作者:薛金库 | QE_LAB
近几年,随着微服务、云原生技术的快速发展,服务应用的数量正以前所未有的速度增长,再加上容器化与高频率的 CI/CD,进一步加剧了软件系统的复杂性。与之而来的系统可观察性作为应对这一复杂性的利器也成为了当下软件领域的一个热门主题。
“可观察性” Observability 一词最初来自于控制论,是由匈牙利裔工程師鲁道夫·卡尔曼针对线性动能系统提出的概念,今天,我们将其用于软件系统,用来描述系统可以由其外部输出推断其内部状态的程度(可观察性 -- 维基百科)。
一般而言,系统的可观察性越高,也就意味着我们对系统当前内部运行状态就越了解,一旦系统运行出现问题,我们也就能越迅速、越准确地定位问题并找到根因,而不需要进行额外的 debug 调试来定位问题。
生活中,汽车的仪表盘作为汽车的一部分,向驾驶者显示了当前汽车的状态信息,如发动机转速,当前车速,剩余油量等,现代汽车的液晶仪表盘更是增加了胎压显示、油耗等信息,这些信息的可观察使得驾驶者能够更多的了解到汽车的行驶状态,从而更加有信心、更加安全的驾驶。
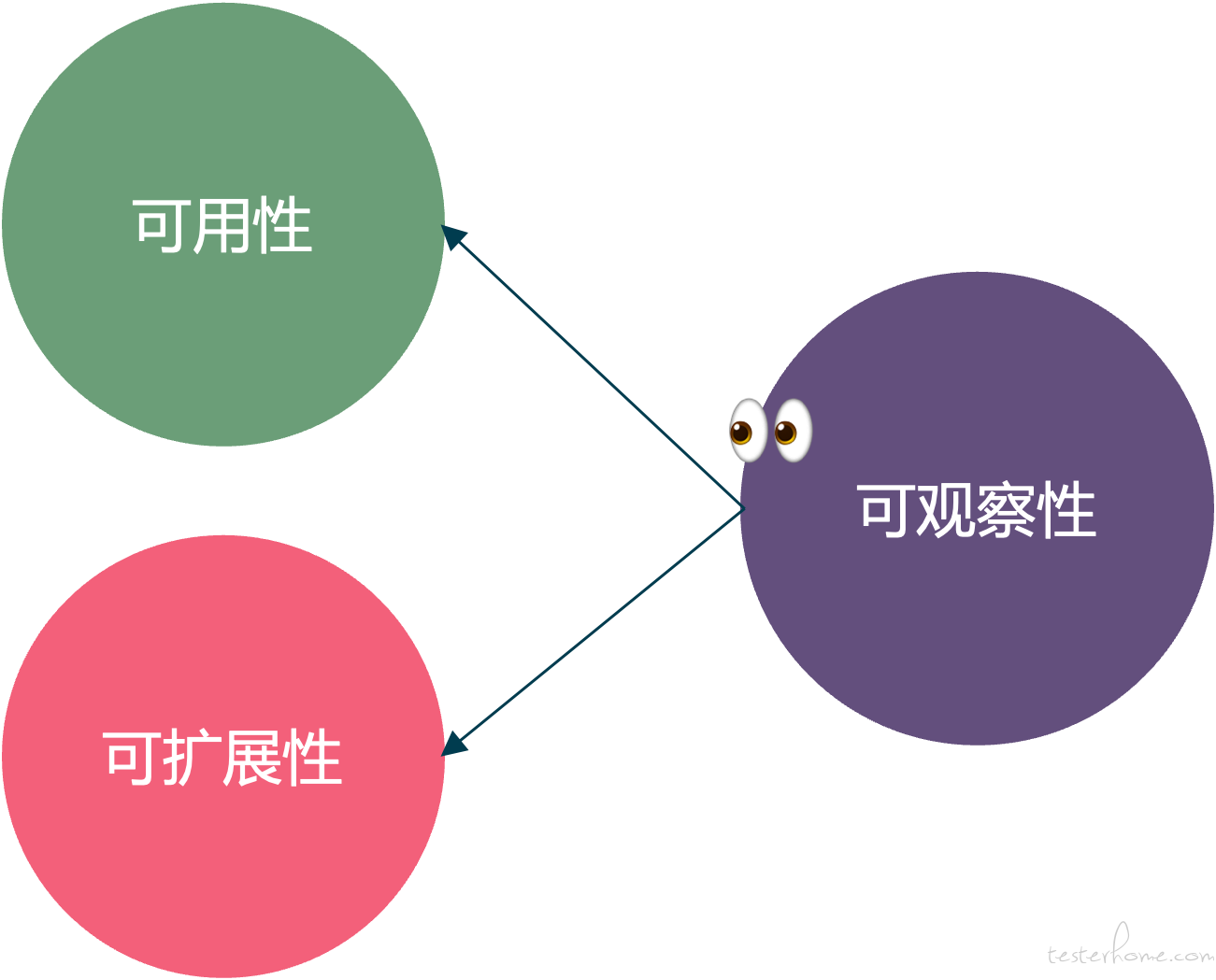
早期的软件系统,我们比较关注于系统的可用性与可扩展性,现在的软件系统正变的日益复杂,不但要满足基本的可用性,可扩展性,还应该具备可观察性:
如果所有其他条件都一样,可观察性强的系统与传统的系统相比:
可观察性作为一个相对较新的 IT 主题,常常被误认为就是 “监控” 或者 APM。简单来做下对比。
APM,即应用程序性能监控,是指使用软件工具和遥测数据来监控业务应用程序关键性能指标的实践。通过 APM 可以确保系统可用性,优化服务性能和响应时间,改善用户体验。
与传统监控/APM 相比:
早期的系统我们使用 APM 进行系统性能监控,而面对复杂架构的现代分布式应用的故障排查时, APM 就有些力不从心了。可观察性是在 APM 基础上进一步发展而来。
近年来越来越多的关于可观察性的项目/工具不断涌现出来,CNCF-Landscape 也增加了Observability and analysis 分组。我们在做可观察性的技术选型时可以参考。

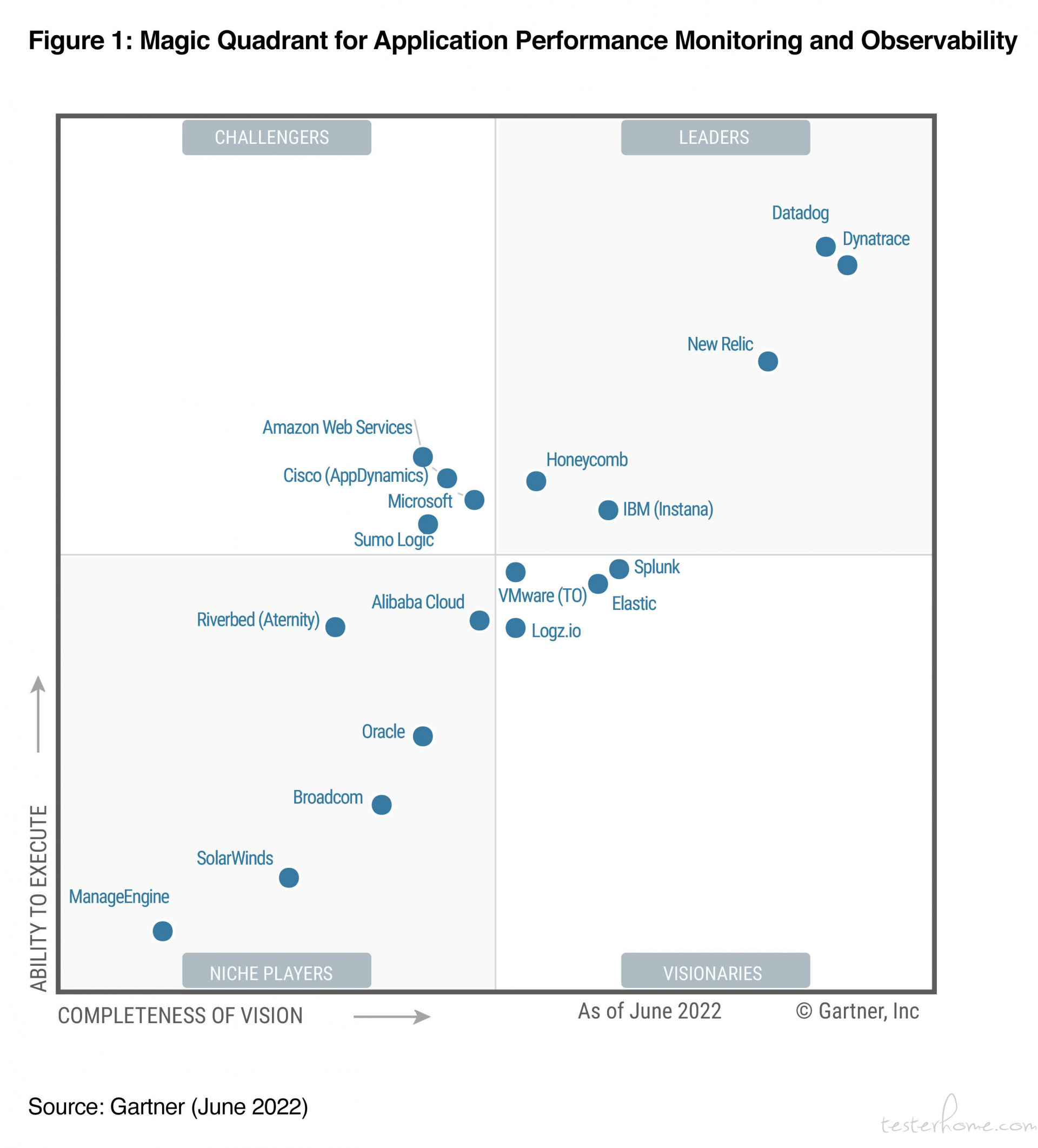
Gartner 也给出了针对可观测性的魔力四象限 (Gartner Magic Quadrant),从中可以看到众多提供可观察性服务的供应商,主流的有 Datadog、Dynatrace、 New Relic、Splunk、Elastic 等,还有一些云服务商。
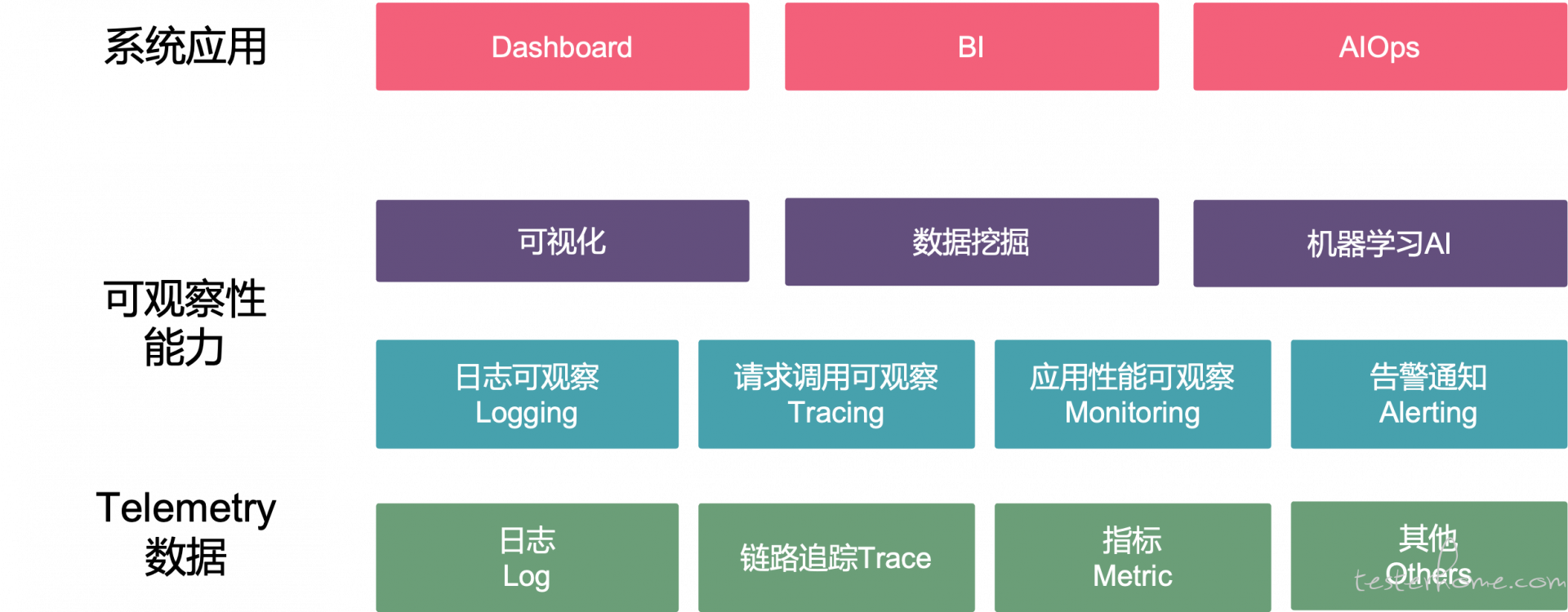
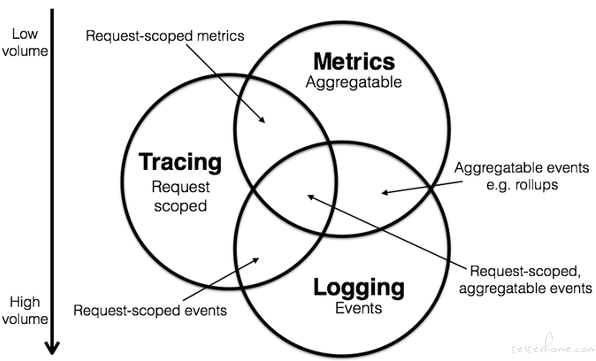
可观察性的 telemetry data 即遥测数据主要包含三种类型——logging 日志, metrics 指标、和 tracing 分布式链路追踪, 合在一起我们称之为可观察性三大支柱。
日志,想必大家再熟悉不过了,日志作为一个可运行的、可维护的软件的基础组成部分。通过日志,我们可以了解软件系统在运行中的实时状态,历史状态和异常状态等,日志也可供开发人员 “回放” 以进行系统的诊断和调试。一个没有良好日志的软件是所有人的噩梦,如果你不想给自己找麻烦,那么请你把日志好好写。
日志的特点:
链路追踪表示请求经由所有系统服务时所发生的一系列事件。
现在的系统架构往往都采用分布式微服务架构,一次客户端请求调用往往需要跨多个服务。
链路追踪会记录每个用户请求的端到端 “旅程”,即从 UI 或移动端开始,经过整个分布式服务调用链,再回到用户端的过程。
指标是描述一段时间内的系统的行为和性能的数字,是以一种量化的形式反映系统的状态。
指标的特点:
指标的类型:
按其数据特点主要分为四种:Counter、Gauge、Histogram、Summary,参见 prometheus metric types,prometheus 指标类型。
不同数据源指标:

三者的组合将会产生丰富的可观察数据,日志和指标可以揭示系统应用程序的行为和性能,分布式链路追踪可以得到业务请求的调用链路。通过链路追踪将日志关联起来,而日志又可以为指标提供更详细的上下文信息。可观察性综合了日志、指标和分布式链路追踪,将整个应用服务的请求数据、性能指标进行收集汇总,可视化地还原业务请求在分布式系统中的执行轨迹和系统运行的状态。
在可观察性提出之前,我们之前的项目实践中也陆续给系统构建了 logging、tracing、monitoring & alerting 等系统所需的能力,也一直在思考如何来抽象和概括这些能力,可观察性提出后,可观察性可以很好的囊括这些能力,且将其称之为可观察性系统的四项基本能力吧。在可观察性的主题下我们可以融合这些技术能力,来构建和提升系统的可观察性。接下来将结合我们之前的项目实践介绍一些主流的工具/平台。
早期的单体应用时代,系统应用都是大单体,单实例,日志就存储在服务所运行的服务器上,可以登录到服务器上查看系统日志,那时候日志源单一,日志查询相对容易,后面考虑到高可用,进行多实例集群部署,日志分散在不同服务器,查看日志时往往要综合多个服务器上的日志。而现在的微服务、云原生技术,使得服务的数量,服务的实例数进一步增长,日志也都分布在不同的容器或者 k8s 的 pod 中,使得日志进一步分散,变化,导致查看日志变得愈加复杂和困难。这个时候我们需要构建日志平台,进行日志的统一收集、存储、查询。
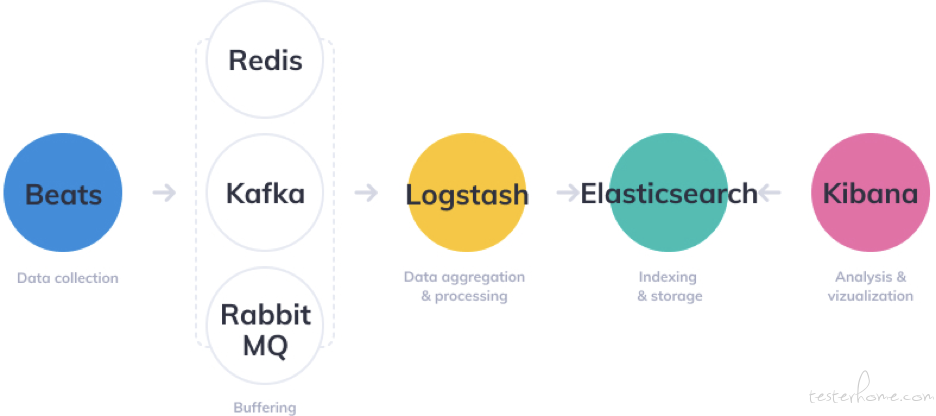
构建日志平台比较常见的工具有 ELK 和 Sumologic。
(1)ELK 是 Elasticsearch、Logstash、Kibana 的简称,是业内流行的开源实时日志分析平台,配套组件有:
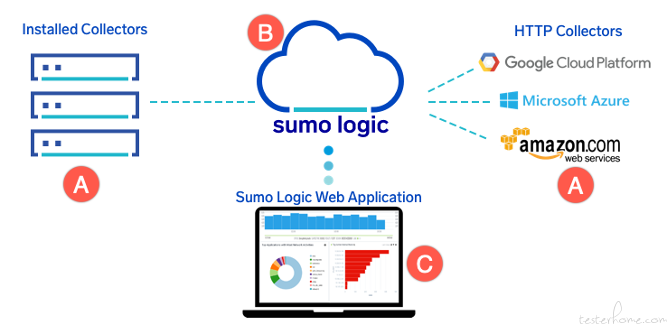
(2)Sumo Logic 是 SaaS 模式的日志管理平台,可以从容器、http Server 多数据源收集数据并进行存储、分析和查询,不过需要付费。
Tracing 的三种标准:

Tracing 比较常见的工具有 Zipkin,Jaeger,SkyWalking。
Monitoring 和 Alerting 的能力可以使用主流的 APM 的工具来构建。如 Elastic APM、Promethues + Grafana + AlertManager。
我们在做可观察性的技术选型时需要考虑以下几点:
(1)系统自身的技术栈,如系统的语言、框架,系统的运行和部署方式,是传统应用还是云原生的应用。确保技术栈兼容,适合。
(2)系统的能力需要,根据系统的能力需要选择合适的工具。如系统缺失 tracing 的能力,那么只需要为其添加 tracing 的能力即可。
(3)预计投入的精力与支出,是否容易集成,是分别构建各项能力,还是选择可观察性的整体解决方案,是选择开源工具还是付费产品。
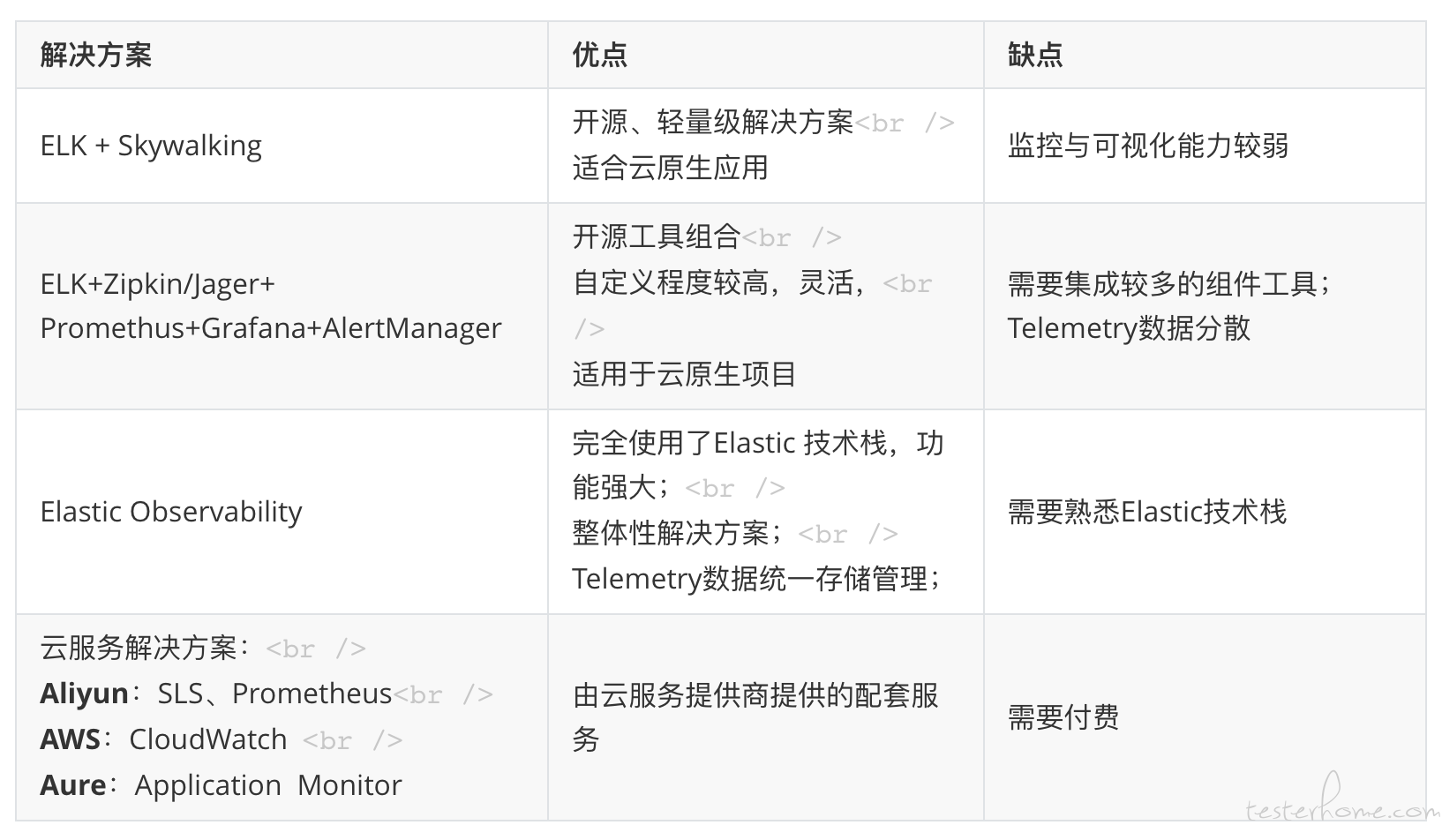
方案对比:
在敏捷开发团队中,每个角色:PO, BA, Dev, Devops, QA,TL 都应该具有可观察性意识,团队中的每个人都应该能够从系统中获取他们想要的数据。做到这点需要团队将可观察性融入到整个敏捷开发过程中。
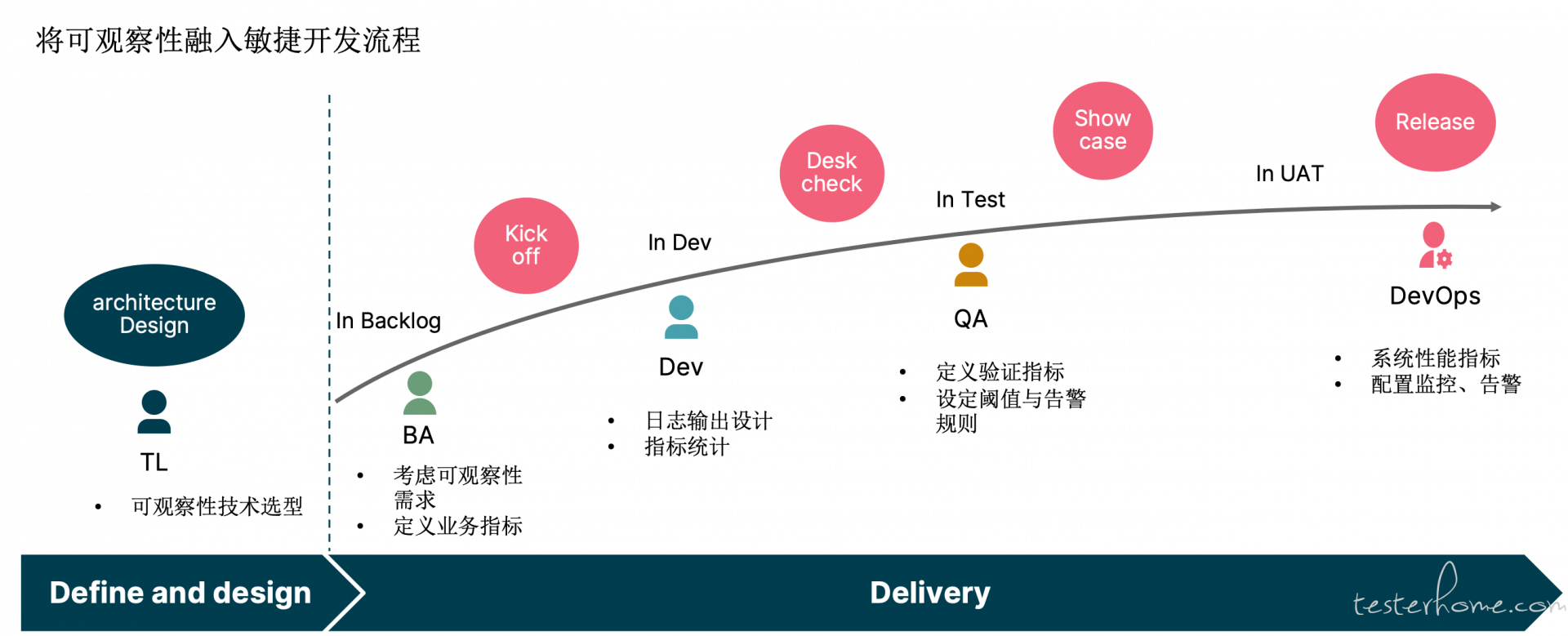
TL
在系统的架构设计阶段 TL 也应该考虑可观测性的技术选型。
PO/BA
在需求阶段 BA 就要将系统可观测性作为非功能性需求进行考虑,PO 与 B A 可以站在业务的角度提出可观测性的需求,定义相关的业务指标。
Dev
之前大部分 dev 只有在系统应用出现异常、错误的时候,才发现缺少关键的日志信息,才会考虑在什么位置加个日志看看,这就导致问题不能及时定位,需要额外的部署跟 debug。
Dev 在开发阶段编写代码的同时也要考虑可观察性:
(1)日志的输出设计,如何输出格式化的日志,如何通过日志来记录下系统关键的步骤、可能出现的异常、系统边界的关键数据等。
(2)以及是否需要增加一些关键指标进行记录。
QA
(1)在 Backlog Refinement、Kick Off 卡的时候 QA 应该考虑如何验收,通过观察系统的那些数据来验证系统有按照我们的预期执行,以及关注请求的响应时间,请求的错误率等。
(2)定义系统正常运行的关键指标并为其设置阈值以及警报规则:及时告警通知,以确保及时解决问题,帮助实现测试右移。
Devops
(1)关注系统应用运行、系统的性能指标,确保应用实例的高可用与自由伸缩等;
(2)负责具体配置 alert role、监控的 dashboard 等。
项目举例
如在我们之前的支付网关系统,有一个新的业务功能是提供新的支付方式。
系统应用的可观察性也应持续构建,将可观察性贯穿到整个软件生命周期中。
可观察性已然成为现代复杂分布式系统应用的必备能力。
可观察性带来的好处:
(1)提供了系统全景图,更好的理解系统如何交互以及掌握系统的运行状态。
(2)快速定位系统错误,追溯系统中的错误和异常,减少问题的识别、确认、恢复时间即 MTTI、MTTA 和 MTTR。
(3)帮助分析用户行为,了解用户需求和行为习惯,改进用户体验。
(4)深入揭示系统性能的瓶颈与原因,提升系统性能。
(5)为自动化运维提供数据支持,实现自动化运维。
(6)提升团队生产力。
可观察性面临一些问题和挑战:
(1)可观察性的构建过程中,往往会遇到各种各样的问题,数据增长太快引起的存储问题,告警风暴等。
(2)系统可观察性能力的构建前期需要投入一定的时间与精力。
(3)可观察性所带来的价值也不是短时间内就可以显现出来的,通过长时间的应用,可以为系统维护,业务决策提供价值。
(4)初步阶段我们在为系统构建可观察性能力时,会选择组合一些开源的工具来实现,分开的日志系统、链路系统、指标系统使得可观察数据分散在不同的地方,数据的聚合分析很难。
(5)收集到的可观察数据可能涉及用户隐私和敏感信息,需要采取相应的安全措施,确保数据安全。
(6)可观察性数据的处理与分析需求借助各种工具和技术,如 ETL,数据挖掘等,具有一定的技术门槛。
可观察性未来的发展:
(1)统一化:将不同 telemetry 数据进行格式的统一,基于统一的数据格式进行统一的存储,基于统一的存储实现统一的查询和分析。
(2)洞察力:关联整合更多的系统数据、业务数据,结合数据分析与挖掘,可以进一步挖掘可观察性数据背后的价值,如更准确的掌握用户行为、业务产品运营情况等,并可将其集成到企业的 BI 系统,给到你更多的的 insights,辅助商业决策。
(3)智能化:结合机器学习和 AI 甚至可以自动发现系统异常和潜在问题,实现智能巡检与 AIOps。