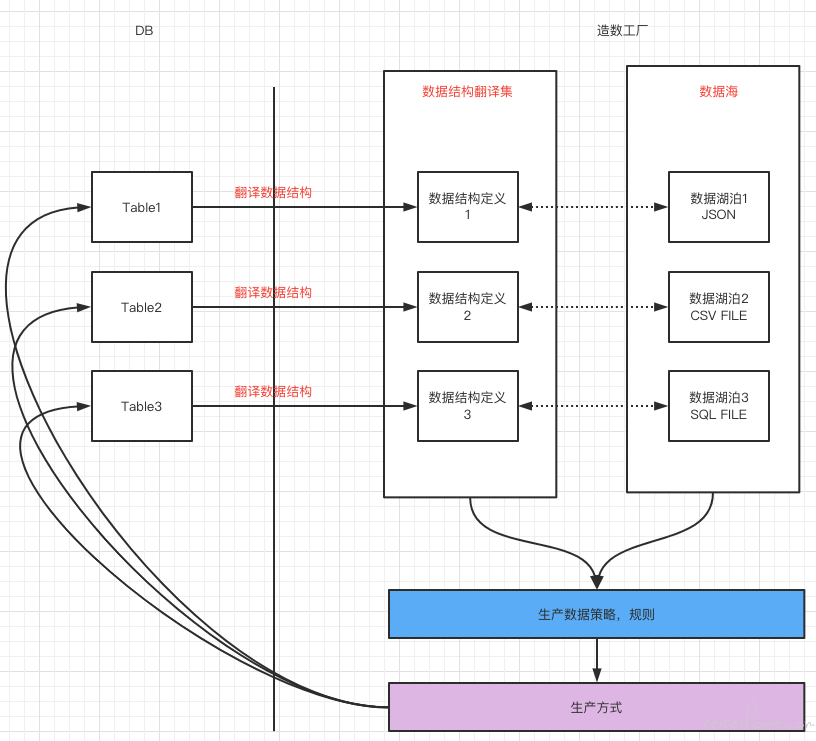
“造数工厂” 是什么?
理解思考造数工厂是什么之前,我们先需要搞清楚业务功能(前端、服务,数据)之间的关系
在业务系统中,业务数据一般由用户发起业务流程产生,也就是由功能产生,这是所谓的正向数据流,例如 “新建” 相关的功能。而产生的数据为后续的业务功能提供基础支撑,例如 “查询”,“更新”,“内存运算” 等,这是所谓的逆向数据流。用户的操作产生数据,产生的数据根据业务要求进行一系列的操作和加工又反馈给用户。所以在业务系统中,我们可以把功能划分为三大类:
- 产生数据的功能;
- 使用数据的功能;
- 产生和使用数据的功能;
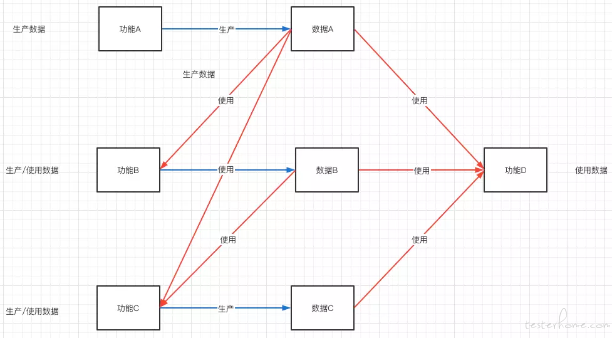
通过上图可以看到:
- 功能 A 类似 “新建” 或 “数据接入” 的功能,纯产生数据。
- 功能 B,功能 C 类似 “编辑”,“删除” 的功能,使用其他功能产生的数据,并进行操作数据进行增、删、改。
- 功能 D 类似 “查询” 的功能,对已经存在数据根据业务要求进行查询,聚合,内存运算,当然这种功能业务产生数据,但这些数据都是存放在内存中,并不会持久化下来,一定时间后会被清理掉。 通过上图也可以看出一些基本常识,在业务系统中功能和功能之间、数据和数据之间,功能和数据之间存在依赖。 正是这个 “依赖” 为 “造数工厂” 的定义提供了有效的参考。我个人理解造数工厂是一种在软件生产过程中为功能直接快速提供业务数据支撑,缩短业务链路,丰富数据样本的能效工具。在文章后续的内容中,会围绕这个定义进行展开。
为什么生产过程中需要类似 “造数工厂” 工具的存在?意义是什么?
我们站在开发、测试两个角色去看待这个问题。
开发:
- 又要联调了,开发环境没有支撑联调的数据啊?
- 开发 A:“我的功能要依赖开发 B 负责的功能产生的数据,我不是很了解,开发 B 你帮我弄一下呗”。 开发 B:“我没时间哦,我还要搞其他需求”。
- 联调过程中, 前端开发:“接口 500,后端看一下” 后端开发:“数据缺失了,我补一下,你再看看” 前端开发:“接口还是 500,后端看一下” 后端开发:“数据还有缺失了,我补一下,你再看看” 前端开发:“接口依然 500,后端看一下” 后端开发:“数据怎么还有缺失啊,那个后端开发,你帮我看看” 10 分钟过去了,接口还没 200
现在很多微服务基于 DDD,后端开发各自专注于自己的领域中,对依赖服务的内部逻辑和数据结果并不关注,只关注交互接口提供的数据结构和含义。这就导致了很明显的问题,开发环境进行联调时,花费大量时间在依赖数据的构造中,效率极低。
测试:
- 我的目标测试对象是功能 X,但是功能 X 依赖其他功能路径和对应的数据,难道我一定要把其他功能路径跑一遍后,我才能测功能 X?
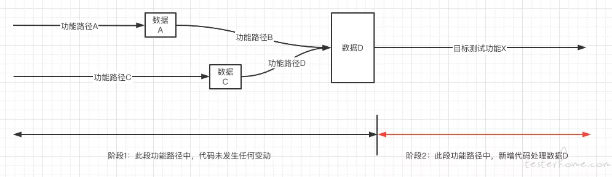
如果测试人员在迭代中为了生成目标功能依赖的业务数据,而去把代码未发生任何变动的功能都跑一遍,这种方式是低效率无意义的。在整个测试过程中,只有阶段 2 才是有效的测试。
如果有造数工厂,你的工作流程会变更为:
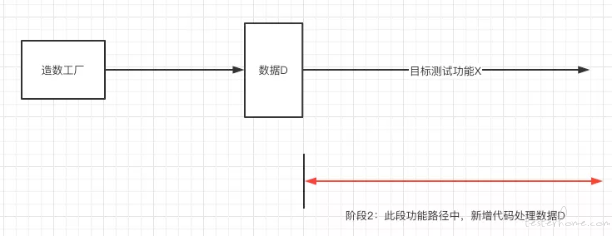
你可以在测试设计阶段中,在造数工厂中将你测试过程中需要的数据先准保好,在测试开始的时候直接在造数工厂中生成依赖的业务数据就好。
- 我的 UI 自动化测试用例,接口自动化测试用例都需要非常多的前置条件,搞得我的脚本内容好多,维护成本大大提升题。
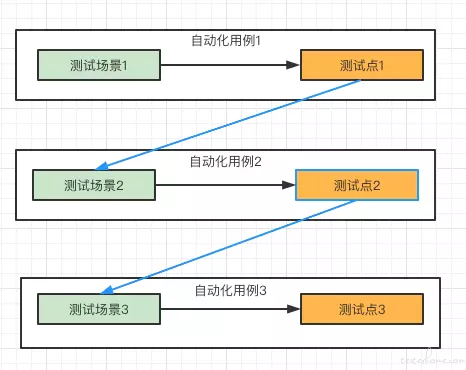
在自动化测试的实践过程中,以下问题会阻碍自动化测试落地:
* 用例和用例之间不独立,依赖严重
* 测试点小、用例大
* 维护脚本成本大
这三个问题背后的原因很大层度都是被 “测试场景构建” 的问题影响:
* 下一个测试用例的测试场景构建,依赖上一个测试用例的执行
* 为了构造测试场景,不得不做很多额外的操作,导致脚本步骤增多,从而导致整个自动化测试的稳定性下降
* 用例无效内容多,不同用例关联关系紧密,与测试点无关的功能变动有可能也会导致用例运行失败
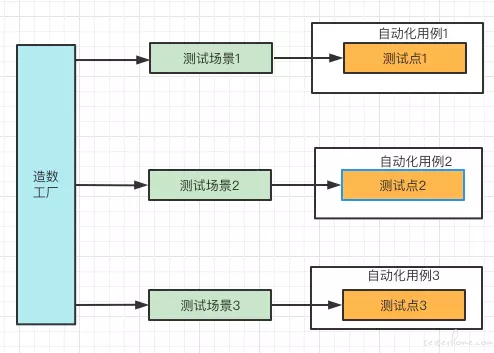
通过造数工厂的能力,将自动化测试脚本强依赖的测试场景构建从自动化测试本身抽离出来,自动化测试的用例只需要调用造数工厂进行测试场景构建。从而解决以上三个问题。
“造数工厂” 应该具备哪些核心能力
- 数据源管理能力
- 用能依赖的数据可能来源于不同的数据源,例如:Mysql、Clickhouse、Redis、ES 等,因此需要支持不同数据源的造数。
- 业务系统中常用、通用数据抽象能力
- 多种造数过程中会使用到相同的数据内容,因此这些数据需要抽象出来,可以复用在不同的造数过程中。
- 造数逻辑编写、组织能力
- 我们采用自行编写语言的方式对造数过程进行设计,并对造数过程中依赖的内容进行组织和管理。
- 造数过程中中间数据记录和传递能力
- 造数过程中,步骤和步骤直接需要数据的传递,因此造数过程中需要具备保存、记录中间数据的能力。
- 造数过程随意在开发、测试环境切换的能力
- 同一个造数过程可以在不同的环境中使用,相同功能的数据不需要在不同的环境中都具备造数过程。
- 造数过程拼搭能力
- 不同的造数过程可以随意的拼搭,组织,这样可以保证造数过程在不同功能中的复用。
我的 “造数工厂” 核心功能长啥样
- 数据源管理: 新建数据源,目前支持 mysql,kafka,mq
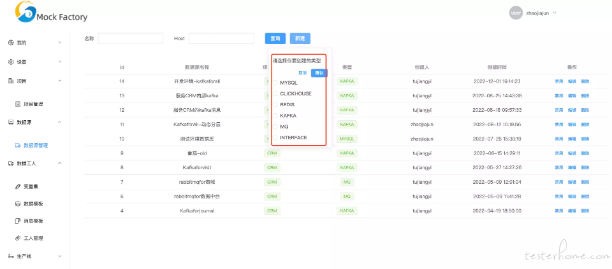
新建 kafka 数据源
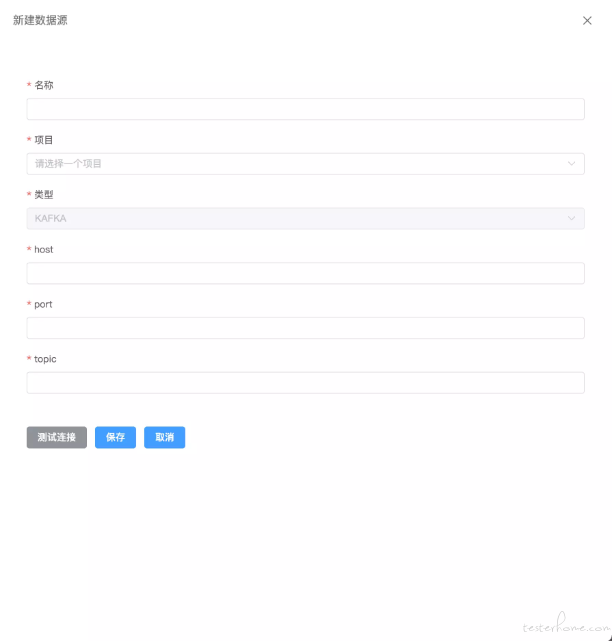
新建 MQ 数据源
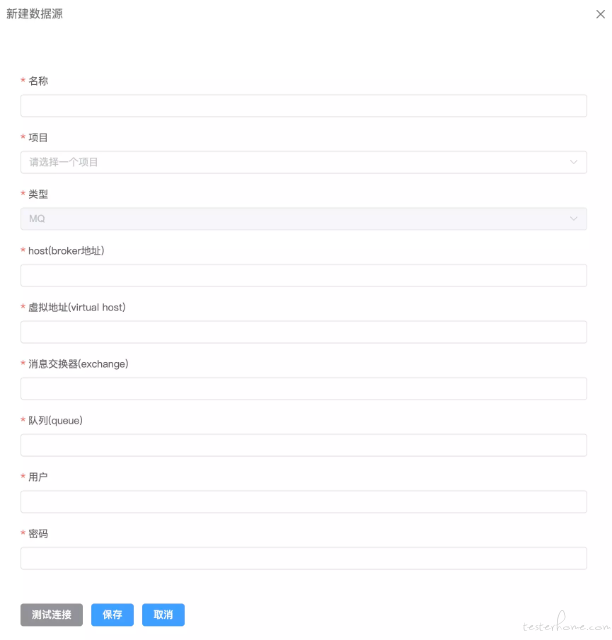
新建 Mysql 数据源:
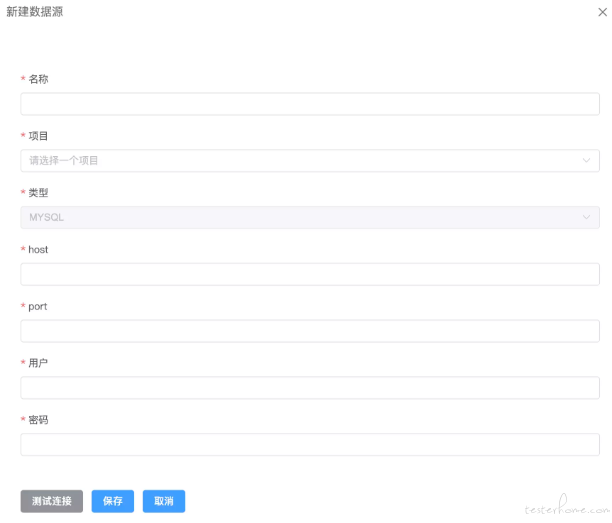
在数据源管理页面中你可以创建、编辑、查询你造数流程中会使用到数据源。
- 通用数据抽象:变量管理 变量采用 json 格式进行编写,保存,方便在造数过程中的使用
新建/编辑变量:
我们使用 codemirror6 的组件编写 json 的编辑器,并且在编辑器中提供了一些使用函数
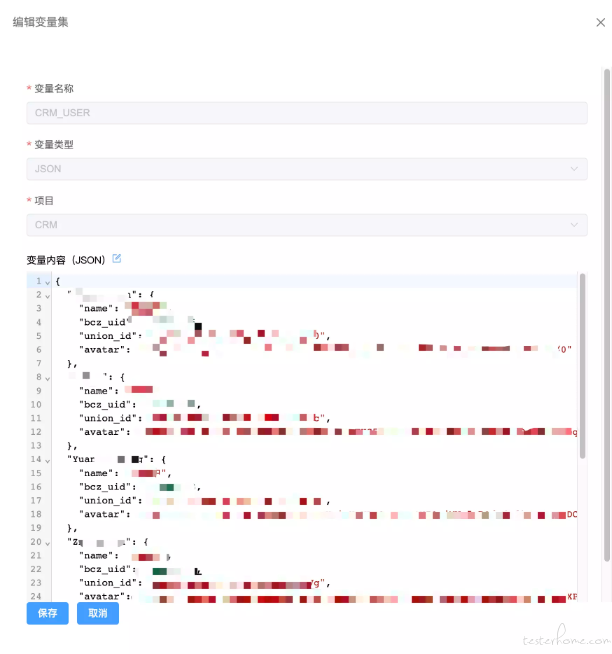
函数在编辑器中会自行提醒并补全
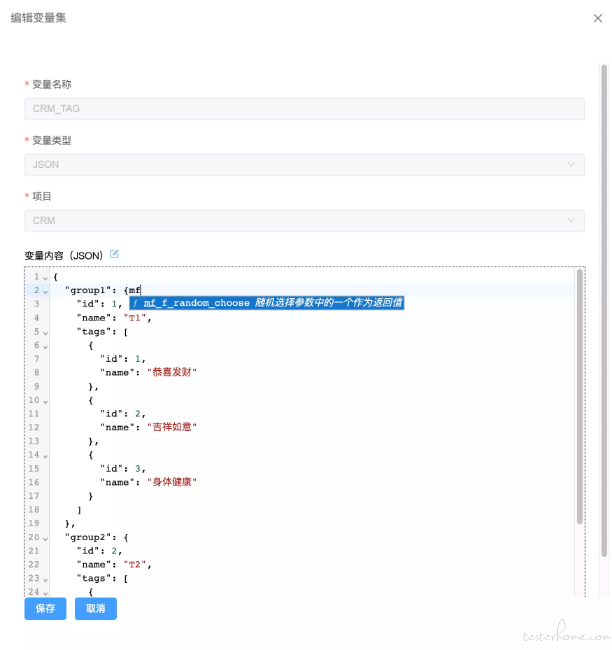
有时候,一个变量 json 内容会非常多,在当前看到编辑器中编写不是很方便,因此我们提供一个放大功能,就是标题旁边那个蓝色的小按钮
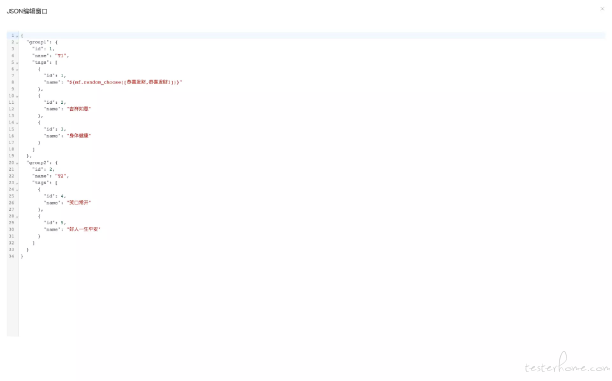
在当前这个纯净的编辑窗口中编写就会非常的舒服啦
- 造数逻辑编写、组织能力 #### 新建消息模板
消息模板采用 JSON 格式进行编写,主要针对业务系统通过消息通道(KAFKA,MQ)接收上游业务系统推数后产生业务数据的造数。这样在测试过程中,就不需要依赖上游业务系统的推送,我们自己按照约定编写业务消息,进行推数验证我们自己业务系统处理消息的业务逻辑就行。
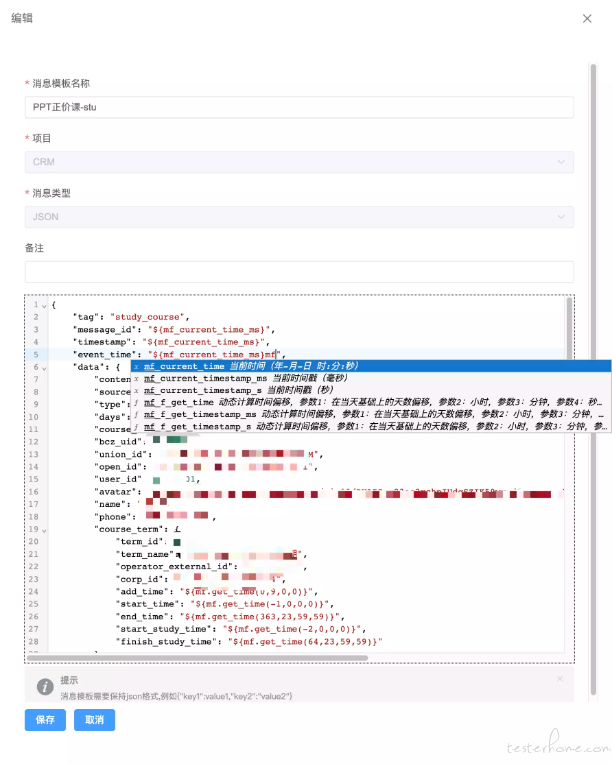
消息模板列表页面
通过消息模板的列表页面对存量的消息模板进行维护
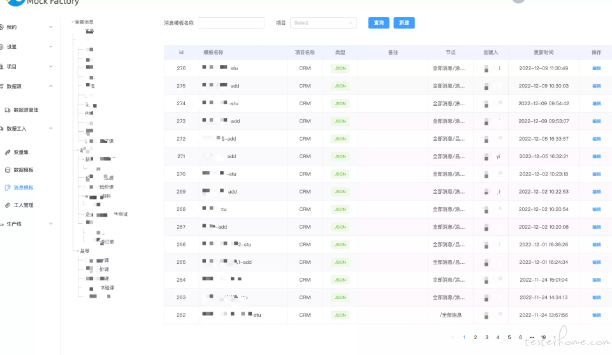
新建数据模板
处理针对消息队列的消息模板外,我们还提供了针对 Mysql、ClickHouse 的数据模板
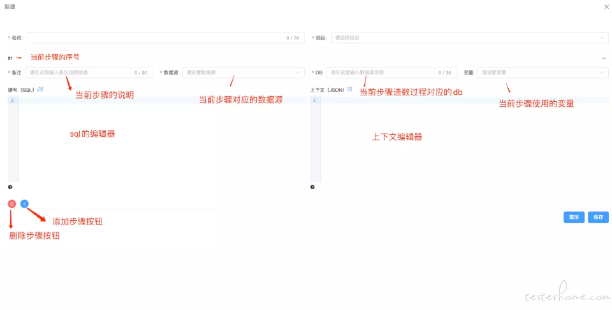
在一个数据模板中,可以有多个步骤:
通过添加按钮添加步骤,删除按钮删除步骤;
每个步骤都对应一个数据源,因为一个功能依赖的数据可能来自不同的数据源;
每个步骤都可以拥有他自己的变量,可以是多个。
在数据模板中使用变量
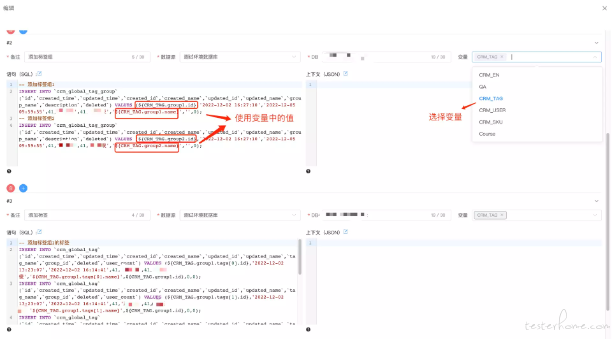
先为当前步骤选择变量,再编写 SQL 语句的时候可以直接引用
编写 SQL 的时候,变量的内容不需要手动编写,编辑器会为你做代码提示
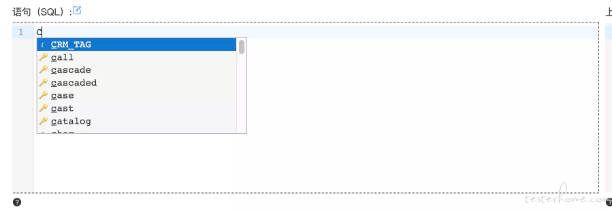

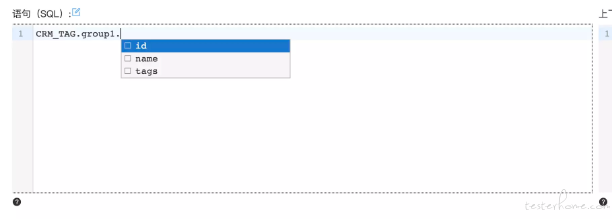
同样 SQL 的编辑器也提供了纯净编写的功能,并且两个不同的编写器的内容相互同步

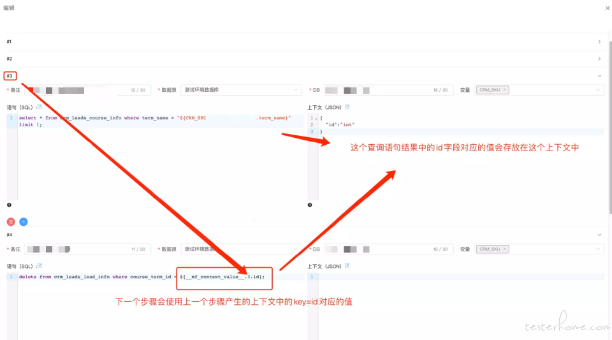
- 造数过程中中间数据记录和传递能力 在数据模板中使用上下文,在造数过程中,下一个步骤可能会使用到上一个步骤产生的内容,因此我们设计了给步骤添加上下文的功能,当前步骤产生的结果数据会存放在指定的上下文中,后续的步骤可以到指定的地方获取上下文中需要的数据。
- 造数过程拼搭能力 一个造数过程可以是多个数据模板和多个消息模板组成,因此我们抽象除了,工人和生产线的概念,在这两个概念上,数据模板和消息模板就变成具体的工作内容,而模板中的步骤则变成了具体的工作细节。
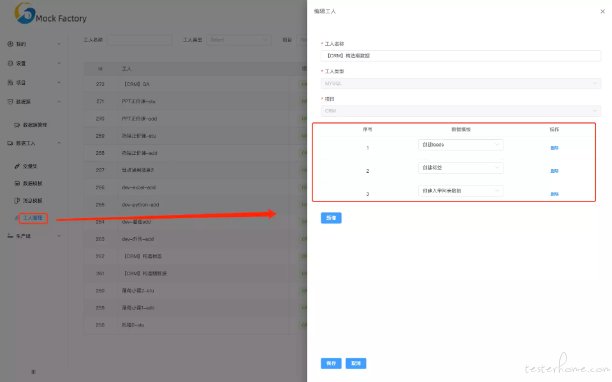
在一个工人中可以设置多个数据模板,他们的序号就是他们工作的顺序,模板中的上下文作用域只能在当前模板中,不能跨模板使用。
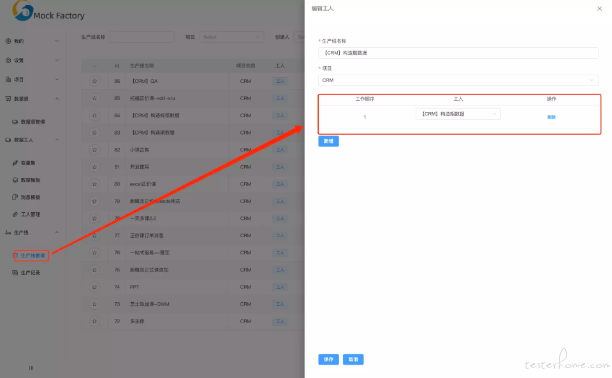
同理一个生产线中也可以有多个工人,他们的需要就是工人之间的工作顺序。
这样通过在工人中设置数据模板和消息模板,在生产线中设置工人并实现了造数过程中的拼搭能力。
综上所述,我们可以看到整个造数过程中数据结构的层级关系是:
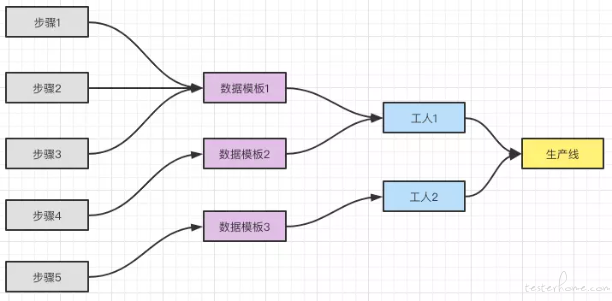
所以按照上述内容,为了使你的造数可用性,复用性更高,应该尽量做到以下几点:
- 尽可能的将通用数据抽象成变量维护
- 数据模板和消息模板中的步骤尽可能的不要太多,方便模板在不同工人中的复用
- 工人中的数据模板和消息模板尽可能的不要太多,方便工人在不同生产线中的复用
当前在项目中的落地情况
因为我们业务系统属于数据密集型系统,无论是后端和前端在开发环境中联调,还是测试执行过程中的提效,自动化测试中场景的构建,对造数工厂都有强烈的需求。目前在项目中已经使用起来,切实帮助测试解决了很大的问题,提升了测试效率,特别是数据模板和消息模板积累起来后,使用效率和带来的效果越来越大。
后续功能:
- 数据模板中,将消息模板,ClickHouse 打通,在一个消息模板中往 Mysql 中造数的同时也可以往消息队列中发送消息,也可以往 ClickHouse 中造数。在一个数据模板中支持多种数据源。
- 上下文可以跨数据模板使用。
- 新增工作空间,不同的登录用户具备自己的工作空间。