作者:郭晨|QE_LAB
大模型的话题还在继续升温,垂直领域大模型也不断受到关注,越来越多人相信它会是大模型未来发展的方向,并且有大量讨论从需求、行业发展、应用等角度阐述垂直领域大模型,但是从理论角度来理解这个趋势的介绍却比较少。大模型应用向领域垂直化发展的趋势,是否有其必然性?又或者垂直领域大模型也只是大模型众多应用尝试中的一种,也要在千军万马中努力争取成为挤过独木桥的幸存者?本文就是尝试在这个角度做一些讨论。
这里和下面所谓的垂直领域大模型,特指使用针对特定领域设计的算法训练领域数据得到的大模型,和通过其他方式得到的可能用于专门领域的大模型做对比。
上周百度的发布会引出了关于《决定大模型未来的,为何是原生应用》、大模型如何商业化、产品化、应用前景到底如何的讨论。由于文章较长,我就没有麻烦文心一言和 chatGPT 来帮忙摘要,而是人肉浏览了一遍,大致是说,大模型要和已有的应用功能结合,比如使用大模型的 NLP 能力让地图导航的交互更便捷,更拟人,而不是让大模型去导航,导航仍然是地图的功能,大模型只是让这个功能更好用。这样让上帝的归上帝,凯撒的归凯撒,功能归 app,交互归大模型,“当越来越多 AI 原生应用改变人类生活,人工智能造福于人类的美化愿景才能真正实现”,AI 技术也才能实现自我造血,可持续的发展下去。
我和几位奋斗在 AI 教学和科研战线的老同学在闲聊中也说起过类似的话题,由于师出同门,所以大家在观点上都有很明显的传统学院派倾向,对大模型的态度和工业界有很大的差异,都认为大模型对 AI 学科的最主要贡献就是引流,吸引资本和眼球,提升 AI 的关注度,用来拉经费用的。
其实早在年初 chatGPT 刚火的时候,就有 AI 领域的资深研究者表达过类似的态度。比如前 MSRA 的 NLP 负责人周明博士就在一次讨论上说,chatGPT 在他看来最大的意义在于,让 NLP 进入公众视野,让更多人知道他们这些 NLP 研究者干的事是有用的,并且调侃说,chatGPT 最大的实用领域有两个,一是青少年教育,因为知识内容固定,不需要定期更新,再就是陪老太太聊天,什么电视剧主角是谁之类的话题,反正说错了也无所谓。这种半开玩笑半无奈看似漫不经心,但是又有多少实话是夹杂在不经意间说出来的呢。
今年各个行业都被 chatGPT 迷住了,都想用大模型,纷纷投入资源,也有各种大模型纷纷出炉,但是像 chatGPT 这种通用大模型在每个行业领域内的表现又确实很一般,因此通用大模型火了大半年,还在继续火,而同时服务于特定领域的大模型越来越被关注。也有人在问,有没有可能,随着大模型的不断发展,越来越大,会出现一个更好的超级大模型,能够驾驭所有行业的垂直领域,到那一天,现在花在领域大模型上的投入就全都打水漂了。
超级大模型的想法,很美好,所以只能是个想法而已。且不说有没有人真的去干这件事,会不会得到各个行业的配合,能否收集到充分的数据用于训练,需要多少算力和能源,单说理论上,这个事就不成立。
模型无论大小,都还是一段程序,仍然没有超越算法和数据。通用大模型的数据都是通用数据,领域专用的数据较少,因此也不能指望它们对特定领域能达到什么深度,这就像只接受通识教育的人不会成为行业专家一样。也有人认为,对于已有的大模型,如果用更多行业更多领域更多数据去训练大模型,是不是会得到一个全知全能的大模型?或者即便全知全能的代价太高,如果只保留现有大模型的代码,把数据替换成某个特定的领域,是不是就可以获得新的大模型?
答案可能有点悲观——这就要从算法领域的一个常识说起。
算法领域有个常识,就是 NFL:No Free Lunch(Wolpert,1996;Wolpert and Macready,1995)。NFL 的逻辑其实很直接,简单说就是:因为算法的确定性,所以算法无法避免归纳偏好,同时问题也是有倾向性的,如果把算法无差别的用在所有问题上,就会发现,所有算法的平均水平都一致——简单说就是,你深思熟虑,我都选 C,只要考试题足够多,咱俩的成绩就一样,谁也没比谁更差。
—————————— TLDR start ——————————
算法的定义要求每一步的结果是确定的,所以计算机擅长处理确定性的问题,答案非黑即白。但是在实际应用里,一定会有模棱两可的场景,如果进入算法流程,就需要 “选边站队”,而且是固定的永远选某一边。最简单的例子比如,折半查找时,遇到元素数量是奇数,正中间的那个元素归前还是归后,排序问题遇到相等是否交换元素顺序。作为算法,不可能这次归前下次归后,也不能随机交换相等的元素,无论选了哪边,都必须永远坚定的选择,不能朝秦暮楚。
这种确定性是算法内在的要求,就像周志华教授在西瓜书里说的,如果算法给出的是随机的结果,那就会导致问题的答案不稳定。而恰是算法内在的这种确定性,导致了算法必然有归纳偏好(inductive bias),永远倾向某一边。而同时,实践里要解决的问题,通常也都有倾向性,我们对于问题的关注角度和预期都有差异。当问题和算法的倾向一致时效果就会比较好,反之就会差。因此选择算法当然有讲究,什么算法针对什么问题,是有规律的,选择算法首先要理解问题。同样,评估模型质量首先也要考虑算法的偏好和问题的倾向性是不是一致,是不是选对了算法。当然,这不是说某个问题必须用什么算法,而是选对了算法,可以更大概率更高效的解决问题。
NFL 的证明在各种算法书上很容易找到,不难,但是有点繁,西瓜书里用二分类问题做了个简单的说明。实践里,回归问题可以通过阈值转化成分类问题,多分类问题可以转化成多个二分类问题,所以这种理论问题,只要二分类搞清楚,多分类和回归也就大概能明白。有兴趣可以参考西瓜书 8-9 页的证明过程,我就不抄了,大致说一下思路:
- 算法就是建立问题到答案的映射关系,对于二分类来说,就是一个离散集 U 到 {0, 1} 上的映射。U 和 {0, 1} 之间实际的相关性记为映射 f: U->{0, 1};
- 通过数据划分的方法,选定 U 的真子集 X 作为学习样本,通过学习算法 L 拟合出映射 h: X->{0, 1},h 就是通过算法 L 训练得到的模型。所谓好模型,就是 h 尽量贴合 f;
- 对 h 进行验证,计算在每个 (U-X) 内的元素上 f 和 h 的差,也就是看 h 对那些在训练中没有用到的数据的表现,然后和 f 去对比,然后取平均,也就是计算每个元素上 h 和 f 的差的平均值,得到平均误差;
- 化简 h 模型和 f 的平均误差的表达式,发现表达式中不包含变量 L,说明 h 和 f 的平均误差和算法 L 无关。
因此可以说明,所有算法的平均误差都是相同的。
—————————— TLDR end ——————————
基于 NFL,如过把算法用在所有的问题上,那么所有算法的平均表现没有差别,也就是说,一个算法如果在这类问题上有优势,也就一定在其他问题上有弱点,从而达到总体平均误差在一个水平上。归纳偏好和问题的倾向性匹配的时候效果好,不匹配效果差,算法偏好和问题倾向的匹配程度会影响效果,所以有的算法就是适合且只适合某些类型的问题。这也很符合我们日常的经验,当算法偏好和问题倾向不匹配的时候,就很难效果好,这个 “难” 可能体现为结果不被接受,P / R / A 差,训练调优成本高,效率低等多种形式。
NFL 字面直译是 “没有免费的午餐”,但我总觉得要表达的不是这么个意思,不妨翻译成 “效果守恒”——出来混迟早要还,收之桑榆失之东隅,谁也别想占便宜。所以西瓜书也反问:是不是 “被一盆冷水浇透了”?
幸好 NFL 针对的是各种算法面对不同类型问题时候的平均表现,而且有个大前提是,假设各种问题的出现几率是平均的。很多对 NFL 的滥用就是因为忽略了这一点,我们要解决的问题,并不是平均的,总会有出现概率的差异,或者重要性的差异。换句话说,NFL 的成立所要求的前提条件在现实中并不存在,或者至少是被回避掉了,而对于足够复杂的问题,本来也不应该幻想能得到 “既要又要我还要” 的答案。因此在各种教材里,提到 NFL 都是作为 “算法服从问题” 的理论依据,所有 ML 圈的人都在念叨 “没有最好,只有最合适” 的口头禅,我以前做模型质量、算法评估和机器学习测试的时候也不断提醒自己以及一起工作的同事,一定要先想清楚问题是什么,我们需要什么,关注什么,再来讨论模型和算法。
但是即然总误差相同,那也就意味着如果追求局部误差减小,就必然放大其他部分的误差——同理,放大局部的误差,可以实现另一部分误差的缩小。对于看似不太好的算法,也可以反思它适合什么场景,而不是一棍子打死。凤凰熬汤不如鸡,但凤凰存在的意义本来也不是作为食材。
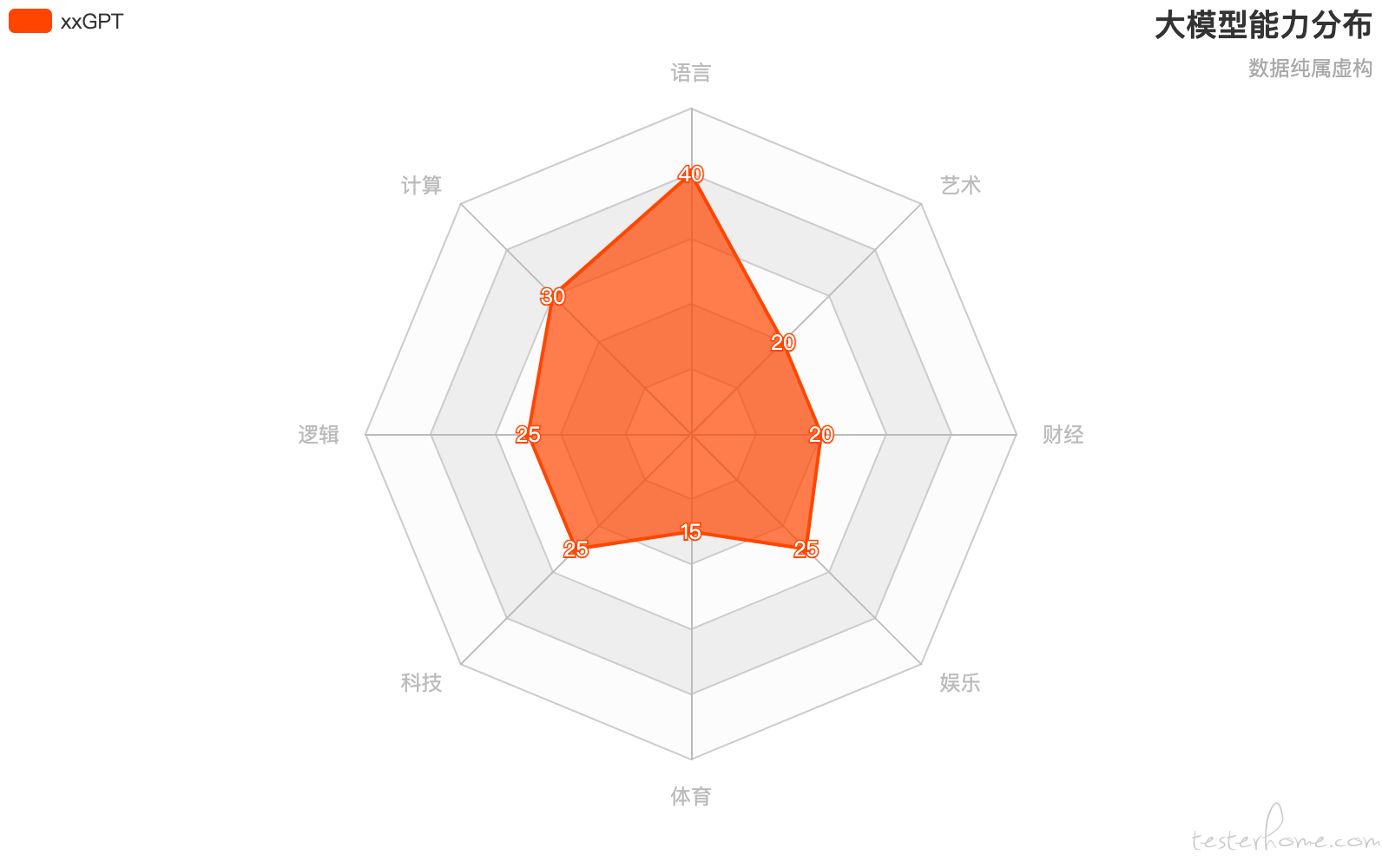
回到前面的问题,例如 xxGPT 即然在某些方面有短板,各领域能力类似下图,这种不均衡是不是可以通过增加数据类型、调整训练算法的方式来补齐短板?
想法很美好,即然在某个领域技能偏弱,就增加这部分数据重新训练。但是根据 NFL,适合训练 NLP 的算法,未必适合训练编程,适合训练逻辑模型的算法,也未必适合训练计算模型。所以增加数据的同时,就也要调整算法。于是,在数据和算法都更新,兼顾了各方面后,得到了没有短板的全能大模型 almightyGPT:
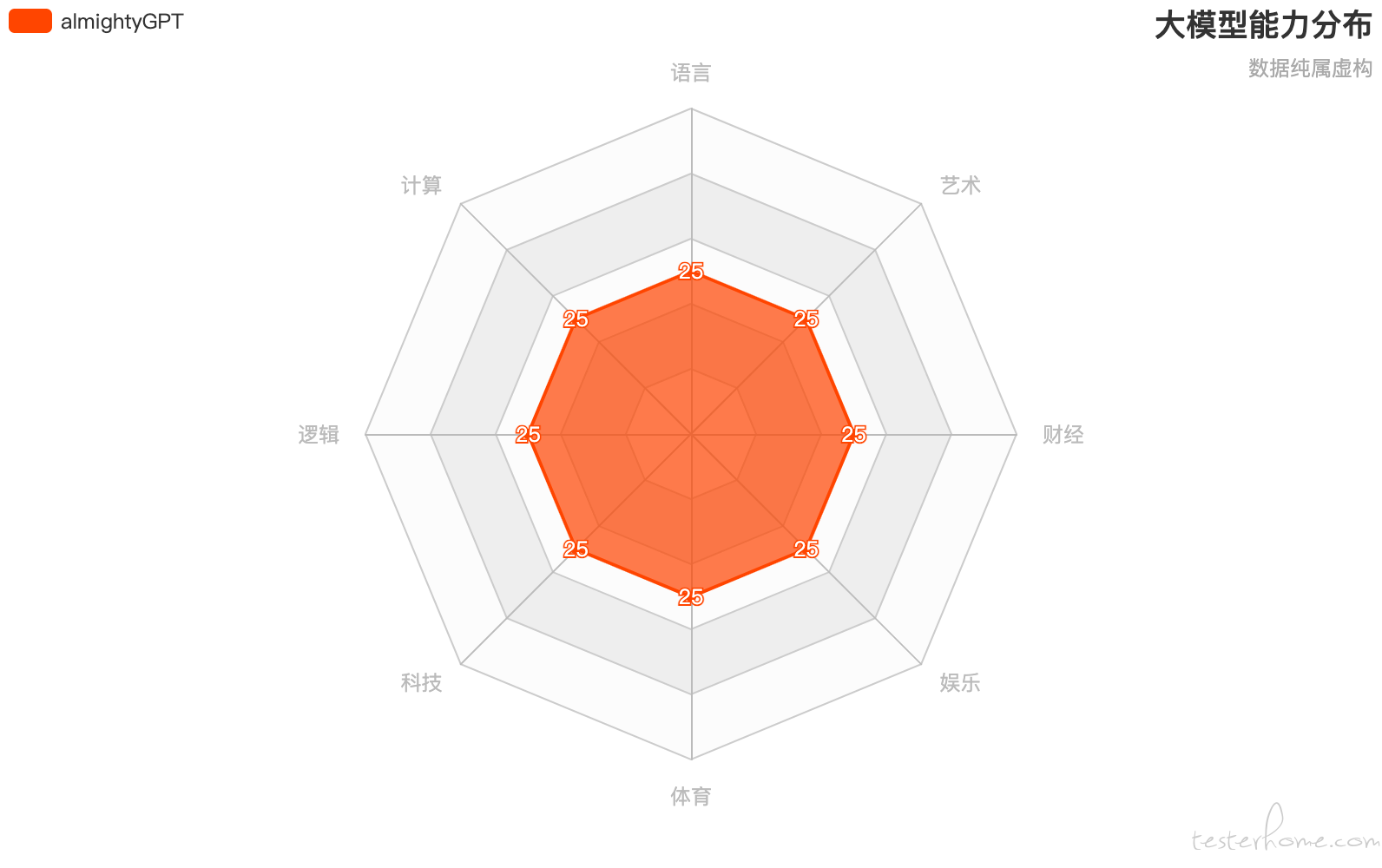
这种模型,用 90 年代末叛逆青年韩寒的话说就是 “全面发展,全面平庸”——任何领域都挺像那么回事,但也就只是那么回事。这种大模型,如果遇到转门针对某个领域的模型会怎样?比如,针对艺术领域的算法和数据训练 artGPT:
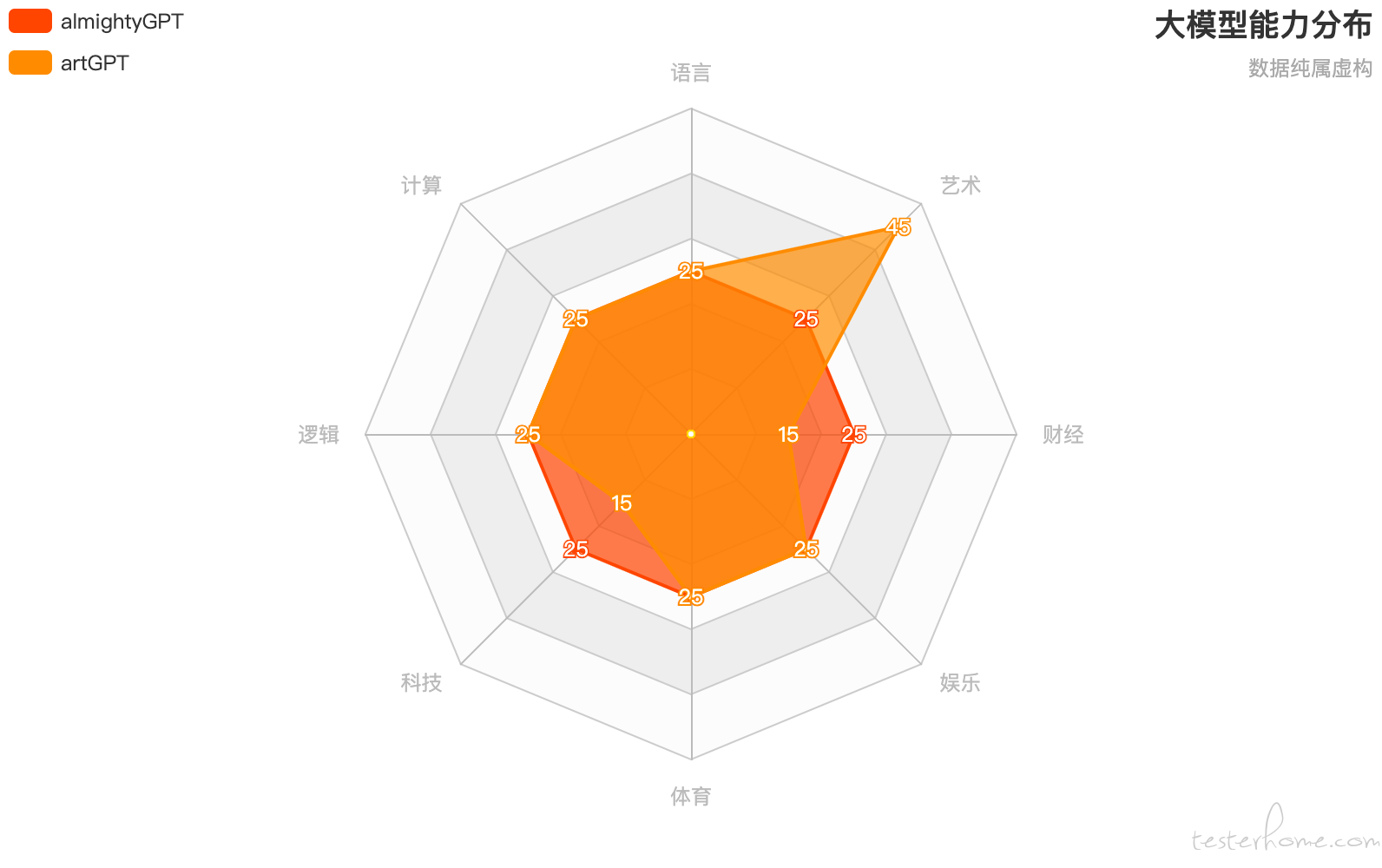
很显然,别的领域可能 almightyGPT 有优势,但是至少在艺术领域,artGPT 可以站稳脚跟,妥妥打赢 almightyGPT。同理,其他领域的专用模型也可以稳赢。最终结果就是,在每个细分领域的战场上,almightyGPT 都有一战之力,但也只限于一战而已。那么 almightyGPT 的生存难度可想而知。
当然了,almightyGPT 可以增加投入,引入各领域的数据,但还是由于 NFL,不能单纯的 “去子留母”,而是连算法也要更新,才能得到进化版的 almightyGPT+:
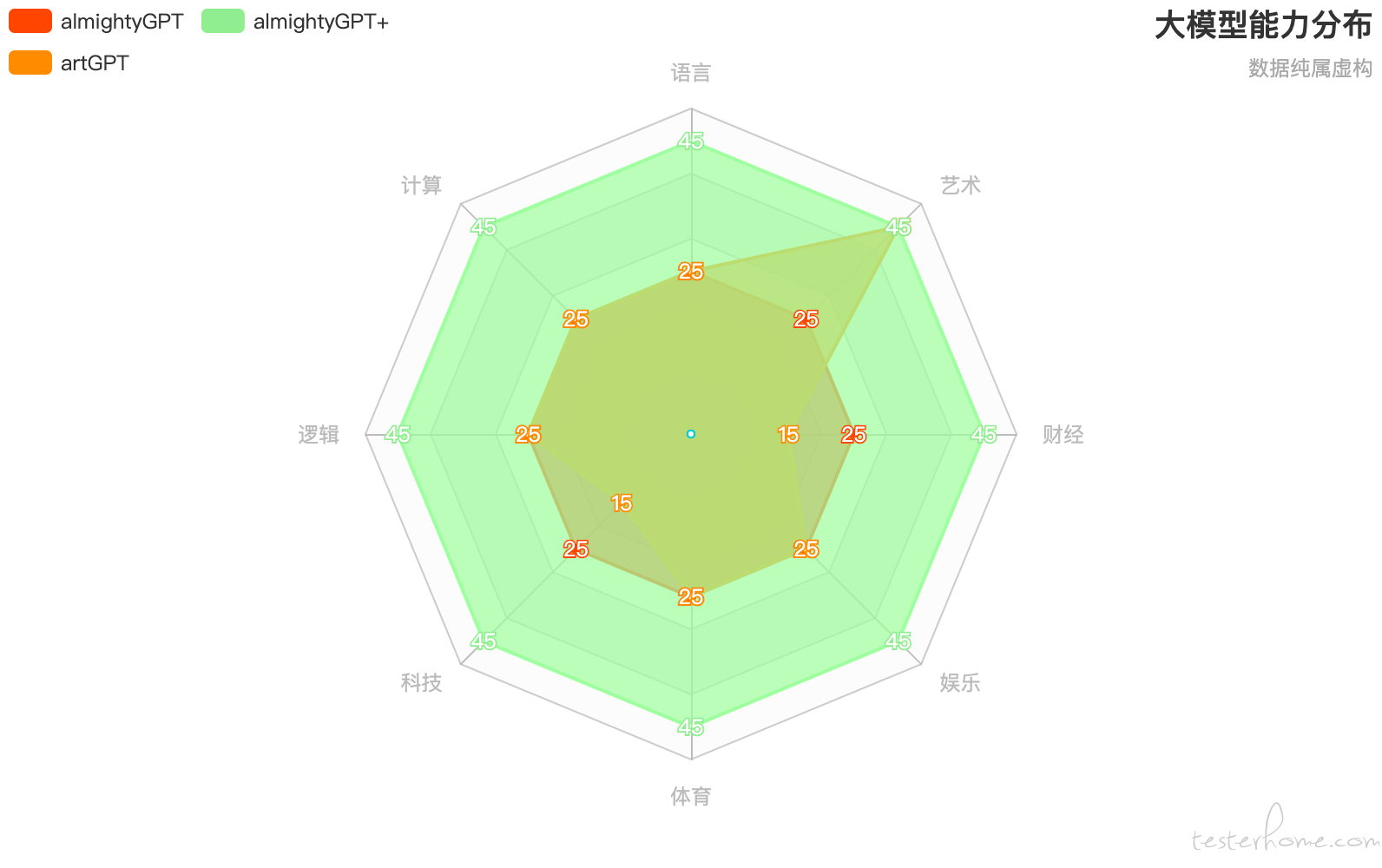
没错,全面碾压其他的各种 xxGPT,但这一定是以增加数据增加算力为代价的,只要其他模型调整算法,用同样的算力,扩充某个特定领域数据,仍然会出现单项超越——换句话说,只要大家烧一样多的钱,针对特定领域的专用模型在专业领域里仍然还是能打赢通用模型,偏科胜全才。
所以这显然不是一条能保持优势的路。与其补短,不如避短,训练模型只针对特定领域,使用模型只针对特定问题。想通了这个,也就回答了前面的两个问题:为什么不会有全能大模型?是不是换了数据训练出的模型就能用于其他领域?
确实悲观。
但是这里有个逻辑不严谨的地方就是,大模型的算法也许很清楚,但是当数据量增加,参数增加,神经网络的深度增加,而且增加到现在这个规模,甚至未来还会继续增加,这时算法到底干了什么,已经没人知道了。也是因此,学院派对大模型的某些也就很正常了。
还有一种很流行的思路是,随着通用大模型可接受的输入越来越大,是不是可以使用语境学习(ICL)的思路,通过微调(SFT / PEFT / RLHF 等)提升通用大模型在垂直领域的表现?
说实话,我还没仔细查相关的研究和实验,但是按照日常的直觉,隐约觉得还是专门设计的领域大模型会胜出,毕竟,领域大模型可以从预训练阶段就开始建立知识,而微调只能依托在现成大模型已有的基础上加强,这就相当于 “用你的爱好挑战别人的饭碗”,如果不是天才,一定输的很惨。
当然了,这不是说微调没意义,毕竟这是获得一个可以用于特定领域的大模型的比较快速的方式,如果对特定的领域,只是需要让大模型来扫个盲,入个门,那微调的结果也差不多能应付,如果遇到个客户说就想要这个,那也不必和客户较劲。不过要解决学科和行业真正有难度的问题,还是需要专门训练的领域大模型。微调只是成本低,不是效果好,皮鞋扎几个洞当凉鞋穿,那就是凑合应个急,也不是不可以。
基于以上,我们对大模型的态度和使用方式也就有了。以 chatGPT 为例,处理数学应用题就是 chatGPT 的弱项之一,曾经就连简单的鸡兔同笼都能让它胡说八道。但是值得注意的是,无论问题回答的多么离谱,chatGPT 都能一直保持着一种有来有回的对话,并没有像 TayTweets 那样丧失优雅的交流方式,因为毕竟 NLP 是 chatGPT 的相对舒适区,chatGPT 擅长的还是在 chat,而不是解决具体学科领域内的问题,虽然 chatGPT 每个版本升级都在增加数据增加参数增加迭代增加自由度增加算力,但是仍然存在相对的短板。
所以很多行业都在研发自己的大模型,让别人解决共性问题,我们解决特性问题,不重复制造轮子。比如彭博社推出的面向金融的 BloombergGPT,学而思的 MathGPT,北大的 ChatLaw,都是顾名思义就知道是什么垂直领域的大模型。同样的,写代码有著名的 Copilot,那么当然也需要有专门为 BA 设计的 chatBA,专门做测试的 qaPilot。
对于广大各行各业的用户来说,对于大模型的需求就是只要自己本行业本领域内表现好就行了,股票大模型不需要会给恐龙化石做分类,通用大模型的某些能力用不到,却还要为此买单,岂不是心里很不爽?更况且垂直大模型的训练成本应该也远远低于通用大模型,甚至当前很多领域都还在数据建设阶段,现有的数据仓库数据湖的主体都还是传统数据结构,可能根本也没有那么多可用于训练的数据。
因此大模型的发展方向一定不会是一个或者一类综合的超级全能大模型,而是多领域大模型的组合。NLP、计算、逻辑等基础能力可能会被某些机构和组织垄断,形成 “基础模型提供者”,而更多的厂商会去竞争不同领域内的模型,就像操作系统和应用软件的关系。chatGPT 的强项在于 NLP,就专注做交互,作为前端接收用户的问题,然后分配给对应的领域大模型,必要时领域大模型还可以调用 app 的功能,最后汇总结果,NLP 根据情景遣词造句,生成合适的输出返回给用户。与其担心随着通用大模型的发展,花在垂直领域的资源打了水漂,还不如反过来考虑一下,如果有 Windows、Linux、Oracle 这种级别的基础能力大模型出现,花在通用大模型上的资源是不是打了水漂。实际上李飞飞等一大批学者早在两年前就在《基础模型的机遇和风险》(On the Opportunities and Risks of Foundation Models)中对大模型的同质化提出了警告。
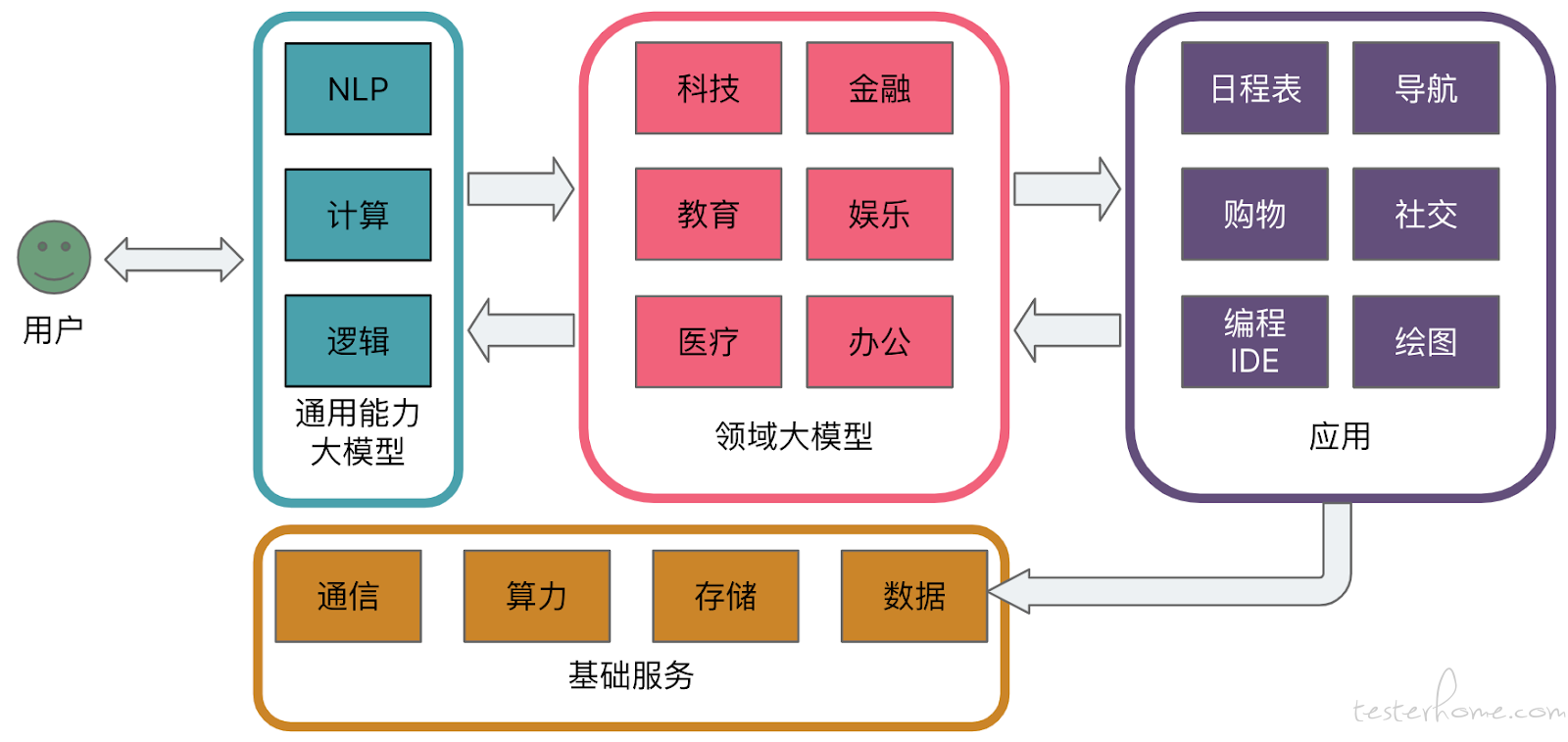
甚至随着需求的进一步提出,还会对每个垂直领域继续细分,比如 Copilot 继续细分出 Copilot-Python 和 Copilot-Java。对于程序员来说,这当然是个好消息——我指的不是 Copilot 会持续的进化,而是,只要人类还在继续提出问题,就一定需要专门的模型去解决这些问题,所以程序员需要持续技能进化,要做的事情一定越来越多。
失业的只是不能与时俱进的码字工。
AI 自从 50 年代提出概念,发展至今几起几落,每次的节奏完全一样,就是 “技术突破 -(被)画大饼 - 资本涌入 - 没有产品 - 凉凉” 循环上演。如今这个风口可以追溯到三十年前的深蓝。在过去的一年里 GenAI 和大模型火爆,的各行各业都表现出了浓厚的兴趣,纷纷畅想如何使用 chatGPT 为代表的各种大模型工具,然而接近年底,仍然罕见一个真正影响某个行业的成功实践案例,再加上因为众所周知的原因,很多行业如今都没有余粮,如果再不趁热解决产品落地的问题,早晚还是回到新一轮的圈圈里。
80 后应该都对 90 年代末的互联网泡沫记忆犹新,当时也是出现了一大批 “风口上的猪”。但是随着泡沫破裂,整个进入了多年的萧条。这其实是无法避免的,互联网在当时就是个新生事物,所有人都知道这将是一件强大的工具,但是没人知道该怎么使用它,因此当时那些雨后春笋般创业的公司,本质上就是气球里的大量分子在不同的方向做布朗运动,谁也不知道气球什么时候能被突破,突破口在哪,大家都在做各种尝试。所以泡沫对于互联网也未必全是负面影响,至少它让所有人认识了互联网,经过洗牌也孕育出了第一批互联网巨头,培养了从业者的技术兴趣,也摸索出了互联网的打开方式。
同样的剧情在电子商务、移动互联网、o2o 也都出现过,在 AI 领域的前几次浪潮里其实也在反复上演,只是 AI 的气球始终没有被突破。
大模型会捅破这个气球吗?
NFL 简单说就是有强项必有弱点,这太像日常生活的经验了,简直让我有种 “一切都被按照 NFL 设计,包括人类” 的恐惧感,甚至怀疑它不是真的。曾经也确实看到过一篇文章,大致是说算法理论有新突破,会打破 NFL。当时没仔细看完。粗略浏览,但是由于根深蒂固的对 NFL 的信任,导致我也没仔细盘一下作者的思路。当时没保存,写这篇的时候想回顾一下,但是再搜又找不到了。
知识越多的人总会越趋向保守,对陌生的观点有本能的排斥,更愿意相信能看懂的东西,从而保持自身在体系内的位置,因此才有了 “无知者无畏” 的说法。而机器可以调整算法,更快吸纳新数据,重塑模型,这大概是人类学习最难超越机器学习的方向吧。
