
目前,大模型的发展已经非常火热,关于大模型的训练、微调也是各个公司重点关注方向。但是大模型训练的痛点是模型参数过大,动辄上百亿,如果单靠单个 GPU 来完成训练基本不可能。所以需要多卡或者分布式训练来完成这项工作。
1.1 目前主流的大模型分布式训练主要包括两种:
DeepSpeed 是由 Microsoft 提供的分布式训练工具,旨在支持更大规模的模型和提供更多的优化策略和工具。对于更大模型的训练来说,DeepSpeed 提供了更多策略,例如:Zero、Offload 等。
分布式训练需要掌握分布式环境中的基础配置,包括节点变化、全局进程编号、局部进程编号、全局总进程数、主节点等。这些组件都跟分布式训练紧密相关,同时组件之间也有非常大的联系,例如通信联系等。
既然是分布式训练,那机器之间必须要保持通信,这样才可以传输模型参数,梯度参数等信息。
DeepSpeed 提供了 mpi、gioo、nccl 等通信策略
| 通信策略 | 通信作用 |
|---|---|
| mpi | 它是一种跨界点的通信库,经常用于 CPU 集群的分布式训练 |
| gloo | 它是一种高性能的分布式训练框架,可以支持 CPU 或者 GPU 的分布式训练 |
| nccl | 它是 nvidia 提供的 GPU 专用通信库,广泛用于 GPU 上的分布式训练 |
我们在使用 DeepSpeed 进行分布式训练的时候,可以根据自身的情况选择合适的通信库,通常情况下,如果是 GPU 进行分布式训练,可以选择 nccl。
Microsoft 开发的 Zero 可以解决分布式训练过程中数据并行和模型并行的限制。比如: Zero 通过在数据并行过程中划分模型状态(优化器、梯度、参数),来解决数据并行成可能出现内存冗余的情况(正常数据并行训练,模型全部参数是复制在各个机器上的);同时可以在训练期间使用动态通信计划,在分布式设备之间共享重要的状态变量,这样保持计算粒度和数据并行的通信量。
Zero 是用于大规模模型训练优化的技术,它的主要目的是减少模型的内存占用,让模型可以在显卡上训练,内存占用主要分为Model States和Activation两个部分,Zero 主要解决的是 Model States 的内存占用问题。
Zero 将模型参数分成三个部分:
| 状态 | 作用 |
|---|---|
| Optimizer States | 优化器在进行梯度更新的时候需要用到的数据 |
| Gradient | 在反向转播过程中产生的数据,其决定参数的更新方向 |
| Model Parameter | 模型参数,在模型训练过程中通过数据 “学习” 的信息 |
Zero 的级别如下:
| 级别 | 作用 |
|---|---|
| Zero-0 | 不使用所有类型的分片,仅使用 DeepSpeed 作为 DDP |
| Zero-1 | 分割 Optimizer States, 减少 4 倍内存,通信容量和数据并行性相同 |
| Zero-2 | 分割 Optimizer States 和 Gradients,减少 8 倍内存,通信容量和数据并行性相同 |
| Zero-3 | 分割 Optimizer States、gradients、Parametes,内存减少与数据并行度呈线性关系。例如,在 64 个 GPU(Nd=64)之间进行拆分将产生 64 倍的内存缩减。通信量有 50% 的适度增长 |
| Zero-Infinity | Zero-Infinity 是 Zero-3 的扩展,它允许通过使用 NVMe 固态硬盘扩展 GPU 和 CPU 内存来训练大型模型 |
相比 GPU,CPU 就相对比较廉价,所以 Zero-Offload 思想是将训练阶段的某些模型状态放(offload)到内存以及 CPU 计算。
Zero-Offload 不希望为了最小化显存占用而让系统计算效率下降,但如果使用 CPU 也需要考虑通信和计算的问题(通信:GPU 和 CPU 的通信;计算:CPU 占用过多计算就会导致效率降低)。
Zero-Offload 想做的是把计算节点和数据节点分布在 GPU 和 CPU 上,计算节点落到哪个设备上,哪个设备就执行计算,数据节点落到哪个设备上,哪个设备就负责存储。
下图中有四个计算类节点:FWD、BWD、Param update 和 float2half,前两个计算复杂度大致是 O(MB), B 是 batch size,后两个计算复杂度是 O(M)。为了不降低计算效率,将前两个节点放在 GPU,后两个节点不但计算量小还需要和 Adam 状态打交道,所以放在 CPU 上,Adam 状态自然也放在内存中,为了简化数据图,将前两个节点融合成一个节点 FWD-BWD Super Node,将后两个节点融合成一个节点 Update Super Node。如下图右边所示,沿着 gradient 16 和 parameter 16 两条边切分。
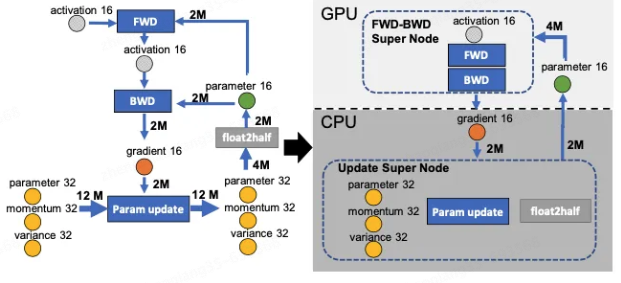
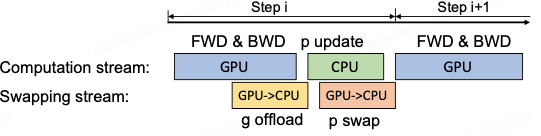
在 GPU 上面进行前向和后向计算,将梯度传给 CPU,进行参数更新,再将更新后的参数传给 GPU。为了提高效率,可以将计算和通信并行起来,GPU 在反向传播阶段,可以待梯度值填满 bucket 后,一遍计算新的梯度一遍将 bucket 传输给 CPU,当反向传播结束,CPU 基本上已经有最新的梯度值了,同样的,CPU 在参数更新时也同步将已经计算好的参数传给 GPU,如下图所示。
混合精度训练是指在训练过程中同时使用 FP16(半精度浮点数)和 FP32(单精度浮点数)两种精度的技术。使用 FP16 可以大大减少内存占用,从而可以训练更大规模的模型。但是,由于 FP16 的精度较低,训练过程中可能会出现梯度消失和模型坍塌等问题。
DeepSpeed 支持混合精度的训练,可以在 config.json 配置文件中设置来启动混合精度("fp16.enabled":true)。在训练的过程中,DeepSpeed 会自动将一部分操作转化为 FP16 格式,并根据需要动态调整精度缩放因子,来保证训练的稳定性和精度。
在使用混合精度训练时,需要注意一些问题,例如梯度裁剪(Gradient Clipping)和学习率调整(Learning Rate Schedule)等。梯度裁剪可以防止梯度爆炸,学习率调整可以帮助模型更好地收敛。
DeepSpeed 方便了我们在机器有限的情况下来训练、微调大模型,同时它也有很多优秀的性能来使用,后期可以继续挖掘。
目前主流的达模型训练方式: GPU + PyTorch + Megatron-LM + DeepSpeed
优势
参考:
1. http://wed.xjx100.cn/news/204072.html?action=onClick
2. https://zhuanlan.zhihu.com/p/513571706
作者:京东物流 郑少强
来源:京东云开发者社区 转载请注明来源
