Elasticsearch 作为一个分布式搜索引擎,自身是高可用的;但也架不住一些特殊情况的发生,如:
集群超过半数的 master 节点丢失,ES 的节点无法形成一个集群,进而导致集群不可用;
索引 shard 的文件损坏,分片无法被正常恢复,进而导致索引无法正常提供服务
本地盘节点,多数据节点故障,旧节点无法再次加入集群,数据丢失
针对上述的情况,今天来聊一聊相关的解决方案。
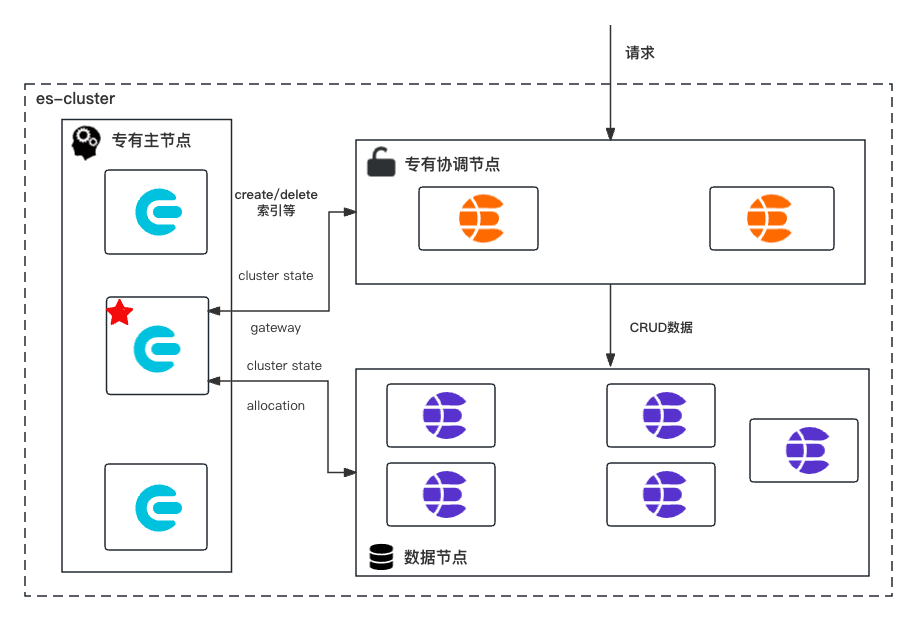
在聊解决方案之前,首先来看一看 ES 集群层面的基本知识,es 的集群组成通常如图 1-1 所示
图 1-1 es 常用集群架构
如图 1-1 所示,为生产环境 es 集群的经典架构,主要由专有主节点、专有协调节点和数据节点组成:
专有主节点 (Master-eligible node): 具有 master 角色的节点,这使其有资格被选为主节点,只存储集群元信息包含 cluster、index、shard 级别的元数据;该种角色节点被选举为 master 之后,将作为整个 ES 集群的大脑,负责维护集群层面的元信息,创建删除索引等工作。该种节点的个数必须为奇数,通常我们固定为 3 个,如果该类节点丢失半数,es 集群将无法维持 es 节点形成一个集群。
专有协调节点 (网关节点): 该种节点不具有任何角色,仅仅用来处理 es 请求;比如(1)将写请求的数据归类转发到数据所属的节点(2)查询请求的二次聚合计算。通常我们也会给该类节点保留ingest 角色,ingest 的主要作用是对数据进行预处理;比如:字段重命名、给数据文档打上指纹和清洗数据等功能主要通过pipeline 能力进行处理
数据节点 (Data node): 存储数据和集群元信息,执行与数据相关的操作,如 CRUD、搜索和聚合。在数据节点上打上不同的属性,可以使其成为 hot、warm、cold 数据节点,在 es7.9 版本之后配置略有不同,但是原理基本不变。
如果没有显示设置节点角色,es 的每个节点都会含有以上三种角色。除此之后还有Remote-eligible node、ml-node和Transform nodes等角色需要显示的配置,节点才会有该角色。
集群完全启动主要包含选举主节点、元信息、主分片、数据恢复等重要阶段;如图 2-1 所示 [1]。

图 2-1 es 集群启动流程
主节点选举的过程,不是本文的重点,而是集群元信息的选举。被选举出的 master 和集群元信息新旧程度没有关系;master 节点被选举出来之后,它所要完成的第一个任务,即是选举集群元信息。
(1)Master 选举成功之后,判断其持有的集群状态中是否存在 STATE_NOT_RECOVERED_BLOCK,如果不存在,则说明元数据已
经恢复,跳过 gateway 恢复过程,否则等待。org.elasticsearch.gateway.GatewayService#clusterChanged
//跳过元数据恢复
if (state.blocks().hasGlobalBlock(STATE_NOT_RECOVERED_BLOCK) == false) {
// already recovered
return;
}
//此处省略部分代码。
//进入gateway恢复过程
performStateRecovery(enforceRecoverAfterTime, reason);
(2)Master 从各个节点主动获取元数据信息。org.elasticsearch.gateway.Gateway#performStateRecovery
# 获取元信息核心代码
final String[] nodesIds = clusterService.state().nodes().getMasterNodes().keys().toArray(String.class);
logger.trace("performing state recovery from {}", Arrays.toString(nodesIds));
final TransportNodesListGatewayMetaState.NodesGatewayMetaState nodesState = listGatewayMetaState.list(nodesIds, null).actionGet();
(3)从获取的元数据信息中选择版本号最大的作为最新元数据;元信息包括集群级、索引级。
## org.elasticsearch.gateway.Gateway#performStateRecovery
public void performStateRecovery(final GatewayStateRecoveredListener listener) throws GatewayException {
# 省略若干行代码
## 进入allocation阶段;
## final Gateway.GatewayStateRecoveredListener recoveryListener = new GatewayRecoveryListener();
## listener为 GatewayStateRecoveredListener
listener.onSuccess(builder.build());
}
(4)两者确定之后,调用 allocation 模块的 reroute,对未分配 的分片执行分配,主分片分配过程中会异步获取各个 shard 级别元数据。
#主要实现方法为如下方法
#org.elasticsearch.gateway.GatewayService.GatewayRecoveryListener#onSuccess
## 主要工作是构建集群状态(ClusterState),其中的内容路由表 依赖allocation模块协助完成,调用 allocationService.reroute 进 入下一阶段:异步执行分片层元数据的恢复,以及分片分配。updateTask线程结束.
ES 中存储的数据:(1)state 元数据信息;(2)index Lucene 生成的索引文件;(3)translog 事务日志。
元数据信息:
nodes/0/_state/*.st,集群层面元信息 MetaData(clusterUUID 、 settings 、templates 等);
nodes/0/indices/{index_uuid}/_state/*.st,索引层面元信息 IndexMetaData( numberOfShards 、mappings 等);
nodes/0/indices/{index_uuid}/0/_state/*.st,分片层面元信息 ShardStateMetaData(version 、indexUUID、primary 等)。
上述信息被持久化到磁盘:持久化的 state 不包括某个分片存在于哪个节点这种内容路由信息,集群完全重启时,依靠 gateway 的 recovery 过程重建 RoutingTable 和 RoutingNode。当读取某个文档时, 根据路由算法确定目的分片后,再从 RoutingTable 中查找分片位于哪个节点,然后将请求转发到目的节点 [1]。
⚠️ 注意:在 es7.0.0 之后 es 的元信息存储方式发生变化;
es7.0.0 之后元信息存储改使用 lucene 的方式存储,见pr50928 Move metadata storage to Lucene)
7.10.2 专有主节点,集群元数据
./
|-- _state
| |-- _39h.cfe
| |-- _39h.cfs
| |-- _39h.si
| |-- node-0.st
| |-- segments_50d
| `-- write.lock
`-- node.lock
6.8.13 专有主节点,集群元数据
./
|-- _state
| |-- global-230.st
| `-- node-2.st
|-- indices
| |-- -hiy4JnoRfqUJHTJoNUt4Q
| | `-- _state
| | `-- state-4.st
| `-- ylJKVlqISGOi8EkpxHE_2A
| `-- _state
| `-- state-6.st
`-- node.lock
⚠️ 注意本文所述的 master 节点个数,假设前提均为 3 个
master 节点是控制整个集群;当该种节点角色丢失过半,由于集群中投票节点永远不可能达到 quorum 无法选主,将无法维持 es 节点形成一个集群;虽然集群无法形成一个集群,但所仍幸 master-eligible 节点存活,我们可以使用如下手段进行处理。
1 修改剩余节点的 elasticsearch.yaml 配置如下,修改 quorum 的个数,然后启动剩余的节点,形成一个新的集群;
discovery.zen.minimum_master_nodes: 1
discovery.zen.ping.unicast.hosts:
- masters-0
2 重建补充之前丢失的 master-eligible 节点,加入集群之后.
3 将集群配置修改为旧的配置,再逐一重启下集群中的节点,先从 master-eligible 开始.
在 es7.0.0 版本之后,由于 es 修改集群的启动配置,新增配置discovery.seed_hosts和cluster.initial_master_nodes;es 集群第一次启动时称为 bootstrap,该过程将配置文件中的 cluster.initial_master_node 作为初始的投票节点Voting configurations,投票节点具有选举 master 和 commit cluster state 的权利,超过半数以上同意即投票成功。如果在集群健康的场景下,我们需要下线超过半数的 master-eligible;则必须首先使用投票配置排除 API 从投票配置中排除受影响的节点。
POST _cluster/voting_config_exclusions?node_names={node_names}
POST _cluster/voting_config_exclusions?node_ids={node_ids}
DELETE _cluster/voting_config_exclusions
但是如果丢失的 master 节点超过半数,则可以使用新的集群处理工具 elasticsearch-node unsafe-bootstrappr37696和 elasticsearch-node detach-clusterpr37979
面对丢失半数 master-eligible,es7.0.0(包含)版本之后的处理步骤如下:
1 使用bin/elasticsearch-node unsafe-bootstrap命令让唯一主节点以不安全的方式改写投票节点,就像重新进行 bootstrap 一样,自己使用持久化的 cluster state 形成一个新集群
2 其他数据节点无法加入新集群因为 UUID 不同 (es 使用 UUID 作为节点和集群的唯一表示,每个节点都会持久化当前集群的 UUID),使用bin/elasticsearch-node detach-cluster命令让节点离开之前的集群
3 启动数据节点和新的 master-eligible 节点 (如下补充两个新的 master-eligible),他会加入新集群中
cluster.initial_master_nodes:
- {master-0}
- {new-master-1}
- {new-master-2}
discovery.seed_hosts:
- {master-ip-0}
- {new-master-ip-1}
- {new-master-ip-2}
1 关闭 security 功能 (如果开启了, 最好先关闭 security 插件功能):
1.1 因为新启动的 master 节点, 没有数据节点 (如果只配置了一个 master 的角色), security 插件的初始化无法完成, 各类接口不好调用
1.2 如果给新启动的 master 节点, 配置了 master and data 角色, 则 security 插件会初始化成功. 会插入 index, 但是这个 index 会和原来的 data 节点上保存的冲突. 不知道怎么解.
elastic 官方xpack-security;关闭鉴权:xpack.security.enabled:false
2 启动足够的新 master-eligible 节点形成一个新集群.
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts:
- {new-masters-1}
- {new-masters-2}
- {new-masters-3}
3 修改数据节点的为新 master 的地址,并且删除掉节点上的_state(因为新集群的 cluster UUID 不一致),同上
4 启动数据节点,数据被恢复加入到集群
已经没有 cluster state 了,唯一的希望是数据节点上的 index 数据;恢复方式借助elasticsearch-node工具
1 关闭 security 功能 (如果开启了, 最好先关闭 security 插件功能),原因同上
2 启动足够的新 master-eligible 节点形成一个新集群
cluster.initial_master_nodes:
- {new-master-0}
- {new-master-1}
- {new-master-2}
discovery.seed_hosts:
- {new-master-ip-0}
- {new-master-ip-1}
- {new-master-ip-2}
3bin/elasticsearch-node detach-cluster命令让数据节点离开之前的集群
./bin/elasticsearch-node detach-cluster
------------------------------------------------------------------------
WARNING: Elasticsearch MUST be stopped before running this tool.
------------------------------------------------------------------------
You should only run this tool if you have permanently lost all of the
master-eligible nodes in this cluster and you cannot restore the cluster
from a snapshot, or you have already unsafely bootstrapped a new cluster
by running `elasticsearch-node unsafe-bootstrap` on a master-eligible
node that belonged to the same cluster as this node. This tool can cause
arbitrary data loss and its use should be your last resort.
Do you want to proceed?
Confirm [y/N] y
Node was successfully detached from the cluster
4查询 dangling 索引,GET /_dangling, 改 api 引入 es7.9 版本于pr58176
5 启动数据节点并使用Import dangling indexAPI将 index 数据 import 到 cluster state 中 (官方推荐,es7.9 版本之后). 或者 配置gateway.auto_import_dangling_indices: true引入于 es7.6 版本pr49174(es7.6.0-7.9.0 可用该配置,在 7.6 版本之前不需要配置默认加载 dangling 索引)并启动数据节点
POST /_dangling/{index-uuid}?accept_data_loss=true
6 导入完成之后,索引 recovery 之后即可进行读写
注意
Q1: 为什么 7.6.0 之后需要配置,才能处理悬空索引(dangling index)才能让数据加入新集群,7.6.0 之后没有悬空索引吗?
A1: 其实也是有的,只不过在 es2 版本将配置移除(对应pr10016),默认自动加载 dangling index(es2.0-es7.6); 具体实现于org.elasticsearch.gateway.DanglingIndicesState#processDanglingIndiceses7.6 再次引入 dangling 配置,es7.9 引入dangling index rest apiQ2: 什么是 dangling 索引?
A2: 当一个节点加入集群时,如果发现存储在其本地数据目录中的任何分片(shard)不存在于集群中,将认为这些分片属于 “悬空” 索引。悬空索引产生的场景(1)在 Elasticsearch 节点离线时删除了多个cluster.indices.tombstones.size索引,节点再次加入集群集群(2)master 节点丢失,数据节点重新加入新的集群等
数据节点灾难故障之后,无法恢复加入集群;可将数据物理复制到新的节点,然后按照 master 节点丢失的方式,将数据节点加入集群即可。
查看索引分片为什么无法分配,POST _cluster/allocation/explain
如果分片数据正常,那么我们可以尝试重试分配分片任务;POST _cluster/reroute?retry_failed
获取索引的 shard 在那些节点上,使用_shard_stores api
GET indexName1/_shard_stores
使用cluster reroute重新分配
# 尝试分配副本
POST /_cluster/reroute
{
"commands": [
{
"allocate_replica": {
"index": "{indexName1}",
"shard": {shardId},
"node": "{nodes-9}"
}
}
]
}
如果是主分片无法分配,可以尝试如下命令进行分配
POST /_cluster/reroute
{
"commands": [
{
"allocate_stale_primary": {
"index": "{indexName1}",
"shard": {shardId},
"node": {nodes-9},
"accept_data_loss": true
}
}
]
}
如果主分片确实是无法分配,只能选择丢失该分片的数据,分配一个空的主分片
POST /_cluster/reroute
{
"commands": [
{
"allocate_empty_primary": {
"index": "{indexName1}",
"shard": {shardId},
"node": "{nodes-9}",
"accept_data_loss": true
}
}
]
}
es5.0 版本之前参考; https://www.elastic.co/guide/en/elasticsearch/reference/2.4/cluster-reroute.html
shard-tooles6.5 版本引入,该操作需要 stop 节点
elasticsearch-shard 工具 es6.5 版本引入pr33848
elasticsearch-shard remove-corrupted-data 的 es7.0.0 引入pr32281
bin/elasticsearch-shard remove-corrupted-data --index {indexName} --shard-id {shardId}
## 示列:修复索引twitter的0号分片
bin/elasticsearch-shard remove-corrupted-data --index twitter --shard-id 0
## 如果--index和--shard-id换成索引分片目录参数--dir,则直接修复data和translog
bin/elasticsearch-shard remove-corrupted-data --dir /var/lib/elasticsearchdata/nodes/0/indices/P45vf_YQRhqjfwLMUvSqDw/0
修复完成之后,启动节点,如果分片不能够自动分配,使用 reroute 命令进行 shard 分片
POST /_cluster/reroute{
"commands":[
{
"allocate_stale_primary":{
"index":"index42",
"shard":0,
"node":"node-1",
"accept_data_loss":false
}
}
]}
5 版本之前可以通过索引级别配置,进行修复
index.shard.check_on_startup: fix ,该配置在 es6.5 版本移除pr32279
修复 translog 操作,需要 stop 节点。
修复工具 elasticsearch-translog es5.0.0 引入pr19342
elasticsearch-shard remove-corrupted-data translog 的 es7.4.1 开始引入,pr47866elasticsearch-shard 可以直接清除 translog,也可以像上文中指定--dir 那样进行修复 translog
bin/elasticsearch-shard remove-corrupted-data --index --shard-id --truncate-clean-translog
## 示列:修复索引twitter的0号分片
bin/elasticsearch-shard remove-corrupted-data --index twitter --shard-id 0 --truncate-clean-translog
清除完成之后使用 cluster reroute 进行恢复
5 版本之前可以通过索引级别配置,进行修复
index.shard.check_on_startup: fix ,该配置在 es6.5 版本移除pr32279
segments_N文件丢失该种场景的文件损坏是最难修复的;官方还未提供工具,我们正在自己调研中
[1] elasticsearch 集群启动流程
[2]https://www.elastic.co/guide/en/elasticsearch/reference/7.9/dangling-indices-list.html
[3]https://www.elastic.co/guide/en/elasticsearch/reference/7.10/node-tool.html
作者:京东科技 杨松柏
来源:京东云开发者社区 转载请注明来源
