1、响应时间(resonse time):
你得定义一个系统的响应时间 latency,建议是 TP95 或以上。响应时间具体要求多少,一般读不超过 200ms,写不超过 500ms。要是实在不知道,对标同行业竞品。(2、5、8 基本原则)
最小响应时间(min rt)
最大响应时间(max rt)
平均响应时间(avg rt)
2、成功率/失败率(Error):
在关注 QPS 和响应时间的同时,还要关注成功率。如果 QPS 和响应时间都满足性能要求时,请求成功率只有 50%,用户也是不会接受的。
成功率=成功请求数 / 请求数总和
失败率=失败请求书 / 请求数总和
3、吞吐量:
TPS(每秒事务请求数)或 QPS(每秒请求量),在目标响应时间要求下,系统可支撑的最高吞吐量。
吞吐率=吞吐量 / 传输时间
QPS=请求数 / 请求时间
TPS=事务数 / 请求时间
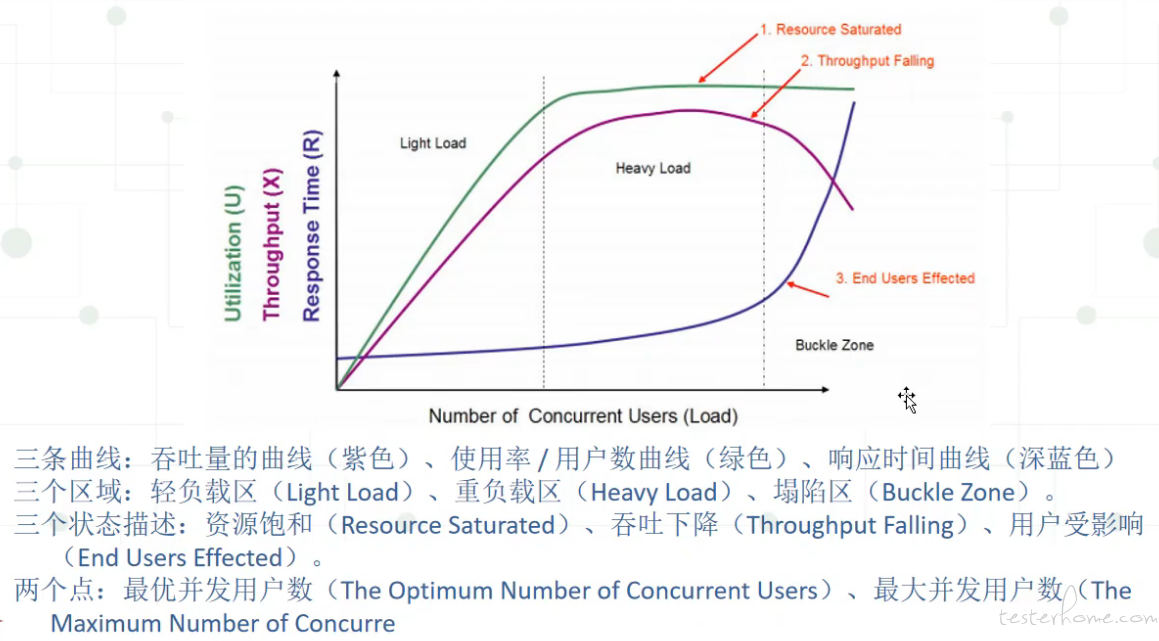
4、性能拐点:
一般服务都有性能临界点。当超过临界点时,吞吐量非线性下降,响应时间指数级增加,成功率降低。
4.1 找到出现性能拐点的主要原因:
基于性能拐点主要原因设置高危性能报警线。此为高风险注意事项,因为一旦达到性能拐点,有可能会出现雪崩现象,造成极其严重的事故。
观察超过性能拐点后,系统是否会出现假死、崩溃等高风险事件。
5、系统稳定性:
保持最高吞吐量(目标响应时间下的最高吞吐量),持续运行 7*24 小时。然后收集 CPU,内存,硬盘/网络 IO,等指标,查看系统是否稳定,比如,CPU 是平稳的,内存使用也是平稳的。那么,这个值就是系统的性能。
6、极限吞吐量:
阶梯式增加并发压力,找到系统的极限值。比如:在成功率 100% 的情况下(不考虑响应时间的长短),系统能坚持 10 分钟的吞吐量。
7、系统健壮性:
做 Burst Test。用第二步得到的吞吐量执行 5 分钟,然后在第四步得到的极限值执行 1 分钟,再回到第二步的吞吐量执行 5 钟,再到第四步的权限值执行 1 分钟,如此往复个一段时间,比如 2 天。收集系统数据:CPU、内存、硬盘/网络 IO 等,观察他们的曲线,以及相应的响应时间,确保系统是稳定的。
8、低吞吐量和网络小包的测试:
有时候,在低吞吐量的时候,可能会导致 latency 上升,比如 TCP_NODELAY 的参数没有开启会导致 latency 上升(详见 TCP 的那些事),而网络小包会导致带宽用不满也会导致性能上不去,所以,性能测试还需要根据实际情况有选择的测试一下这两咱场景。
4、硬件资源利用率:cpu、内存、磁盘 io、网络 io
5、并发数:并发数、并发用户数、虚拟用户数
6、并发数、响应时间、吞吐量(tps)的关系:
tps=并发数 / 平均响应时间
监控指标:
1、操作系统:
cpu 繁忙率、内存使用率、网络流入流出率、磁盘 IO 繁忙率
2、应用:
线程数、JVM 参数、GC 频率大小、锁(乐观锁、悲观锁等)
3、中间件:
Tomacat 连接数、MQ 队列大小、kafka 队列大小、redis 队列大小
4、数据库:
数据库连接数、SQL 执行效率
