在那里,可以以一个较小的延迟(默认 10ms)恢复; Sleep:是一种自旋策略,使用纳秒级别的自旋交叉执行 Thread.yield() 和 LockSupport.parkNanos(),该种策略可以较好的平衡系统性能和 CPU 资源的使用率,并且对程序线程影响较小。 Yield:相较于 Sleep 省去了 LockSupport.parkNanos(),而是不断执行 Thread.yield() 来让渡 CPU 使用权,但是会造成 CPU 一直处于较高负载,强烈不建议在生产环境使用该种策略 |
| 异步队列满后执行策略:log4j2.asyncQueueFullPolicy | Default (强烈建议设置为 Discard) | 当 Appender 的日志消费速度跟不上日志的生产速度,且队列已满时,指定如何处理尚未正常打印的日志事件,默认为阻塞(Default),强烈建议配置为丢弃(Discard)|
| 日志丢弃阈值:log4j2.discardThreshold | INFO (强烈建议设置为 ERROR) | 当 Appender 的消费速度跟不上日志记录的速度,且队列已满时,若 log4j2.asyncQueueFullPolicy 为 Discard,该配置用于指定丢弃的日志事件级别(小于等于),默认为 INFO 级别(即将 INFO,DEBUG,TRACE 日志事件丢弃掉), 强烈建议设置为 ERROR(FATAL 虽然有些极端,但是也可以)|
| 异步日志超时时间:log4j2.asyncLoggerTimeout | 10 | 异步日志等待策略为 Timeout 时,指定超时时间(单位:ms)|
| 异步日志睡眠时间:log4j2.asyncLoggerSleepTimeNs | 100 | 异步日志等待策略为 Sleep 时,线程睡眠时间(单位:ns)|
| 异步日志重试次数:log4j2.asyncLoggerRetries | 200 | 异步日志等待策略为 Sleep 时,自旋重试次数 |
| 队列满时是否将对 RingBuffer 的访问转为同步:AsyncLogger.SynchronizeEnqueueWhenQueueFull | true | 当队列满时是否将对 RingBuffer 的访问转为同步,当 Appender 日志消费速度跟不上日志的生产速度,且队列已满时,通过限制对队列的访问,可以显著降低 CPU 资源的使用率,强烈建议使用该默认配置 |
| 配置源 | 优先级(值越低优先级越高)| 描述 |
| Spring Boot Properties | -100 | Spring Boot 日志配置,需要有【log4j-spring】模块支持 |
| System Properties | 0 | 在类路径下添加 log4j2.system.properties_(推荐)_ |
| Environment Variables | 100 | 使用环境变量进行日志配置,注意该系列配置均以 LOG4J_作为前缀 |
| log4j2.component.properties file | 200 | 在类路径下添加 log4j2.component.properties(其实是【System Properties】的一种配置方式,但是具有较低的优先级,一般用作默认配置)|
以上内容均参考自 Log4j2 官方文档:Log4j – Configuring Log4j 2 (apache.org)
经过上文分析,我们可以将 Log4j2 的异步日志打印优化总结如下:
1.在日志可以丢弃的情况下,推荐使用log4j2.asyncQueueFullPolicy=Discard 和log4j2.discardThreshold=ERROR的组合配置;
2.不要在生产环境使用可以直接与中间件交互的的 Appender,如 KafkaAppender。此类 Appender 一般都会有 ack 机制,与直接打印到日志文件不同的地方便是需要进行网络交互,如果中间件性能出现问题或者网络出现抖动,那么同样也会造成日志阻塞(话分两头,如果必须要使用 KafkaAppender,那么可以考虑将 syncSend 设置为【false】,该配置的作用是指定 Appender 是否需要等待 Kafka Server 的 ack,但是需要注意的是该开关配置需要 Log4j2 版本为 2.8+);
3.Appender 的【immediateFlush】设置为【false】,使用批量日志写入的方式,避免频繁的执行写磁盘操作。
上述三个配置可以保证在极端情况下日志的打印不会成为系统瓶颈,喂系统服下一颗 “定心丸”。
作者:京东物流 曹成印
来源:京东云开发者社区 自猿其说 Tech 转载请注明来源
