本文主要想通过两个案例来分享下,以下实践的经验
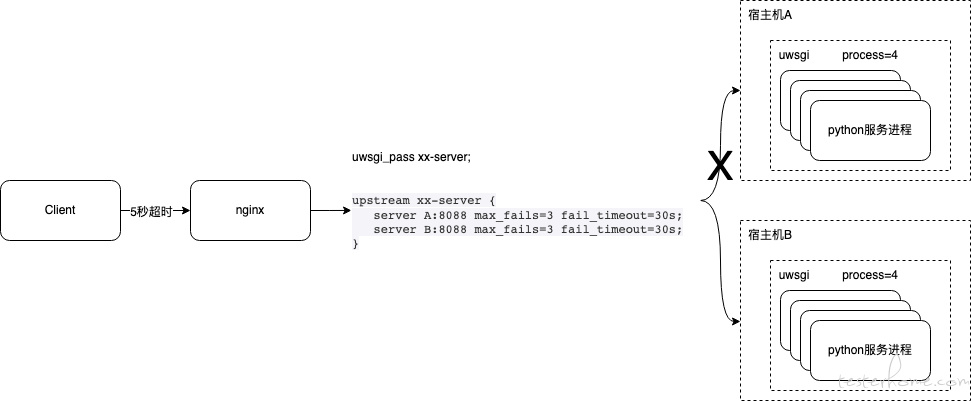
X 项目所在宿主机 A-内网光口网卡硬件故障,导致网络故障,服务不可达,简要架构如下
业务接口请求持续有一定比例超时失败
1.python+Flask 快速构建服务,两台主机上分别部署,修改 retDescp 为 “helloA” 和 “helloB”,请求路径保持一致
from flask import Flask, jsonify
app = Flask(__name__)
@app.route("/hello")
def say_hi():
return jsonify(retCode=200, retDescp="helloA")
if __name__ == '__main__':
app.run(debug=True)
2.采用 uwsgi 启动 A、B 两台机器服务
uwsgi --chdir=$WORKSPACE --wsgi-file=hello.py --master --pidfile=$PIDPATH --socket=0.0.0.0:$PORT --http-socket=127.0.0.1:$LOCAL_HTTP_PORT --processes=4 --enable-threads --threads=8 --harakiri=600 --max-requests=5000 --vacuum --post-buffering=32768 --buffer-size=32768 --wsgi-disable-file-wrapper
3.测试环境模拟线上 nginx 配置,采用 uwsgi_pass 进行代理转发
uwsgi_pass xx-server;
upstream xx-server {
server A:8088 max_fails=3 fail_timeout=30s;
server B:8088 max_fails=3 fail_timeout=30s;
}
4.发起请求流量
for i in {1..2000}; do curl -X GET --connect-timeout 5 -m 5 "http://xx-test.xx.com/hello" >> log.txt 2>&1; done
5.中断宿主机 A 网络,复现线上故障场景
宿主机 A 网络中断,客户端侧 5 秒超时会主动关闭连接,实际 nginx 侧 max_fails 不会计数失败,导致异常节点一直不会被触发 “下线” fail_timeout 长度的时间
经过沟通,发现此处存在 2 种 “失效”
官方解释:
fail_timeout – Sets the time during which a number of failed attempts must happen for the server to be marked unavailable, and also the time for which the server is marked unavailable (default is 10 seconds).
max_fails – Sets the number of failed attempts that must occur during the fail_timeout period for the server to be marked unavailable (default is 1 attempt).
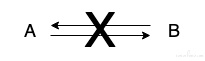
一个链路 A 到 B 可能出现的故障场景可以简单分为以下 4 种,对于 health check 配置需要覆盖这 4 种可能出现的故障,前三种可以走 4 层 TCP CHECK,第 4 种 “服务进程假死” 需要真正的业务请求可达,需要走 7 层 HTTP CHECK
check interval=3000 rise=2 fall=3 timeout=5000 type=tcp default_down=false;
Redis 集群三主三从,挂掉从节点后,应用请求出现大量的超时
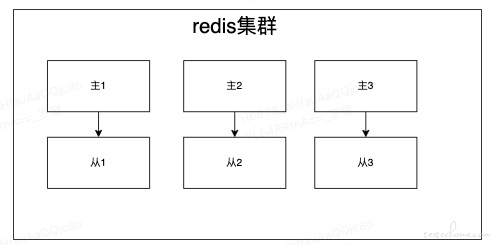
从理论上来讲,挂掉从节点不会对业务造成任何影响,Redis 集群主 1 从 1 之前发生过一次主从切换,下线所谓的 “从” 节点时(之前的主 1),由于集群拓扑未刷新,连接请求仍然会请求到主 1,导致应用持续大量请求超时
在分析问题的过程中,存在两个配置失效的问题,一是 spring.redis.timeout=100000 设置的超时时间过长,导致需要 100 秒后才会刷新集群拓扑,这期间会有大量的业务请求失败;二是集群拓扑刷新失效,redis 的客户端(lettuce、Jedis、redisson)对拓扑刷新的处理不同,spring-data-redis 包中实现的 Lettuce 客户端时,默认没有开启客户端刷新功能,需要 SpringBoot 版本>=2.3.0 后有属性配置支持开启自动刷新
spring:
application:
name: xxx
#***********************redis***********************
redis: #redis配置
lettuce:
cluster:
refresh:
adaptive: true #自动刷新集群 默认false关闭
period: 30000
