Hi,我是测试耿晓,前段时间我发布了一篇有关自己做接口测试的实践经验,发出后受到了很多小伙伴的关注,也收到了很多佬儿哥的指点,很是开心,TesterHome 真是一个温暖的地方。在众多建议中,频率最高的就是"pytest+requests+allure"的组合了,随后我就学习了 pytest 和 allure 的相关知识,并且在项目中进行了实践。本次我就总结一下基于这个框架的阶段性成果,希望伙伴们继续纠偏指点。
第三代测试框架是基于 unittest+requests 实现的,使用 ddt 库实现了数据驱动测试,使用 excel 管理测试数据,以及使用 excel 持久化接口响应的相关信息,具体细节感兴趣的小伙伴可以查看上篇文章接口测试 - 从 0 不到 1 的心路历程。依据这个模式写了 30 个接口的 case,发现如下问题:
1.编写测试数据生成函数时,不光要写数据生成逻辑的代码,还要写将测试数据写入 excel 的代码,导致整个函数冗长,函数职能不单一。
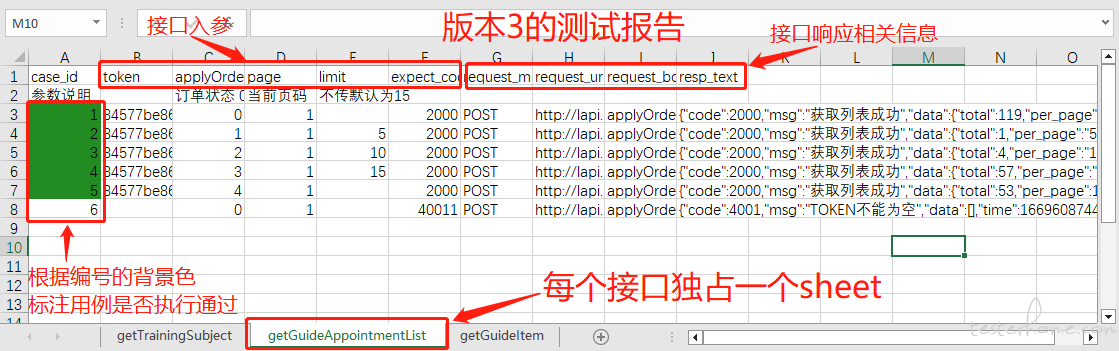
2.使用 excel 保存接口响应的相关信息,每个接口单独占据一个 sheet 页,这种方式一旦接口数量过多,最终查阅起来并不方便 (首先打开 excel,然后查找目标 sheet,然后再查找目标 case)。
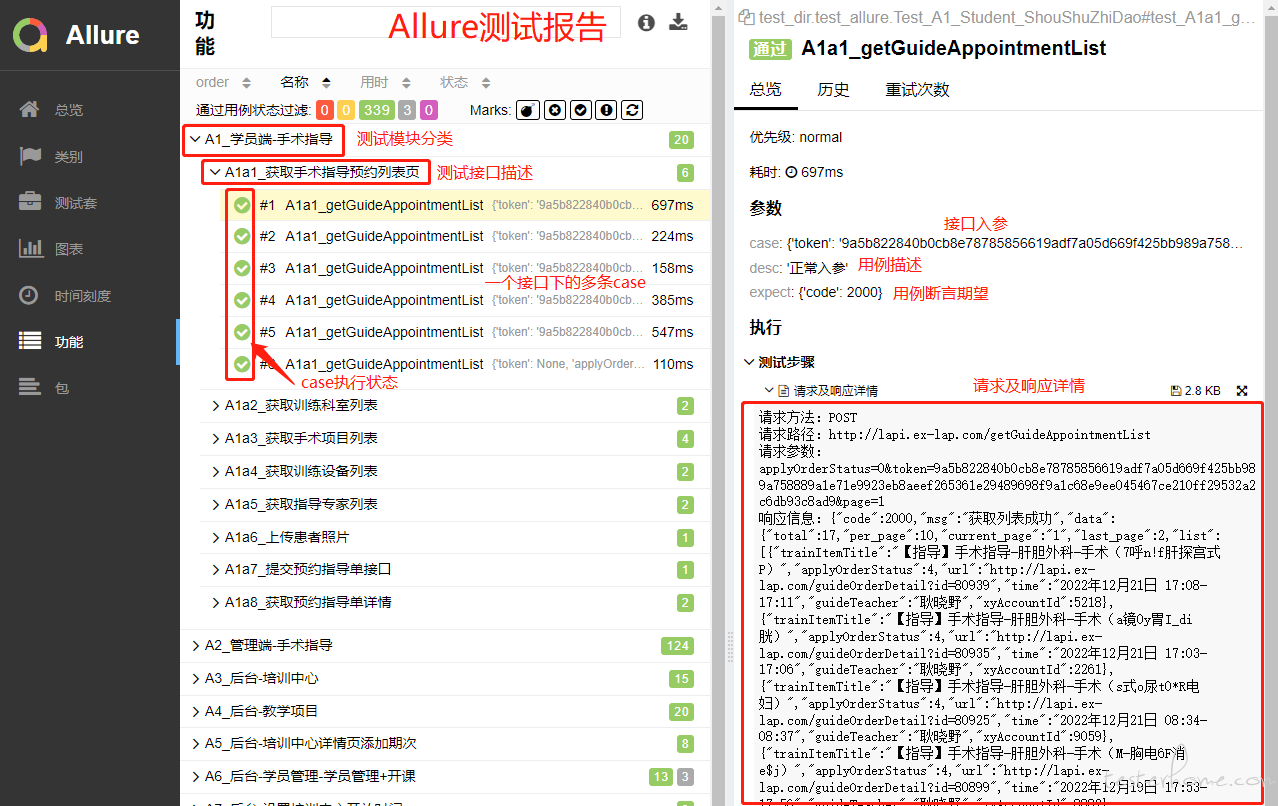
学习 allure 之后,发现 allure 可以记录接口的入参及接口响应等信息,基于此就可以完美解决上述问题,测试数据生成函数仅需要编写数据生成逻辑,无需再写处理 excel 相关代码。接口响应等信息直接使用 allure.attach() 方法就可以记录在报告中,所以也就不用再像版本三一样编写收集接口响应信息并写入到 excel 的函数了。先上两张 excel 报告和 allure 报告的效果对比图,然后再叙述第四版框架的堆砌过程。
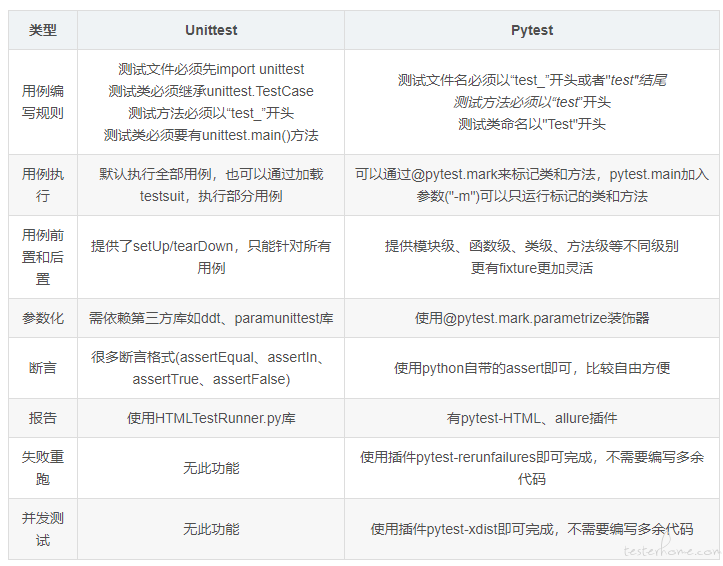
我主要是通过《pytest 测试实战》这本书学习 pytest 的,这是一本工具书,整书不厚,看完前四章就可以动手实战了,有兴趣的伙伴也可以看一下。pytest 的优势在此就不过多赘述了,不过我认为还是很有必要了解一下 pytest 和 unittest 的区别的,我在网上借了一张对比图,刚了解 pytest 的伙伴可以参考下。
在 pytest 使用过程中,有三点优势是我切实感受到的:
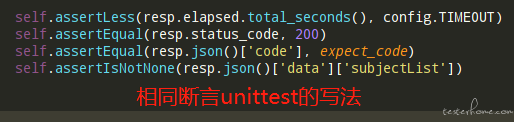
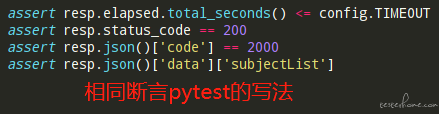
1.pytest 使用 assert 关键字来进行断言,相比 unittest 的断言就四个字:简洁明了
2.pytest 提供的失败重跑插件"pytest-rerunfailures"。例举一个使用场景:case1 为新建商品,新建成功后保存商品 id,case2 为编辑商品,需要使用 case1 保存的商品 id。在运行测试脚本时,case2 有一定概率会报错,提示被测系统中不存在此商品 id,但事后手动执行 case2 发现并没有问题。究其原因可能是 case1 的新建接口新建完商品后需要一定的时间进行数据落库等操作,但运行测试脚本时,case1 和 case2 的衔接时间又很短,导致 case2 有一定概率会报错。在使用 unittest 框架时,对于这种场景,我一般会在 case2 发送请求前强行休眠 1 秒:sleep(1) ,不过像这种蠢呆呆的代码我都会用遮羞布盖住,生怕别人看见。不过接触到"pytest-rerunfailures"插件后,再也不用担心这个问题了,只能用四个字形容:极其好用!
,不过像这种蠢呆呆的代码我都会用遮羞布盖住,生怕别人看见。不过接触到"pytest-rerunfailures"插件后,再也不用担心这个问题了,只能用四个字形容:极其好用!
前提条件:pytest (>=5.3) 和 python >=3.6
安装:
1.pip install pytest-rerunfailures
2.pip show pytest-rerunfailures
使用:
1.命令行参数: --reruns n(重新运行次数)–reruns-delay m(等待运行秒数)
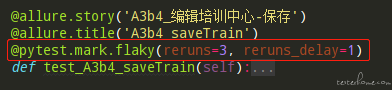
2.使用装饰器: /@pytest.mark.flaky(reruns=5, reruns_delay=2)
注意兼容性:
1.这个插件不可以和 class, module, package 级别的 fixture 装饰器一起使用;
2.这个插件与 pytest-xdist 的 --looponfail 标志不兼容;
3.这个插件与核心 --pdb 标志不兼容;
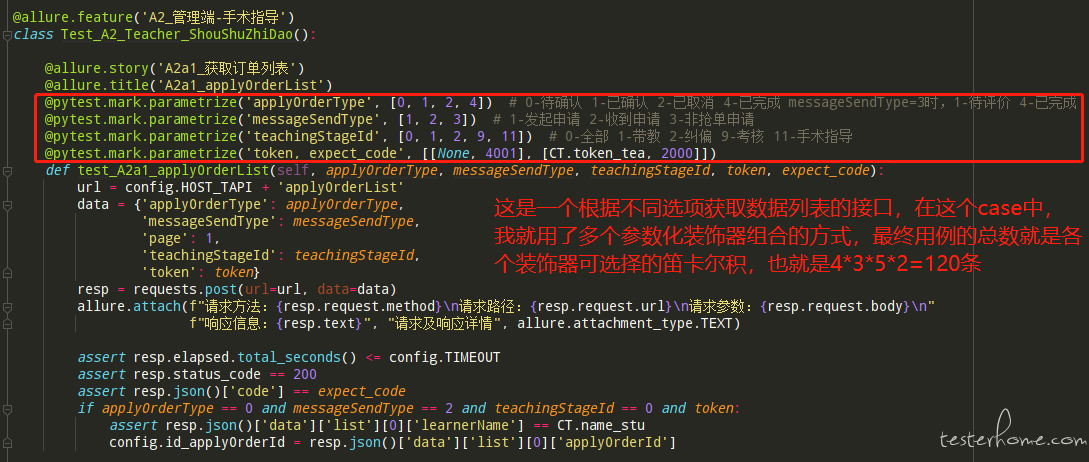
3.pytest 的参数化-@pytest.mark.parametrize(‘参数名’, list) 。这个装饰器的使用很简单,大致为:第一个参数是字符串,多个参数中间用逗号隔开;第二个参数是 list。我觉得比较有意思的一点是可以使用多个@pytest.mark.parametrize(‘参数名’, list) ,最终效果就是每一个参数化装饰器中可选值的笛卡尔积,在上篇文章的讨论区中,有小伙伴就问过,参数组合的场景中,想做全面的笛卡尔积应该怎么做,喏,用@pytest.mark.parametrize(‘参数名’, list) 就可以解决你的问题了。让我们演示一下 (方法虽好,可不要过于贪恋,非必要我们还是要慎用笛卡尔积的,毕竟也要考虑用例冗余带来的效能问题):
allure 是一个灵活的轻量级多语言测试报告工具。在使用 allure 之前,需要安装"allure 命令行工具"和"allure-pytest"插件,需要注意的是,allure 需要依赖 jdk,我想 it 人电脑上 jdk 应该是标配吧,所以在此就不过多介绍 jdk 的安装详情。
allure 命令行工具安装步骤:
1.下载安装包,我选择的是"allure-2.20.1.zip",allure 安装包下载地址
2.解压缩
3.配置环境变量 path,我的是:D:\Gxy\allure-2.20.1\allure-2.20.1\bin
4.检查是否配置成功,在 cmd 命令窗口输入: allure --version
"allure-pytest"插件安装:
1.pip install allure-pytest
allure 运行命令:
1.pytest --alluredir ./report ./test_dir # 生成测试报告所需要的数据,数据在 report 目录里。
2.allure serve report # 会自动使用默认浏览器打开 allure 报告,默认是英文的,我们可以在页面左下角切换成中文显示。
3.如果我们想每次的报告不掺杂历史数据,那我们可以在运行测试命令后面加"--clean-alluredir"。这样最终的命令就是:
"pytest --alluredir ./report ./test_dir --clean-alluredir"
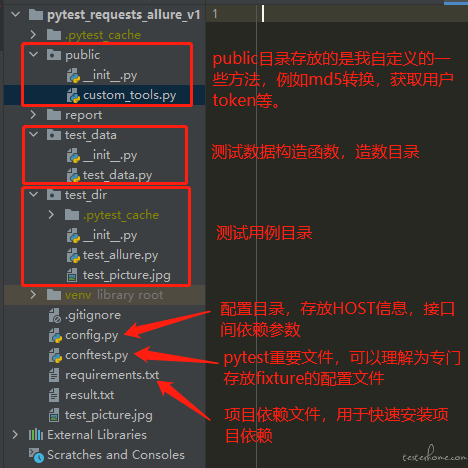
首先介绍一下我的项目目录,相比之前版本的测试框架,去除了 TestRunner 文件夹 (用于生成测试报告),项目的根目录下多了"conftest.py"、"requirements.txt"和"result"文件,具体如下:
在实践过程中,我有思考以下问题:
问题 1:pytest 怎么控制用例的执行顺序?
问题 1 的解答:
在 unittest 框架中,默认按照 ACSII 码的顺序加载测试用例并执行,顺序为:09、AZ、a~z,测试目录、测试模块、测试类、测试方法/测试函数都按照这个规则来加载测试用例。
pytest 默认执行顺序:测试目录、测试模块,按照排序顺序执行。
pytest 也自定义执行顺序:需要安装 pytest-ordering 插件。
# 需要使用 @pytest.mark.run()
@pytest.mark.run(order=2)
def test_a():
print("test_a")
@pytest.mark.run(order=1)
def test_2():
print("test_2")
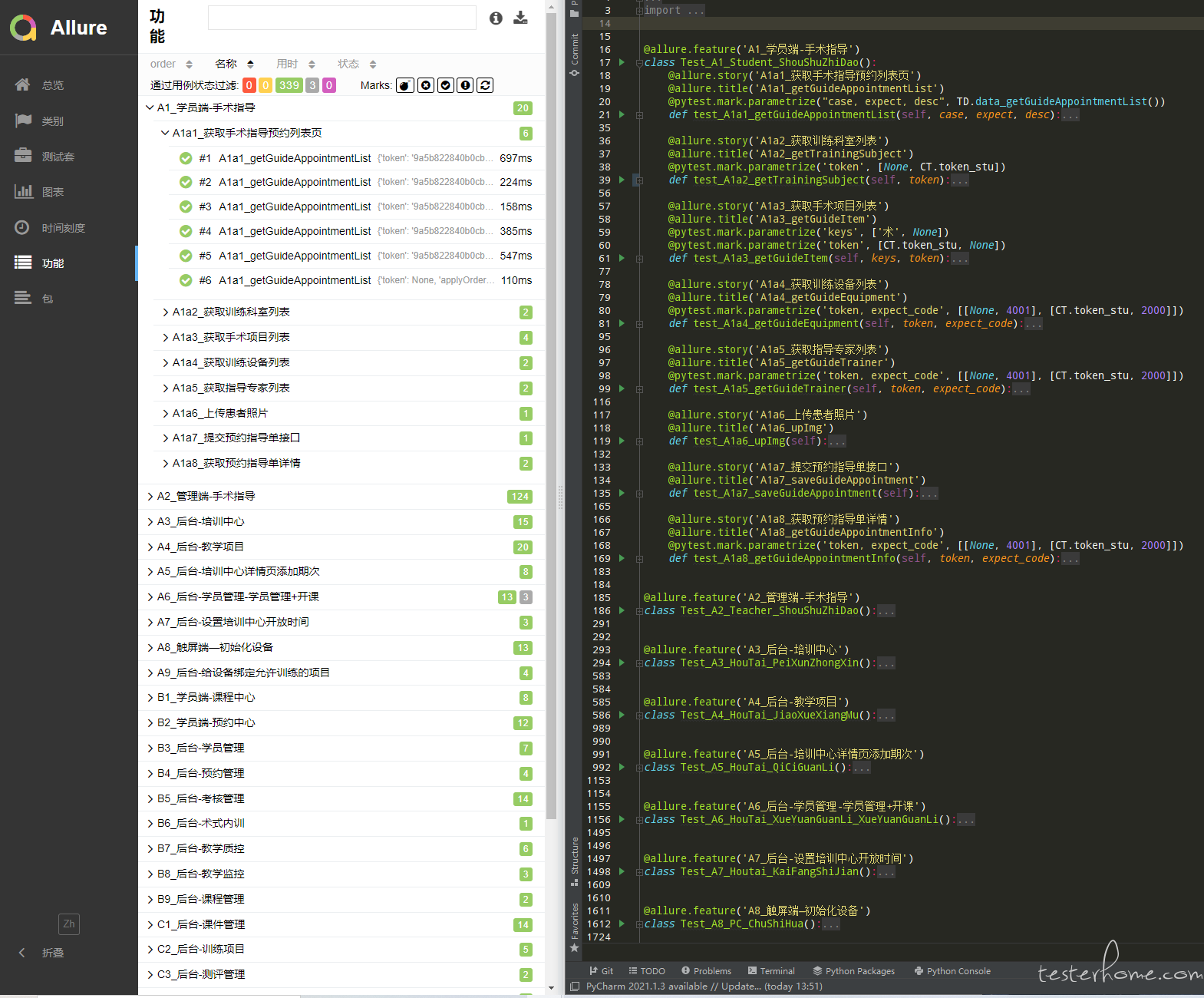
因为我这套测试脚本,用例间还是很讲究运行顺序的,所以我就遵循 pytest 按照排序顺序执行的特点顺序编写测试脚本。起初我并没有给 case 进行编号,只是单单的按照排列顺序写,可在查看 allure 测试报告时,发现报告中 case 显示的顺序并不是按照脚本中 case 排列顺序展示的,并且我手动点击 allure 报告中排序规则后,还是没能按照脚本中 case 的顺序进行展示,这就令我很恼火,于是我还是按照 unittest 中根据名称排序的习惯,将所有 case 的标题都改了一遍,果然,allure 报告中 case 的顺序被我成功拿捏住了。效果如下:
问题 2:有接口数据依赖时,怎么判断依赖数据被成功赋值
场景描述:还是以新增和编辑接口举例,首先我会在 config.py 文件中设置一个商品 id,初始值为-1,然后新增接口的 case 断言通过后会重新赋值这个商品 id,最后编辑接口 case 运行前,需要先判断 config.py 文件中的商品 id 是否被成功赋值,成功赋值则继续运行 case 后续代码,如果没有成功赋值则不运行 case2 后续代码。
我在第三版测试框架中是这样做的:
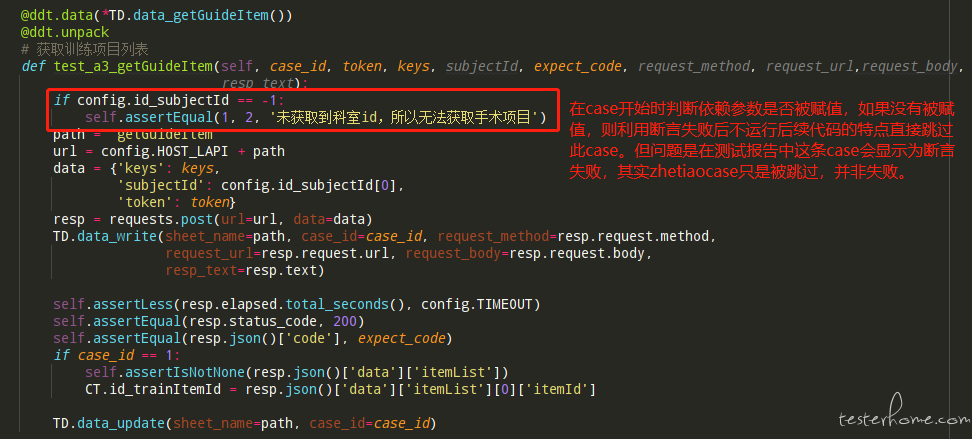
如果我在第四版中依然沿用这个思路,那一旦依赖参数没有被成功赋值,则在 allure 报告中会显示本条 case 失败,可其实本条 case 并没有被运行,所以感觉被置为失败不确切。
def test_getGuideItem(self, case, expect, desc):
if config.id_subjectId[0] != -1:
assert 1 == 2, '未获取到科室id,所以无法获取手术项目'

那我将 “assert 1 == 2” 改成"raise KeyError()"效果怎么样呢?
def test_getGuideItem(self, case, expect, desc):
if config.id_subjectId[0] != -1:
raise KeyError('未获取到科室id,所以无法获取手术项目')

在 allure 报告中显示故障好像也不太恰当,分析后其实这种情况应该属于 case 入参没拿到,所以跳过本条用例,那自然而然的就想到了 pytest 跳过测试用例相关知识。pytest 跳过测试用例大致分为方法外跳过 (@pytest.mark.skip()) 和方法内跳过 (pytest.skip()),分别演示:
# 使用方法外跳过
@allure.story('获取手术项目列表')
@pytest.mark.skipif(config.id_subjectId == -1, reason='未获取到科室id,所以无法获取手术项目')
def test_getGuideItem(self, case, expect, desc):
....
经实践后发现,方法外跳过行不通,因为测试脚本运行时会先加载所有用例的装饰器,然后才会执行用例本身,而我们的依赖参数 (config.id_subjectId) 是在运行用例过程中进行赋值的,所以方法外跳过的装饰器读取的是原值,读不到变更后的值。
# 使用方法内跳过
@allure.story('A1a3_获取手术项目列表')
def test_A1a3_getGuideItem(self, keys, token):
if config.id_subjectId == -1:
pytest.skip(msg='未获取到科室id,所以无法获取手术项目')
url = config.HOST_LAPI + 'getGuideItem'
......
经实践后发现,使用方法内调过可以达到期望效果。如果依赖参数没有被赋值,那么在 allure 报告中会显示此用例被跳过。这个结果就很符合实际情况了。

在第四版测试框架中,我一共写了 101 个接口,共计 342 条 case,这些是我从公司业务中梳理出来的重要流程中涉及到的所有接口,因为团队中的接口文档并不是很完善,所以我主要通过 fiddler 抓包工具收集涉及到的接口及其入参出参,工作量真心不小,但好在第四版的测试框架编写起 case 来相对简洁,让我很快就完成了所有工作。为了更直观的体现第四版的简洁,让我们来对比一下第四版和第三版编写相同 case 时需要的代码量 (一条 case 由 case 本身和造数函数两部分组成):
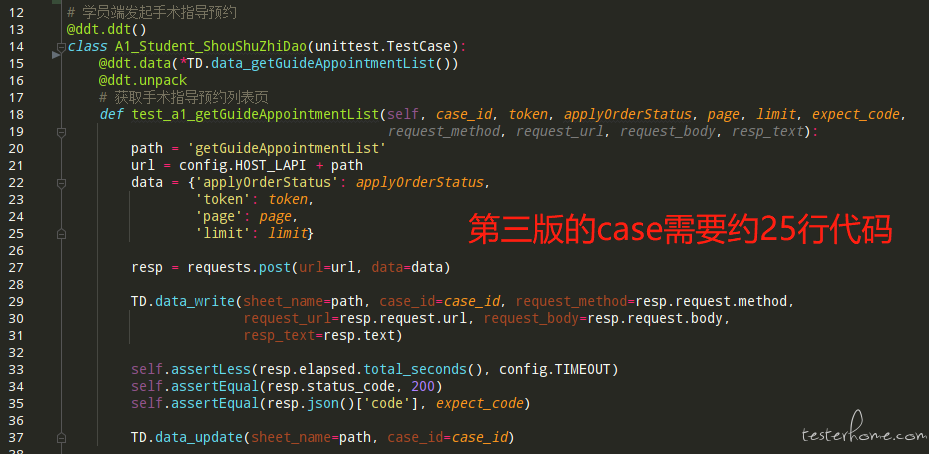
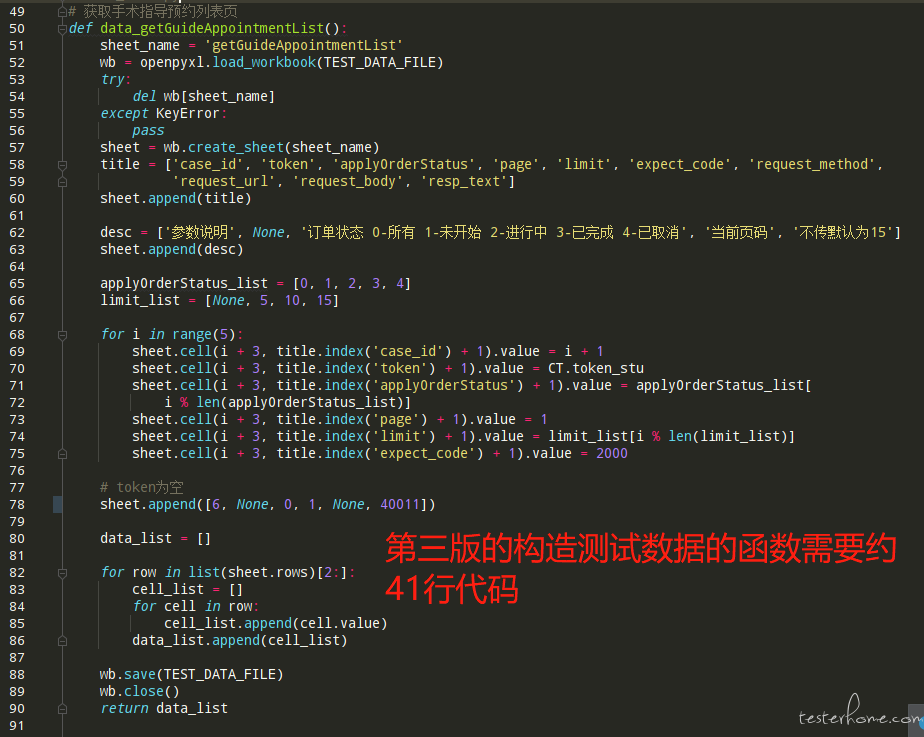
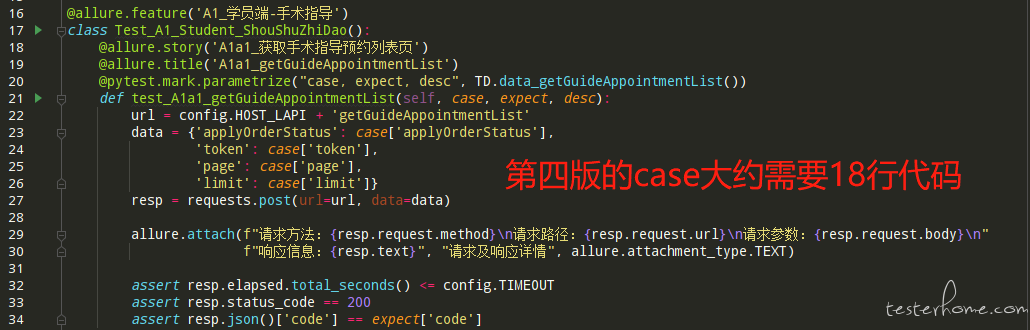
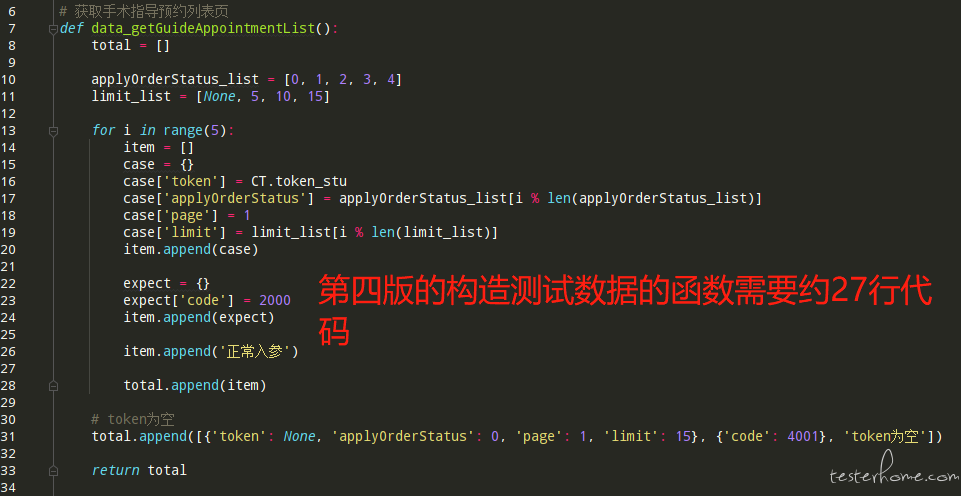
从代码量来看,实现相同的效果,不论代码逻辑,就单单代码数量就大约减少了三分之一,确实很不错!
从运行时间来看,整个脚本运行大概需要 110 秒左右的时间,如果这些核心流程人工点点点的话,业务熟练如我的人也需要至少半个小时,从运行时间上也能很好的体现出接口测试确实是一把利器,值得测试人员为之投入。
第四版框架的实践总结就写到这里吧,虽然磕磕绊绊的实现了,但自知其中绝对还有很大的优化空间,刚接触 pytest+allure 不久,理论和实操经验都很是欠缺,就好比在刚接触 pytest 的时候,很多资料显示 pytest 的核心之一是 fixture、conftest 等,而我却压根没用到这些,对其也是一知半解,显然我这 pytest 用的就很皮毛了 ,所以期望社区中的佬儿哥 佬儿姐们能够对发现的问题纠偏赐教,也希望和我一样刚接触 pytest 的伙伴能够相互讨论一下自己的踩坑史。
其实在第四版框架堆砌的过程中,踩坑无数,我将一些最令人头大的坑罗列一下,希望能够帮助一样在摸索的伙伴们。
踩坑 1.切换办公电脑后,项目的 Python 运行虚拟环境无法使用。
场景描述:由于疫情原因,一直居家办公,项目是在家里电脑 (电脑 A) 创建的,创建时是用 pycharm 创建的虚拟环境。之后疫情稍微稳定,返回公司办公。我就用电脑 A 将项目上传到了 git 上,然后用公司的电脑 (电脑 B) 克隆项目。最后使用电脑 B 运行项目发现 Python 运行环境无法使用。(现在知道问题是由于用电脑 A 上传 git 时,将项目根目录下的 venv 文件夹 (虚拟环境及项目依赖文件) 一同上传到了 git 上,然后用电脑 B 克隆项目,由于项目在不同电脑上的路径不一样,导致电脑 A 的 venv 文件夹在电脑 B 无法正常使用)(但是当时并不知道),然后当时就只能在电脑 B 上重新创建虚拟环境,然后再重新安装项目依赖,下班时再用电脑 B 上传项目到 git 上,回家后用电脑 A 拉取项目,同样在重新创建虚拟环境,然后再重新安装项目依赖。反复几次后,实在受不了自己这种 stupid donkey 的行为。决定先解决这个问题。
解决方案 1:不使用虚拟环境,改用全局环境;但可能出现不同项目间依赖包版本冲突的问题,所以弃用方案 1。
解决方案 2:创建.gitignore 文件,忽略 venv 文件;
经过一系列实践,发现方案 2 可行。最终项目中的.gitignore 文件内容如下:

但为了快捷的安装项目依赖,又学到了 requirements.txt 相关知识。具体如下:
在项目终端运行:pip freeze -> requirements.txt
这条语句可以将项目依赖信息保存为 txt 文档。
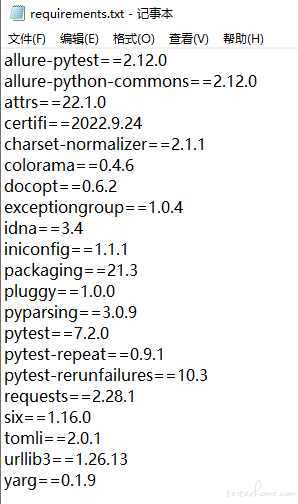
然后再在新的运行环境中运行命令:pip install -r requirements.txt
这样就可以快速的安装项目依赖了。
过程中又联想到另一个分支问题,为什么使用 pip freeze 而不是常见的 pip list?
随后我又使用 pip list -> list.txt 命令导出了 list 文件,两个文件对比如下:
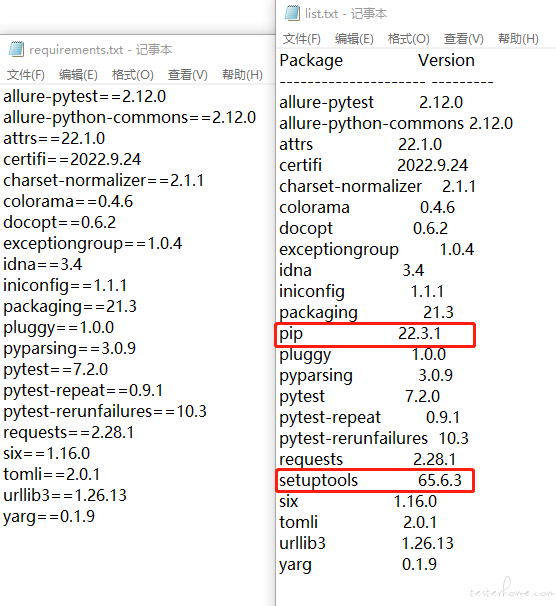
发现 pip list 比 pipfreeze 多了"pip"和"setuptools"两个文件。
度娘之后得到如下结论:
"pip , wheel , setuptools 等包,是自带的而无法 (un) install 的。考虑到 pip freeze 的用途,所以这些包并没有显示。如果一定要用 pip freeze 来显示所有包,可以加上参数-all,即 pip freeze -all"
踩坑 2:项目路径中含有中文,导致在 terminal 运行语句:pytest --alluredir report test_dir 时报错 "pytest: error: unrecognized arguments: --alluredir"。
这个问题只有在我家里电脑上才会出现,在公司电脑上不会出现。
起初我以为是家里电脑 Python 的运行环境有问题,结果重新创建运行环境后,仍然存在此问题。
然后我又怀疑是家里 pycharm 有问题,然后我就将家里电脑的 pycharm 卸载,重新安装成和公司电脑一样版本的 pycharm,运行后仍然存在问题。(现在想想有点搞笑,terminal 报错,跟 pycharm 有什么关系呢 )
最后百度寻找答案,其中有一条结论说"虚拟环境地址不能有中文",然后我看一下自己项目的路径 (G:\耿晓野的口袋\PycharmProjects\pytest_requests_allure_v1),确实有中文,然后我就把项目路径更改成 (G:\gxyPocket\PycharmProjects\pytest_requests_allure_v1),由于项目路径变更,我不得不重新创建项目虚拟环境并且重新安装项目依赖,随后再次在 terminal 运行语句:pytest --alluredir report test_dir,成功了!
由此也解答了为什么办公室电脑运行就没问题,因为项目直接放在了办公室电脑上的 D 盘下。突然想起上学时 Java 老师说路径中尽量不要有中文,不然会引发很奇怪的问题,喏,这回被我切实体会了一次。
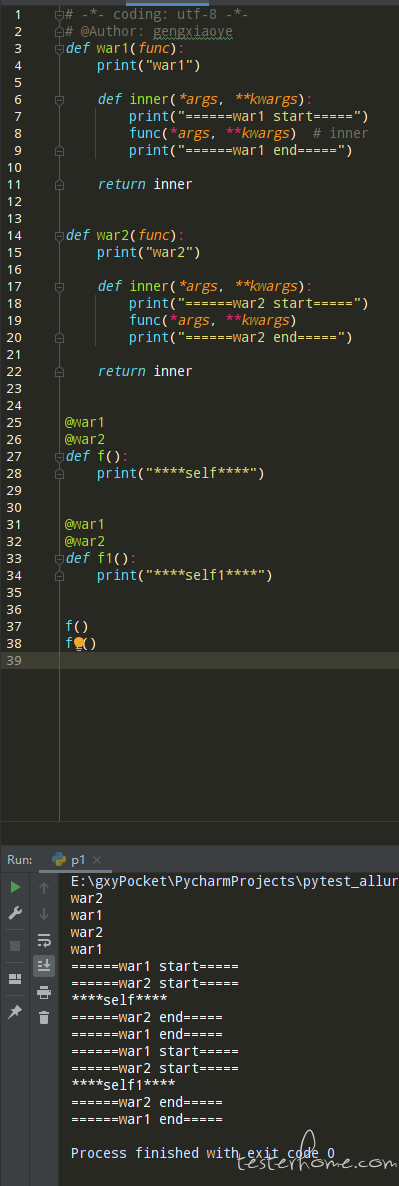
知识点 3:在使用 pytest 过程中,用到了大量的装饰器,我就在想,函数上方罗列这么多装饰器有没有前后顺序要求?多个装饰器的执行顺序是怎样的?
百度及实践后得到以下结论:
装饰器函数的执行顺序是分为(被装饰函数)定义阶段和(被装饰函数)执行阶段的,装饰器函数在被装饰函数定义好后立即执行;
在函数定义阶段:执行顺序是从最靠近函数的装饰器开始,自内而外的执行;
在函数执行阶段:执行顺序由外而内,一层层执行;
本次实践过程中掉坑和爬坑过程就写这么多吧,如果你也有有趣的爬坑经验,也可以写在留言区,大家相互讨论下。
其实这次我不光重构了第四版测试框架,还买了个服务器,并且在服务器上搭建了 jenkins,最终实现了 jenkins 每天定时使用 git 拉取代码,自动构建项目,并且把测试报告发送到我邮箱的效果。我打算也将这个过程总结输出一下,可能更多是每一步的操作步骤以及一些注意事项,应该会类似于 CI/CD 创建说明书。如果感兴趣的伙伴可以继续关注一下 ,拜拜。
,拜拜。
Two days later
Hi,我把在 Linux 上搭建 Jenkins,并且实现自动构建接口测试工程的搭建过程整理输出好啦。期望伙伴儿们去指点一下呀
在 Linux 上搭建 Jenkins,自动构建接口测试
