
关于这个监控组件我之前写过一篇文章:https://testerhome.com/articles/32478K8S 内部的 watch 机制来订阅相关事件并判断是否出现异常。,是利用 根据这个告警内容可以知道该节点的 kubelet 已经申请不到足够的内存,这导致该节点有崩溃的风险。
最近我们的测试环境中频繁有节点因为内存被耗尽而崩溃,由于每次都是发生在非工作时间(过一段时间内存就恢复了),所以我们一直没定位到具体什么原因导致的,查看监控系统也没找到具体是哪个容器有内存使用的异常。于是当今天早上某个测试环境发出了节点告警并显示内存不足后,我就赶紧登陆到服务器 上 看到底是哪里出 问题了,整个排查的过程比较有意思,所以我打算在这里记录一下。如下图:
关于这个监控组件我之前写过一篇文章:https://testerhome.com/articles/32478K8S 内部的 watch 机制来订阅相关事件并判断是否出现异常。,是利用 根据这个告警内容可以知道该节点的 kubelet 已经申请不到足够的内存,这导致该节点有崩溃的风险。
登陆到该节点首先通过 kubectl describe node 查看该节点的所有 event:

通过 event 发现 K8S 在过去一段时间内已经开启了驱逐策略,把当前节点的一些低优先级 Pod 驱逐到了其他节点, 这通常都是节点内存 不足导致的,查看 linux 内核日志也发现了很多 oom kill 记录:
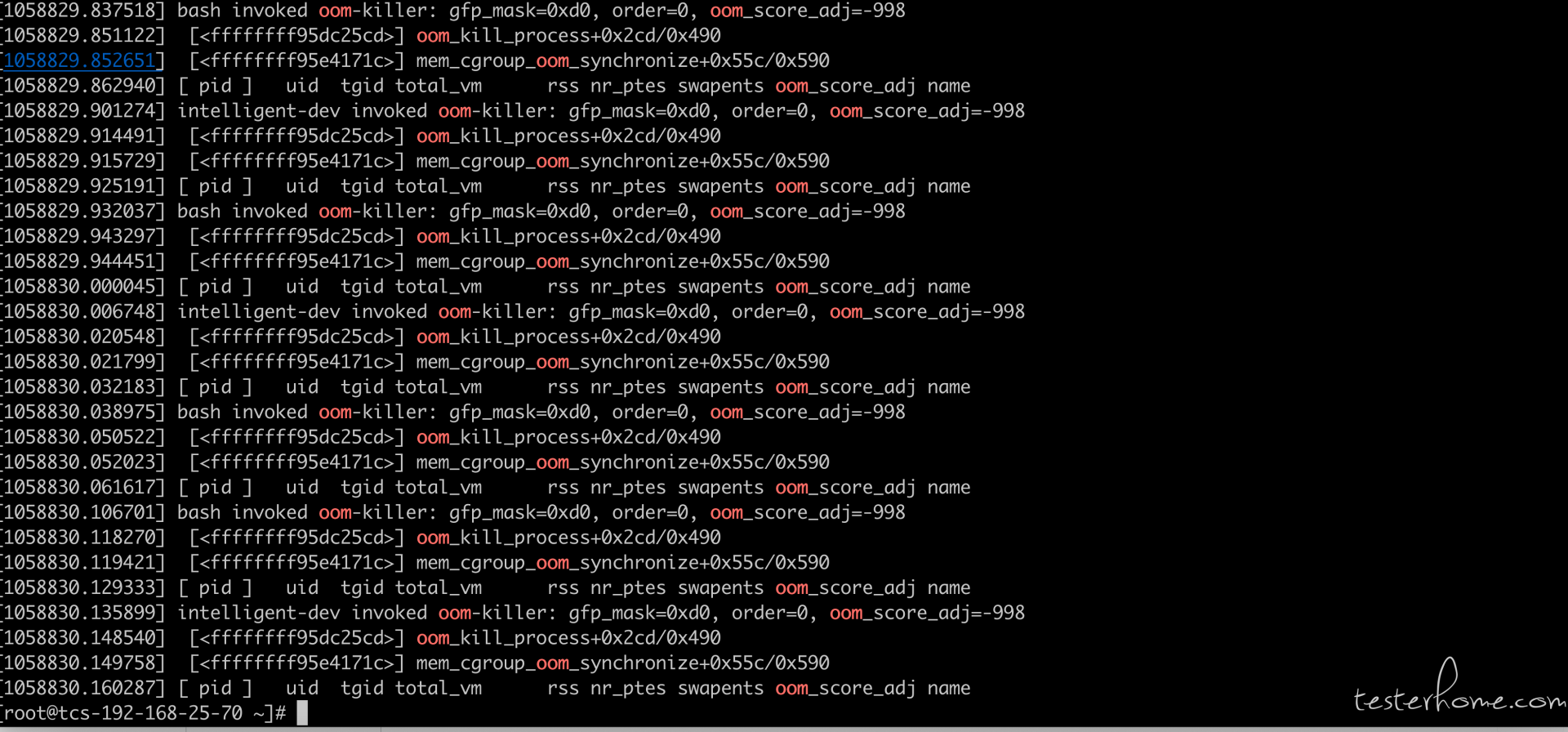
这里的第一个问题就是 K8S 的驱逐策略已经触发的情况下,为什么还会导致节点因为内存不足而崩溃(k8s 的驱逐策略就是为了防止内存占满而节点崩溃的,它会在内存到达一定的值后,就开始把当前节点的 pod 陆续调度到其他节点上来平衡负载),于是查看节点 kubelet 的启动参数,看一下驱逐策略是如何配置的:
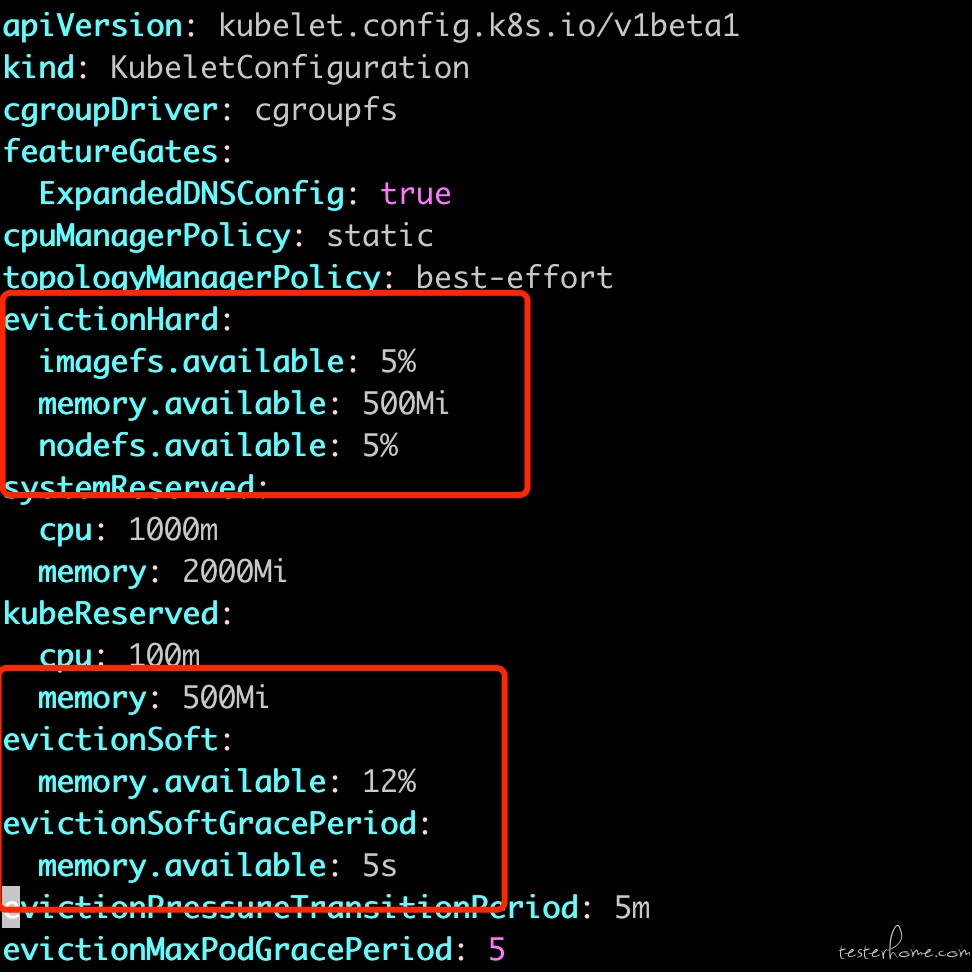
可以看到 K8S 软驱逐阈值设定在内存低于 12% 触发,硬驱逐则是内存低于 500M 触发,于是这里第一个问题就出现了, 首先介绍一下软驱逐和硬驱逐:
按理说有硬驱逐在,很难会出现内存被打满,节点崩溃的情况。但根据 kubelet 的硬驱逐,我们发现硬驱逐的参数配置只有 500M。 这个值应该是过低了,这里需要注意的是这个 500M 是 k8s 计算的 500M 而不是我们在 free 命令中看到的 500M.(K8S 是通过 cgroups 来计算当前节点的可用内存的, 比如要计算一个容器到底占用了多少内存,则主要是通过 working_set+active_file 作为该容器的内存总和,而没有计算 inactive_file,所以下面那个脚本是总内存减去 memory_total_inactive_file 来计算的),这里有一个以 K8S 为视角计算内存的脚本:
#!/bin/bash
#!/usr/bin/env bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to root cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)
memory_total_inactive_file=$(cat /sys/fs/cgroup/memory/memory.stat | grep total_inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
所以也许根据 K8S 计算的内存还有 500M 以上,但是从 free 命令上看内存已经所剩无几了。 这也是为什么有硬驱逐在,节点的内存仍然被占满了。 所以这里的第一个问题是需要运维同学重新调整硬驱逐的阈值。
首选通过 top 命令按内存排序,发现进程占用内存最多的是 updatedb 这个进程:

这里需要这个进程是从哪里来的,当时的第一个反应是这个进程是从某个容器中启动的。所以通过/proc/1337531 看这个进程的 cwd 和 exe,发现 cwd 里指向了一个目录,就是 pod(e13c3afb-d0a2-425e-9296-50ae995d0603):

根据截图,怀疑可能是这个 pod 引起的,所以根据 docker 和 kubectl 命令定位到了该 pod,但是很奇怪的是,这个 pod 的容器配置了资源限制(limit):

所以如果这个进程真的出自这个容器,那么它应该受到 limit 的限制,不可能会使用 18G 内存这么多,所以我之前的猜测可能是错的。 于是再次查看 cwd,发现所指的目录发生了变化:

由此我应该对 cwd 目录所有误解, 我在之前查找的资料中说 cwd 指向的是该进程的工作目录, 所以我理所当然的认为它指向了某个 pod 的目录,那么该进程就是属于该 pod 的,但显然我理解错了。 并且如果这个进程是来自这个 pod 中的容器的, 那为什么 cgroups 没有限制住。 然后我通过 ps -e -o pid,cmd,comm,cgroup 来尝试查询这个进程的 cgroups,发现它根本没落到 k8s 的 pod 所在的 cgroups 目录里:

正常的进程,如果它是启动在容器中的话,那么它的 cgroups 一定会落在:/sys/fs/cgroup/memory/kubepods 目录下, 如下图:
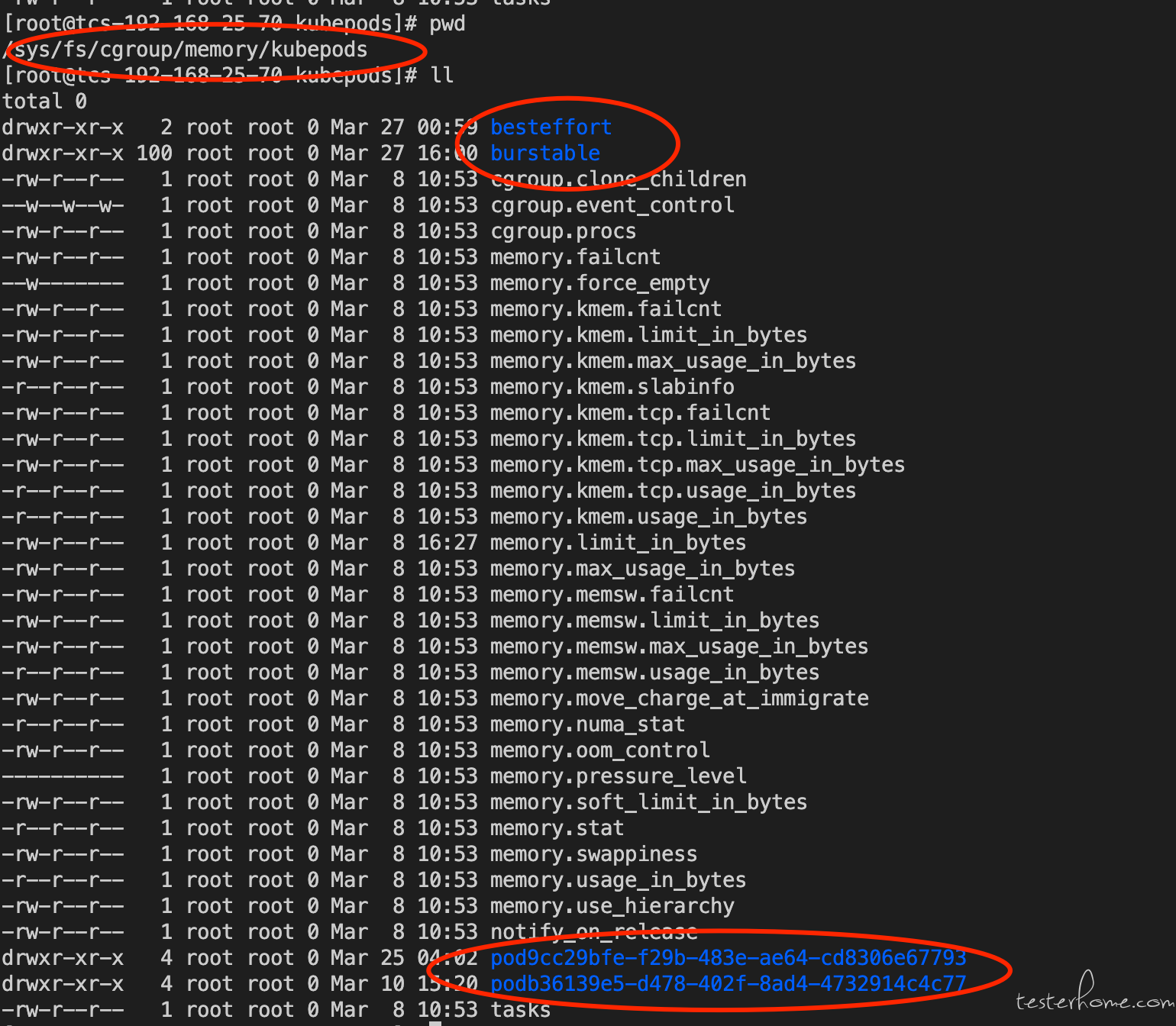
所以这里说明,该进程并不是启动在容器中,于是观察该进程的 cgroups 的 task,发现里面除了该进程外,还有一些其他进程。 再经过针对这些进程进行查询,以及在 网络上根据 updatedb 为关键字进行查询。 发现 updatedb 是 linux 为 locate 命令而更新数据库的定时任务:
查询该定时任务的配置:

最后确定操作系统开了 linux locate, 为了维护 locate 数据库,所以每天要执行一个定时任务来运行 updatedb 命令。 我们的环境里挂载了 ceph 存储, 文件非常多。 导致了这个命令运行的非常慢并且占用内存非常高。 我看网络上给的建议是如果对 locate 命令没有强需求,就直接禁掉。
在跟研发同学反馈后,更新产品部署文档,后面做私有化部署时会要求认为的删除该定时任务,避免再次出现性能问题 。当然后遗症是无法使用 locate 命令了
