Hi,我是一名做了三年测试的 tester,2020 年以功能测试工程师的身份入职北京一家医疗培训公司,入职后为了提高测试效率,接触到接口测试,以下是从零到现在 (还有很大完善的空间,所以不能算是 1) 的一些心路历程。
于公司业务和团队现状而言,团队中仅我一名测试,随着产品功能日益丰富,导致回归测试任务量越来越大,紧靠人工回归,效率低,质量低,所以自动化测试势在必行。
于个人职业发展路径而言,每天点点点,看似很忙,但除了对业务流程越来越熟练之外,硬技能长进很慢,要想把测试这条路走宽走远,主动求变是必须的,站在功能测试工程师的角度看职业发展方向,无非就是安全测试、性能测试、自动化测试以及管理方向,刚好公司业务所需,所以决定先从自动化测试入手。
我认为打算做一件事情之前,如果准备过多,往往会阻碍起步的脚步,过犹不及,不如稍作准备就马上抛竿,实践一下鱼塘里有没有口儿。所以我选择了上手比较容易的 JMeter,从接口自动化开始突破。当时手握《全栈性能测试修炼宝典 JMeter 实战》这本经典工具书,参考网上优秀的实战经验帖,很快就搭建出了一套 200 条 case 的脚本,脚本中尽可能的提取公共变量,解决接口依赖问题。
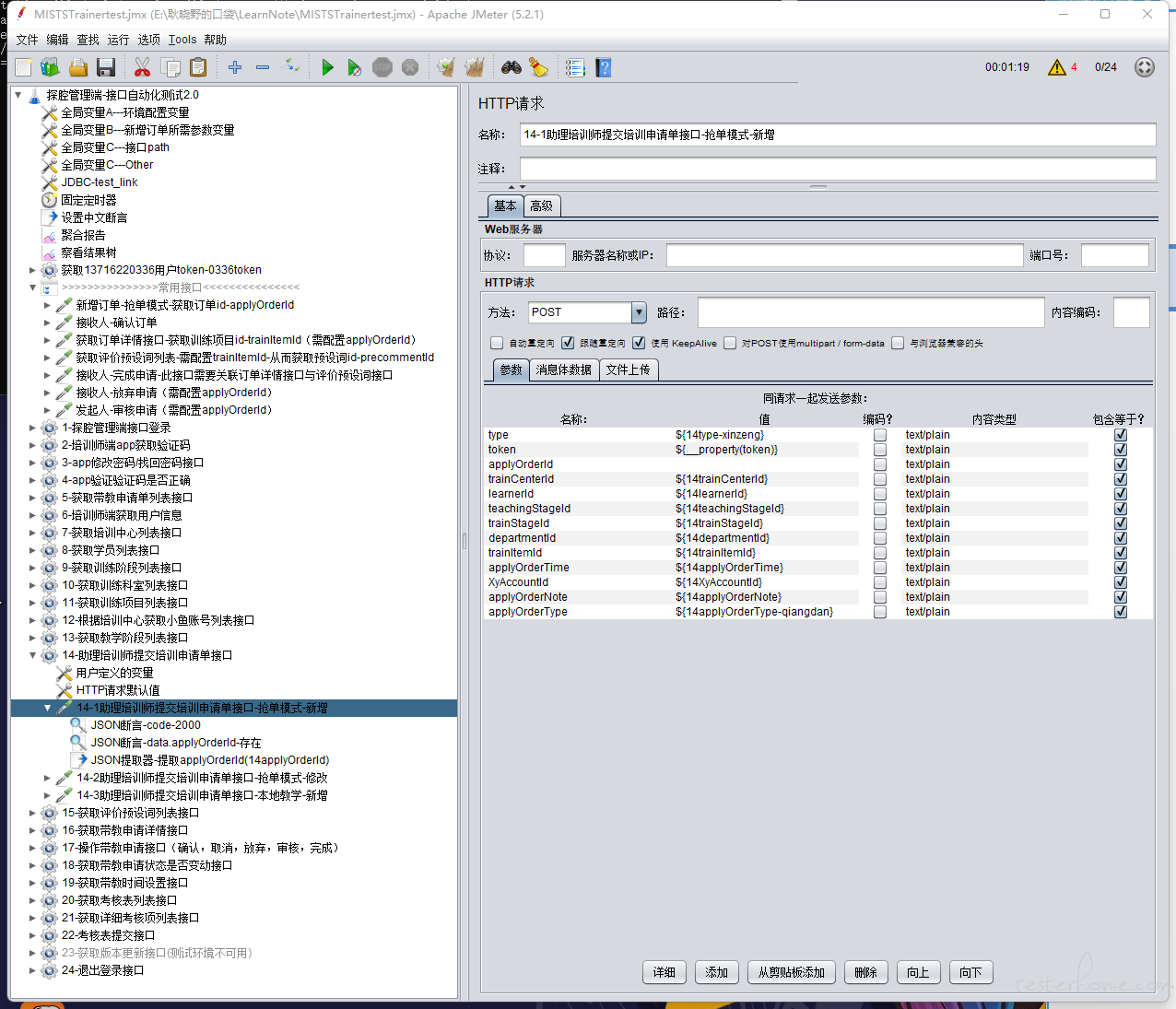
随着 case 越来越多,发现一但有接口变更,维护起来的难度极大 (极容易眼花缭乱),有一次因为入参的值多了一个空格,导致我整整找了 3 个多小时,当发现原因时直接崩溃 (具体是哪个参数值想不起来了,举个例子:正确:${14trainCenterId},错误:${ 14trainCenterId}),就因为在 14 面前多了一个空格,我在 200 多条 case,几千参数值中找了整整一下午,至此,决定放弃 JMeter。
其实 JMeter 不适合在团队中做接口自动化测试的另一个重要原因是多人合作编写一个脚本并不是很方便,但介于当时团队中只有我一个人,所以没切实的体会过这个缺点。
虽然弃用 JMeter,但在编写接口测试期间,脑子里也形成了一套接口测试 case 的编写方法论,比如接口测试 case 设计需要考虑正常情况 (必填项必填,参数之间的组合,参数值的遍历等等),异常情况 (必填参数参数值为空、为异常值、索性连参数都不写等等),其实接口 case 的设计和业务功能测试 case 设计时的思路差不多,唯一区别可能是手动点点点时一些参数的输入被大前端限制住了,但是接口测试就可以随便传参。
弃用工具那就只好选择编程语言了,当时选择 Python 其实没那么多高大上的理由,单单是因为看到了那句"人生苦短,,,",再加上在自动化测试这方面 Python 的呼声也很高,我自己也倾向做事尽可能的立竿见影,所以没有考虑 Java。
要单说仅仅让 Python 脚本跑起来,也许只需要学一些基础的语法,迟则三五天的事情,再选择一个测试框架,当时选择的是这样的组合:Python+unittest+requests。前期照葫芦画瓢一边学 Python 语法,一边学习测试框架。很快就写出了一套和之前 JMeter 一样效果的测试脚本(虽然整个项目就仅有两个文件:test_.py 和 run.py,虽然简陋,但是能跑,入门学习是够了的)。至此也算是入了道儿了。
因为我是刚刚起步,团队中也没有这方面的前辈可以指点,所以几乎是摸着石头过河,走了很多弯路 (也许现在走的路也不直),但我每积累一段时间我都会停下来总结思考是不是需要重构,并不会随着思维惯性 瓷蹦蹦 的复制粘贴。截至目前,有三版较大的改动,让我说给你听。
简单来说,第一代主要的事情就是搭建基础框架,使用 parameterized 实现数据驱动测试。
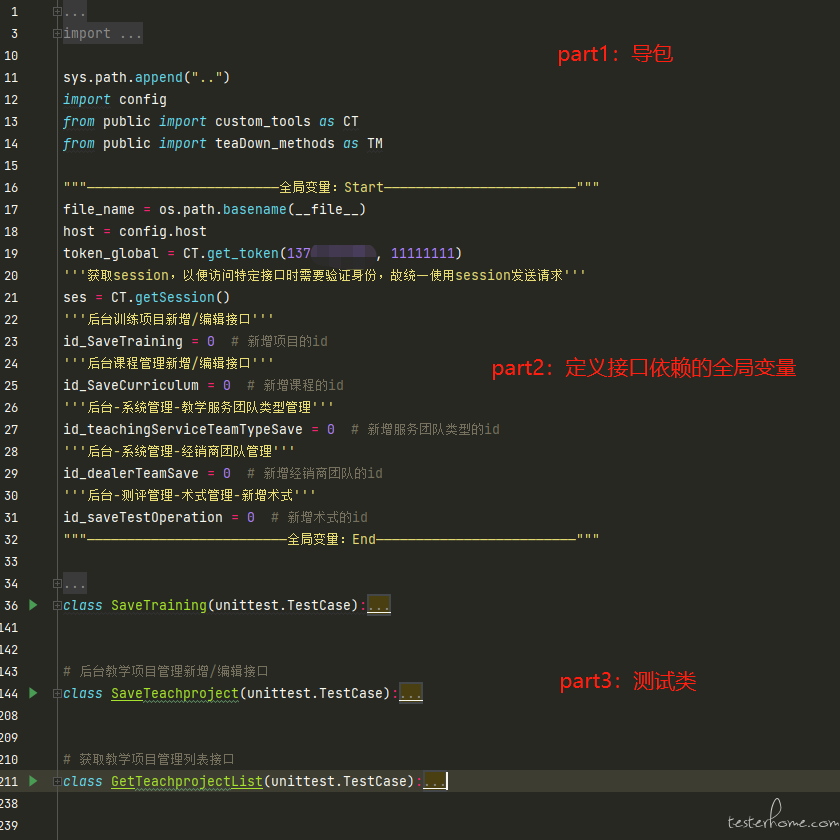
第一代我的目录结构是这样的:
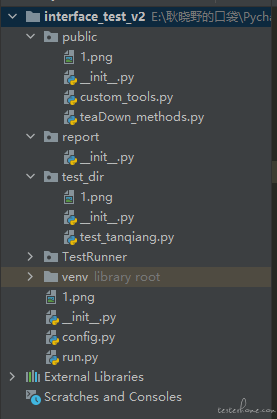
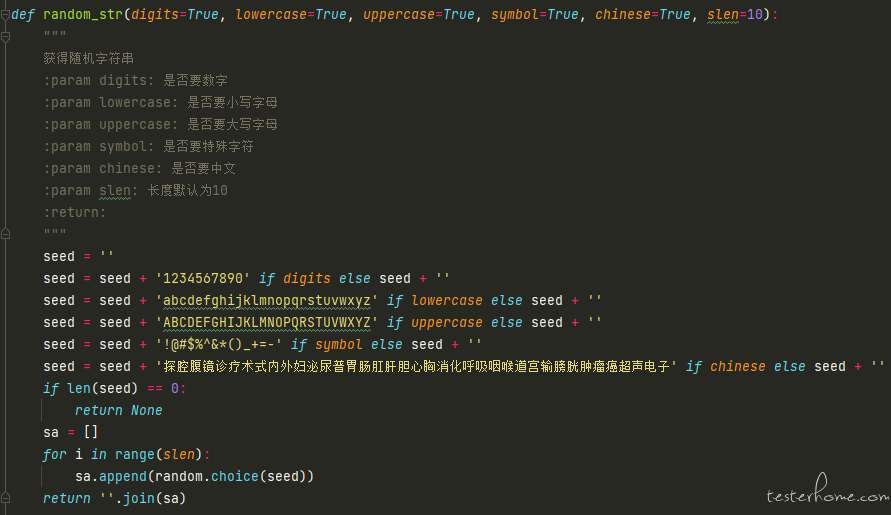
其中有 4 个目录和 2 个文件,需要解释的可能是 public 下的 custom_tools,我将一些通用方法写在这个文件里,例如获取指定个数个字符串的 random_str 方法、对参数进行 md5 加密的 to_md5 方法等。
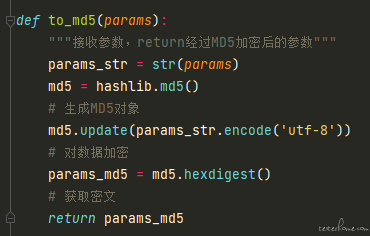
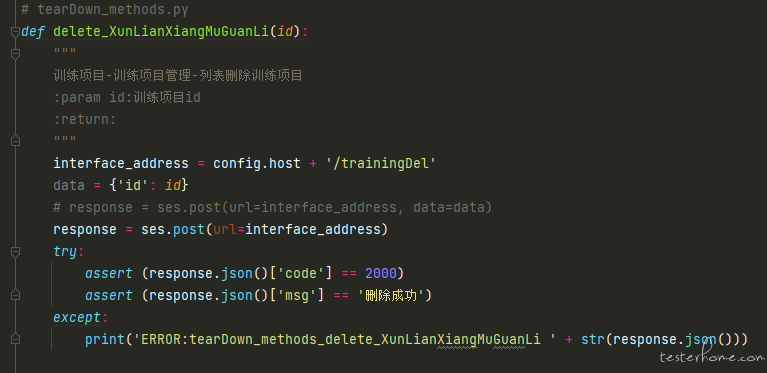
至于 public 下的 tearDown_methods 文件,我当时为了清理测试数据,定义了一些数据删除的方法,举个场景:接口 A 生成产品、接口 B 通过商品 id 编辑商品、接口 C 通过商品 id 删除商品。在这个版本中我就把接口 C 写到了 tearDown_methods 文件中,然后再在正式的测试脚本文件中定义 teardown 方法调用删除接口(此时可能就有小伙伴质疑了,你这不是脱裤子放屁么,哈哈,我刚开始的时候还认为这种写法很高端,但在不久之后我就意识到了这个问题,所以在后面的版本就改正了)。
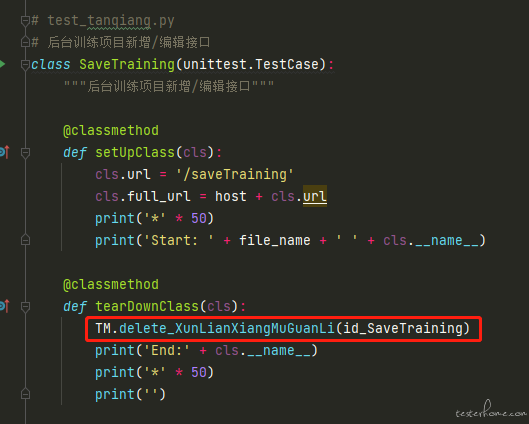
正文-test_tanqiang.py 的编写思路是这样的:
为了解决接口依赖的问题(例如上面举的例子:接口 A 生成产品、接口 B 通过商品 id 编辑商品、接口 C 通过商品 id 删除商品)我在测试文件的前部分初始化了多个全局变量 (例如 id_product = -1),然后在新增接口中,新增成功后获取产品 id,并赋值给 id_product ,然后在编辑和删除接口中就能使用这个值。文件结构大致如下:
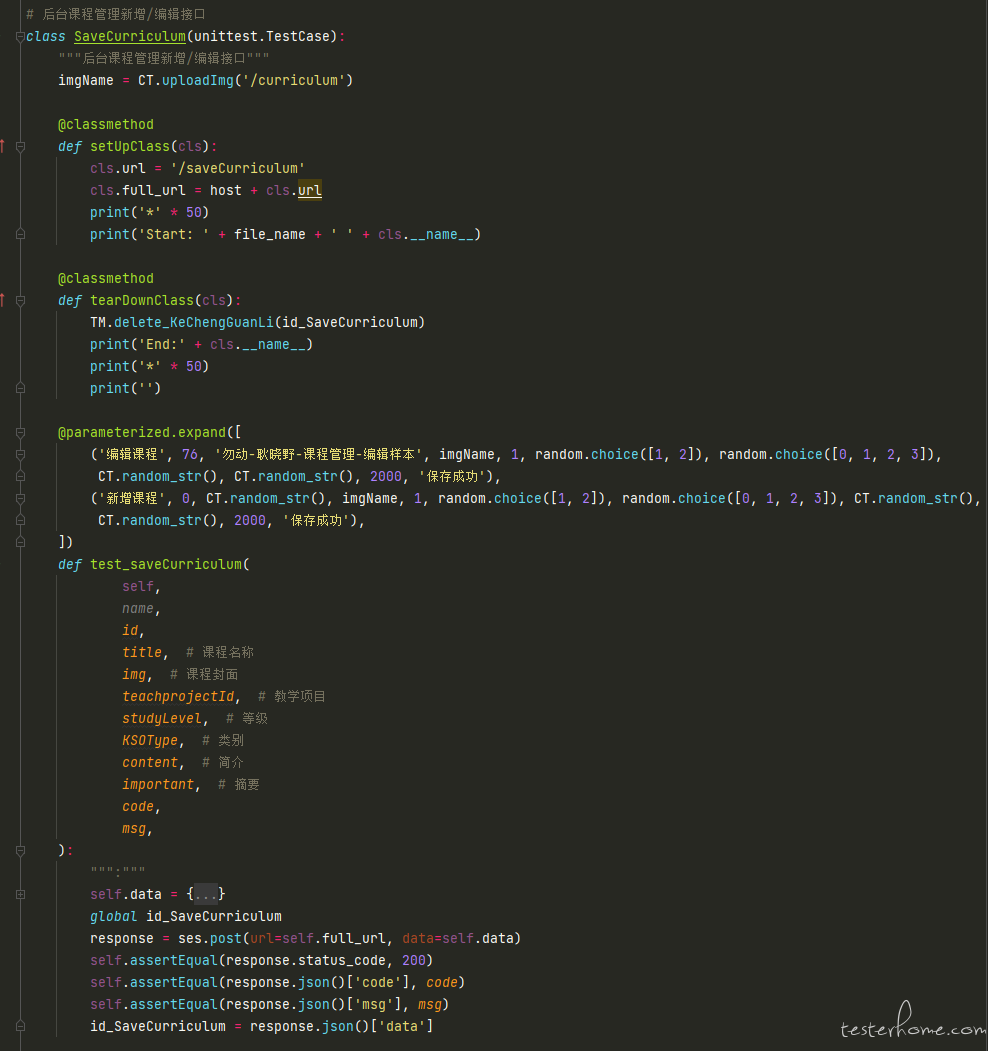
第一版使用 parameterized 装饰器做了数据驱动测试,完整的一条 case 如下:
另外,我将不同环境和不同端的 HOST 写到了 config 文件中。
这个版本也能实现生成测试报告,并发送电子邮件的功能,想的是为日后持续集成做铺垫。
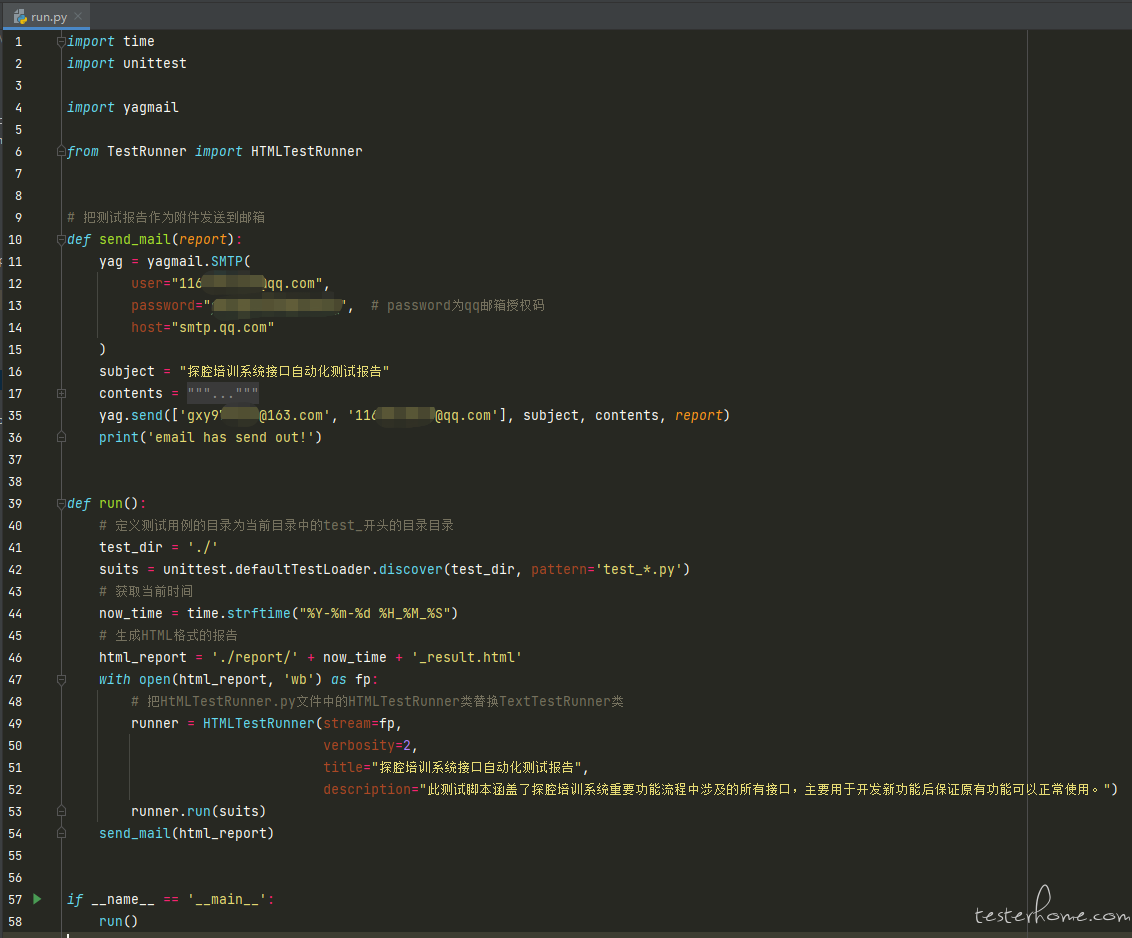
第一版的成果和反思:在这种模式下,我一共写了 70 多个接口的 case,实践证明使用 Python 做接口自动化测试确实比 JMeter 灵活得多,可实践后也发现如下问题:
1.没必要将测试数据清理的方法单独写在一个文件中,可以直接写在测试类下,因为删除接口也是接口测试的范畴。
2.数据驱动测试时,将测试数据罗列在测试方法上方,如果接口入参过多,那么在阅读及后期维护上很不方便 (因为得数索引位置)。
3.数据驱动测试时,如果其中一条 case 断言失败,也不知道具体是其中哪条数据出的问题。
4.测试 case 的执行顺序不可控。

根据第一代的经验和问题,重构框架,详细如下:
变动 1:弃用数据驱动模式,因为做接口自动化测试的初衷就是为了做回归测试(保障原有功能不受影响),而不是通过接口自动化测试发现新的问题。再加上团队中就我一名测试,我的时间重点还是在保障功能测试上。根据以往接口受影响的经验来看,接口如果受影响更多情况会直接 500,而不会是 type 传 1 接口正常,type 接传 2 接口异常。所以在第二版中,我仅选择每个接口的正常入参,并将测试数据直接写进了测试脚本里。
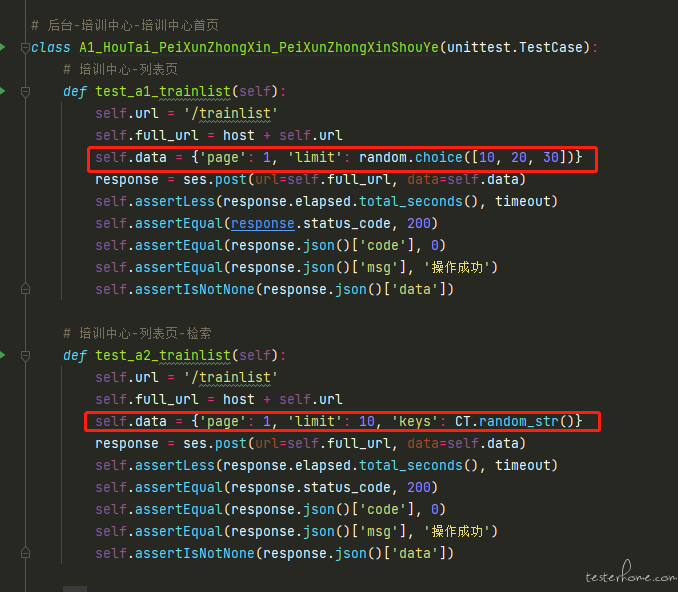
变动 2:通过文件、类、测试方法的名称来控制用例的执行顺序。
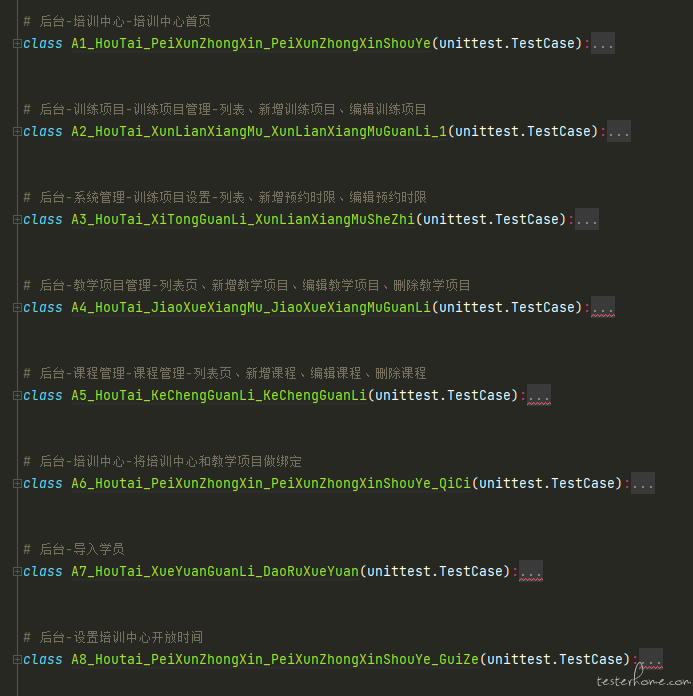
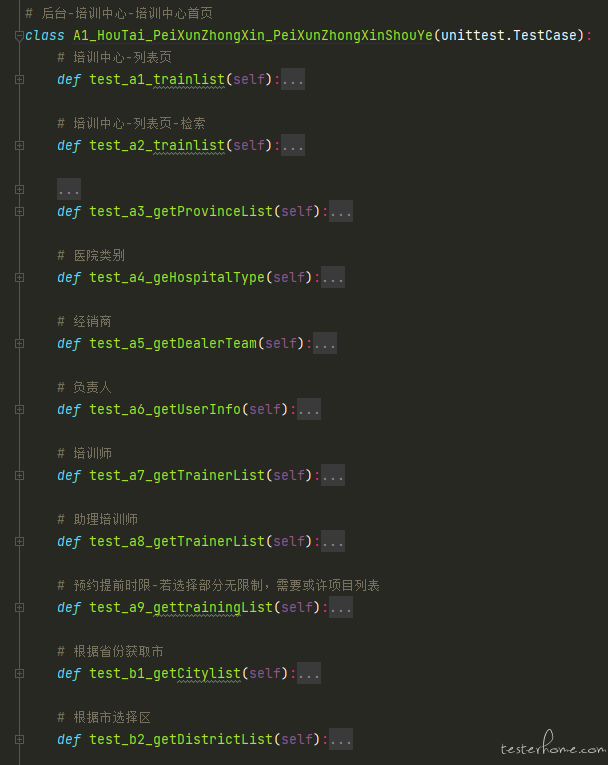
变动 3:移除 public 下的 teardown_method.py 文件,将数据清理接口写进 test_xxx 文件中的测试类下。
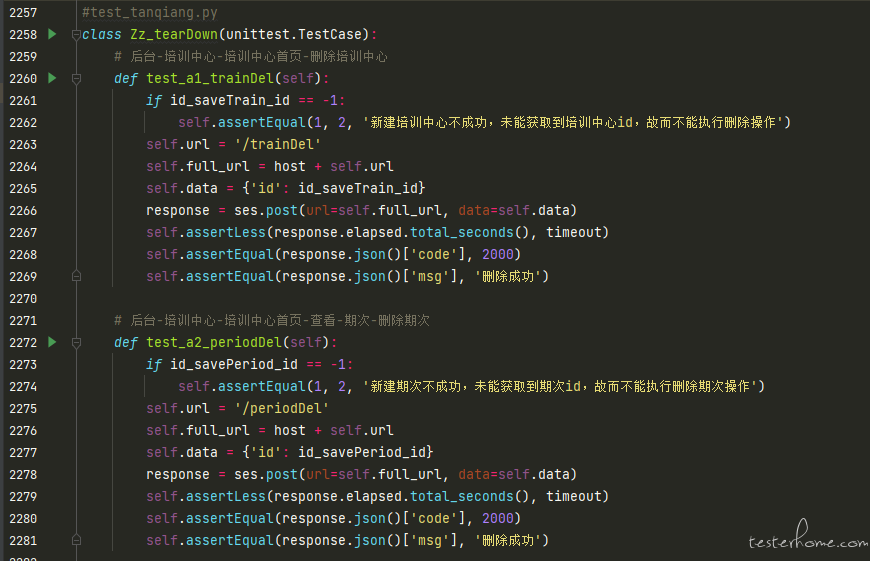
变动 4:丰富接口断言。接口自动化测试重中之重就是断言设计,所以本次改版丰富了断言类型。
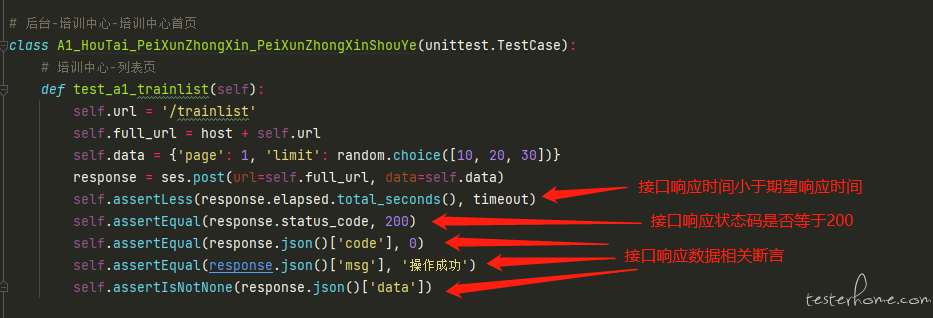
(有可能有的小伙伴会发出疑问:问什么都断言了响应的 code,还有必要断言响应的 msg 吗?我的思考是:如果你所处的团队接口开发比较规范的话其实 code 和 msg 断言其中一个就可以了,但我目前的团队并不是很规范,例如有的接口成功的响应是{'code':'2000','msg':'操作成功'},有的接口成功的响应是{'code':'0','msg':'成功'},基于此,我对 code 和 msg 都做了断言。)
变动 5:接口依赖时采用 “错误先行” 编程思想。(可能有小伙伴会发出笑声,寻思为什么还有这种写法:self.assertEqual(1, 2, '省份 id 获取失败,所以无法进行新建培训中心操作'),后来我也发现了这个问题,所以在下个版本中改为 “raise KeyError('省份 id 获取失败,所以无法进行新建培训中心操作')”)

第二版的成果和反思:在这个模式下我共集成了 150 个接口的自动化 case。不过在实践中又发现了新的问题:如果某条 case 报错,那么报错后我并不能清楚的知道测试时的请求体的具体内容,以及响应体的具体内容。这会让我在排查以及跟开发反馈时很困难(运行完乌压压一片红,具体错在哪不是很明了)。
我加入这家公司正是团队刚刚起步的时候,所以那时迭代很快,每天都很忙,转眼入职两年了,产品预期的功能都已上线,我们公司主打的本就不是软件,it 部是职能部门,所以一旦该有的功能都有了之后也不会有太多大动作的更新(懂得都懂)。这个时候我就有时间再重新思考下当前的测试脚本了。
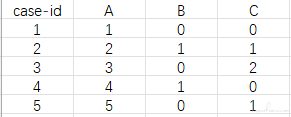
最近在反复的读《测试架构师修炼之道第 2 版》这本书(强烈推荐给大家),书中系统的教授了如何设计测试用例,从其中教授的多参数组合测试方法中得到启发,大致意思就是比如一个接口有 3 个必填参数(参数 A(可取值:1,2,3,4,5)、参数 B(0,1)、参数 C(0,1,2)),相互之间没有关联关系,据此可生成 5 条 case:
基于此,我又再次想到了数据驱动测试,这次想把测试数据源放在 excel 中,可能有的小伙伴就会吐槽这种 excel 模式的数据驱动测试,会觉得在测试前先去整理 excel 很麻烦。我本次的策略是,不手动在 excel 中数着格子填写测试数据,而是编写一个生成测试数据的方法,让其自动生成测试数据。整体思维脑图大致如下:

(整体思路)
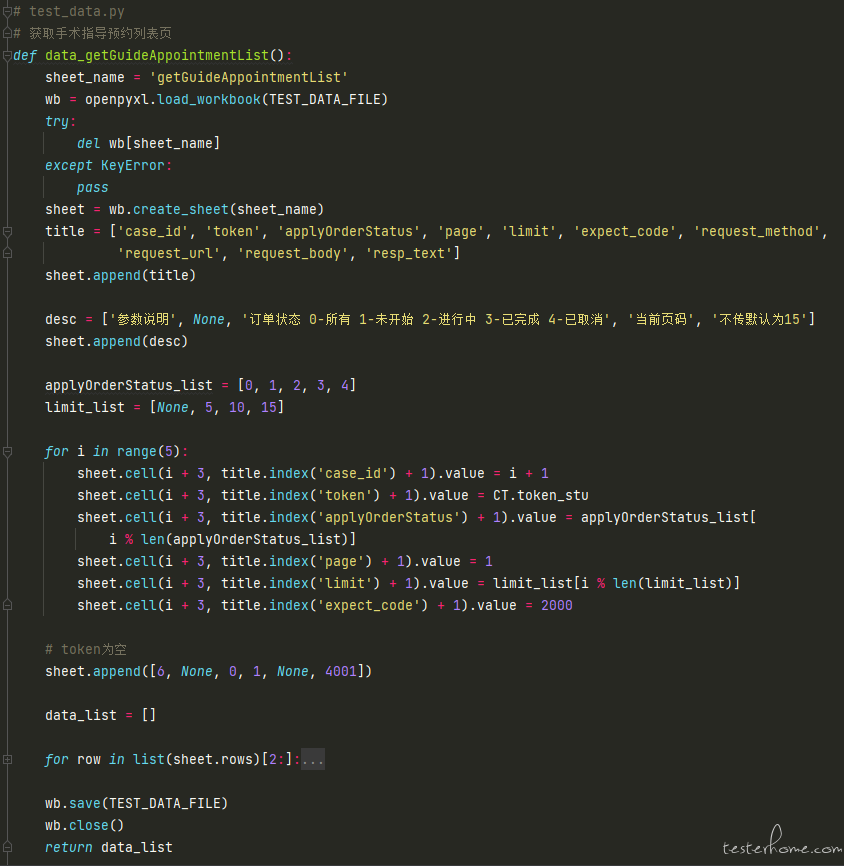
(测试前编写生成测试数据的方法(需要根据每个接口编写各自的测试数据生成方法))
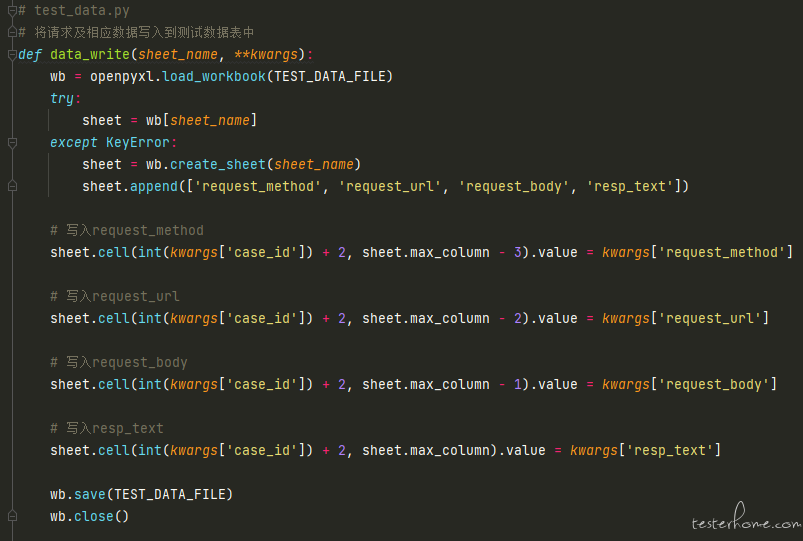
(将测试运行过程中的 response 的相关信息写入到 excel(这个方法可公用))
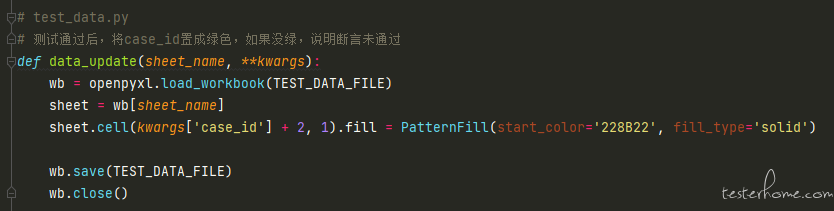
(测试结束后,如果所有断言都通过,则将 excel 中对应的 case_id 置成绿色(这个方法可公用))
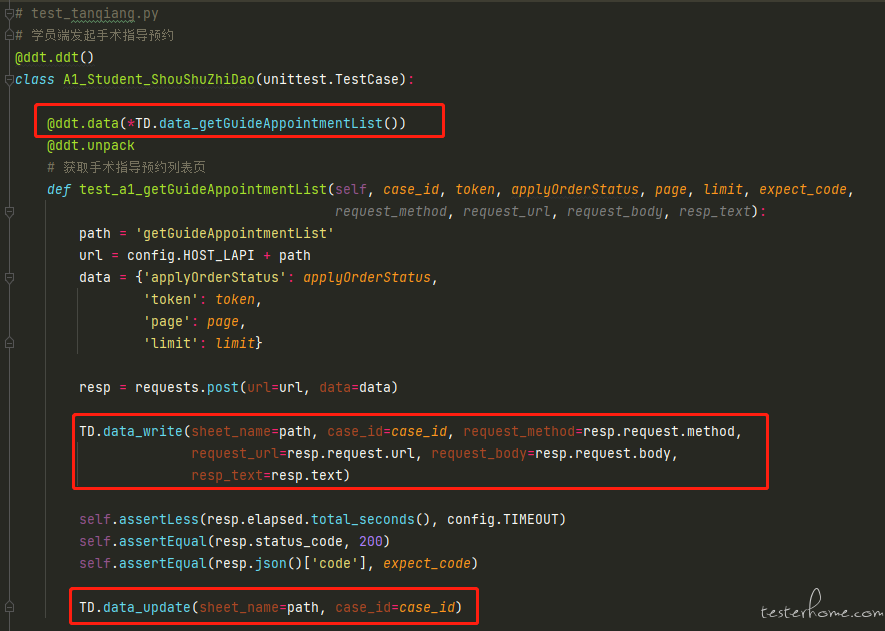
(在 testcase 中调取响应的方法)
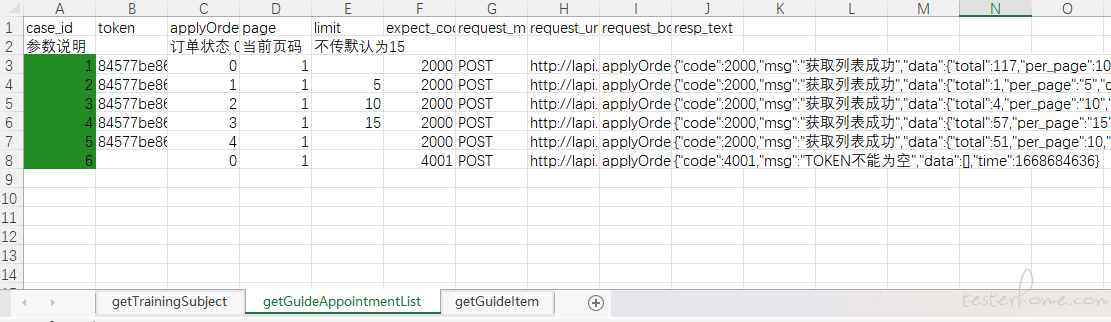
(测试运行结束后,excel 中的结果)
第三版除此之外的变动主要还有:
1.将原测试脚本中的全局变量全部移到了 config 文件中,使得测试脚本文件更加整洁;
2.将原测试 case 中不必要的 self.去掉了,只有在断言的时候才加 (self.assertEqual()),例如之前会这么写:self.url = "XXX" self.data = {'id':1} ,现在改成:url = "XXX",data = {'id':1},理论可度娘 “在类方法中添加 self 和不加 self 的区别”,反正我实践结果是加与不加都不影响测试结果,那自然不加(能少写就少写,~.=)。
第三版的成果和反思:目前使用这个版本刚刚写了 23 个接口的 case,虽然看似在写正式脚本前还要先编写一个生成测试数据的方法很麻烦,但实操发现并没有想的那么麻烦,而且这个投入产出比我认为还是很高的。也许以这个模式写的接口数量还不够多,等在沉淀沉淀一定还会发现其他新的问题。
我们的成长不就是不断的发现问题,不断地解决问题,再发现新的问题么,嘿嘿。
罗里吧嗦写了一大推,更多的是对自己在接口测试这方面从开始到现在的一个总结,就像开头说的,因为目前团队中在测试方面能相互沟通的伙伴几乎没有,所以一直都是自己摸着石头过河,走了很多弯路,现在走的路也可能不是直的,我真的真的真的真的很渴望沟通,希望各位佬儿哥佬儿姐能够不吝赐教,将发现的问题或者建议留言给我,如果能添加微信对我指点一二那简直太哇塞了(VX:GXY1162031010)。
其实重构到当前版本仍然有很多问题没有想通该怎么解决,大家帮我盘盘呗:
问题 1:接口依赖怎么做数据驱动测试?
场景描述:创建产品的接口 A,调用成功之后会提取新建产品的 id,并保存为全局变量(例如:id = -1,接口 A 调用成功后置为新值,例如 id = 100),编辑产品的接口 B,在编写接口 B 生成测试数据的函数中,期望能够读取到 id 的最新值 100,实操后发现是原值-1。这个问题的原因我也知道个大概,因为运行测试前先加载所有的 ddt,然后才会运行 testcase,所以读不到在测试运行中赋予 id 的新值 100。有佬儿哥指点,可以把 id = -1 写成 id = [-1],这样 ddt 就可以在测试运行中读到新值,我测试后确实可以,但又有佬儿哥建议接口依赖不能做数据驱动测试,所以目前还在不断试错、尝试。
问题 2:针对查询接口,怎么做断言?
场景描述:新增一个产品,新增成功后拿到产品 id = 100,然后对查询产品接口 C 做断言,我目前的断言策略是 “self.assertIsNotNone(response.json()['data'])”(捂脸),我尝试过断言查询结果的第一条数据的 id 是否等于 100,可是这种断言很不稳定,如果有多人在使用,那么列表中的第一条数据很有可能就不是你刚刚添加的数据。所以目前还没想到合适的断言方法。
问题 3:在第三版的 testcase 中,在获取到响应后,都会固定的调用 TD.data_write() 方法,且传参内容很多,并且即使是不同的 testcase,在这一步时,传入的参数都是一样的。有没有什么优化方法,可以避免每个 testcase 都写这么多重复的内容?

本文参与了TesterHome 技术征文,欢迎正在阅读的你也加入
