虽然一直在吐槽性能测试变得越来越简单(压测的工具越来越多,框架的规范越来越好,可供调优的空间越来越有限,只要合理地使用,性能问题基本上很少,但也架不住有些开发真的乱来,所以性能测试还是有空间的,但已经没必要去组建专职的性能团队了,特殊场景除外,高端的性能测试人员需要足够多的实际场景去培养,中小企业也没必要。性能测试人员能力两级分化极其严重)
但是如果不能掌握基本的性能测试理论和能力,还是不可以的。因为团队还是会偶尔需要你做下性能测试,你也不能错得太离谱。
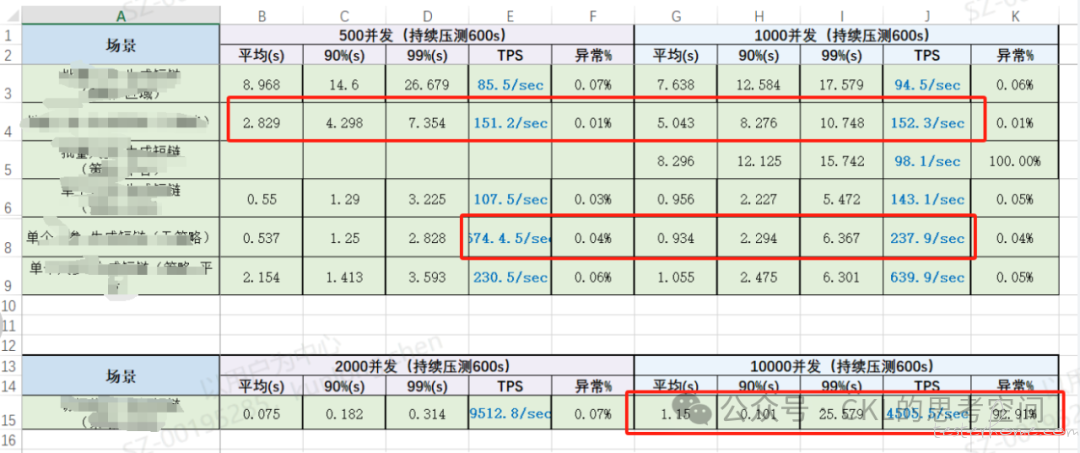
故事,从一份测试结果数据说起~
当你看到上面这份性能测试结果数据,你有什么想法呢?是否正常?
直观来看,这份测试数据至少有三个问题没有澄清:
第二个场景中,用户数增加了一倍(从 500 加到 1000),TPS 基本上没有变化,但是响应时间增加了近一倍?原因有可能是什么?
第五个场景中,用户数增加了一倍(从 500 加到 1000),TPS 断崖式下跌,原因是什么?
最后一个场景中,错误率是 92%,具体是什么异常呢?这组数据其实没有任何意义。
得到的回复是,数据就这样的,测试只负责压数据,其他的事也不会啊~
血压飙升。。。。
其实这也是很多性能测试人员面临的问题,没有具体分析问题的能力,也不要求测试人员去确认是哪个部分组件的性能问题,或者去定位代码级的问题,但是至少,你也需要有分析测试数据并给出合理的结果数据吧。
你会如何回答上面三个问题?能给出可能的原因吗?
先来看一张性能测试人员可能看到吐,但又没太看明白的性能测试曲线拐点图:
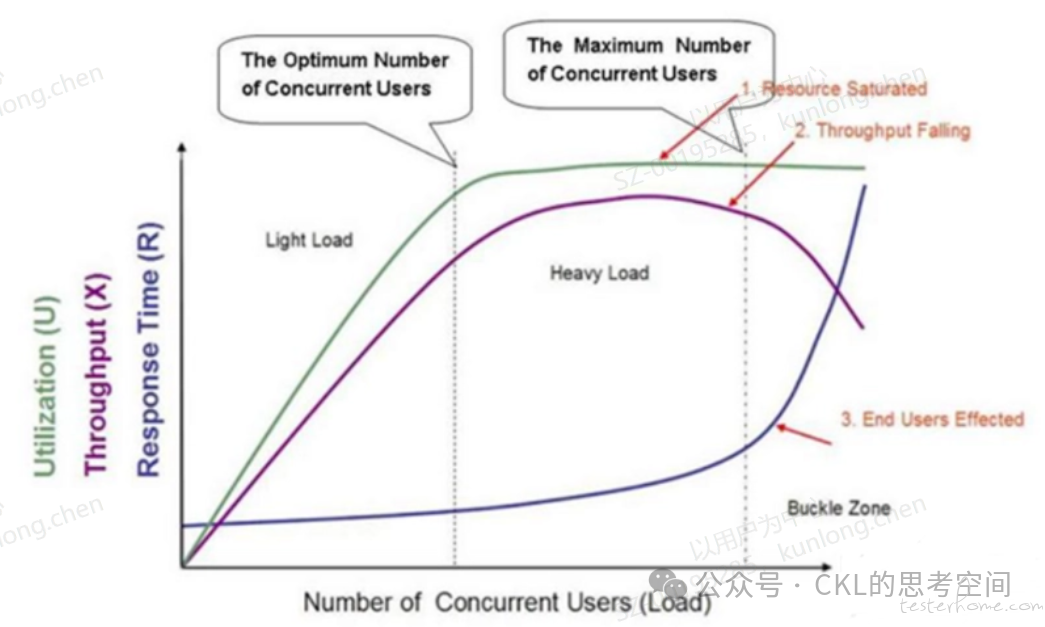
这里先不分析几个 Load 的划分,主要来看看随着用户的增加,Throughput(也可以理解为 TPS)、Utilization(资源使用率)和 RT(响应时间)的变化关系。上图表达的是理论上在性能测试的过程中,这三者的变化关系。如果不符合,那肯定就是某个环节出了问题。
这是性能测试数据分析的第一步,也是性能测试的基本功,需要从这三者的变化关系中,先确认是哪里出了问题。而不是一上来就分析线程数、中间件等等,还没到哪一步。
那么,这三者会有几种常见的问题组合及解决方案呢?直接上结论吧,如下图所示(变化大小指的是斜率的变化):
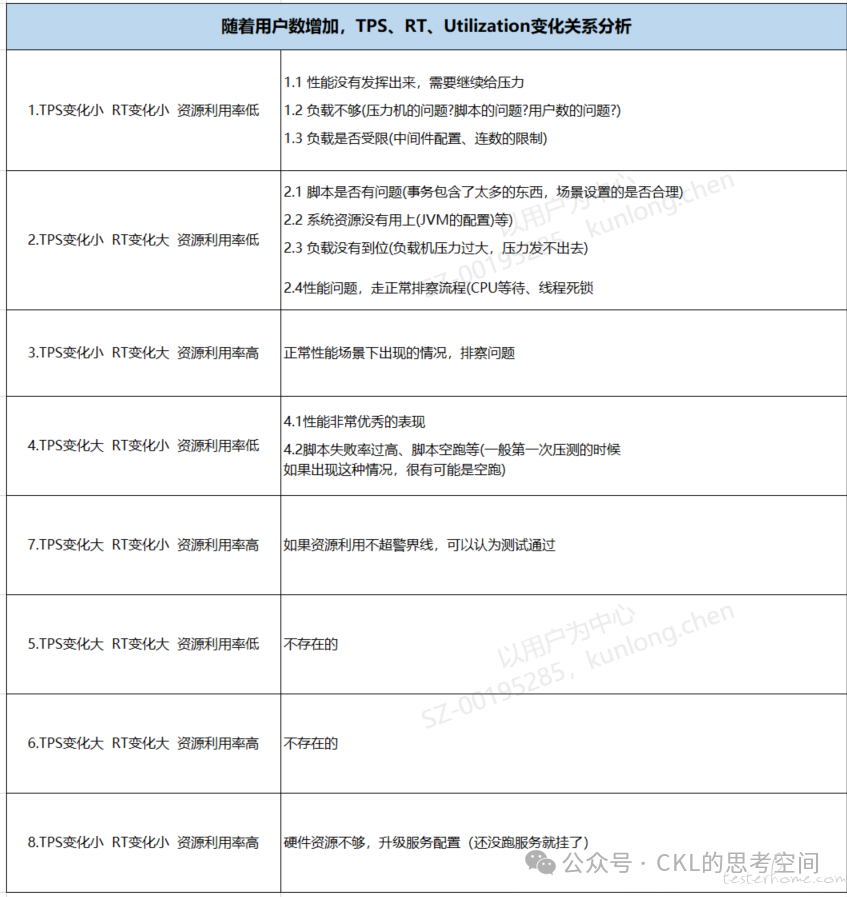
所以,上面的第一个问题就符合场景 2:用户数增加了一倍(从 500 加到 1000),TPS 基本上没有变化,但是响应时间增加了近一倍(TPS 变化小,RT 变化大,资源利用率待确认),所以排查的方向就相对比较明确了,参考表中场景 2 的排查思路。
对于第 2 个问题,TPS 断崖式下跃,99% 的响应时间也增加了近 3 倍,则说明系统出现了明显的性能瓶颈,而且已经过了性能拐点,符合性能测试曲线拐点图中的 Buckle Zone 表现,需要利用二分法找到那个拐点并监控服务资源的情况,定位问题。
针对第三个问题,错误率达到 92%,但是由于是非 GUI 执行,无法看到具体的错误信息,这个如何处理呢?一般情况下,在性能测试脚本中都会设计对应的检查点来确保存在高并发下业务的正确性,所以针对断言失败的情况,我们有必要输出返回信息,在 Jmeter 中,一般会做如下设置:
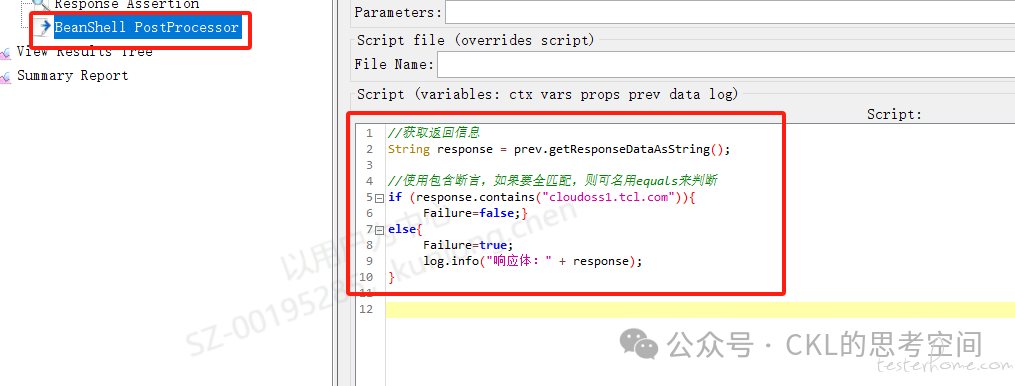
然后在执行脚本时,结合-j 参数来输出错误日志,方便排查问题,而不是一问三不知。
其实这份测试结果还有一个严重的问题,就是压测的情况过少,只压测了 2 种用户数情况,这是远远不够的,因为 2 种情况并不足以说明变化情况,至少需要 3 个及以上,才能有效的观察出 TPS、RT 和资源使用情况的变化关系。
小结:
作为性能测试分析的第一步,我们需要根据 Throughput(也可以理解为 TPS)、Utilization(资源使用率)和 RT(响应时间)的变化关系,找出是压力机的问题、配置的问题还是应用的问题,让这三者的变化关系符合性能测试曲线图。确保你的压测是正确的、合理的,然后再进一步分析性能瓶颈。否则就是在错误的道路上越走越远(在错误的压测数据上做分析没有任何意义)。
