6 月 10 日,MeterSphere 一站式开源持续测试平台发布 v1.20.6 LTS 版本。
从2020年2月2日MeterSphere 开源项目在 GitHub 代码托管平台创建至今,我们累计收到了来自社区用户提交的超过 5000 条 Issues,其中 60% 的 Issues 与接口测试模块相关。作为一款开源持续测试平台,MeterSphere 是如何去覆盖这些业务形态各异的接口测试需求的呢?
今天,我们将以 “接口自动化多元化执行” 的场景作为切入点,为大家深度解析 MeterSphere 接口自动化的实现原理。
用户执行接口测试的行为建模
用户执行接口测试的行为建模一直是接口测试模块的关键设计之一。如何针对不同测试场景推荐给用户最优的执行方案呢?
用户执行接口测试的行为可以简单分为以下四个阶段:
■ 编写用例/场景调试阶段
■ 小规模批量执行阶段
■ 大批量回归阶段
■ 定时跑批阶段
针对用户不同测试阶段的需求,系统能够推荐给用户相应的执行策略,以满足用户各种形态的业务场景。
MeterSphere 平台可提供的四种执行策略
基于 MeterSphere 平台的执行特点,我们设计了不同的执行策略来满足多元化任务执行方案,目标是在满足业务需求的同时保障平台的稳定运行。
■ 策略一
增加系统级并发数控制功能,由用户根据自身业务和服务器性能来决定并发数,可自由伸缩控制。
■ 策略二
分为不同的执行模式:
① 并行模式将执行任务分离成不同执行单元(用例/场景),采用 Master-Worker 的模式去执行,Master(MS-Server)服务负责接受和分配任务,Worker(Node-Controller)服务负责处理执行单元;
② 串行模式采用流程式设计,每次执行从执行流程中有序取出一个执行单元加入到执行队列中。
■ 策略三
采用加权轮询算法来计算分配执行节点任务,每次执行前计算不同执行机的权重,合理利用每个执行机资源。
■ 策略四
执行机支持分布式部署/Kubernetes 集群管理,用户可以根据执行资源进行动态伸缩。
执行模型结构
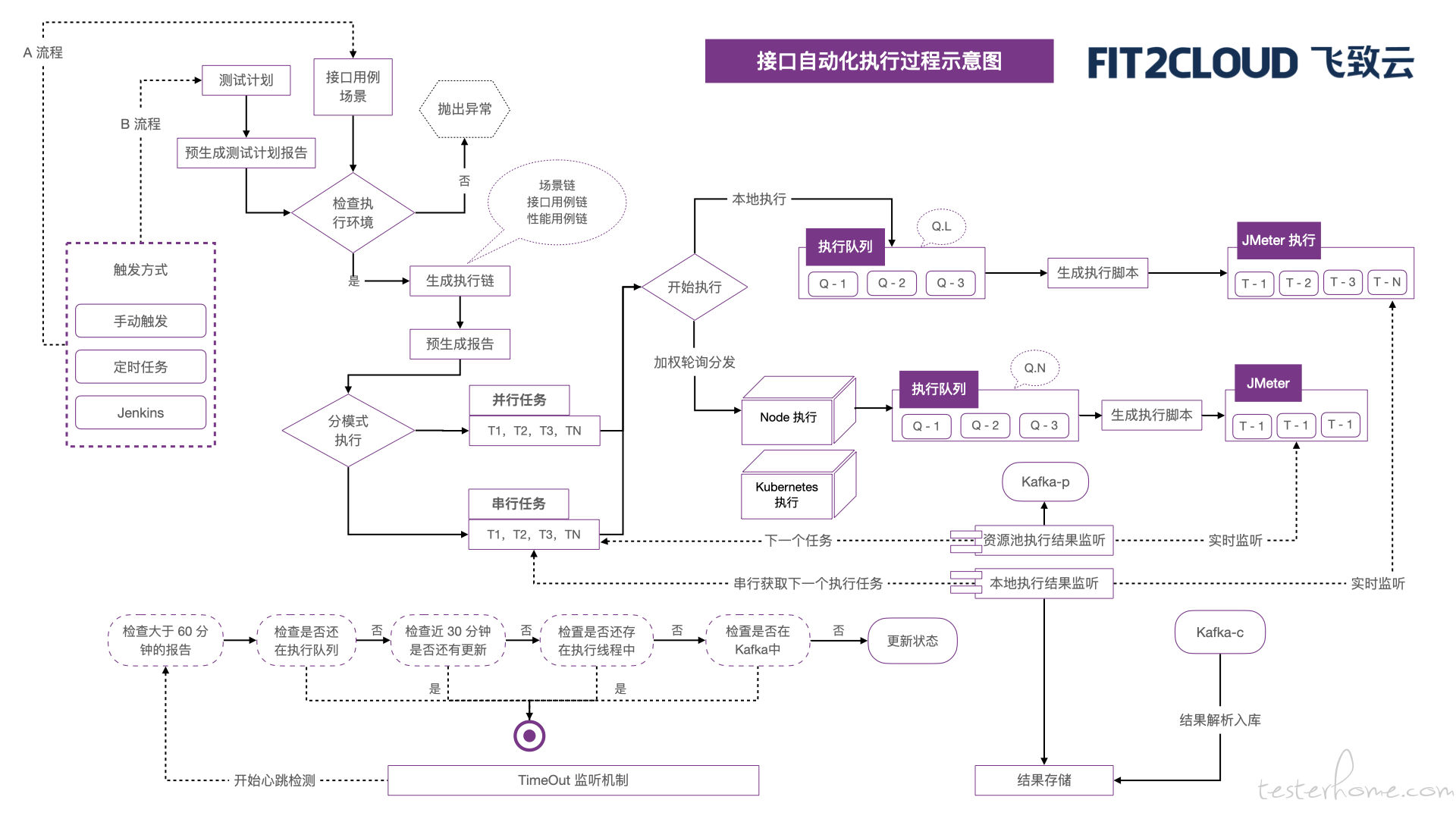
接口自动化的执行过程可以通过 2 条业务主线去看:
■ 测试计划执行
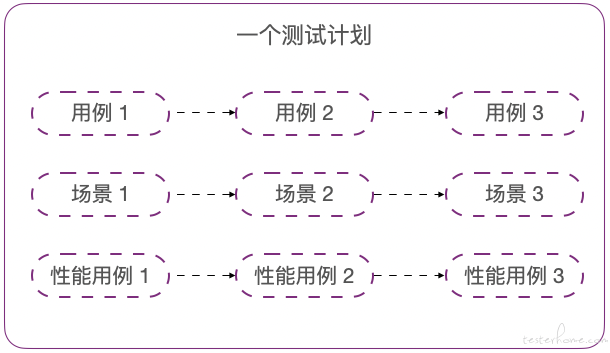
一个测试计划的执行包含用例/场景/性能用例,每个类型的测试资源都会生成一条执行流程链。这条链会存储到数据库,并伴随整个执行周期;如果是串行则每次按照流程获取一个点加入到执行队列,并行则所有点同时加入到执行队列。
■ 接口/用例/场景执行
单一元素触发执行过程和测试计划类似,唯一不同是测试计划会生成一个整体的计划报告,而用例/场景则是生成当前选择资源的独立报告/集合报告。
多元化部署方案配合执行模式
具体部署方式分为以下 3 种:
■ 精简部署

以最简单、最小的硬件资源就可以启动 MeterSphere 平台开启你的测试之旅了。
■ 默认常规部署
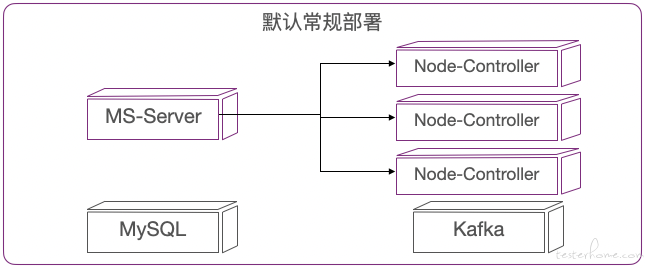
这种是我们在线安装和离线包安装中默认支持的一种部署模式,可以支撑大多数的测试业务场景,一键部署非常简单方便。
■ 分布式部署
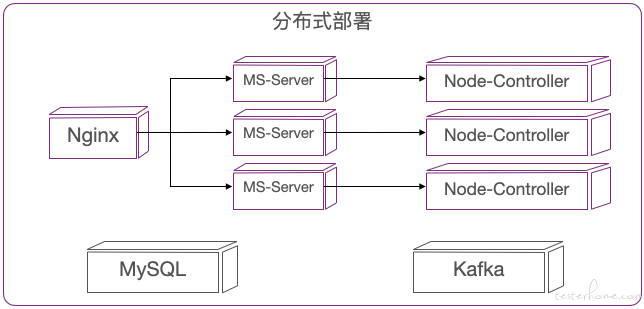
对于有复杂业务场景和执行要求的用户可以采用这种部署方式,安全可靠,支持大规模回归测试或跑批业务,可以动态伸缩扩展。
基于大规模执行行为建模
在执行阶段部分提到,不同测试阶段选用不同的执行方式来满足业务需求,像大规模跑批具有周期长、执行量大、高频次等特点。但是对于执行实时性要求并不是特别高,有比较宽裕的时间处理执行数据。
我们首先想到的是,应对这种业务特点使用什么部署方案才能支撑起我们的业务执行量?其次,是需要投入多少硬件资源,怎么做到合理使用在不浪费的前提下还能稳健地支撑起业务目标?
■ 性能方面
第一个前提是保障我们在大批量跑批过程中其他业务功能不会受到影响,其次在指定时间内覆盖到相关业务。
■ 效果方面
数据分析显示,在不同任务量下适量增减执行机可以有效的达到预期效果,这也在侧面说明了合理的部署加上一个有效的使用方法既能节俭资源又能保障执行效率。
■ 实验分析
在前期行为建模中我们也分别尝试了以下方案:
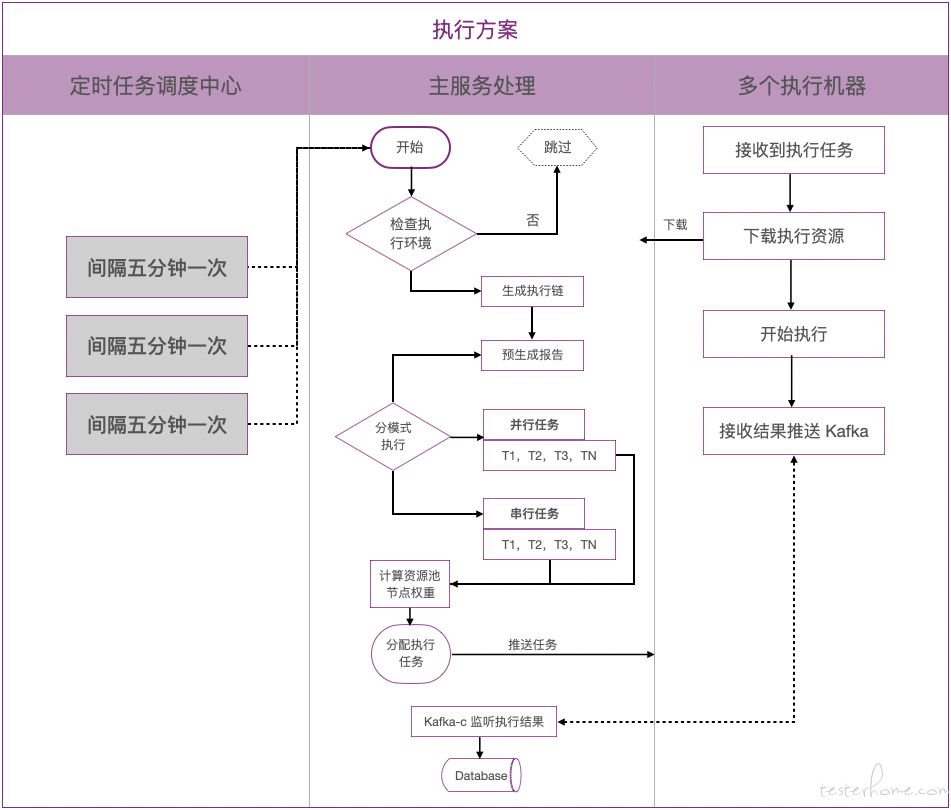
此方案没有部署限制,可以满足以上提及的三种部署方式,其次我们的任务调度也可以调整到夜间执行,真正做到无人值守下的全自动化执行。
线上效果
■ 效率指标
我们持续跟踪了线上应用实验结果如下:

从一个简单测试实验可以看出,不同执行策略下应该怎么去选择策略应对也是至关重要的。
■ 多样性指标
除了效率指标外,我们观察发现,对于推荐的多样性指标也有所提升,用户可以自由选择自己所需的策略:

工程实现中的问题
■ 报告状态处理
执行报告状态处理一直是比较头痛的问题,执行过程中不可控因素较多,比如:
业务复杂的接口执行等待时间过长处于假死状态;
执行过程中测试引擎发生不可控异常;
网络波动造成消息丢失情况;
某接口/场景过大造成执行机 OOM(Out Of Memory);
执行过程中测试资源被删除等。
针对以上的这些问题,MeterSphere 在后期系统设计阶段又增加了超时机制,针对一些执行时间较长的任务,发送心跳检查确保执行任务还在正常进行中,对于异常的报告及时更新报告状态。
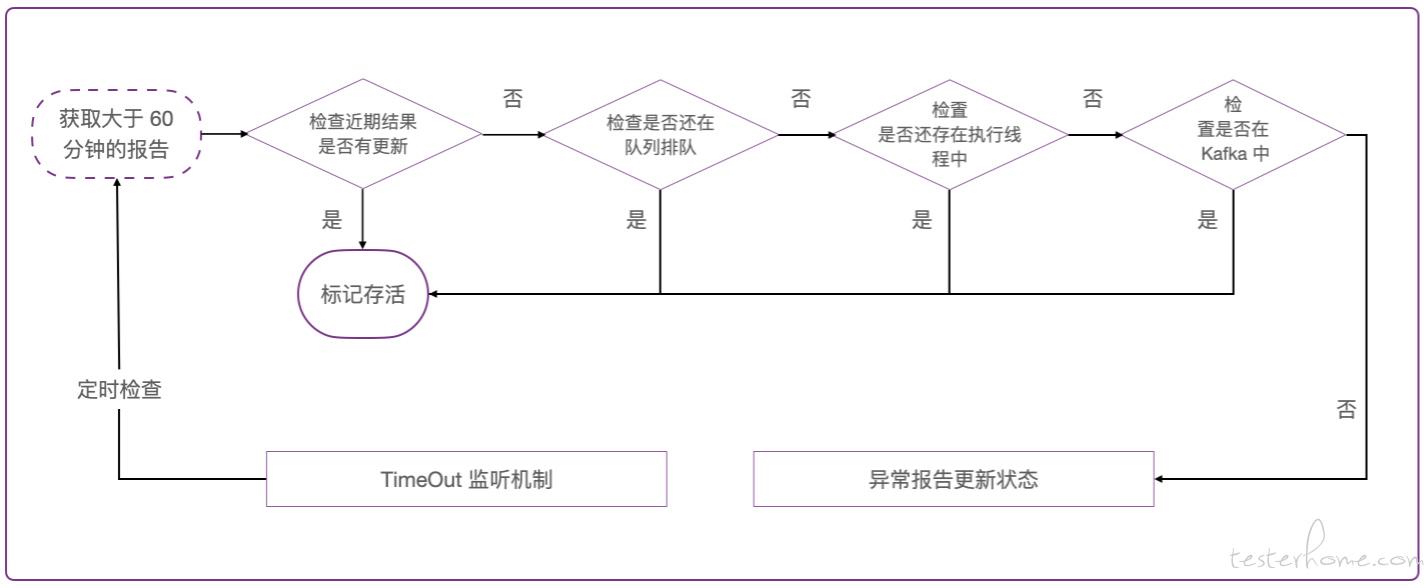
■ 执行机稳定性
在最开始的线下实验阶段,我们设置了并发处理机制,增加了全局队列来控制并发数;后续又优化了任务的分配机制确保每个执行机可以均摊任务,防止执行任务都阻塞在某个执行机上。
■ 失败报告通知
报执行失败后用户无法第一时间知道,因此 MeterSphere 平台后续增加了丰富的通知机制,用户可以选择不同的通知方式,在报告执行结束后平台会及时通知用户,以便及时做出调整策略。
总结与展望
用户执行接口测试的行为建模一直是 MeterSphere 平台设计中重要的优化点之一。目前,MeterSphere 平台在用户行为不明确、业务复杂多变、执行问题定位困难等场景中的表现有进一步完善的空间。在未来,MeterSphere 开源持续测试平台会持续优化系统稳定性,建立更透明的执行体系,以及更完善的排查文档。
