
之前总结了一篇基于现有业务线在停机重启时会产生RPC 和 MQ调用强杀导致业务数据不一致文章,文中通过优雅停机改造对 RPC 服务进行反注册和 MQ 进行暂停消费,进而可以解决在停机时强制 kill掉 RPC 线程或者 MQ 线程导致数据不一致现象,具体的原文大家感兴趣可以去看一下。Ok 前情提要结束,最近在一些核心应用上线重启的时候又出现了业务订单数据不一致的情况,通过排查定位发现还是因为停机不够优雅,罪魁祸首是定时任务执行时间过长,在上线重启的过程中定时任务没有执行完成而被强行 kill,详细分析及处理方案如下。
为了便于快速理解上线停机时导致业务数据不一致的的具体环节,简要的绘制一个业务流程图如下,其中以资金前置应用为例,定时任务运行在资金前置应用上,当涉及到资金前置应用的重启或者停机时,之前的优雅停机改造是会先把RPC 反注册和 MQ 暂停消费,然后在预留 60s的时间以供存活的线程执行完毕。其实这么做确实还是有缺陷的,就比如 60s 也不能确保所有的存活线程执行完毕,文中前言中所提到的问题就是这个,由于定时任务执行时间大于 60s,所以就会存在在定时任务尚未执行完成的情况下,强行把该定时任务给销毁掉了,恰巧两个数据表的更新还不在一个位置,导致停机完成的第 60s正好在其中的一个表更新完成和发送 MQ 去更新另一个数据表之间,这样就会存在两个表的数据不一致。
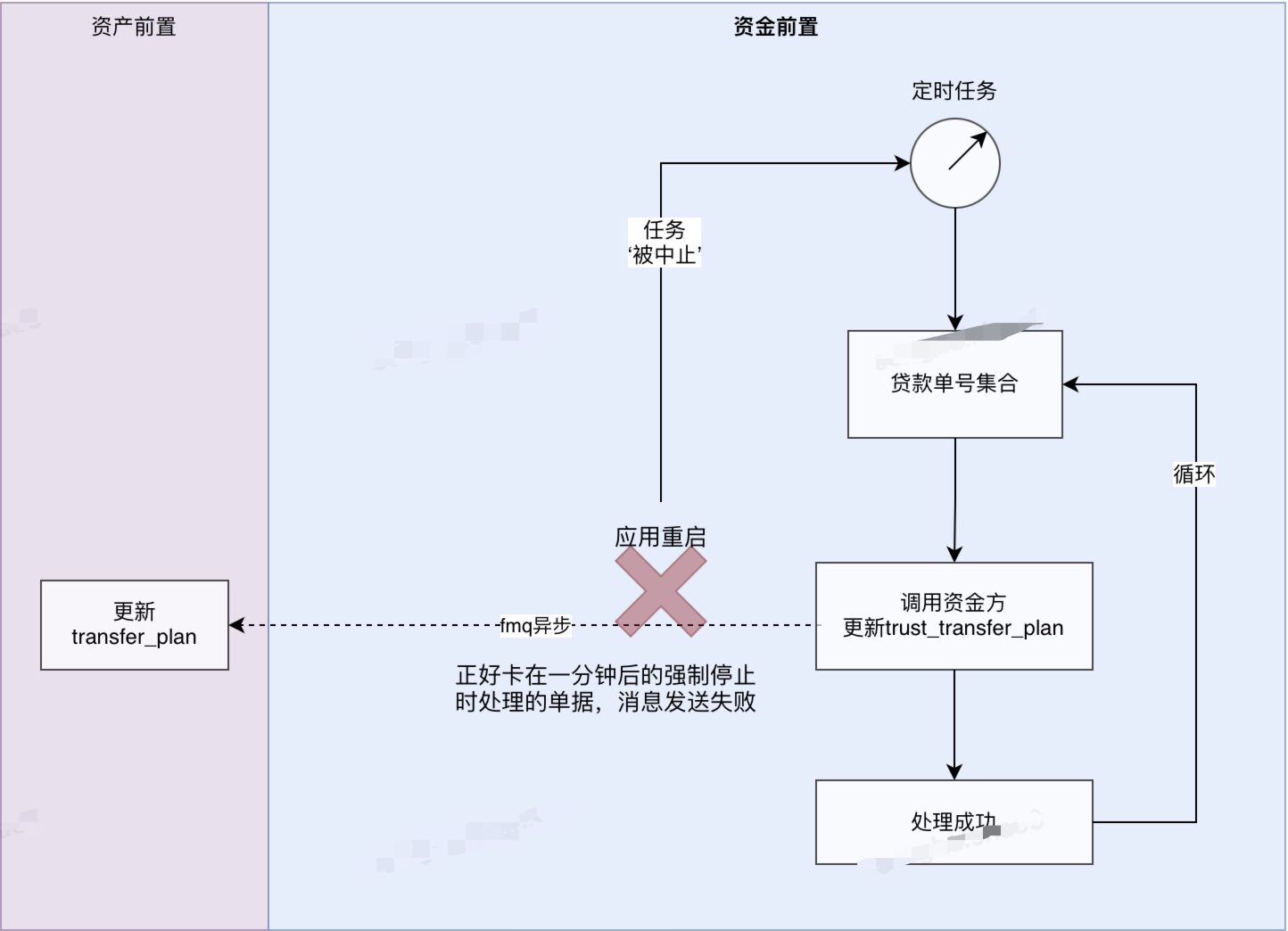
现有中断问题流程图
通过对上述问题的调研及分析,目前有以下几种解决方案。
当然这个方案治标不治本,降低定时任务的执行时间只能说会降低数据不一致产生的频次,即使将定时任务优化到执行完成进需要2s,上线的时候只要不刻意避开定时任务的执行的话,还是会存在在倒计时结束的第 60s时正好撞上定时任务正在执行的场景。不过还是借此机会排查了一下定时任务耗时的原因,其主要原因如下。其中以目前耗时比较长的定时任务(还款结果查回)为例。
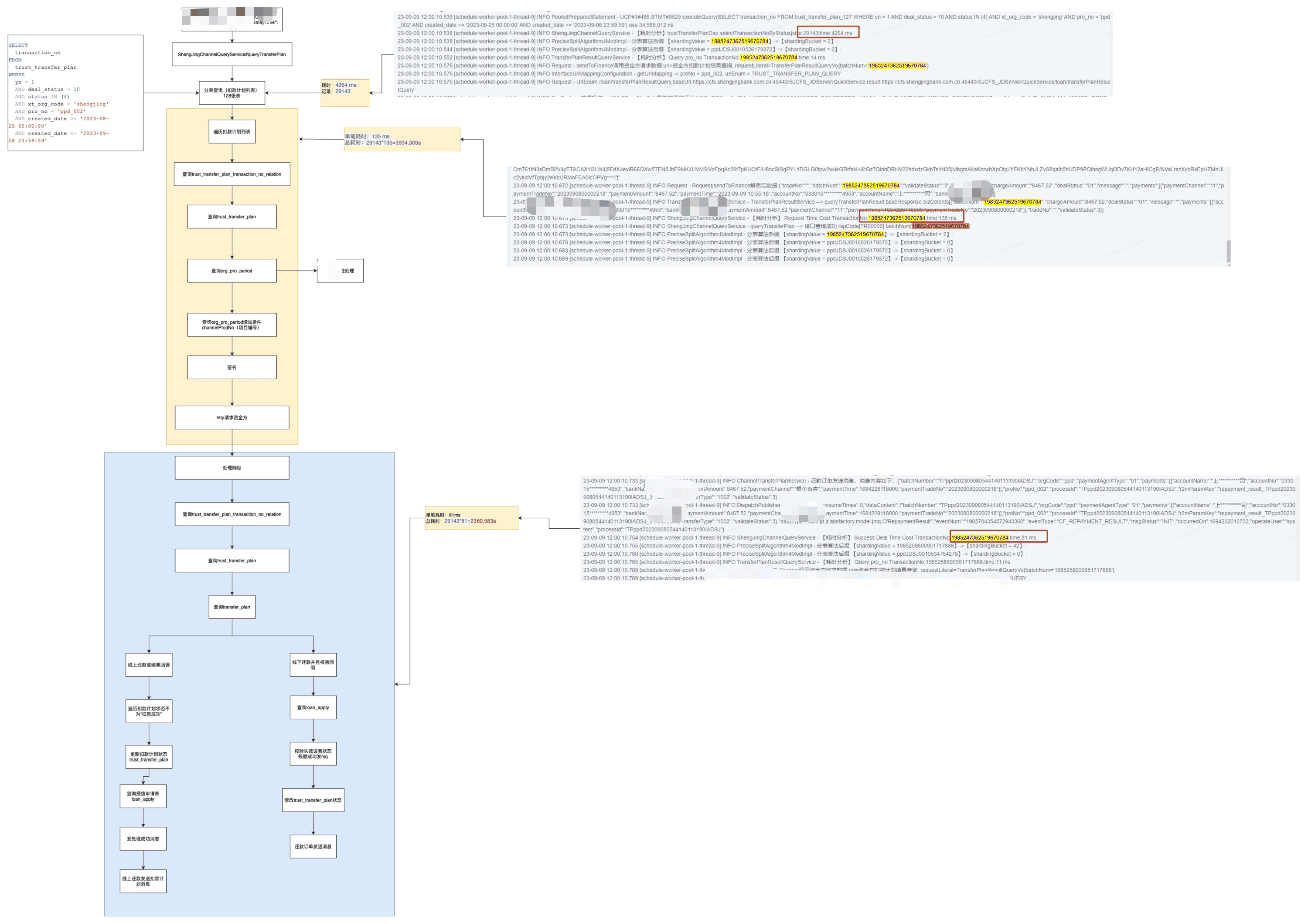
定时任务 1
通过梳理还款结果查询定时任务发现,主要的耗时点有两个:数据量大和并发量小。其中数据量大这个只能通过优化索引结构来降低耗时,并发量小可以通过拆分子任务或者修改代码批量发送数据到业务方来提速。
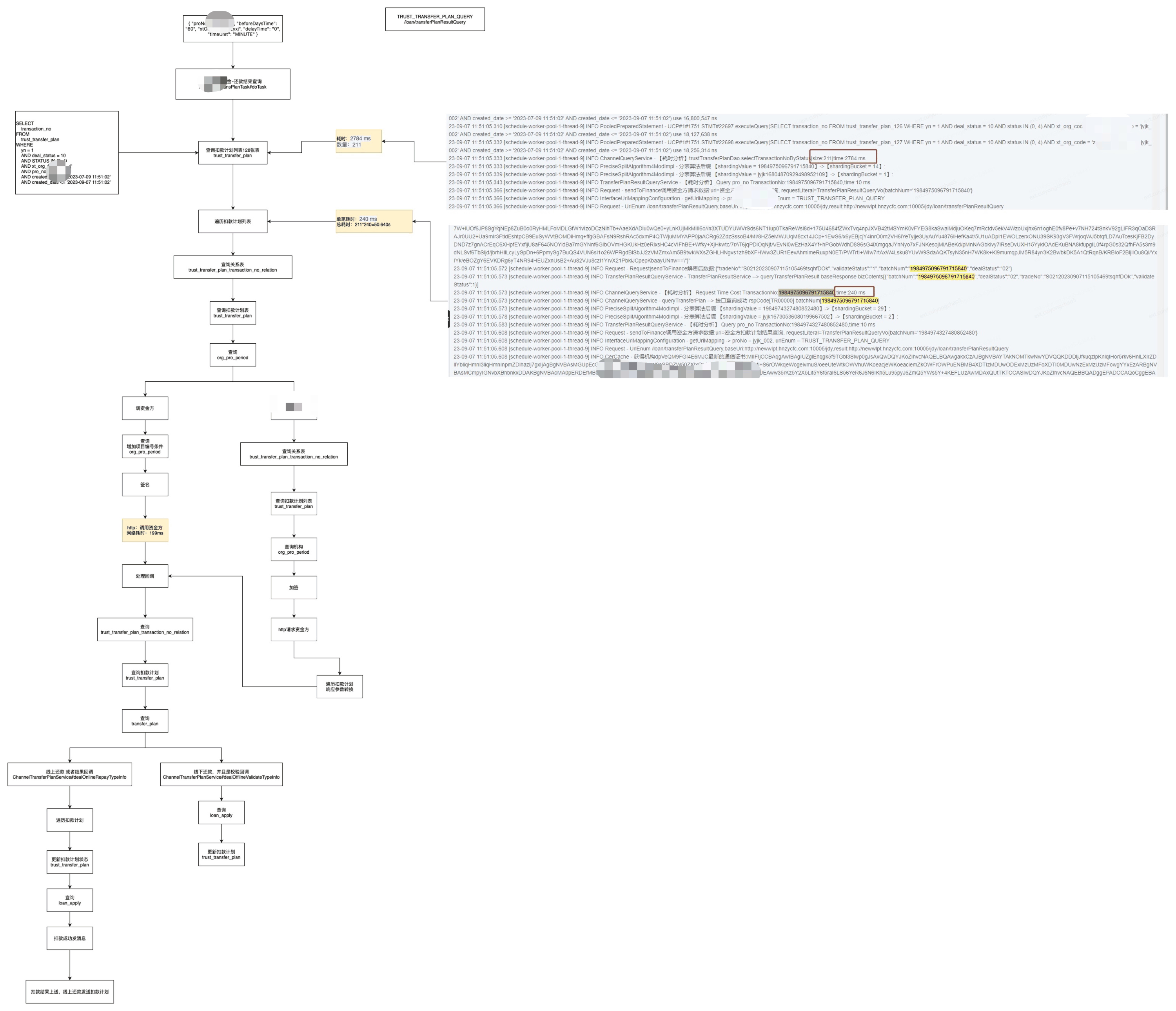
定时任务 2
同理,该定时任务制约因素同上。通过调研 EasyJob 平台发现提供了拆分子任务功能,可以通过平台拆分来降低耗时,并且不对现有的业务代码进行修改。emm,然而通过跟下游业务方沟通发现,受业务方并发 tps 制约,不建议通过此方式来提速。那降低耗时方案不是最佳的,可不可以通过设置一个全局变量呢?通过共享该变量的值,这样可以在停机的时候判断是否还有定时任务在处理。因此,方案二应运而生。
既然定时任务无论执行多少时间都可能会出现这个停机不优雅的问题,那么我们可以尝试增加一个全局变量,其主要作用是在定时任务中和优雅停机任务中共享达到优雅停机的目的。
@Component
@Slf4j
public class ShutDownHook {
/**
* 定时任务停止执行标识
*/
public static volatile int interrupt = 0;
@PreDestroy
public void destroyHook() {
try {
JobService jobService = schedulerFactoryBean.getObject();
if (null != jobService) {
boolean stop = jobService.stop();
if (stop) {
log.info("停止EasyJob完成。");
} else {
log.info("停止EasyJob失败");
}
} else {
log.info("停止EasyJob没执行");
}
} catch (Exception e) {
log.error("停止EasyJob异常", e);
}
interrupt = 1; //Easyjob停止后修改标识
}
}
@Component
public class xxxTask implements ScheduleFlowTask {
@Override
public TaskResult doTask(ScheduleContext scheduleContext) throws Exception {
transactionNoList.forEach(transactionNo ->{
if (0 != ShutDownHook.interrupt) {
throw new RuntimeException("停机中断");
}
// 业务逻辑
...
});
return TaskResult.SUCCESS_BLANK;
}
}
通过interrupt标识作为共享变量,这块就涉及到一个问题,如果多个线程同时修改这个变量会不会导致数据错误呢?为了避免出现和这个问题,在优雅停机脚本中我们使用volatile关键字来修饰该变量,通过先初始化停机标识interrupt,利用volatile关键字中的可见性(即:一个线程对其修改立即对其余线程可见)可以在停机脚本反注册掉定时任务服务后,修改该停机标识为 1,然后在定时任务执行业务逻辑数据更新时,每次执行前判断停机标识是否为 1(即是否已开始进行 EasyJob 服务反注册),假如停机脚本已经开始 EasyJob 服务反注册,则不继续进行后续业务逻辑操作,直接抛出运行时异常RuntimeException。
那么此时还有一个问题,定时任务在上线期间中断后,能不能在我们无感知的情况下进行重做呢?难不成我们每次都需要去根据异常来确认在上线期间是否存在定时任务中断,如果有的话难不成我们还要手动再次执行么?亦或者是等到定时任务的下一次自动执行的时间点执行?那么有没有一种方案可以自动立即重做呢?

自动失败重做机制
通过调研 EasyJob 定时任务平台发现提供了自动重做机制,通常我们一般部署的服务都是多台机器,即当我们上线的这台机器上面的定时任务执行中断后,可以通过配置自动重做机制来自动选择现有的存活的机器执行,其中自动重做里面中设置的参数如下:可以通过调整参数来控制第一次重做延迟时间、后续的重做时间间隔、以及最多重做次数。为什么要配置重做次数呢?一般机器上线是陆续进行的,极端情况下,定时任务执行时间完全覆盖了所有机器的上线时间,那么定时任务就会分别在每台机器上面中断一次,最终还是回归到最开始的那台机器上面继续执行(此刻该机器已上线完成)。所以针对定时任务时间执行比较长的,需要根据实际机器设置合理的重做次数。
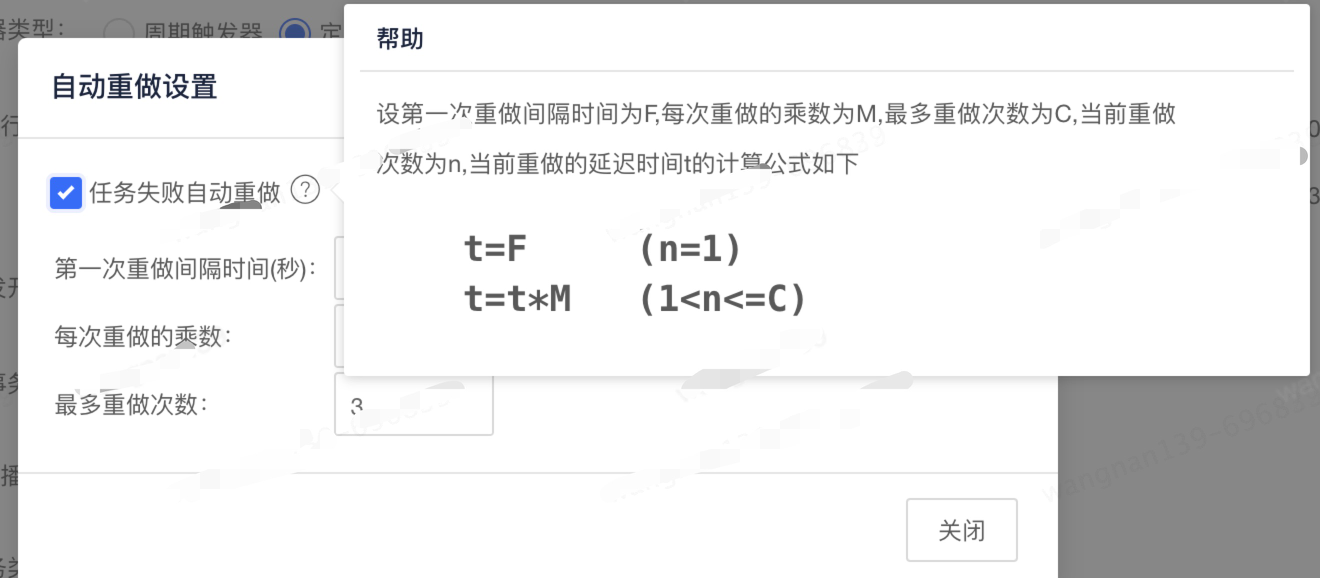
参数详情
另一个方案其实就是融合了方案一(拆分子任务)和方案二(共享信号量),这样的好处就是能够解决在 3.2 节末尾提到的上线期间极端情况下,定时任务执行时间过长而在没台机器上都中断重做场景。但是受限场景和方案一也是一致的,目前受下游业务方能够接受的最大并发限制而暂缓实施。
因为涉及到更新两个数据表操作,要想避免两个数据表数据不一致,最常用的做法就是把更新两个数据表的操作封装成一个事务操作,这样的话就无需考虑定时任务的执行时间,由于事物的原子性,肯定不会出现两个数据表的数据不一致情况。当然这个方案的缺点就是需要重构现有的业务逻辑,需要把 MQ 的下游重构,把两个数据表的更新位置重构一下。这块对现有的业务逻辑代码有侵入,并且需要重构现有的业务流程,目前不太建议这么修改。
ok,通过这次优化应该能够使得现有的应用在重启或者是上线停机时,能够避免定时任务中断而导致的数据更新不一致场景。以上是优雅停机第二弹内容。以上。
作者:京东科技 宋慧超
来源:京东云开发者社区 转载请注明来源
