最近在做性能测试的经常是好几个场景需要压测,而且每次监控的服务器都有好几台,所以在编写性能测试报告的时候经常统计得头晕眼花的,于是我就想着要怎么去自动生成相应的统计数据。使用 nmon 工具还好说,官方自己有工具去生成统计好的文件,我们可以通过代码自己去读取文件来统计即可,但由于压测使用的工具 loadrunner(以下简称 lr),其生成的报告没法直接导出数据,要么就是一个图表一个图表的导,这样更为麻烦。
为了解决这个问题,我花了很长的时间去网上查找资料,但因为这个工具在国内的资料太少,即使国外的网站也很难得到相关的内容,所以查来查去也没得到什么收获。于是乎,我开始自己去找到相关的数据文件。还别说,这还真让我找到相关的数据文件,其是一个 Access 数据库文件,而且还是一个不加密数据库文件(还算有点良心···),可通过相应的读取工具,即可读取其中的内容。
下面我将说明下该文件的读取,需要声明的是,读取文件仅仅只是我的一种思路,如各位大神有更好的方法,还请勿喷。
首先我们需要进入 lr 导出的测试报告文件夹中,例如,我导出了一个叫 “基准测试” 的 lr 性能测试报告,打开报告文件夹,我们就可以找到以文件夹名称命名的 “.mdb” 文件
通过网上查找该后缀的资料便可知道,这是 Access 数据库的数据文件,我们可通过相应的数据库工具将其打开,这里我使用 DBeaver 工具。打开数据库后,我们翻看表结构,可以看出,其数据库是由一些以固定英文命名的表还有一些以 “T” 开头和结尾,中间为随机数字的表,不过不用担心,因为你猜得没错,我们要的数据就在这些随机数字命名的表中_^
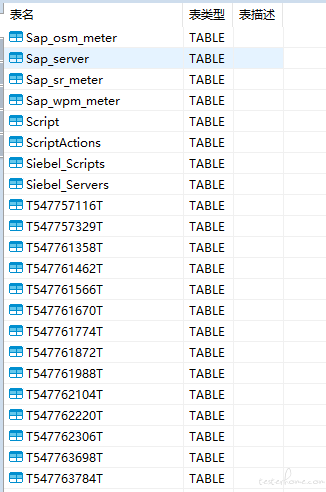
这个库里面固定命名的表我都翻了个遍,除了压测时间可能会用到外,可能真的就没什么有用的信息了···估计这也是 lr 官方想做封闭报告的一种手段吧,起初我以为报告里面的某些文件记录相关的表读取的配置文件,但直到我翻遍的所有的文件以后,我才发现,是我想多了···无奈,还是得从表下手(也可能就是我找不到)。
当然,我既然敢写,自然是有读取的方法的。首先根据数字去推断表中的内容,我个人认为不太现实,反正我是没找到其中的规律,由于缺少资料和实验对象(关键是我也懒得将所有的报告一个个翻出来,对比生成的表顺序是不是固定的),所以只能从表中的内容下手。以获取时间为例,通过翻看每一个表,我找到了目标表
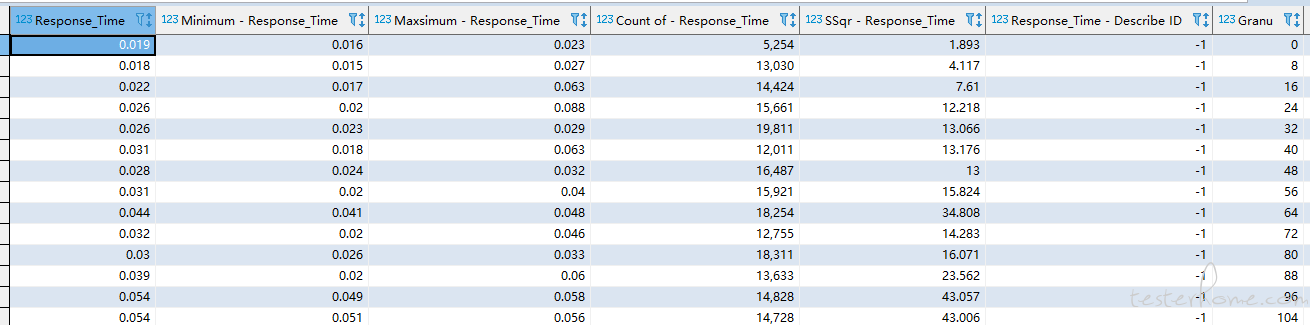
我也将该表与其他的表进行了对比,发现该表的特征还是比较明显的,只要包含 “Response_Time” 字段的,就可以确定该表存放的数据是响应时间数据了。
有了这个前提条件,那么读取就方便了,即使我不知道表是怎么命名的,但只要我认准了 “Response_Time” 字段,那么该表就是响应时间表。下面,就可以到最后的写代码分析的环节了。
⚠️需要注意一点,在数据库中,同样数据的表可能不止一张,例如响应时间的表,我在翻看所有表的时候就发现三、四张,数据都是一样的,所以我们只要读取到其中一张表即可
这里我使用的 java 语言,其他语言请自行查找对应的读取方式。由于需要读取的是 Access 数据,故需要在 pom 文件中添加如下依赖:
<dependency>
<groupId>net.sf.ucanaccess</groupId>
<artifactId>ucanaccess</artifactId>
<version>5.0.1</version>
</dependency>
有了读取工具后,我们便可以编写相应 JDBC 代码了,当然,这里我使用的是我自己编写的 “autest” 工具,有需要的也可导入下面依赖:
<dependency>
<groupId>com.gitee.pyqone</groupId>
<artifactId>autest</artifactId>
<version>3.6.0</version>
</dependency>
工具一直在更新,欢迎大家来使用,也欢迎各位有兴趣的小伙伴一起来探讨~咳咳咳,扯远了,我为了简化代码,所以就使用了自己写的工具,使用 JDBC 原装的代码,同样是能实现相同的效果。
同样以响应时间表举例,根据在第一节中我们的思路,只要包含 “Response_Time” 字段的,我们就可以认为是响应时间表,那么我们首先要做的,就是获取库中的所有以 “T” 开头和结尾的表:
// 连接数据库,假设数据库在“D:\\基准测试\\基准测试.mdb”下
SqlAction sql = new SqlAction(DataBaseType.ACCESS, "", "", "D:\\基准测试\\基准测试.mdb", "");
// 获取数据库中的所有表,并筛选出正则为“T.+T”的表,即以T开头和结尾的表
List<String> tableNameList = sql.getAllTableName().stream().filter(name -> name.matches("T.+T"))
.collect(Collectors.toList());
获取到所有的表后,我们再对表进行一次筛选,找到包含 “Response_Time” 字段的目标表
String responseTimeTableName= "";
// 遍历表名集合
for (String tableName : tableNameList) {
// 获取当前表中的所有字段
List<String> fieldNameList = sql.getTableAllFieldName(tableName);
// 若字段集合包含“Response_Time”则结束遍历
if (fieldNameList.contains("Response_Time")) {
responseTimeTableName = tableName;
break;
}
}
通过以上代码,我们便得到响应时间的表名,之后我们在通过 “select Response_Time from 表名”,执行该段 sql 语句,便可得到相应的响应时间数据了
String sqlText = "select %s from %s";
List<Double> reponseTimeList = sql.run(String.format(sqlText, "Response_Time", responseTimeTableName))
.getAllResult().getFirstColumn().stream().map(Optional::get).map(Double::valueOf)
.collect(Collectors.toList());
在得到数据集合后,我们便可通过代码自己算出最大、最小与平均值,并自行生成相应的文件,这样便可达到让电脑帮我们读取和分析数据的效果。
以上便是我对获取 lr 数据的一些思路,可能我的方法不是完美的,但这个方法至少可行。我主要也是想告诉大家 lr 生成的报告数据并非封闭的,我们是可以自己去读取的,无论方法的好坏,只要能达到自己想要的结果即可,至少这样我们可以批量处理测试报告,而不是自己一个个打开,这样不仅效率低,还容易出错。
