在京东家居事业部,线索 CRM 系统扮演着至关重要的角色,它作为构建家居场景核心解决方案集的首要环节,肩负着获客和拓展业务的重要使命。然而,随着业务的不断扩张和市场需求的日益增长,系统原有的架构开始显露出诸多不适应之处,如架构设计不再清晰,代码存在过量冗余,核心的读写接口响应时间长等问题,这些问题严重制约了业务的敏捷性和快速发展。鉴于这一状况,系统的性能优化和调整势在必行,以确保其能够更好地支撑业务的快速发展需求。
系统中存在五个主要的线索创建渠道,它们的处理流程高度相似,但是代码却是分散冗余的。每当有新渠道需要接入时,之前的做法都是从已有代码中复制粘贴并做小幅调整,缺乏抽象和封装,导致了代码的高度重复,增加了维护的难度和出错的风险。
比如当时我们为了支持多供应商这个需求,需要对线索分派商家的逻辑进行更改,由于这段逻辑分散在多处,同时由于测试对底层实现的不了解,可能会误认为只需要测试一个渠道就能覆盖基本场景,就有可能导致非必要的线上问题的产生。
在线索创建过程中,由于业务的复杂性需要执行 10 来个子流程以及开发过程中的不规范导致的对线索主数据的不必要的重复更新、重复同步 ES 等问题,接口性能较慢,tp99 将近 3000ms。
线索创建主数据,分配商家以及匹配到重复规则时需要新增运营回访记录,这些流程都涉及到对数据库的写操作,但是这些写入没有放在同一事务中,导致了某个子流程写入失败时存在数据一致性问题。
我们的优化目标是对线索提交流程统一封装和抽象,提高系统的可维护性和扩展性。同时降低新渠道接入的时间成本,提高接口性能和响应,保证接口在复杂情况下的正确性。
我们首先对当前所有渠道的线索创建流程进行了全面的梳理,将线索的创建流程抽象化,并定义出一套标准化的流程模板。具体来说一个线索的创建包括以下流程:
(1) 入参校验
(2) 查询三级渠道
(3) 验证三级渠道开关
(4) 根据入参封装要创建的线索实体
(5) 线索是否重复的规则校验
(6) 数据库保存线索和异构到 ES
(7) 读取配置规则以及后续的同步京音系统
(8) 将新线索分配到对应的商家
(9) 短信消息和京麦消息通知商家
(10) 根据线索和分配的商家信息为用户创建装修档案
通过分析发现,对于不同渠道的线索创建过程来说,最大的差异点在于流程 (1) 和 (2), 对于流程 (3)-(10) 基本相似。
这些流程虽然在逻辑上紧密相连,但是对于线索创建这一业务来说最核心的流程是流程 (6) 及之前的流程,至于流程 (7)-(10) 则是线索创建后的附属操作,这些附属操作涉及到和外部门系统间复杂的交互,占用了大量资源并影响到核心流程的响应速度。
因此我们聚焦于线索创建这一核心流程,和从职责单一的角度考虑,我们将整个线索的常见进行拆分:
第一 核心流程 - 线索的创建。
第二 线索分配商家以及之后的通知操作
第三 为分配商家后为用户创建对应的装修档案
这三个创建流程通过京东自研消息 JMQ 进行串联,解耦了线索创建和附属操作的执行。通过异步处理附属操作,附属操作的耗时不会阻塞核心流程的执行,减少了对核心流程的干扰,从而大大提升了系统的响应性和吞吐量。
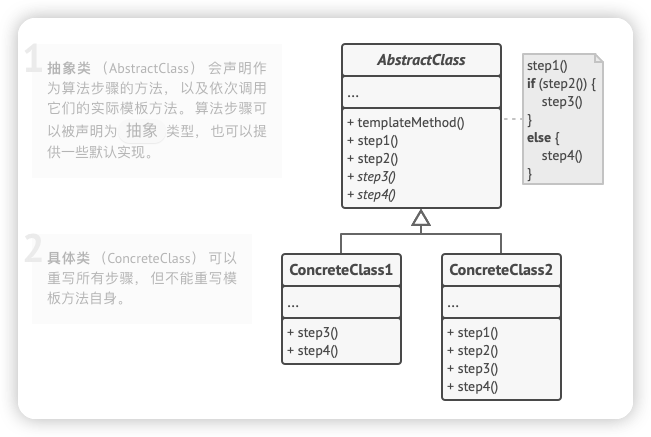
定义: 模板方法设计模式是一种行为设计模式,它在一个方法中定义了一个算法的骨架,将一些步骤的执行延迟到子类中。这样,子类可以在不改变算法结构的情况下重新定义算法的某些特定步骤。
通用类图:
示例代码:
public abstract class Game {
// 模板方法,定义算法骨架
public final void play() {
initialize();
startPlay();
endPlay();
}
// 需要子类实现的方法
abstract void initialize();
abstract void startPlay();
abstract void endPlay();
}
public class Cricket extends Game {
@Override
void initialize() {
System.out.println("Cricket Game Initialized! Start playing.");
}
@Override
void startPlay() {
System.out.println("Cricket Game Started. Enjoy the game!");
}
@Override
void endPlay() {
System.out.println("Cricket Game Finished!");
}
}
public class Football extends Game {
@Override
void initialize() {
System.out.println("Football Game Initialized! Start playing.");
}
@Override
void startPlay() {
System.out.println("Football Game Started. Enjoy the game!");
}
@Override
void endPlay() {
System.out.println("Football Game Finished!");
}
}
public class TemplateMethodPatternDemo {
public static void main(String[] args) {
Game game = new Cricket();
game.play();
System.out.println();
game = new Football();
game.play();
}
}
在这个例子中,Game是一个抽象类,定义了游戏的模板方法play()。Cricket和Football是具体的游戏,它们实现了Game类的抽象方法,以提供各自的游戏初始化、开始和结束的具体实现。
具体到我们系统, 流程 1 到 10 是创建线索的骨架抽象和定义。对于骨架中的子流程,我们识别出易变部分(步骤 1 和 2)和 不易变的部分(步骤 3 至 6)。易变部分需要交给子类去实现,不易变部分则需要统一实现。
对于入参校验和查询三级渠道这两个流程来说,每个渠道都存在独有的逻辑,比如,心愿单渠道需要校验心愿单类型和来源 ID 必传,而投放助手渠道则需校验投放单号必传;多阶段订单渠道是通过 SKU 来查询三级渠道,而市场部渠道则是通过媒体账号 ID 来查询。
因此我们对于这两个流程定义了抽象方法,并将实现细节交个具体渠道的负责。
对于线索创建流程中的不易变部分,我们实现了统一的处理逻辑,如三级渠道开关验证、线索归集信息封装、重复规则校验、数据库保存以及异构到 ES 等流程。
同时对于所有需要数据库变更的操作放到一个事务中,保证了写入的同时成功或失败。
通过上文介绍, 编码大体实现如下:
//获取三级渠道
protected abstract ChannelThreeDto getChannel(ClueDTO clueDTO);
//前置状态校验
protected abstract boolean preConditionCheck(ClueDTO clueDTO);
public ResultDto<Boolean> submit(ClueDTO clueDTO) {
//1.前置状态校验
if (!preConditionCheck(clueDTO)) {
return ResultDto.getFailedResult(ResultCodeEnum.SERVICE_ERROR.getMsg(), ResultCodeEnum.SERVICE_ERROR.getCode());
}
//2.获取三级渠道
ChannelThreeDto channelThreeDto = getChannel(clueDTO);
//3.确认渠道开关是否开启
if (!checkChannel(channelThreeDto)) {
return ResultDto.getFailedResult(ResultCodeEnum.SERVICE_ERROR.getMsg(), ResultCodeEnum.SERVICE_ERROR.getCode());
}
//4.线索重复校验
Boolean isRepeat = checkClueRepeat(clueDTO, channelThreeDto);
if (isRepeat) {
return ResultDto.getFailedResult(ResultCodeEnum.SERVICE_ERROR.getMsg(), ResultCodeEnum.SERVICE_ERROR.getCode());
}
//5.封装线索实体对象
ClueManageDto clueManageDto = buildClueManage(clueDTO, channelThreeDto);
//6.数据清洗规则检查
ClueVisitDto clueVisitDto = clueDataWash(clueManageDto, channelThreeDto);
if (!ObjectUtils.isEmpty(clueVisitDto)) {
clueManageDto.setClueStatus(ClueStatusEnum.INVALID.getCode());
}
//7.数据库保存
boolean result = saveClueManage(clueManageDto, clueVisitDto);
//8.发送线索创建通知,执行之后的线索分配商家等操作
sendClueMessage(clueDistributionDTO);
return ResultDto.getSuccessResult(result, ResultCodeEnum.SUCCESS.getCode());
}
通过引入模板方法的设计模式、异步拆分以及优化事务管理策略,创建线索的系统架构得到了根本性的改进。 我们不仅提高了代码的复用率,降低了新渠道接入的成本,也极大地提升了系统的可维护性和扩展性。
现在,新渠道的接入变得更加快捷和灵活,从之前新渠道接入耗时 6 人/天降低到 2 人/天左右;同时线索创建的响应时间也从之前的 3000ms 降到现在的 250ms 左右。
在竞争激烈的市场环境中,CRM 系统不仅需要准确无误地收集用户的客资信息,更重要的是要实现对这些宝贵信息的快速响应和有效跟进。用户留下联系方式的瞬间,往往是他们对产品或服务兴趣最浓厚的时刻,我们需要快速响应,抢占先机,才有可能增加用户转化为客户的可能性,因此对于核心接口的性能有较高的要求。
但是当前系统在处理线索创建、分配商家,状态变更以及商家反馈等核心流程上存在接口性能不理想的问题,比如商家反馈线索 tp99 耗时 2000ms, 分配商家耗时 1500ms。
在每个核心流程中,系统会进行两项重要的操作:
1.更新数据库:将业务操作的结果持久化到数据库中。
2.数据同步到 ES:将变更的数据同步到两个 ES 集群中(一个供运营端查询,另一个供商家端查询适用)
传统同步机制是在业务逻辑操作完成后立即进行数据同步。这种同步方式虽然简单直接,但存在几个缺点:
•性能瓶颈:同步操作耗时,导致接口响应时间增长,影响用户体验。
•复杂度增加:业务逻辑与数据同步逻辑耦合,增加了代码的复杂度和维护难度。
•扩展性受限:随着业务增长,同步操作成为系统扩展的瓶颈。
针对上述问题,我们采取了一系列措施来优化系统性能,核心策略是将数据同步到 ES 的过程异步化。
1. 订阅 Binlake 变更
我们将业务逻辑操作和数据同步到 ES 的过程分离。业务接口只负责业务逻辑的变更和数据库的更新,而数据同步到 ES 的操作,通过订阅 Binlake 变更事件来异步执行。
2. 处理变更消息
通过订阅线索主数据和线索分配商家数据的变更消息,封装接口将线索主数据和分配商家信息同步到 ES。值得注意的是,为了避免数据库变更在 JMQ 中的乱序性以及可能带来的数据被错误覆盖的问题,我们只关注消息中的哪个线索单号发生了变化,而不关注具体的变更细节,通过线索单号反查数据库的方式,将最新的数据同步到 ES。
3. 合并更新和统一事务
在原来的线索分配商家以及商家反馈线索接口中,存在对同一个表反复更新并且多次同步 ES 的问题,通过底层重构,我们把所有的 DML 操作合并到一个事务中,减少更新次数的同时保证了数据的正确性。
4. 非核心流程异步化
把原来线索反馈商家接口中的非核心流程异步化。在商家反馈线索状态后需要触发回流操作,回流操作本身就是一个非常耗时的操作,经常导致用户反馈接口超时,但是回流本身是用户不关注的,用户只关注他反馈的动作是否完成。因此我们对回流进行异步化,反馈线索接口现在只处理线索状态的更新,回流则是通过发送 JMQ 消息的方式异步处理来减少用户等待时间。
经过优化,线索系统的性能得到了显著提升:
1. 接口响应时间明显缩短:
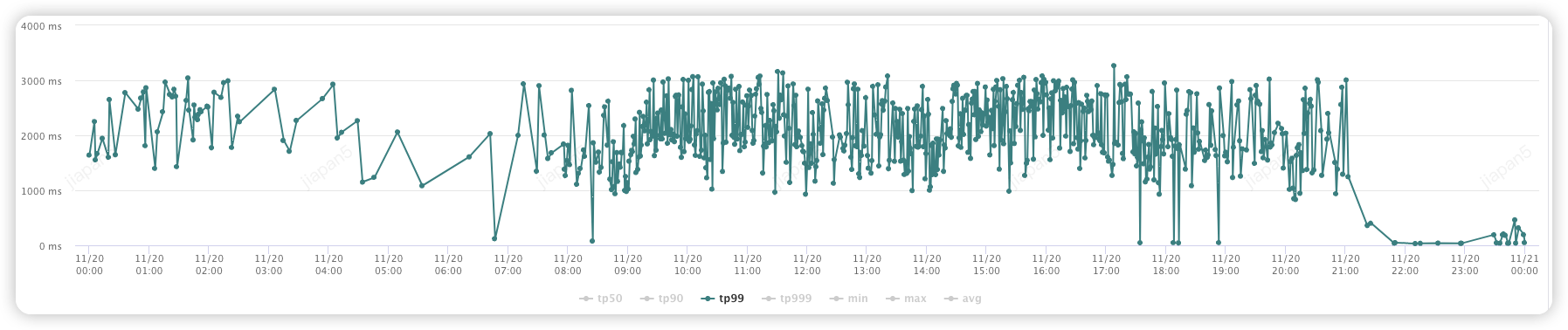
(1) 线索提交 (投放助手渠道):
优化前:(2000-4000ms)
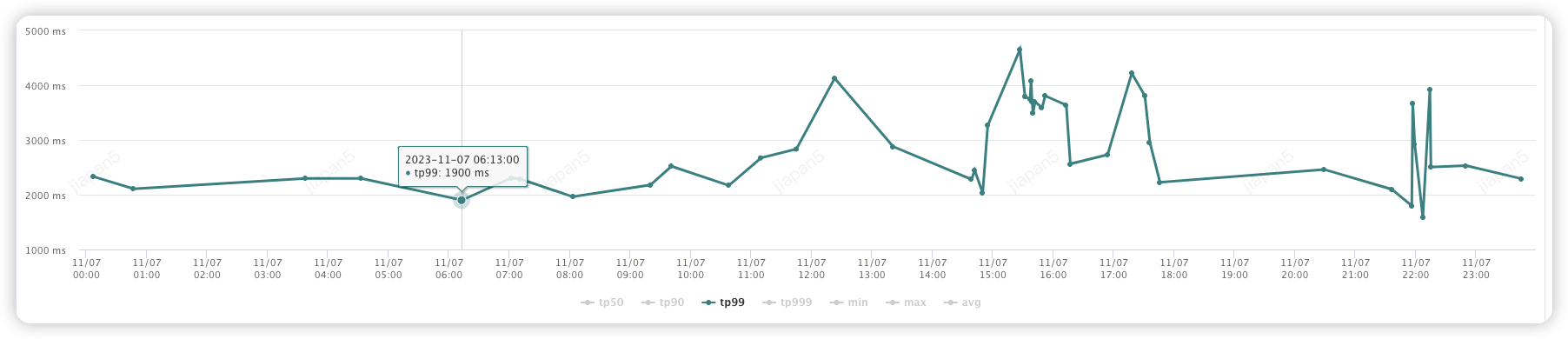
优化后:(100-300ms)
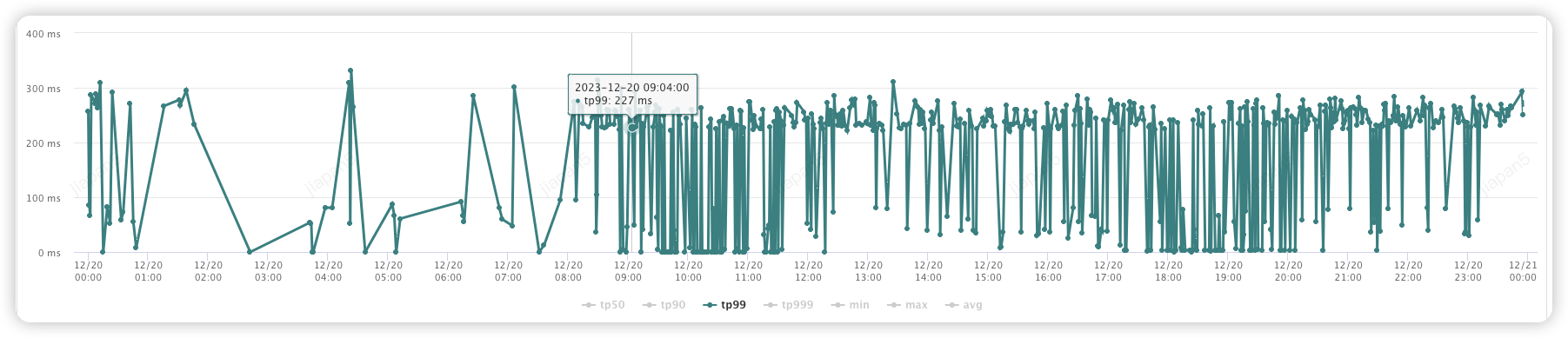
(2) 线索分配商家接口:
优化前:(1000-2000ms)
优化后:(100-400ms)
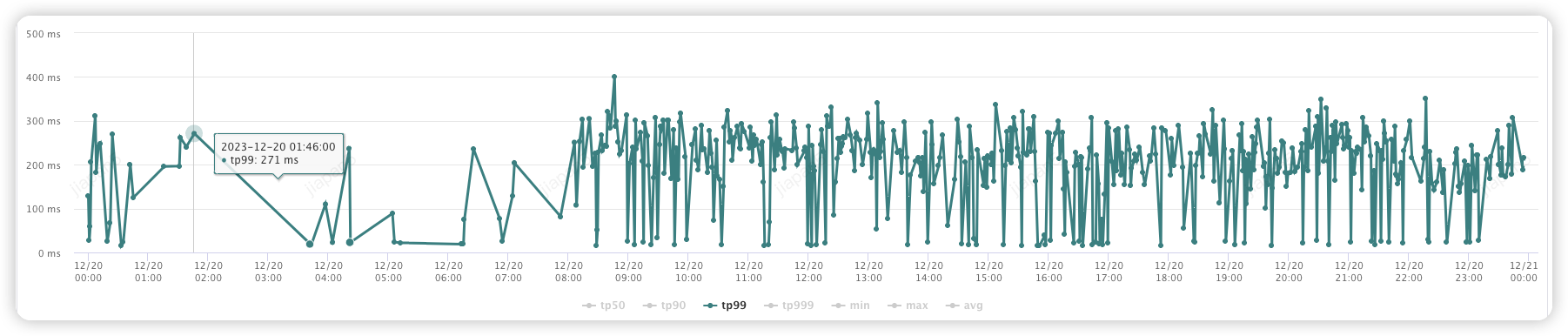
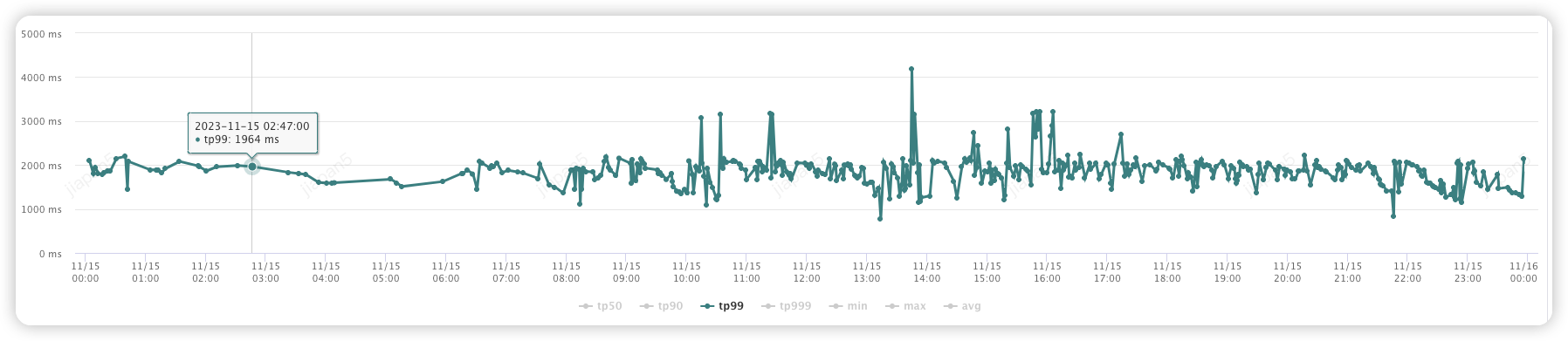
(3) 商家反馈线索接口:
优化前:(1000-3000ms)
优化后:(30-60ms)
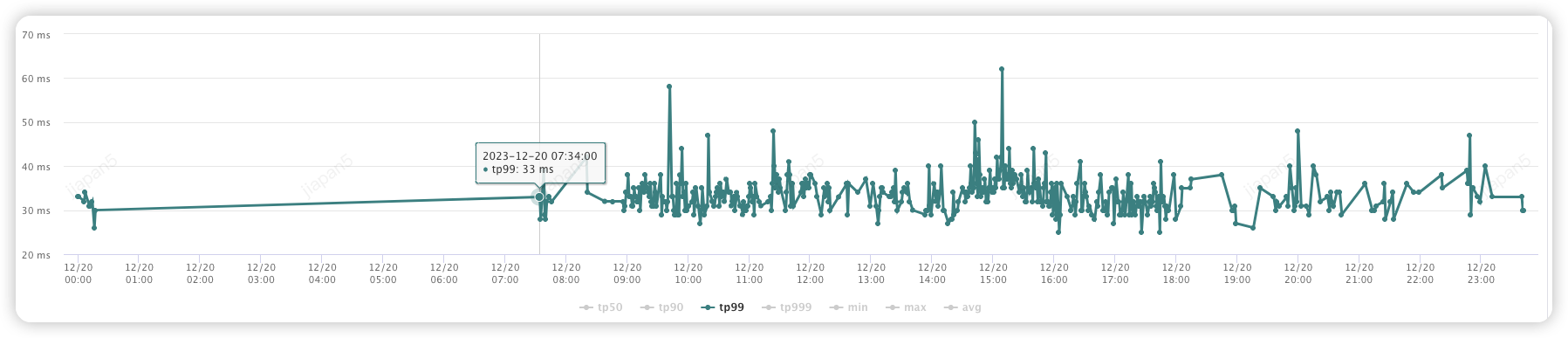
2. 用户体验改善:商家在反馈线索状态时不再遇到超时问题。
3. 架构清晰:业务逻辑与数据同步逻辑解耦,代码更加清晰和容易维护。
4. 扩展性提升:异步化后的数据同步流程为未来的系统扩展提供了更大的空间。
在运营管理 CRM 系统的实践中,线索列表的查询功能是不可或缺的一环,它支持基于复杂组合条件对线索数据进行精细筛选。然而,在当前的系统实现中,线索列表页面需要展示每页 50 条或 100 条线索数据时,接口性能表现并不理想:响应时间普遍超过 2000 毫秒,有时甚至延迟至 6000 毫秒。这一性能瓶颈已经引起了用户的广泛关注和较为严重的负面反馈。
通过对接口的分析,接口性能瓶颈主要来源于以下几个方面:
1.多次 ES 查询: 先根据搜索条件查询一次 ES 获取基础数据后,再循环遍历列表,对每个线索再查询两次 ES 来获取线索的手动及自动分配商家数量。
2.频繁的 RPC 调用:循环遍历线索列表为每个用户进行 RPC 调用以获取用户昵称。
3.过多的远程调用:ES 查询和获取用户昵称都是调用服务端服务。
针对这些拖慢接口性能的瓶颈点,我们采取下列优化措施:
1.减少远程调用: 我们将线索运营端多次请求服务端的过程调整成单次调用。查询逻辑都下沉到服务端,由服务端查询所有字段,运营端只需要调用一次,从而显著减少了网络延迟。
2.聚合查询优化:我们利用 ES 的 Aggregation 聚合 API,一次查询获取当前分页内所有线索的手动分配和自动分配商家数量,减少了多次查询的性能损耗。
代码部分实现:
BoolQueryBuilder query = QueryBuilders.boolQuery();
//线索单号列表过滤
query.filter(QueryBuilders.termsQuery("clueNo", clueIds));
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.trackTotalHits(true);
searchSourceBuilder.query(query);
IncludeExclude includeExclude = new IncludeExclude(new String[]{"1"}, null);
//按照分配类型聚合1
AggregationBuilder aggregation2 = AggregationBuilders.terms("distributionType").field("distributionType").includeExclude(includeExclude);
//按照线索单号聚合2
AggregationBuilder aggregation1 = AggregationBuilders.terms("clueNo").size(100).field("clueNo").subAggregation(aggregation2);
searchSourceBuilder.aggregation(aggregation1);
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(vendorClueESIndexName);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
1.合理使用缓存:针对用户昵称变动频率低的特点,我们引入了缓存机制, 首次 RPC 查询用户的昵称成功后对结果进行缓存,再次请求时直接从缓存获取昵称,减少 RPC 次数。
2.并行: 在处理线索列表填充手动分配和自动分配商家数量以及用户昵称的过程中,我们使用 parallelStream() 并行流技术,从而加快数据处理速度。
通过以上优化方案, 对于查询 100 条线索需要的查询次数:
优化前: 1 次 ES 查询列表 + 200 次 ES 查询分配商家数量 + 100 次 RPC
优化后: 1 次 ES 查询列表 + 1 次 ES 查询商家分配数量 + 100 次 RPC(有缓存下会减少次数)
响应时间缩短:
优化前:
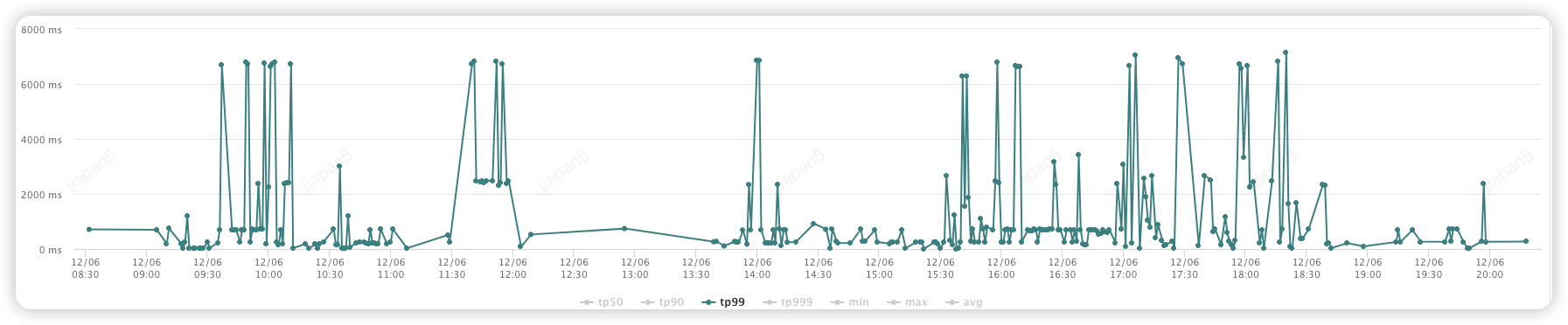
优化后 (250ms以下):
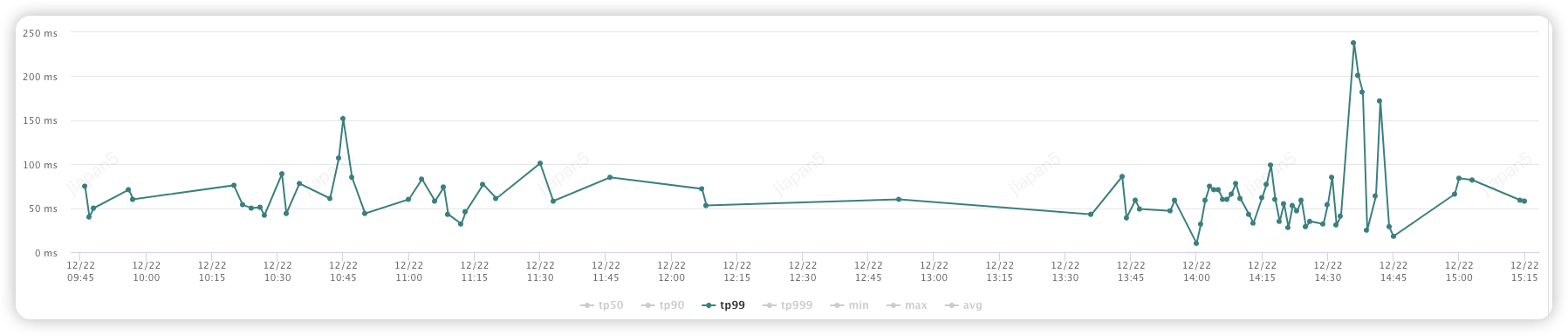
通过对线索系统的深度优化,我们不仅解决了线索系统在核心流程中的性能瓶颈,也为系统的长期健康发展奠定了基础。这一实践表明,适时地对系统架构进行优化,能够有效提升系统的性能和可维护性,进而支持业务的快速增长和变化。在未来,我们将继续追踪新的技术趋势和业务需求,不断优化我们的系统,确保它们能够支撑起日益增长的业务挑战。
作者:京东零售 贾攀
来源:京东云开发者社区 转载请注明来源
