在一定程度上,测试二进制大小和 RAM 与测试是否不稳定有很强的相关性,但随着二进制和 RAM 大小的增加,线性拟合残差也会增加,相关性则降低。
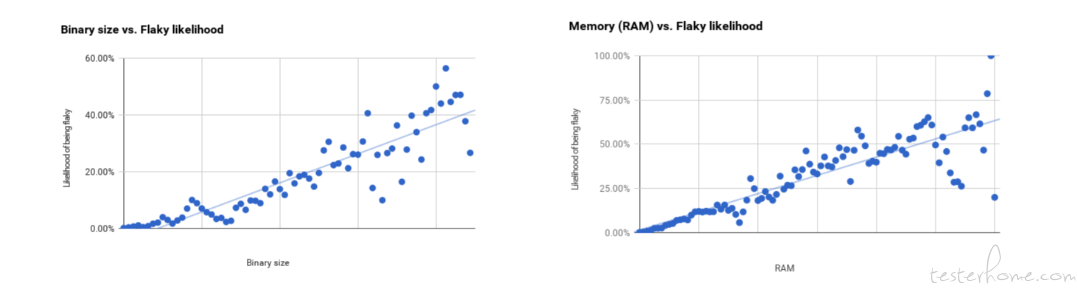
某些工具具有更高的不稳定测试率。但是二进制大小和 RAM 比工具更具预测力。

flaky 形容词,意为 “片状的、古怪的”。所谓 Flaky Tests,就是指在被测对象和测试条件都不变的情况下,有时候失败、有时候成功的测试,即不稳定的测试。它是自动化测试的产物。
无法实现测试目标:理想情况下,我们希望测试结果是确定的:测试失败,那么软件存在 bug;测试成功,则软件没有 bug。但 Flaky test 的存在就破坏了这种关系,我们无法根据测试结果来评判软件质量的好坏,测试目标就无法达到;
有可能摧毁测试价值:(自动化) 测试是有巨大价值的。软件开发人员基于自动化测试的结果判断软件代码的改动是否可以提交;项目管理人员基于自动化测试的结果判断软件产品是否可以交付。如果测试结果出现随机性 (尤其当 Flaky Tests 被证明是由非软件代码因素造成时),软件开发人员和项目管理人员对自动化测试的信任度将大打折扣;
降低研发团队的效率:在 TDD(测试驱动开发) 中,代码仓库的任何改动 (包括产品代码和测试代码),通常都需要经过 (自动化) 回归测试集的验证,才能被接受。一旦出现 Flaky Test,意味着需要花费时间去检查和确认测试失败不是由已知 Flaky Test 问题引起的。一定程度上降低了团队的效率;
影响研发团队的协作:TDD 模式中,开发人员和测试人员是紧密合作的,这也是产生高质量产品的重要条件。但由于 Flaky test 的存在,有可能会给双方的合作带来负面的影响,开发人员会认为 “我的改动没有涉及到这一块测试用例就失败了,测试用例有问题 “,而测试人员则认为 “之前用例都没有问题,结合你的代码跑就出现问题,代码质量有问题”。相互抱怨,就会影响彼此间信任。
根据 google 发表的文章《where-do-our-flaky-tests-come-from.html》所分析,有两个观点:
在一定程度上,测试二进制大小和 RAM 与测试是否不稳定有很强的相关性,但随着二进制和 RAM 大小的增加,线性拟合残差也会增加,相关性则降低。
某些工具具有更高的不稳定测试率。但是二进制大小和 RAM 比工具更具预测力。
由此可以看出,Flaky Test 是自动化测试中常见的产物。那么导致它形成的主要原因是什么呢?
由文章《test-flakiness-one-of-main-challenges.html》所述,一个被测应用程序或系统的堆栈可分 4 层。最底层是硬件。然后是操作系统,上面是提供系统接口的库。在最高层是中间件,该层提供特定于应用程序的接口。
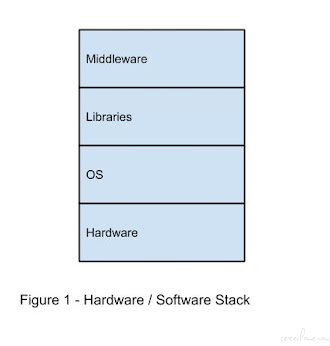
根据这一结构可以对不稳定测试的来源进行分组:
由文章《test-flakiness-one-of-main-challenges.html》,每一组件典型的原因和补救措施:
| 不稳定的原因 | 分析提示 | 补救措施 |
|---|---|---|
| 初始化或清理不当 | 1. 查找「未初始化变量」的编译警告; 2. 检查初始化和清理代码; 3. 检查环境是否已正确设置和清除,验证测试数据是否正确。 |
1. 在使用之前用适当的值显式初始化所有变量; 2. 正确设置和拆除测试环境。考虑一个验证环境状态的初始测试 |
| 关于测试数据状态的无效假设 | 独立重新运行测试 | 使测试独立于其他测试的任何状态和执行结果 |
| 关于系统状态的无效假设,例如系统时间 | 明确检查系统依赖性假设 | 删除或隔离 那些 SUT 依赖但你又无法控制的环境方面关系 |
| 对执行时间的依赖,期望异步事件以特定顺序发生,等待没有超时,或者测试和应用程序之间存在竞争条件 | 1. 记录访问应用程序的时间; 2. 作为调试的一部分,在应用程序中引入延迟以检查测试结果的差异。 |
1. 将同步元素添加到测试中,以便它们等待特定的应用程序状态; 2. 禁用不必要的缓存以获得应用程序响应的可预测时间线 |
| 依赖于测试运行的顺序 (类似于上面的第二种情况) | 独立重新运行测试 | 使测试彼此独立,并且不受之前运行的任何状态影响 |
| 不稳定的原因 | 分析提示 | 补救措施 |
|---|---|---|
| 未能为 SUT 分配足够的资源,从而阻止它运行 | 检查日志,查看 SUT 是否成功启动 | 分配足够的资源 |
| 测试安排不当,导致用例 “冲突” | 以不同的顺序显式独立运行测试 | 使测试彼此独立运行 |
| 系统资源不足,无法满足测试要求 | 检查系统日志,查看 SUT 是否耗尽了资源 | 修复内存泄漏或类似的资源 “出血”, 并分配足够的资源来运行测试 |
| 不稳定的原因 | 分析提示 | 补救措施 |
|---|---|---|
| 竞争条件 | 通过日志记录共享资源的访问 | 将同步元素添加到测试中,以便它们等待特定的应用程序状态。注意:不要添加任意延迟,因为随着时间的推移,这些延迟会再次变得不稳定 |
| 未初始化的变量 | 查找「未初始化变量」的编译警告 | 在使用之前用适当的值显式初始化所有变量 |
| 对测试的刺激反应迟钝或无反应 | 记录发出请求和响应的时间 | 检查并解决任何导致延误的原因 |
| 内存泄漏 | 1. 查看测试运行期间的内存消耗; 2. 使用 Valgrind 等工具进行检测 |
修复导致内存泄漏的编程错误,这篇文章https://en.wikipedia.org/wiki/Memory_leak有很好的讨论 |
| 资源超额认购 | 检查系统日志,查看 SUT 是否耗尽了资源 | 分配足够的资源来运行测试 |
| 对应用程序(或依赖服务)的更改与相应的测试不同步 | 检查修订历史 | 制定一项政策,要求代码更改要有测试用例伴随 |
| 不稳定的原因 | 分析提示 | 补救措施 |
|---|---|---|
| 网络故障或不稳定 | 检查系统日志中的硬件错误 | 修复硬件错误或在不同硬件上运行测试 |
| 磁盘错误 | 检查系统日志中的硬件错误 | 修复硬件错误或在不同硬件上运行测试 |
| 与正在运行的测试无关的其他任务/服务消耗的资源 | 检查系统进程活动 | 减少测试系统上其他进程的活动 |
有时候,用例不稳定原因并不一定能够分析并解决。所以需要有其他策略:
可靠性测试:造成 flaky test 的原因可能是软件因素,也有可能是测试本身因素。为了减少自动化测试自身的因素,可以在用例上线前,进行严格的可靠性测试。比图,不间断地对用例重复执行几十次、上百次,全部通过后才认为测试用例的质量过关;
重跑处理:回归用例失败时一般有两种可能:一是代码改动破坏了回归测试集,产生新的问题;二是测试用例是 Flaky test,其失败和代码的改动没有关系。怎么去判断呢?可以触发重跑失败的用例,只有连续失败或者达到一定失败率后,才认定用例不是 Flaky test;
隔离处理:将 Flaky Tests 移到隔离区。任何人提交代码都不会再执行隔离区的用例;
分析趋势:可以监控自动化测试来检测 Flaky test 程度的变化,拿到有关 Flaky Test 的准确信息,分析引发的特征来帮助识别不稳定的结果而无需重跑。google 就有专门的团队研究 Flaky test。市面上也有相应的付费工具https://buildpulse.io/。
测试的自动化程度越高,Flaky Tests 的问题也就越突出。所以,承认 Flaky Tests 的客观存在是必要的,“如果你还没有遇到 Flaky Tests,那是因为你的自动化测试还没有做得足够好”。
从代码角度重视 Flaky Tests。不管是由于产品代码 bug,还是测试代码 bug 导致的 Flaky Tests,我们都需要从产品代码角度排查 Flaky Tests。因为漏掉一个真实产品 bug 的后果,远比误查一个测试代码 bug 的后果要严重得多。
flaky test is a war that never ends. 我们要打的是持久战。
