锦礼平台,作为一家企业级 B2B2C 电商平台,同时服务于企业客户和企业员工,因此需要遵循企业客户的政策规范,确保商城内商品符合规定,并提升员工购物体验。然而,这种独特的运营模式导致锦礼平台上商品的可见不可售问题较为突出,对最终消费者的购物体验和平台的产品和业务产生了较大的负面影响。
如题,之所以说是小技巧,是因为我们并没有使用一些高精的技术,只是把多种成熟技术结合加入一些算法而已。
以下是我们经历的 3 个版本的方案迭代,也代表着一个技术人从技术思维到业务思维的转变
版本 1.0:我们尝试在不可售商品上增加一个遮罩,标注其不可售的原因,以防止客户误操作。然而,这种方法并未完全解决问题,因为消费者可能仍然对某些商品为何不可售(例如为何在锦礼平台无法购买黄金,或为何看到的商品被列入黑名单)感到困惑。
版本 2.0:我们努力提升搜索的效率,加快不可售商品出库的速度,并优化商品同步的机制,以降低不可售商品的出现频率。然而,随着锦礼平台不可售规则的扩展(如定价规则和价格倒挂限制等),这种定制化的方式对搜索团队来说过于复杂。
版本 3.0:随着我们对消费者需求的深入理解,我们逐渐意识到,虽然我们前期的手段降低了不可售的商品的即使平台上只出现一个不可售商品,也可能会对消费者的购物体验造成损失。因此,我们需要运用技术手段将这些商品 “隐藏” 起来。
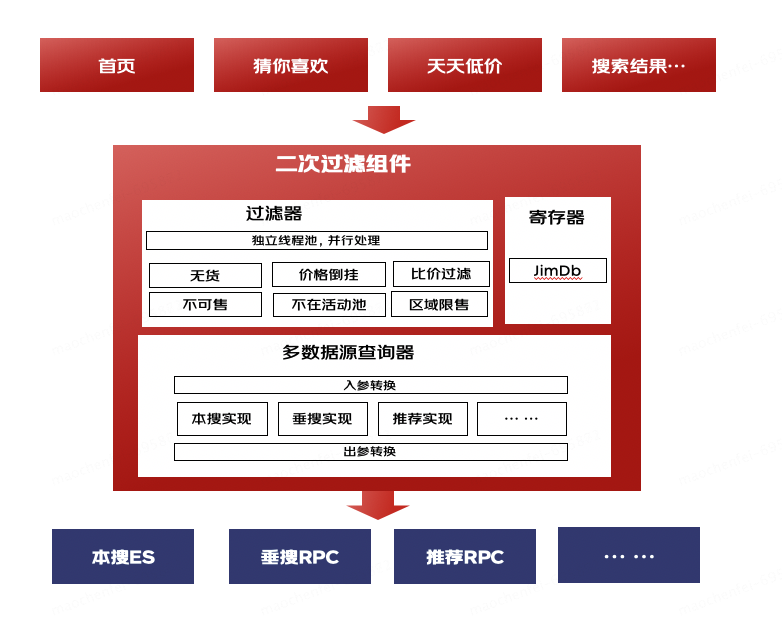
图 1 二次过滤工具
在进行到 3.0 的时候,我们首先推演了以下两种方案:
然而,上述技术方案的缺点也是显而易见的:
针对前端预加载可能导致前端业务逻辑复杂化、引入后端轮询可能出现数据同步问题,我们进行了一系列的优化。
我们引入了寄存器和过滤器两个重要组件,对原始请求进行合理的调度和处理。
首先,寄存器用于临时存储商品数据,这样前端每次只需要从前端发送请求到寄存器,就可以获取到最新的商品数据,避免了后端轮询的重复请求和超时问题。
其次,过滤器则用于对商品数据进行筛选和处理。在获取到最新的商品数据后,过滤器会根据一定的规则对数据进行筛选,将符合政策规范和用户需求的商品数据筛选出来,并将其展示给用户。同时,对于不符合政策规范或存在违规商品的商品数据,过滤器将其隐藏或标记为不可售,以防止用户误操作购买违规商品。
通过这样的优化,我们既避免了前端业务逻辑复杂化的问题,也解决了后端轮询可能出现的数据同步问题。同时,改造后的接口仍然是一个普通的 REST 接口,前端和后端都可以轻松理解和使用。
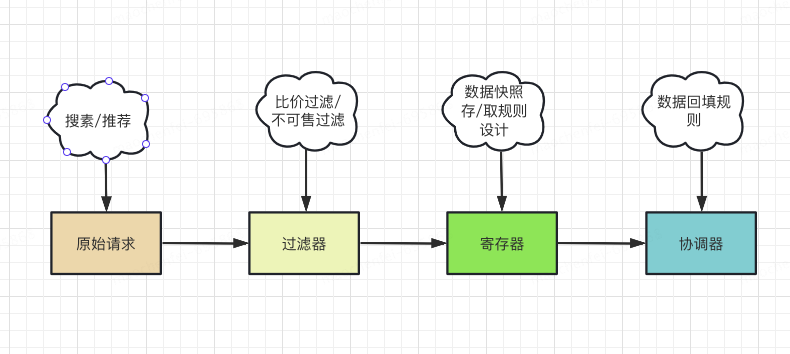
图 2 过滤工具的组成
以下是各个环节的职能介绍
原始请求 (orgin request)
常见的列表请求有以下三种:
1、第三方提供的查询服务,RPC 分页请求,比如搜索商品列表 RPC 接口、推荐商品列表 RPC 接口
2、数据库查询,mybatis 分页查询,可以利用自增主键 id,做后续请求
3、ES 搜索查询,ES 分页查询,滚动查询
入参:PageParams, 标准分页请求参数,T 为真实的分页请求对象
出参:PageResult,标准分页返回参数,R 为真实分页请求返回对象
SDK 的实现基于泛型开发,调用方需要按照规范自定义实现该方法
过滤器 ( customer filter )
入参:List< R > sourceData,原始的返回结果列表
出参:List< R > targetData,筛选过滤后的结果列表
SDK 的实现基于泛型开发,调用方需要按照规范自定义实现该方法
寄存器(storage register )
通过缓存中间件实现,临时寄存查询结果,前端请求过来后优先从寄存器获取。将请求参数通过算法压缩,保证相同的请求参数,可以得到相同的值,来确定是否是同一查询条件的请求。
寄存器的 key 结构如下:
scroll_id : pin&actiivtyCode&uid&查询入参 MD5 压缩算法,
另,查询入参需要排除掉页码以及动态变化的参数
存储内容:缓存补齐分页后剩余的数据快照、前端请求页码、实际后端请求页码
协调器( coordinate )
协调器实现数据的补充和寄存器数据快照的查询、存入和取出,以及分页相关数据的更新
1、协调器根据原始前端请求,后端实际请求扩大步长,进行后续数据的拉取
2、前后端固定步长进行请求,比如前端每次请求 10 条,后端每次请求 20 条,步长比,可以根据实际情况动态调整
3、请求深度和前后端步长比通过 ducc 进行控制。 例如:前端每页请求 10 条数据,步长比为 3,则后端每次请求每页 30 条数据;请求深度为 2,则如果请求两次如果仍不符合要求则强制停止。客户维度定制请求参数
{
"DEFAULT": {
"deep": 2,
"multiple": 3
},
"营销测试2": {
"deep": 2,
"multiple": 5
},
"呼铁福利商城采购账号": {
"deep": 2,
"multiple": 4
}
}
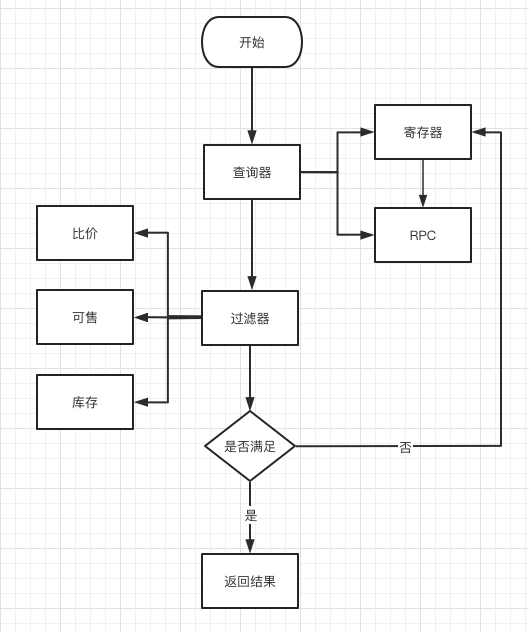
图 3 数据二次过滤流程图
我们将数据二次过滤拆分为以下四个阶段:
Query 阶段:
接收前端请求,根据寄存器中数据的大小,决定后端接口请求,后端按前端 N 倍步长进行 RPC 请求,将命中的结果,在缓存中创建一个优先队列快照,并通过 scroll_id(C 维度的缓存 key)指向它,lastPageNo 指向上次访问的页码,realPageNo 指向真实访问的页码
Filter 阶段:
读取过滤规则,进行数据过滤的实现,常用的过滤规则,比如:不可售、无货、价格高于市场价等,不符合规则的数据直接移除掉
Cache 阶段:
• 如果过滤后数据小于前端请求步长,则继续进入 Query 阶段,进行优先队列快照数据补充
• 如果过滤后数据大于等于前端请求步长,则直接返回 pageSize 的数据列表,剩余数据放入优先队列快照中
• 后端请求深度暂设置为 2 次,如果两次后端请求,过滤后的数据仍不满足前端请求步长,则不再继续请求
• 如果后端请求多次返回失败,则及时熔断,返回寄存器内剩余数据,且返回结果标识非最后一页
Fetch 阶段
通过以上两个阶段,我们可以获取到符合前端请求步长的数据集,补充其他附属信息后进行,返回分页的数据结构
初次之后查找数据,在 Query 阶段通过 scroll_id 找到对应的快照,然后用 lastPageNo,realPageNo 将原来的查询语句添加查询条件( pageNo=realPageNo + 1),在快照中找数据。
技改方案上线后,集中观测中秋流量,日常千万级的商品过滤次数,平均每次请求过滤 3-4 个商品
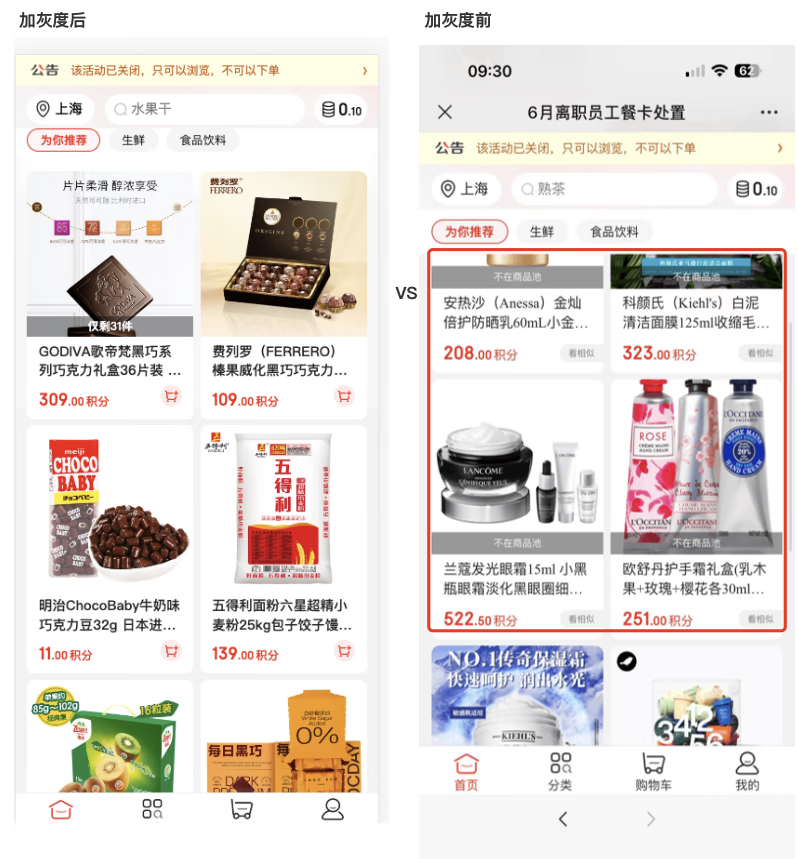
图 4 二次过滤开启前和开启后的效果
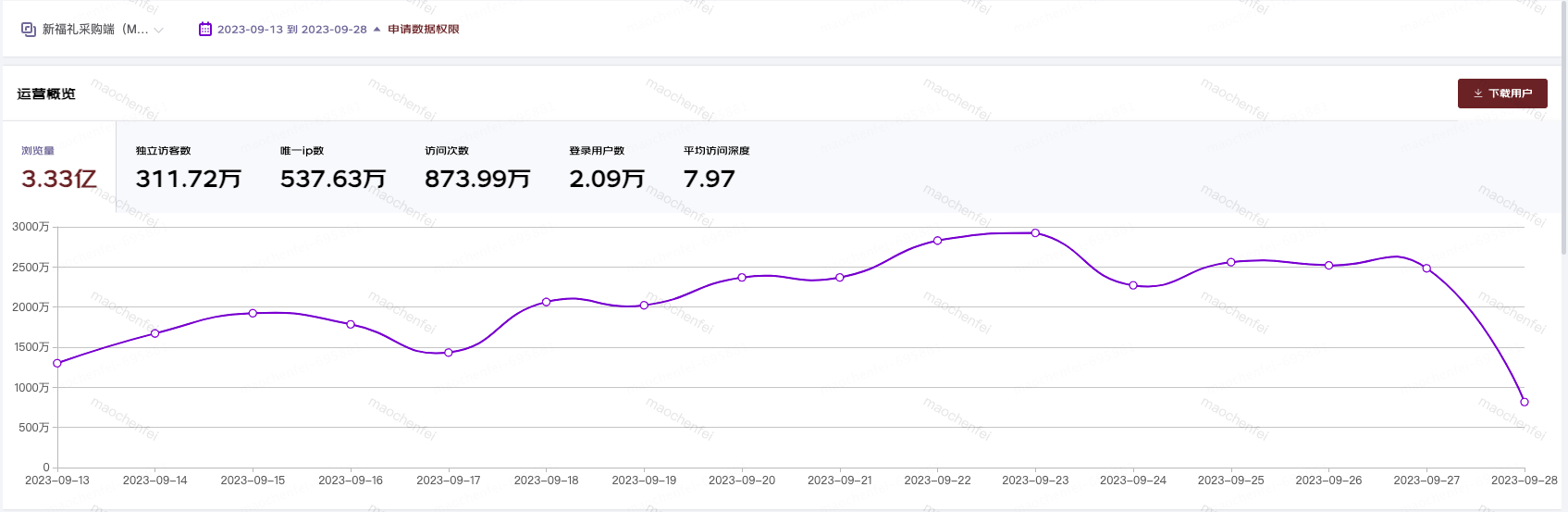
图 5 中秋期间锦礼平台流量
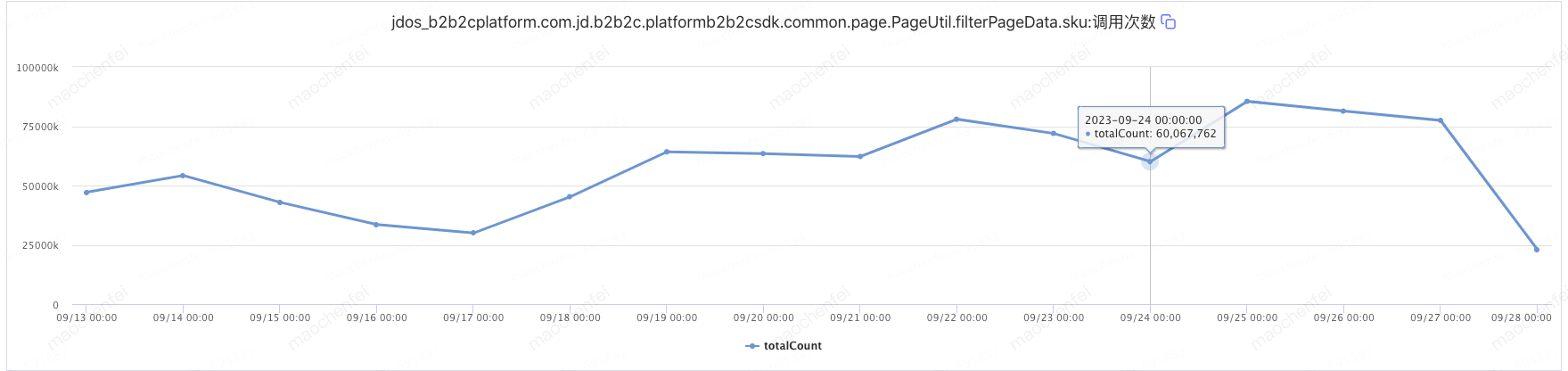
图 6 中秋期间商品过滤的次数
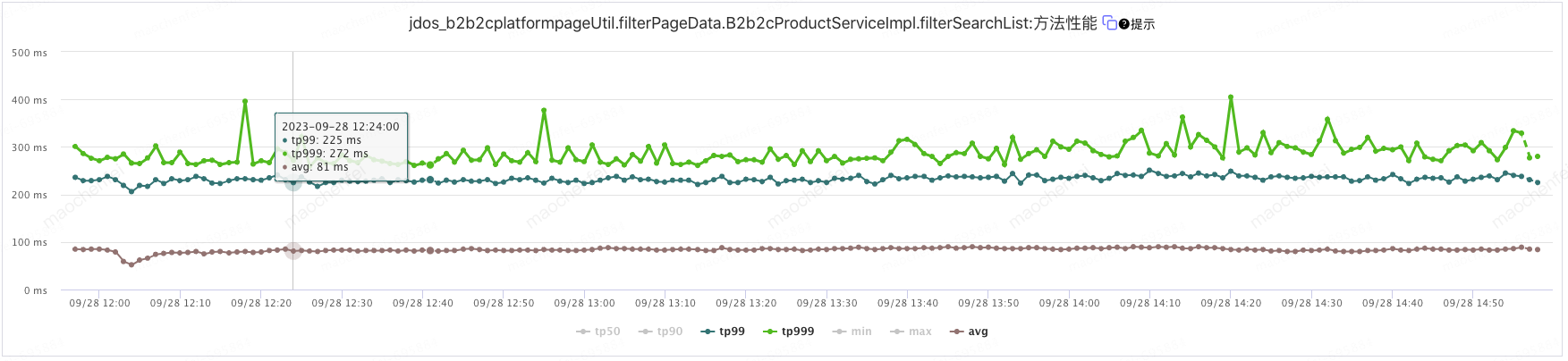
图 7 商品搜索过滤后的接口性能
在产品迭代演进中,我们坚信,技术能够为我们的业务带来无限可能。它能帮助我们创新、优化流程、提升效率。同时,我们也明白,技术并非万能的。但正是对技术的这种深深敬畏,让我们始终保持谦逊和开放的心态,使我们始终能找到新的突破口,超越自我。
一个小小的技巧,也可以给业务带来大大的价值!!!
作者:京东零售 毛辰飞
来源:京东云开发者社区 转载请注明来源
