
快船 蚂蚁质量 AnTest | 作者
随着支付宝小程序和 H5 应用的生态开放,很多前端层面的业务自定义弹层不满意监管合规要求的现象日益突出。本文提出一种基于运行时的动态检测算法来解决此类前端弹层的识别问题。
检测范围:支付宝所有小程序或 H5 应用在 Render 层 Webview 出现的前端业务弹层。
目前前端领域有部分前端弹层的检测方案。主要可分为两个方向:
对这两种算法进行调研分析,对两者算法之间的优缺点进行了比对分析,如下表所示:
| 检测算法 | 方案原理 | 优点 | 缺点 |
|---|---|---|---|
| 基于图像算法识别 | 基于图像算法理论对像素点或者图像特征进行分析,通过阈值、ocr 或者深度学习方式判断弹层区域 | 1.对特定场景下的弹层识别能力较强,比如背景对比度差异很大、样式高度相同的弹层。 2.可以对弹层进行二级检测,进一步分析弹层内部结构,比如分析弹层是否有关闭标签等能力。 | 1.适合静态图像检测,欠缺动态检测能力。 2.前端弹层样式丰富,无法单凭一种图像算法识别不同种类的弹层。 3.图像识别复杂度较高,不利于实时检测。 |
| 基于 Dom 树的弹层检测 | 探测前端 Dom 树的实时变化,根据 Dom 样式、位置、以及内部结构判断弹层区域 | 1.可探测 Dom 树的实时变化,可做到动态检测弹层能力。 2.根据 Dom 的前端样式对弹层进行预测,检测覆盖面较广,普适性较强。 3.相比图像分析,算法开发难度较低,无需 GPU 运算能力。 | 1.缺少图像内容识别能力,比如无法进行 ocr、图片特征识别。 2.某些无法通过前端样式识别的弹窗很难检测出。 |
综上分析,基于前端 Dom 结构的检测相比于图像算法有以下两大优势:
通过实际调研发现目前端领域的弹层检测方案主要是基于 Puppeteer(无头浏览器)检测方案,可理解为模拟器环境启动一个 Chrome 浏览器进行检测。基于真机运行时的弹层检测方案目前较为零散,没有一套相对成熟的算法机制。
因此本文旨在从算法层面出发,实现一套在任何浏览器环境下都可以运行和检测的前端弹层识别算法,在小程序或者 H5 动态运行时自动进行检测,捕捉支付宝生态开放后业务方实现的前端弹层。
要检测弹层,自然首先要定义弹层,弹层一般有以下特性:
1)监听 Mutation Observer 获得 Dom 变更记录,为什么只取出第一层的 Records?
弹层跳出时机有两种:
因此只需遍历 Records 第一层就可以把可能出现的第一类弹层全部检测出来;而第二类弹层需要遍历 Records 所有元素才可捕捉到,而页面渲染包含大量渲染帧,如果将每次渲染帧的所有元素都遍历一遍,那么会导致算法复杂度很高不利于运行时的实时检测,因此第二类弹层检测采用如下算法进行检测
2)第二类弹层筛选算法
上述算法已将可能的第一类弹层全部挑出,在此基础上我们通过视觉坐标定位的方式尽可能的收集出第二类弹层元素。首先可以明确的一点是业务写的前端弹层基本在以下 6 种形式呈现在页面中:
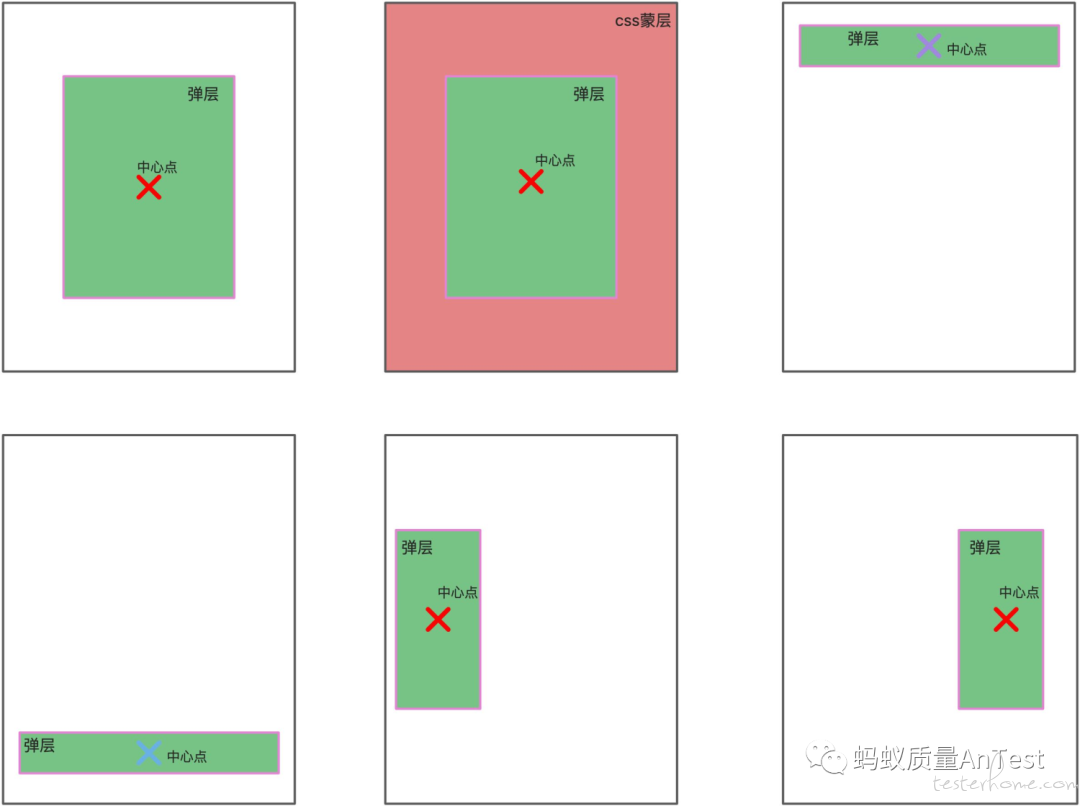
通过观察发现我们只需要对页面特定区域进行检测即可找出可能存在的第二类弹层。因此方案设计如下:
遍历第一类候选弹层的所有 element,对每个 element 进行如下操作:
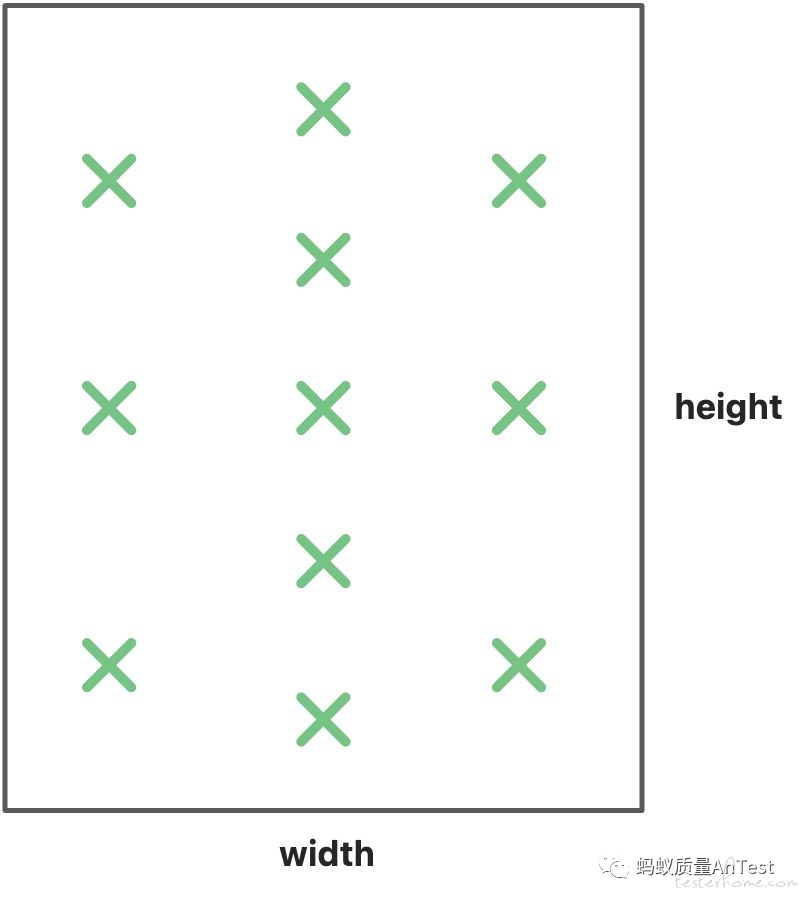
页面初始渲染时,在第一次 Dom 变更记录中 Records 的最外层必定存在一个覆盖整个视口面积的 div 元素,因此这个元素一定存在于第一类弹层的检测结果中。这也自然将手机屏幕中的这些特定位置坐标点加到了我们筛选出的特定坐标中,保证了之前提到的 6 种弹层能全部检测到。为了更全面的搜索其他未知区域的弹层,我们也将其他第一类候选弹层的特征点加入进来,进一步扩大弹层搜索的区域范围。相比遍历每帧的所有元素,此算法只需遍历个位数级别的元素,大大降低算法复杂度且搜索精度极高,适合运行时的动态检测。
3)如何确认弹层候选元素
经过上述算法已将两类弹层候选节点筛选出来,接下来经过以下三个步骤最终确认弹层候选元素。
流程可分为三步:
3.当出现用户交互(用户事件、页面隐藏、页面销毁)或者页面 Dom 稳定 15 秒不发生任何变化时停止检测,开始对弹层的视觉可视化进行检测,包括以下几项:
如果 Candidate 内部含的内容节点数量和面积均为 0,证明该弹层无实际意义的可视内容,直接剔除
如果 Candidate 底下覆盖的内容节点数量和面积均为 0,证明该弹层底下没有覆盖任何内容,从弹层角度上来说没有任何覆盖效果,直接剔除
通过 getComputedStyle 判断 Candidate opacity、visibility、display 属性是否为不可见,直接剔除
如果 Candidate 元素的宽高刚好等于屏幕视口的宽高,证明此弹层大概率是蒙层弹层,此时计算弹层底下覆盖内容面积/弹层元素自身总面积,如果占比低于 10% 我们也直接剔除
到此为止,整个前端弹层的检测流程结束,剩余的 “幸存” 节点作为前端弹层的检测结果上报给后台。
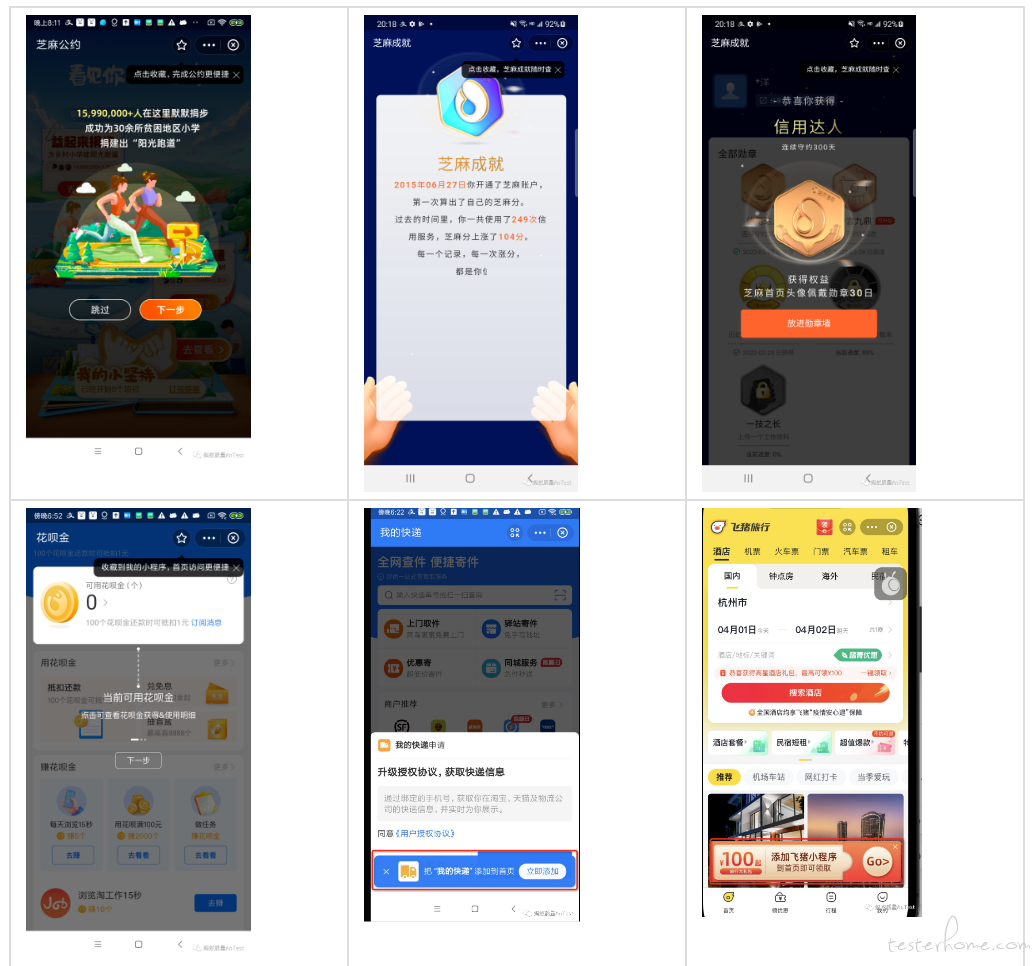
特殊场景的检测准确性
