
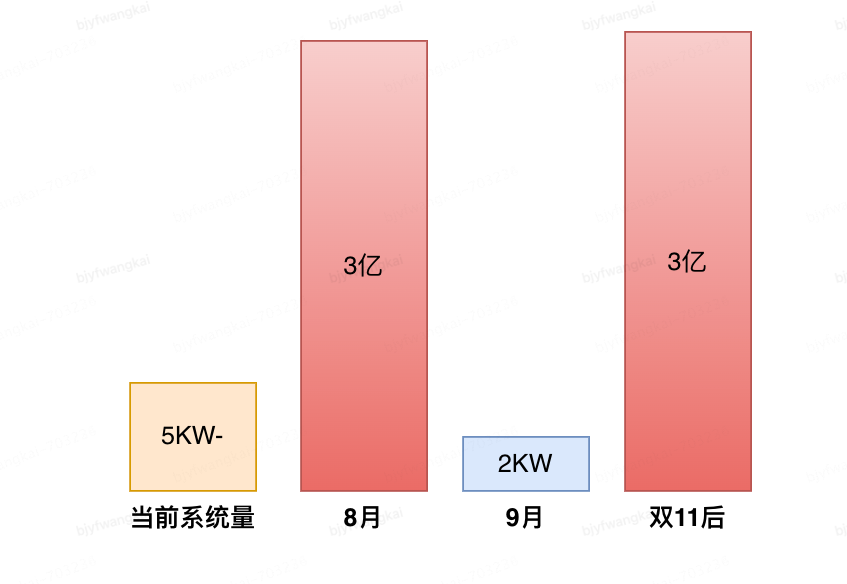
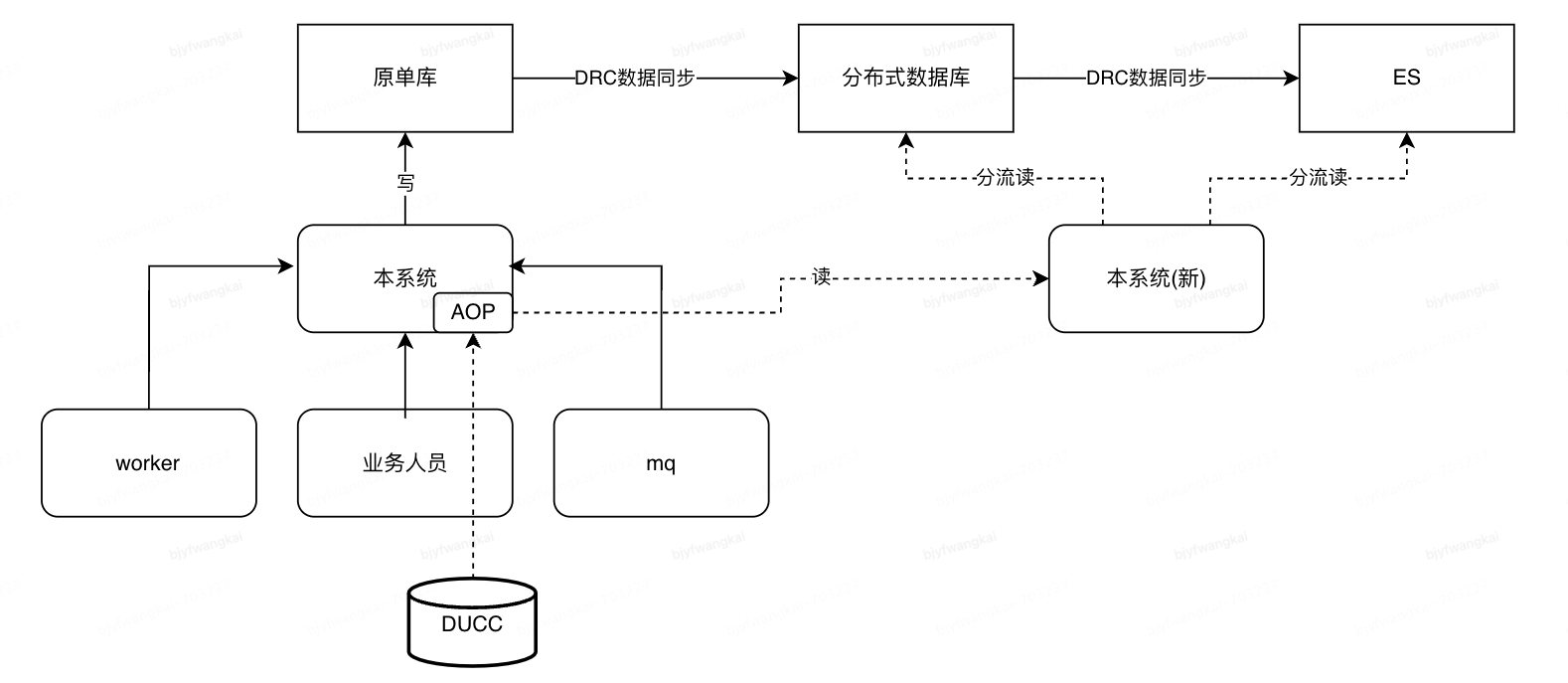
系统业务功能:系统内部进行数据处理及整合, 对外部系统提供结果数据的初始化 (写) 及查询数据结果服务。
系统网络架构:
•
部署架构对切量上线的影响 - 内部管理系统上线对其他系统的读业务无影响
•分布式缓存可进行单独扩容, 与存储及查询功能升级无关
•通过缓存层的隔离, 系统扩展期间外部系统可保持不变, 只对内部管理系统升级
•内部系统上线/验证时, 除了业务场景 1 相关的初始化操作, 仍可提供读服务,降低上线影响
整体实施方案图例:
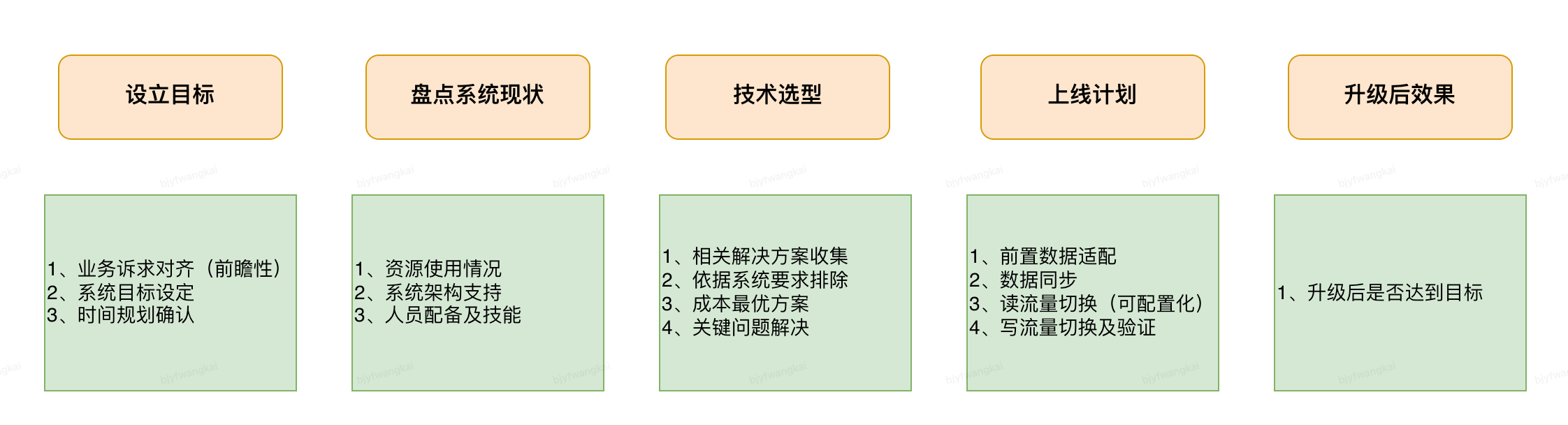
商品全量渠道化 - 切量计划: (总量为当前 10 倍):
目前:
当前数据库常用表均已超过5000W, 其中部分结果表达 6000W, 已达到 MYSQL 数据库表容量峰值, 对于全切量无法支持;
目标:
最高支持9 亿: 根据切量计划, 全切量后系统约为 6.7 亿, 保留 1/4 的冗余, 取8.375亿; 向上取整 9 亿, 此值冗余量较大, 可满足未来 5 年数据支持
时间目标: 8 月初方案设定, 8 月 17~8.22 上线及验证, 8.24 切量计划开始
•当前部署结构
——机房分布,Mysql: 1 主 4 从 (机房 A 1 主, 3 从; 机房 B 只读从)
——机房分布,Doris: 32C, 63 个节点, 3 副本
•当前应用容器(docker)数量,db 最大连接数
——应用容器数量: 62 (Web 分组: 25, Worker 分组: 31, MQ 分组: 6)
——db 最大连接数 100 (每个容器配置)
•当前业务是否读写分离,读写比例情况
——无读写分离
•各业务场景下,是否可容忍主从延迟?可容忍的延迟时长是多少
——目前业务人员修改操作多数为同步操作, 修改完成后返回操作结果到前端, 从业务方操作 + 查询结果来说, 无法空忍延迟
——后台任务场景, 对于中间数据处理, 可以容忍主从延迟
•产品层面,系统出现瓶颈压力时,是否接受限流?是否接受数据延迟展示?
——对外服务接口本次不涉及开发, 服务接口不受影响;业务页面访问量少,可接受短时间内的延迟
•团队是否有 ES 使用经验
——部分了解, 未在项目中使用
使用通用性的盘点框架对系统进行全面性现状梳理
表内空间, 业务场景等信息(部分)
| 表名 | 当前表记录数(单位:万)| 最大支持条数(单位:万)| 表字段数 | 是否可拆分出分片键 | 分片键字段 | 是否存在不带分片字段的 SQL | 是否有跨表查询场景 | 数据记录读写比 | 是否存在写后立即查询 | 使用场景 | 数据是否 可截转 | 可接受的截转时长 | 切量后预估量 | 分布式 DB | ES 判断条件:是否有复杂查询 | ES 直接双写 判断条件: 写后立即查询 |
| 审批流表 | 3.5KW | 4KW | 43 | 有 | sku | 存在 | 存在 | 1000/1 | 存在写后用户手动再查询操作 | 1、页面创建审批流 2、页面查询审批流 3、页面数据置失效 4、审批平台回调修改 | 否 | | +3 亿 | ✅ | ✅ | UI 修改后需重新点击"查询"按钮; |
| 审批流细目表 (历史数据已清理) | 800W | 4KW | 20 | 有 | 增加 sku | 无 | 存在 | 1000/1 | 存在写后用户手动再查询操作 | 1、刷新审批流 (删除 + 增加) 2、查询审核中流程 (任务) | 审批通过可转冷备 | | 转冷备 | ✅ | ✅ | |
| 业务数据表 1 | 3.3KW | 4KW | 15 | 有 | sku | 无 | 无 | 100/1 | | 1、审批流通过后, 创建 2、数据失效, 删除操作 3、后台工具: 同步缓存 (存在复杂 + 分页查询) | 否 | | +3 亿 |  |
|  | |
| |
| 业务数据表 2 | 5.9KW | 4KW | 16 | 有 | sku | 存在 (新增后异常按 id 删除) | 无 | 1000/1 | | 1、业务查询/导出维度 1 数据 2、业务查询维度 2 数据 2 3、后台工具: 同步缓存 | 否 | | +5 亿 | | 同步大数据推送数据到缓存, 使用 creator 字段查询; 多个 SKU 分页查询 | |
| 支持数据表 (大数据平台计算后推送) | 1.2KW | 4KW | 12 | 有 | item_sku_id | 无 | 无 | 5/1 | | 1、运维工具: 增加/删除记录 2、清理历史数据 (任务) 3、数据查询 (显示使用) 4、计算 5、大数据推送数据 | 按日期推送, 目前保留 3 天 | 历史数据无用 doris? | 一天 3~4KW | | 删除数据 dt | |
| ..... | | | | | | | | | | | | | | | | |
系统特点:单表高并发写、复杂读
结论:
内部分布式 DB: 由单分片拓展到多分片, 解决海量数据存储及简单查询
ES: 新引入, 实现复杂查询(分词查询)及全局排序
redis: 保留, 需扩容
Doris: 保留, 容量增大
复杂查询 (原因: 前端业务访问存在多表关联场景(2 张千万级别表关联查询), 随着表容量变大, 关联查询性能下降, 已无法满足业务高效需求)
复杂查询决策因素:
| | | 分布式 DB(mysql)| es | doris | TiDB |
| 决策指标 | 产品定位 | 数据库(OLTP)| 搜索引擎 | 数据库(OLAP)| 数据库(OLTP+80%OLAP)|
| 优势 | 1、高并发、高吞吐量事务处理 2、稳定性 3、数据实时(写后即读)| 1、全文索引 2、复杂结构化查询 | 高并发查询分析 | 1、兼具事务处理 + 数据分析 2、自动拓展 3、数据实时(写后即读)|
| 劣势 | 1、大量数据分析 2、手动拓展 | 1、事务处理 2、实时(写后即读)| 1、事务处理 2、实时(写后即读)| 高并发、高吞吐量事务处理 |
| 可靠性 | 高(多机房)| 高(多机房)| 低(共享集群)| 低(单机房)|
| 拓展性 | 库维度:平台管理 表维度:应用控制 | 平台管理 | | 库维度:平台管理 表维度:应用控制 |
| 数据一致性 | 最终一致性 | 最终一致性 | | 强一致性 |
| 运维支持 | DBA | 分公司运维 | 无专业运维团队 | 分公司 DBA |
| 总结 | 复杂业务查询慢 无法支持大数据量跨表查询、多维度复杂查询及全局排序 单表使用分片字段查询性能快 | 复杂业务查询性能高 | 部署结构为共享集群,(特别是)写性能受外部影响大 | 部署架构为单机房,无法满足 0 级系统可靠性要求 |
| | 架构目标 | | | | |
| 结论 | 海量存储及高并发写 | ✅ 大数据量存储,基于分库字段单表查询性能高, 单库事务处理 | ✖️ 高并发下的事务处理 | ✖️ 查询受写入/更新操作影响大 | ✖️ 高并发下的事务处理 可靠性 |
| 复杂度查询 | ✖️ 性能差, 可能会存在跨库查询 | ✅ 可靠性高 大数据量下的复杂业务查询 | ✖️ 查询受写入/更新操作影响大 | ✖️ 可靠性 |
方案描述:使用 DRC 平台配置化完成分布式 DB 到 ES 的准实时数据同步 (注: DRC 为公司内部通用数据同步平台, 可在多个数据源之间进行数据同步)
优势:简单无序代码开发 劣势:可能存在业务写后即查场景,数据不一致风险
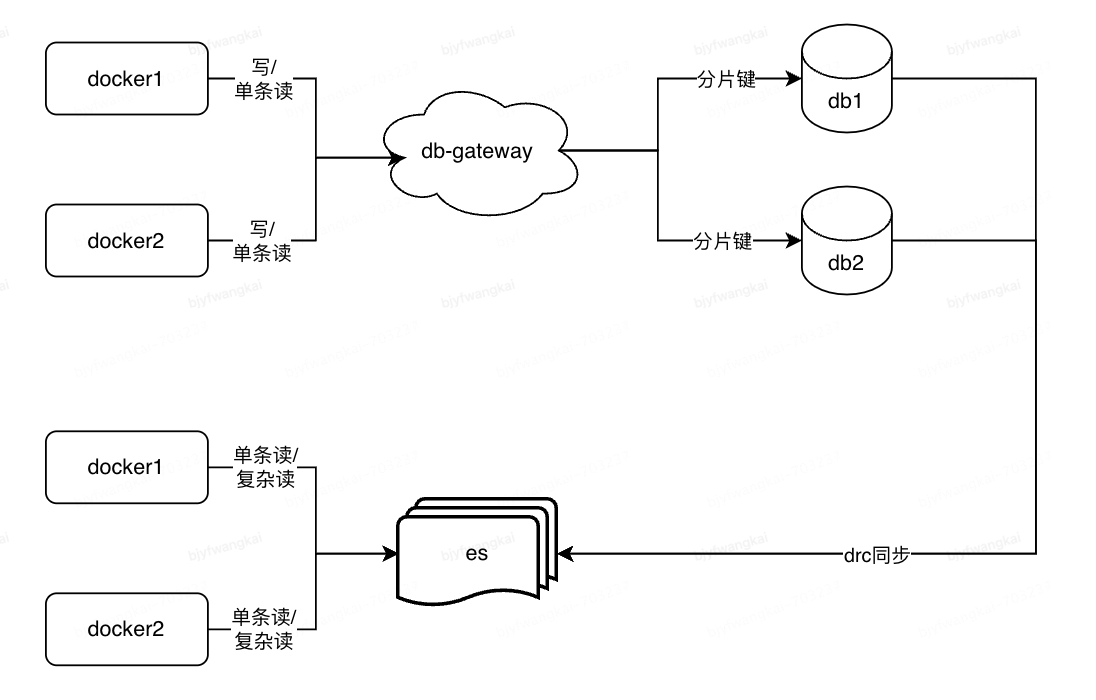
方案描述:双写分布式 DB 与 ES, 保证数据一致性
优势:保障数据写即读场景一致性 劣势:代码开发成本高

先选择 A-准实时同步方案 -> 线上验证是否满足业务操作体验-> 再选择是否实施 B-双写强一致方案
问题:
•双表联合查询场景无法直接使用 DRC 平台同步, 需另开发相应的同步模块 jar 包, 嵌入 DRC 任务, 或放弃使用 DRC, 直接使用代码同步, 都存在开发时间长问题
•ES 索引空间占用多, 冗余记录条数多, , 查询结果需排重, 查询复杂
难点:流程表与流程细目节点表涉及联合查询, 两表都存在单表增删改的操作; 导致同步到 ES 的数据模型复杂、同步困难
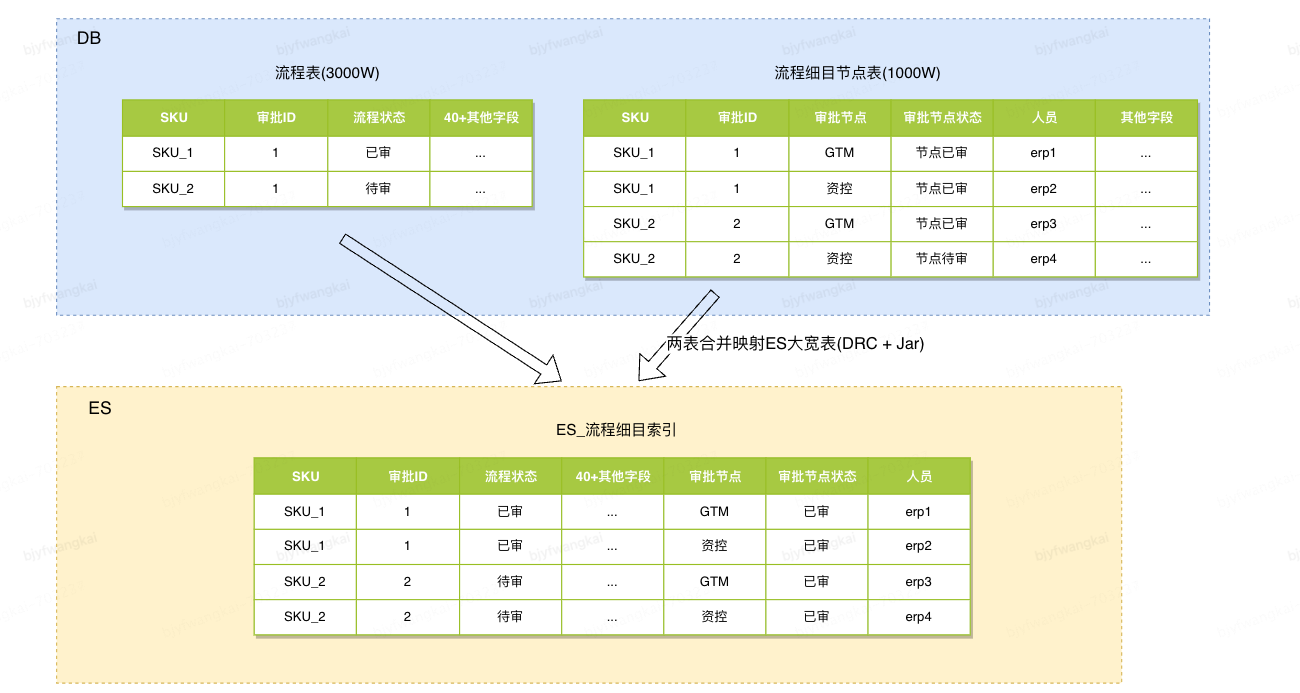
解决方案:(数据库表增加冗余字段, 冗余字段专用于 ES 查询)
在 DB 的流程表增加待审人员, 已审人员字段, 字段的值使用空格分隔, 使用 ES 的分词功能, 同时 ES 可直接使用 DRC 工具直接同步此表数据, 减少同步的开发时间
方案成本: 增加/修改流程细目时同步修改流程表新增字段; 开发刷新历史数据工具

1)业务表新增分库字段
部分业务表缺少分库字段,无法直接分片。针对业务表新增 sku 分片字段, 同时对现有逻辑改造增加 SKU 条件,以提升查询效率;
2)ES 相关查询冗余字段的增加(刷数据)
1)完成分布式 DB 分片库 + ES 初始化;
2)配置 DRC 完成原单库到分布式 DB 分片库的全量 + 增量数据同步;
3)配置 DRC 完成分布式 DB 分片库到 ES 的全量 + 增量数据同步;
4)通过检验工具,定期比对分布式 DB 单片、分布式 DB 分片及 ES 间的数据一致性。

1)新增 AOP 切面, 通过 DUCC 配置 (erp 白名单, 全量读, 结果对比等维度配置),将读请求逐步切量到新应用集群
2)待产品、业务侧完成验证后,切换全部读流量至新应用集群(注: 新应用集群使用数据库只读帐号)
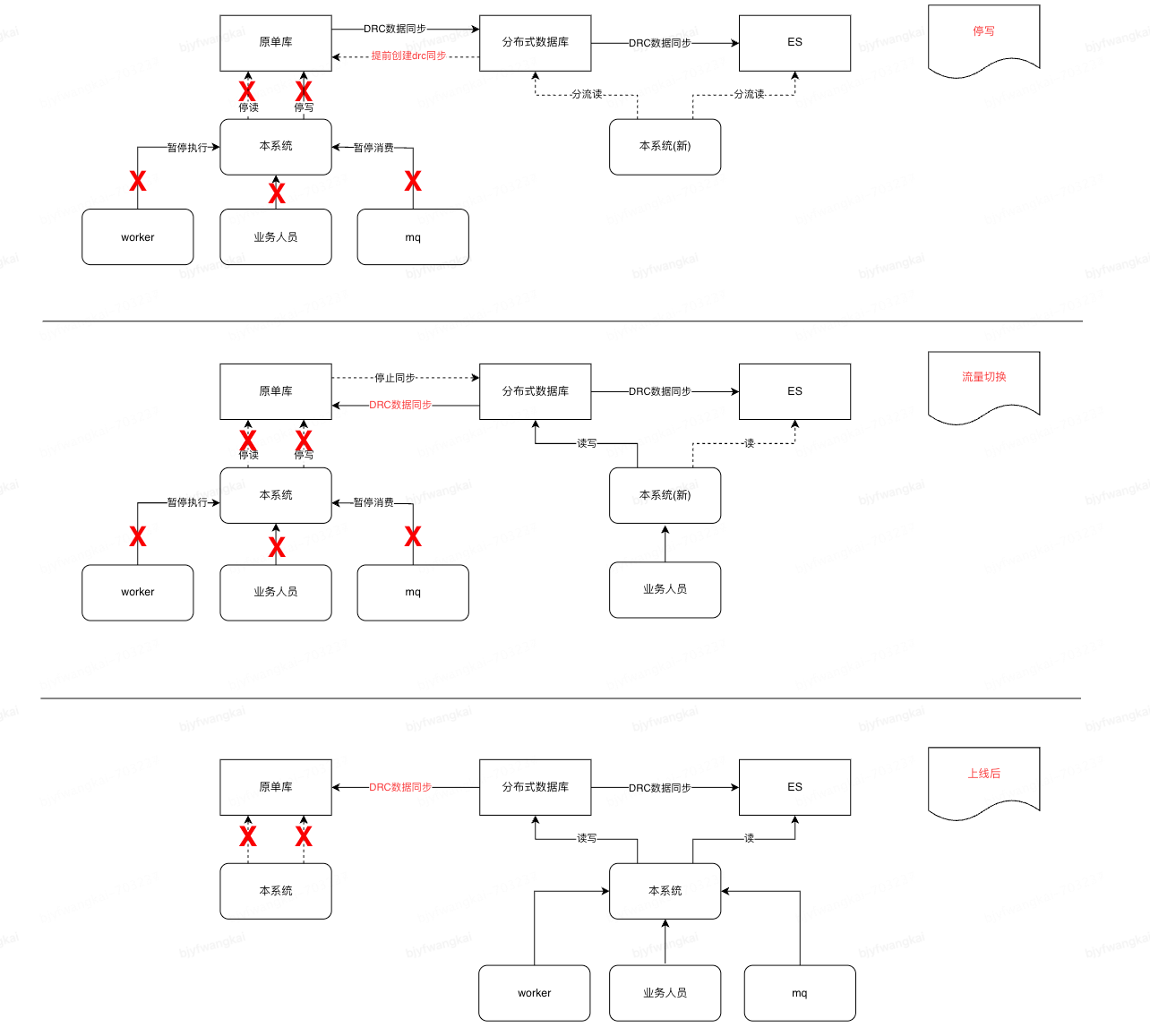
1) 上线前周知业务方及上下游系统,告知上线时间段及预估时长,减少业务影响
2) 新增一个静态页面提示用户系统升级中不可用,切换前端域名至静态页面, 避免用户操作
3) 停止原系统分组,确保原单库不再存有写流量,同时协调 DBA 对原库执行禁写 (关闭 worker, 暂停 MQ 消费)
4) 等待并确保原库数据均同步至目的库后,再次通过手动 + 自动方式校验新老两个数据库的数据一致性
5) 新系统分组切换为读写帐号, 进行部署
7) 研发及测试人员对新系统分组功能使用测试商品进行功能验证, 无问题后交由业务人员验证 (切换静态运维页面)
8) 启动 worker 及接入 MQ
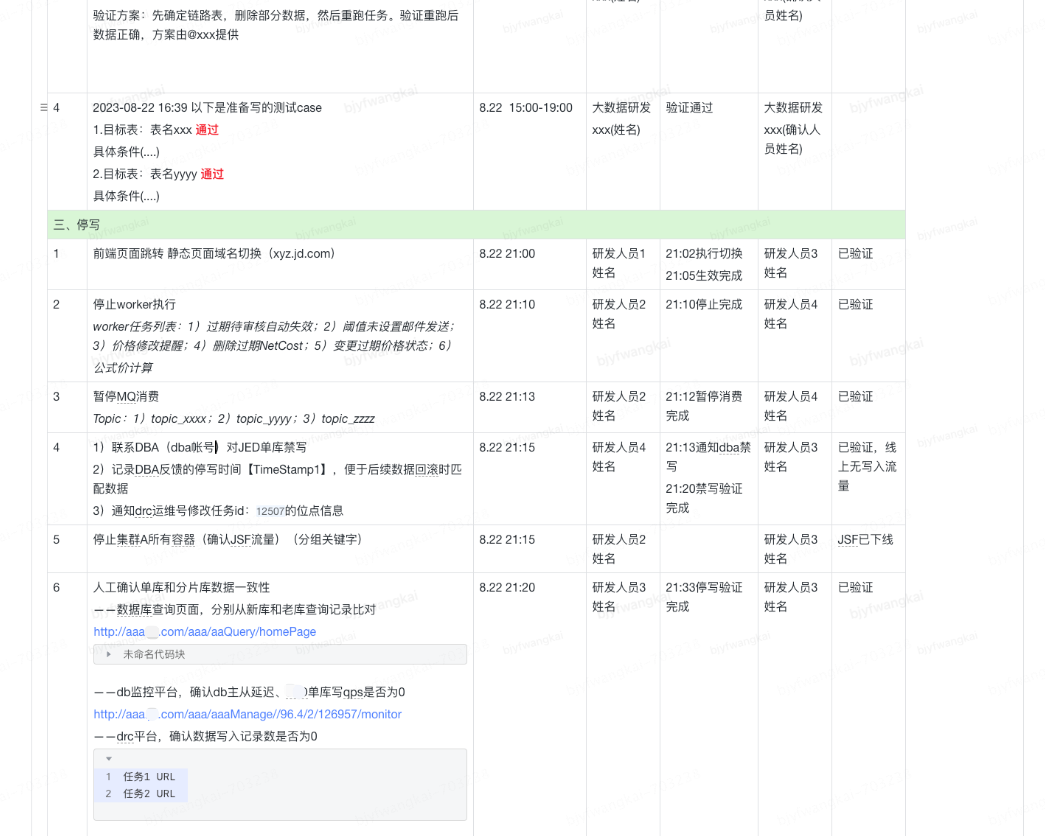
上线后系统运行正常, 8.23 至今已结转商品 2.6 亿; 目前系统支持商品场维度数据 3.16 亿; 最大 DB 表数据已有 2.84 亿; ES 数据 4356W;
前后对比: erp:xxx; 此 erp 帐号数据 29w 原查询 9s,新查询 1s;
•全面、清晰的系统现状盘点:可以降低复杂度、提高质量
•清晰的上线计划:指导人员合理分工、缩短上线时间、降低上线难度
目前分布式 DB 分布式事务支持比较弱, 无法保证跨分库时多条记录在一个事务中修改的正确性, 需要提交后进行读取后再验证确保数据正确保存
业务人员名下商品数据百万时, 查询时间仍然效长, 查询性能将持续优化
作者:京东零售 王凯
来源:京东云开发者社区 转载请注明来源
