链接:https://pan.baidu.com/s/1IEClXb1LKIOWTM7KD_KGgA
提取码:5suc
链接:https://pan.baidu.com/s/1H-OE0Q-ABmEF4MbXfDRR5Q
提取码:9qqy
3、解压后的 Tess4J\tessdata 文件夹,放到自己需要使用的文件目录,后面代码会使用到
方法 1:验证码让程序员帮忙处理,写死固定的验证码
方法 2:通过图片识别 (本文主要说明该方法)
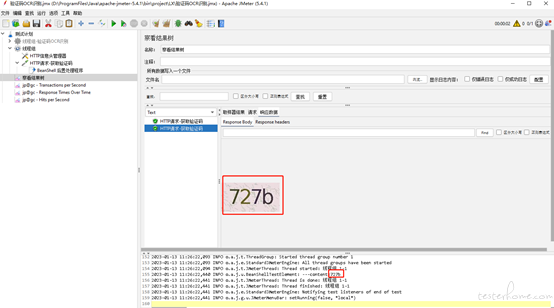
打卡 Jmeter,创建线程组和请求,这里已获取验证码接口为请求,添加后置处理器,后置处理器填写如下代码
后置处理器脚本:
import java.io.*;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
String projectPath = System.getProperty("user.dir");
String imgPath= projectPath + "/project/LX/yanzhengma.jpg";//将验证码保存到本地文件中
byte[] responseBody = prev.getResponseData();
File imageFile = new File(imgPath);
FileOutputStream out = new FileOutputStream(imageFile);
out.write(responseBody);
out.flush();
out.close();
File imageFile1 = new File(imgPath);//读取图片数字
//Tesseract instance = new Tesseract();
ITesseract instance = new Tesseract();
instance.setDatapath(projectPath + "/project/LX/tessdata"); //上面第3步的目录
instance.setLanguage("eng");//英文库识别数字比较准确
content = instance.doOCR(imageFile1).replace("\n", "");
content = content.replace(" ", "");
log.info("---content:" + content);
vars.put("yanzhengma",content);
