从去年开始,我就想着用 pytest 来做一个接口自动化测试工具。而在这之前我只写过零散的一些 py 脚本,甚至没正经用过一个 python 项目。
于是我先花了点时间先去看 pytest 教程,但是在了解了怎么发请求、参数化、做断言后,心里的疑问反而只多不少。
1. 整个项目架构、目录结构应该是怎样的?有无最佳实践?
2. 接口和用例应该要解耦吧,怎么分离,分离到什么程度呢?
3. 接口层和用例层的代码 是否要用 class 来组织,还是说只用函数就可以?
4. 做数据驱动用 json 还是 yaml,接口信息要不要和请求体放在一起? 响应断言要不要也放进来?
5. 哪些代码应该放在 conftest 里,哪些代码适合做成 util ?
6. 每次临时想测一个接口都要写好接口信息、用例断言、数据驱动太麻烦,应该怎么设计框架才能同时兼顾 2 种场景。确保我既能在 1 个地方快速测试接口,又能对所有接口进行统一调度并充分解耦。
对当时的我来说,这些问题我都不知道怎么解决。虽然很担心后期会频繁返工、重构,但如果不写下第 1 行代码,就什么都没有。
于是我在 Github 上找了个看起来还算完善的 pytest 接口自动化测试项目,看下源码,把公司的接口搬过来,照着写个用例试了下。中间虽然也经历了一些小波折,比如 pip 安装失败、virtualenv 用得磕磕绊绊、不知道 pycharm 可以把 unittest 改成 pytest 还在傻傻地用命令行来运行等等一系列很低级的问题,但一路百度谷歌,最终总算是能用 pytest 发起请求并且做了断言校验。
看着控制台输出的 ‘Hello world’,我意气风发、雄心勃勃。
俗话说:人生苦短,我用 Python。
写 python 代码整体上确实比写 java 要来的省心,代码量更少。而我也从这个项目里学到了很多东西,少走了很多弯路。
先简单说下原项目的组成架构:
api 层: 对应开发写的 api
config 层: 项目配置文件
core 层: 基类
data 层: 存放 yml 数据
operation 层: 介于 api 层和 testcases 层之间,负责数据处理组装
testcases 层: 对应测试写的测试用例
这种设计很常见,清晰易懂。
但是!
真的按照原项目的写法开始用起来后,发现写接口测试代码很费劲,这里列举其中 2 点。
原项目中要测 1 个接口,前期需要写很多代码。
1.首先在 data 层写好 yml 测试数据。
# data层的 user.yml
test_register_user:
# 用户名,密码,手机号,性别,联系地址,期望结果,期望返回码,期望返回信息
# username, password, telephone, sex, address, except_result, except_code, except_msg
- ["测试test", "123456", "13599999999", "1", "深圳市宝安区", True, 0, "注册成功"]
- ["测试test", "123456", "13599999999", "3", "深圳市宝安区", False, 2003, "输入的性别只能是 0(男) 或 1(女)"]
- ["wintest4", "123456", "13599999999", "1", "深圳市宝安区", False, 2002, "用户名已存在"]
2.然后要在 case 层写好 test_register_user 的测试方法,里面引用 operation 层的 register_user 方法
# case层test_02_register.py
def test_register_user(self, username, password, telephone, sex, address, except_result, except_code, except_msg):
result = register_user(username, password, telephone, sex, address)
assert result.response.status_code == 200
3.然后要在 operationc 层实现 register_user 方法,方法里调用 api 层的 register 方法
# operation层user.py
def register_user(username, password, telephone, sex="", address=""):
result = ResultBase()
res = user.register(json=json_data, headers=header)
result.msg = res.json()["msg"]
return result
4.最后在 api 层实现 register 方法
# api层user.py
class User(RestClient):
def register(self, **kwargs):
return self.post("/register", **kwargs)
user = User(api_root_url)
整个过程环环相扣,错一个地方,就得在几个文件中排查半天,最后你往往会念起隔壁 postman 的好:“明明 1 分钟就能搞定的事情 为什么我非要折腾上 10 分钟?”
当然,我们做接口自动化工具,并不排除这种分层设计,甚至还是必要的。
但我们也希望,这个工具能兼容多种场景。既能在大批量接口测试的时候,做到低耦合高内聚。也希望能在简单的单接口调试阶段,能尽可能快地测试单个接口用例。这个问题必须解决。
大部分接口都少不了请求参数,有的还多达 5、6 个甚至更多。
在原项目中,我们得在 case 层的方法签名里,把这些 username, password, telephone, sex, address,except_result, except_code, except_msg 重新复制粘贴一遍。
而方法体里面,这些 username, password, telephone, sex, address 也在嗷嗷待哺等着你传给 operation 层。
# test_02_register.py
@ pytest.mark.single
def test_register_user(self, username, password, telephone, sex, address, except_result, except_code, except_msg):
result = register_user(username, password, telephone, sex, address)
assert result.response.status_code == 200
最后来到 operation 层,还得在编写方法签名的时候把参数再写一遍。
我们来算一笔账,1 个 api 接口要传 5 个字段 a、b、c、d、e。
在 yml 文件里,起码要写 1 遍。
在 case 层,又要写 1-2 遍。
在 operation 层,又要写 1-2 遍。
在 api 层,这里的字段基本都用关键字参数 **kwargs 来整合所有字段,这里就忽略不计了。
整个流程下来,1 个字段要复制粘贴 3-5 遍。5 个字段就是 15-25 遍。
一顿操作猛如虎,最后你发现自己哪是个程序员,就是个审核员,天天在检查这些字段复制得对不对。接口跑不通,还得先打断点看下问题处在哪个模块里。
虽然说这样接口测试也不是不能做,但是对于一个测试工具来说,如果让测试人员觉得写代码验证接口太费劲,那是很影响使用体验的、也不利于后续推广落地。
不过没关系,别人已经替我们走出了第一步,接下来该我们出马了。
前面说到,我们在编写 1 条测试用例的时候,非常耗费精力,应该考虑修改下整个流程。
首先,case 层肯定少不了,这是我们测试的主战场,我们要在这里写测试用例代码。
其次,data 层提供了我们 数据驱动、参数化的能力,也是不可或缺的。
这里提一句,除了请求体 body 以外,个人不建议在 yml 里维护请求域名路径。理由很简单,yml 里面 3 个请求体数据代表不同 3 次不同的接口测试请求,但是却要在里面重复编写 3 次请求域名路径,没必要。这个请求域名和路径本来就应该放在 api 层去维护才更合理。至于要不要在 yml 里维护断言信息,这个就见仁见智,加了断言无非就是在重复运行或者参数化请求接口的时候可能得考虑接口幂等性、数据清理还原的问题。
然后,api 层也得保留,且必须要和 case 层分开。让开发的归开发,让测试的归测试。每个方法只维护 method、path、header 等信息,域名 host 因为很少改所以可以放到整个类的全局变量里。
同时,既然我们要维护这么多个 api,且这些 api 结构也都类似,那么自然也需要抽象 1 个 BaseRequest ,所有 api 都共用的能力可以放到这里来。 这个 base 层不光可以放 BaseRequest,像一些基本异常、基本响应也可以抽象出来放在这里。
最后,就是 operation 层了。原项目中,它只负责组装 json、header、cookie 等信息,然后供 api 层调用。那我们在 data 层把这些请求体参数组装好,供 case 层直接获取不就行了吗? 至于 header 和 cookie 完全可以放在 api 层处理。 这样一来就可以砍掉这一层了。
框架结构确定下来后,我们就可以着手解决之前的那些麻烦问题了。
先看问题 1。
前面我们已经通过修改架构,砍掉了 operation 层,现在 api 层里面 method、path、header、cookie 都齐了。
至于 body 请求体的数据既可以自己在 api 层代码里自己造,也可以用 data_util 工具类 直接从 yml 里解析出来给 api 层用。
而 api 层拿到这些数据后 调用 requests 库不就可以单独发起请求并获得响应了吗?
等等,我们要怎么才能在 pycharm 中单独执行这个方法呢?
其实也简单,在 api 层里面加上 对 __name__ 的判断。只要我们在 pycharm 里,点击左边的绿色箭头,就能单独执行了。
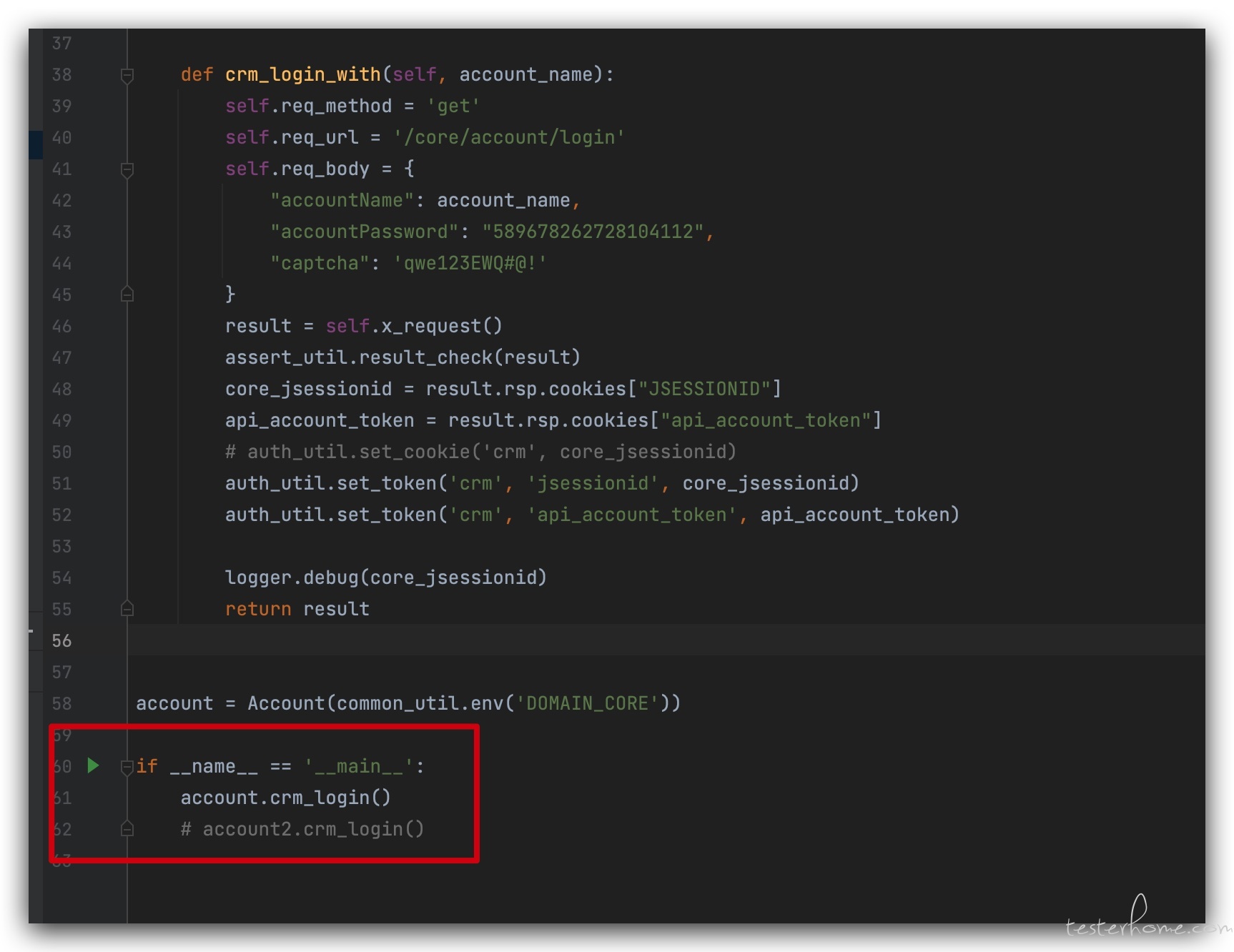
现在我们的代码变成了这样:
# api层的user.py
# 每个api层的类都要继承自 BaseRequest
class Account(BaseRequest):
# 这里编辑 api 接口请求信息
def crm_login(self, kwargs):
self.req_method = 'get'
self.req_url = '/core/account/login'
self.req_body = kwargs
# 调用父类封装好的方法,发起请求
result = self.x_request()
# 1个对象包含多个 api 接口
account = Account(common_util.env('DOMAIN'))
if __name__ == '__main__':
# kwargs = data_util.get_data('xxx.yml','user_1')[0]
kwargs = {
"accountName": "xxxxxx",
"accountPassword": "589674112"
}
res = account.crm_login(kwargs)
print(res)
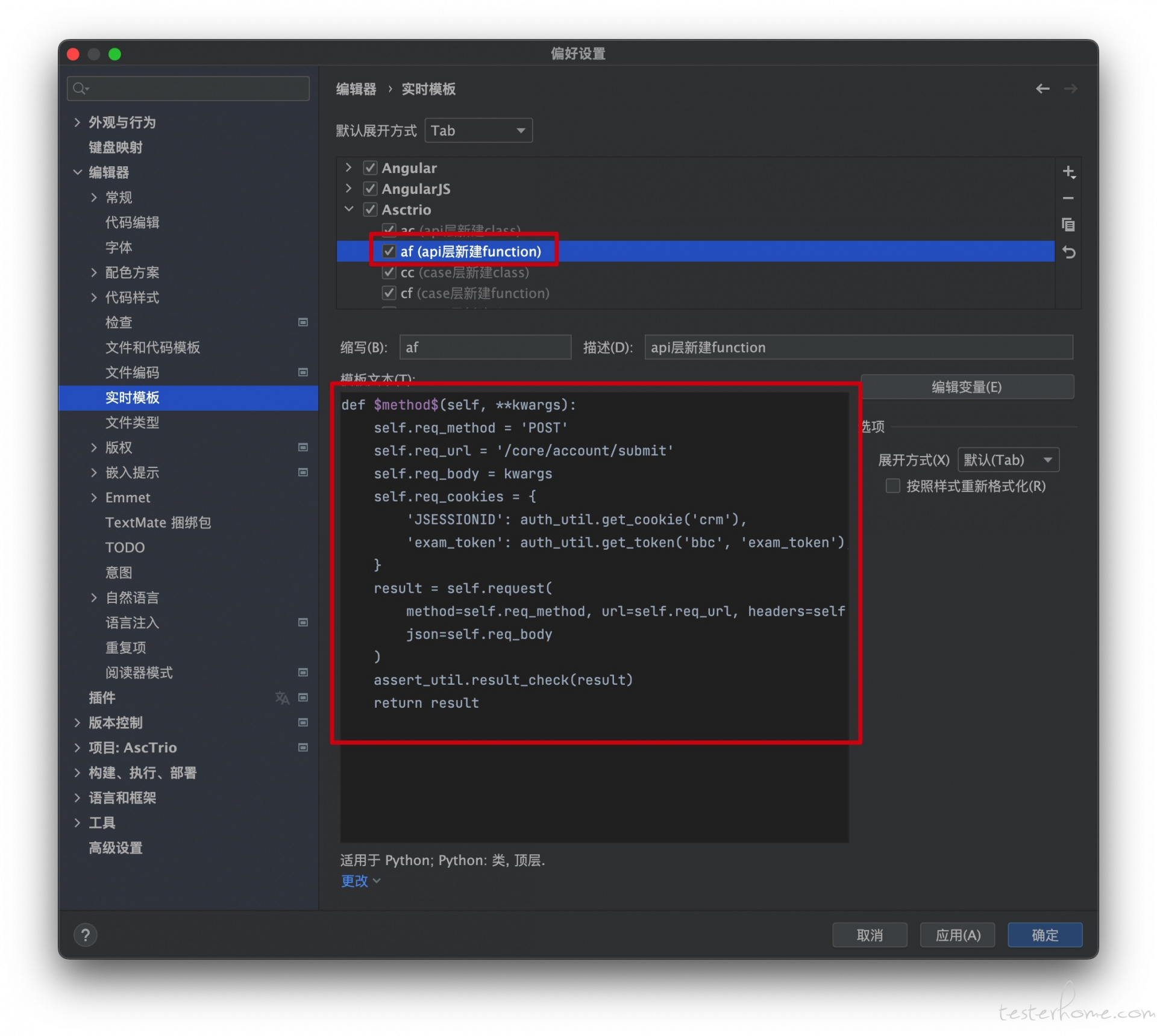
经过以上修改,我们如果临时想测试下某个接口,直接在 api 层就可以完成发起完整的请求,如果你觉得复制上面的代码还比较麻烦,也可以使用 pycharm 里面的 live template 功能,自己创建好函数模版,如下图
接下来是问题 2,既然 1 个字段 1 个字段传参太麻烦,我们干脆把整个请求体以字典 dict 的形式来传参。
case 层从 yml 中获取到的 请求体是 1 个完整的字典,如果想要对请求体做一些修改、mock、递增变量什么的,也可以自行修改字典里的值,然后以字典的形式 传递给 api 层。api 层拿着这个字典 传递给 requests 库的 data 或者 json 即可。
(当然,这样一来就限定死了每个接口调试前都得先在 yml 文件里组装好字典数据。如果想要让接口既能接受多个参数,又能接受字典,也有办法,那就是用到关键字参数 **kwargs。不过这样一来,就需要 case 层和 api 层都改成 **kwargs。个人感觉效率上没差多少,应该可以统一用 1 个字典来传参。)
经过以上修改,我们的代码现在变成这样,看着简洁了不少:
# cast层的test_blue_bridge_contest.py
# 在 case层 parametrize 只暴露1个 kwargs 字段。
@ pytest.mark.parametrize("kwargs", data_pool.supply('bbc_signup_data.yml', 'audit_success'))
def test_audit_fail(self, kwargs):
kwargs['matchId'] = '58'
res = bbc_signUp.audit(kwargs)
assert res.status is True
# api层的blue_bridge_contest_signup.py
class BBCSignUp(BaseRequest):
# 这里同样只有1个字段传参
def audit(self, kwargs):
...
(其实在 parametrize 参数化 的时候,每次都要给 supply() 提供 yml 文件名和 key 值也挺麻烦,灵活是灵活了,但是能不能智能一点呢?下一节会提供一个优化方法,这里先卖个关子)
到目前为止,我们分别从宏观架构和具体用例细节上对代码做了改进,整个项目框架至此也基本定型,是不是感觉 pytest 也没那么难,无非就是一些 python 基础再加上 parametrize、skip 和 fixture 啥的嘛。
别急,还没完。
由于项目组的小伙伴都各自用各自的工具来发请求(有的用 postman ,有的用 httprunner ,老大想让我们统一用 yapi),导致后面很长一段时间,我都只是在往这个项目里堆砌业务代码。
直到有次遇到了一个很棘手的 bug,我才意识到,pytest 中还有太多细节我不了解。
我们像往常一样,在 case 层 加了个方法 test_11 ,顺手点 pycharm 编辑区左侧的绿色按钮运行,结果却提示‘TypeError: 'NoneType' object is not iterable’,看报错和 parametrize 有关,但是检查了下,parametrize 语法没错,对应的 yml 文件也在,里面的数据 key 值也对得上,怎么就 NoneType 了?
@ pytest.mark.parametrize("kwargs", data_pool.supply('bbc.yml', 'submit11'))
def test_11():
...
# bbc.yml文件
submit_11:
- '111'
- '111'
然后我把代码回滚到上次正常运行的场景下,发现有问题的地方其实不在 test_11 函数对应的 yml 数据里,而是和 test_11 同一个类的 test_22 函数所对应的 yml 文件里。由于找不到 submit_22 这个 key,导致 pytest 的 parametrize 参数化在收集阶段获取的数据为 None,自然提示无法迭代。改好后就正常运行了。
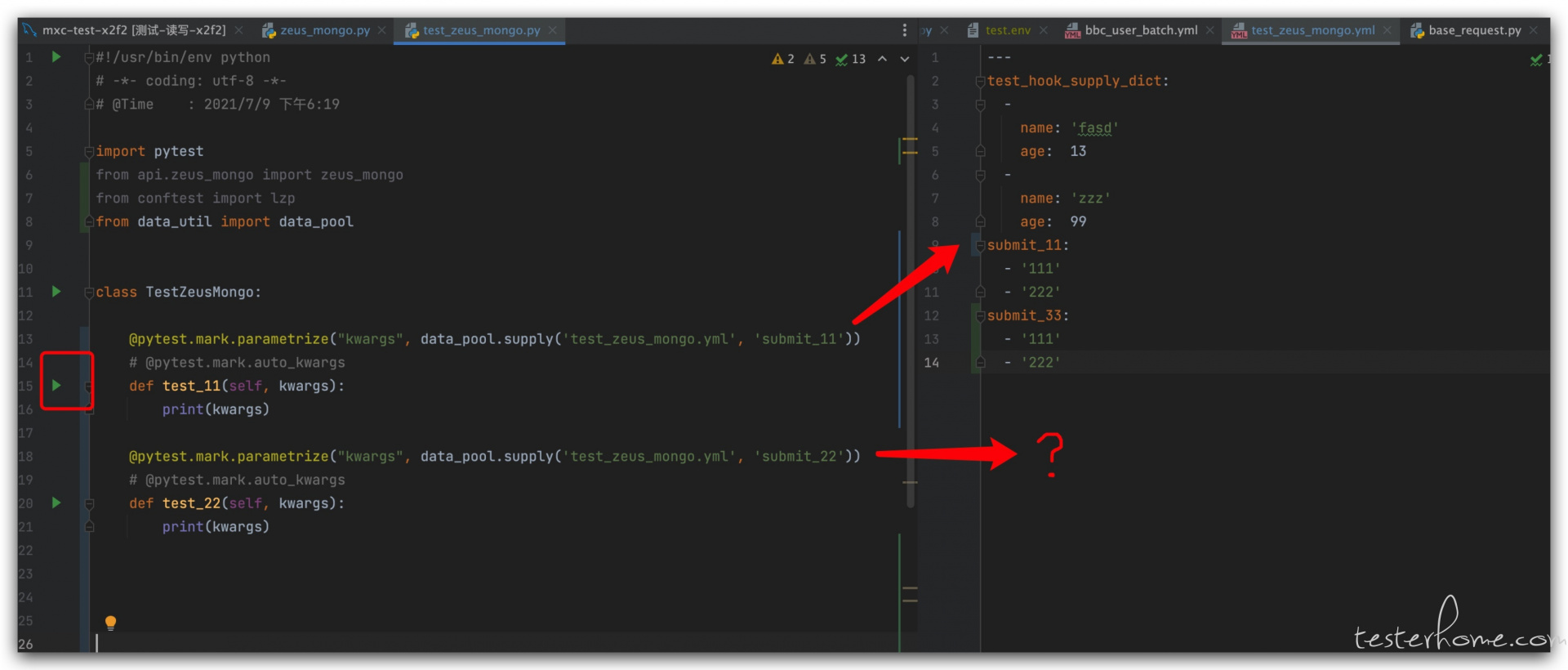
那么问题来了,我明明只想运行 test_11,pytest 为什么要跑去检查 test_22 的参数化情况呢?
实际上,pytest 在进行测试的整个过程中,会执行【插件注册】、【读取配置】、【收集用例】、【运行用例】、【取消配置】等多个步骤。
不管我们是点击绿色按钮去执行 test_11,还是给 test_22 加上 @pytest.skip 来绕过其他函数,这些操作都只作用于【运行用例】阶段,并不代表这时候 pytest 就完全不关心 其他符合条件的 测试用例了。
回到我们刚才说的 pytest.mark.parametrize ,对 python 来说它就是个装饰器。众所周知,装饰器里的代码在模块被导入的时候就会执行了。哪怕我不运行 test_22,装饰 test_22 方法的 parametrize 也一样会运行,也自然会执行 data_pool.supply('bbc.yml', 'submit22'),并将结果返回给 parametrize 的第 2 个入参,而一旦 parametrize 检测到 第 2 个入参里的值 是不可迭代的(这里就是 None),自然就报错了。
这个小 bug 也给我提了个醒,不能满足于简单用 pytest 写接口测试用例,我要多尝试下各种骚操作,还记得我们上一节卖的关子吗?
是时候填上这个坑了。
接下来的内容,会较多涉及到 pytest 中的 parametrize 参数化 和 fixture 夹具,以及 hook 钩子函数的内容,相关教程网上有很多,这里就不再介绍了。
让我们先回顾下之前的代码。
supply 方法要根据 yml 文件名和 key 值,获取一个字典/数组给 parametrize 做参数化。
但其实我们只关心内容,至于具体名字是啥,对我们来说并不重要。
# case层 test_zeus.py
@ pytest.mark.parametrize("kwargs", data_pool.supply('test_bbc_signup.yml', 'save_match'))
def test_save_match_enable(self, kwargs):
res = bbc_signUp.save_match_2(kwargs)
assert res.status is True
那我们完全可以先做好约定:
听起来略晕,看图就一目了然了。
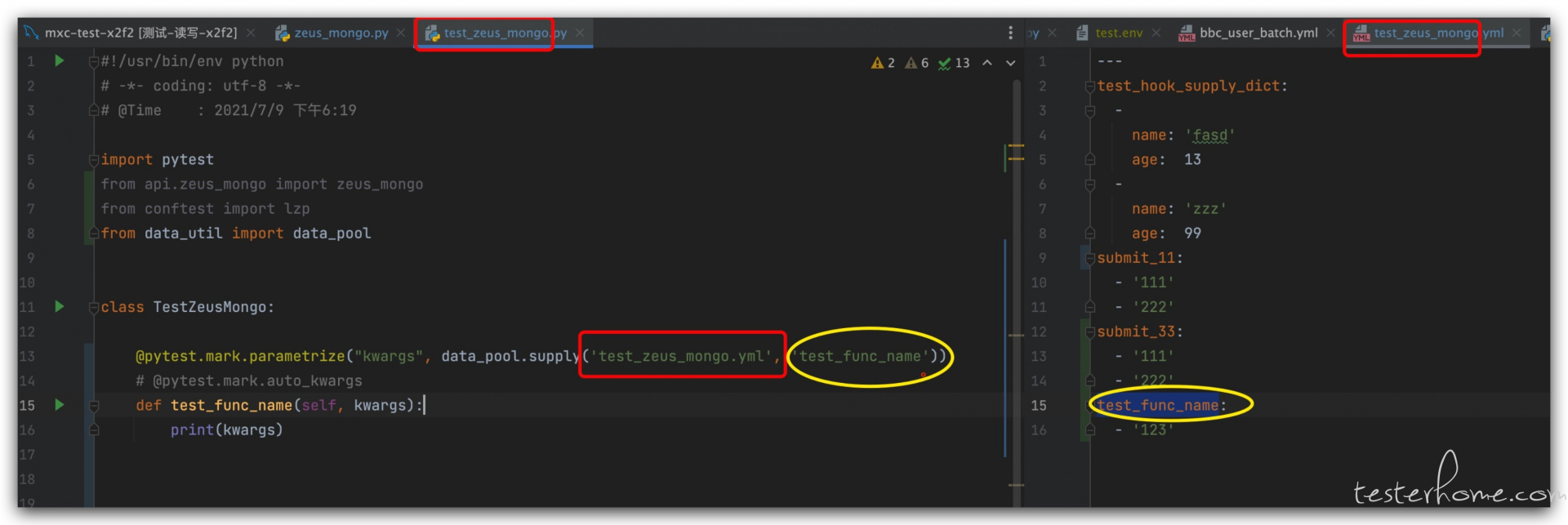
我们只要通过某种方法,让代码实现这个逻辑就可以了。但最折磨的地方,也就在这里。
一开始,我想到的是通过 test_save_match_enable.__name__ 这种内置属性获取到当前函数名,然后替换到原来的'save_match'。接着获取当前运行的模块,然后替换原来的'test_bbc_signup.yml'。
一运行,发现并没有输出 test_save_match_enable 实际输出的却是 wrapper ,原来 test_save_match_enable 函数已经被 parametrize 装饰器装饰过,所以函数的元数据比如名字、文档字符串、注解和参数签名都丢失了。要想保留原始的函数元数据,就得在这个装饰器内部给它加上一行 @wraps(func)。这是要我改 pytest 源码的节奏啊。
我自知以我目前的水平,还不足以对 pytest 源码下手,而且就算下手,影响范围也不可控。所以这个方案先放弃。
然后我上网查了下,还可以用 inspect 模块获取函数运行调用的帧栈信息。
简单试了下能获取到,但是你仔细想想,还是不靠谱的。
我们没办法知道别人在调用这个方法的时候中间嵌套了几层,索引下标无法固定,自然也就不知道当前被嵌套的 test_save_match_enable 函数当前在第几层里面。这个方案也放弃了。
靠 parametrize 走不通,我又把目光放在 usefixture 和 fixture 上,说不定他俩能提供啥帮助。
先是查阅 usefixture 的文档,发现 usefixtures 只能接受 fixture 名称作为入参, 不提供其他任何字段入参。
那除了直接当装饰器以外基本没别的用处,就算和 parametrize 组合使用,发挥空间也很有限。思考再三,果断放弃,转而考虑 fixture。
我之前只是将 fixture 用于测试前获取登录 token,这次我仔细查了 pytest 的官方文档,终于让我找到 request(注意不是发请求的 requests)这个 pytest 自带的 fixture。
相信不少对 pytest 比较熟悉的大佬都知道这个 fixture 的强大,借助它,我们可以轻松获得使用了该 fixture 的模块名、函数名等等。
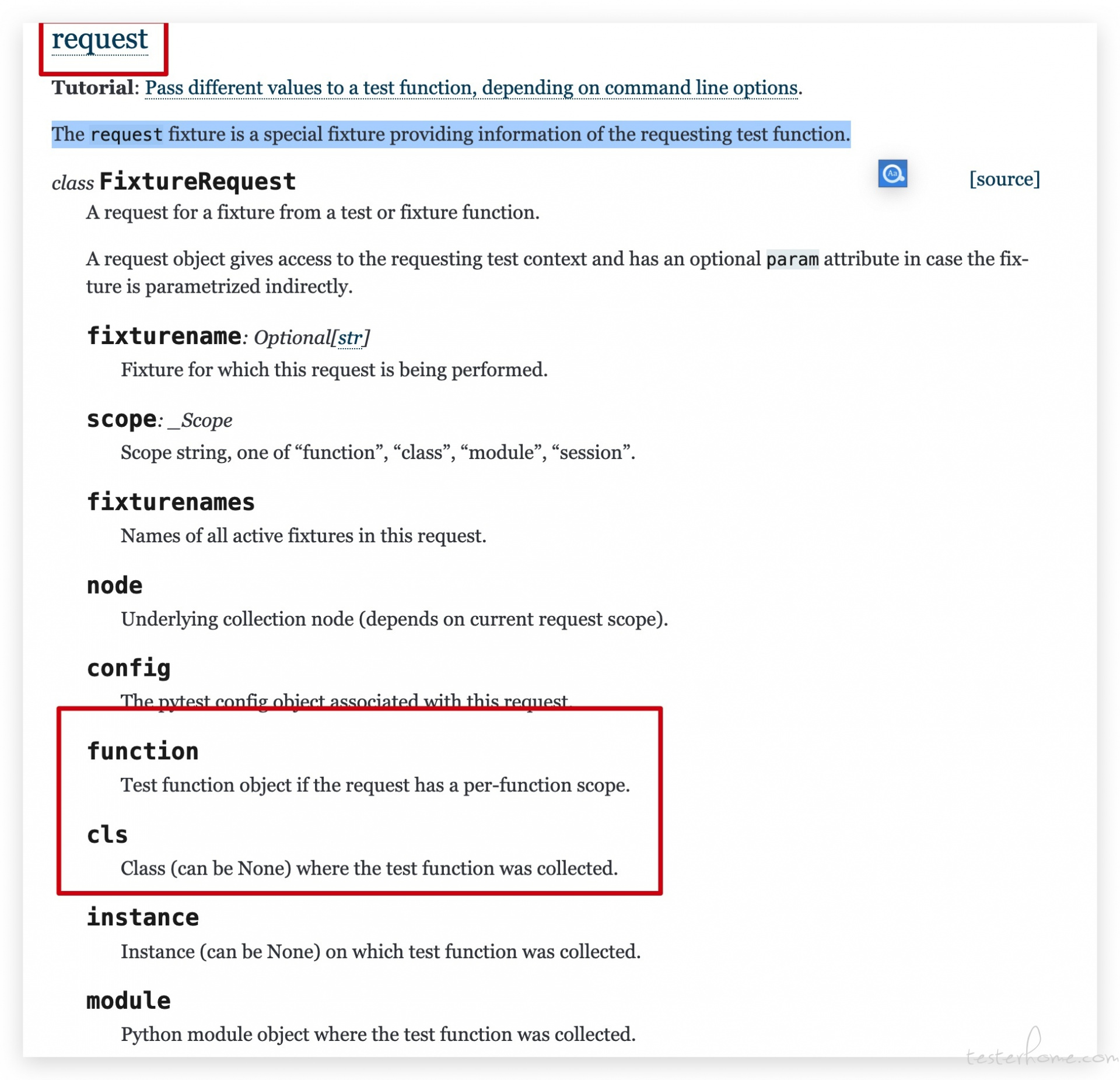
这不正是我们想要的功能吗?
于是我立刻在 conftest.py 中写了个 fixture
@ pytest.fixture(scope="function")
def zeus(request):
func_sign_1 = str(request.function).split(' ')
# 获取模块名
module_name = func_sign_1[4].split('.')[-2] + '.yml'
# 获取方法名
func_name = func_sign_1[2].split('.')[-1]
# 获取到对应的数组并返回
kwargs = data_pool.supply(module_name, func_name)
return kwargs
在 case 层代码中,我们直接使用这个 fixture 即可。正常来说 zeus 这个 fixture 会返回一个数组。然后 parametrize 会解析并根据数组长度依次赋值给 kwargs 进行参数化并执行测试。
# test_zeus.py
from conftest import zeus
@ pytest.mark.parametrize("kwargs", zeus)
def test_save_match_enable(self, kwargs):
print(kwargs)
好消息是,这个 fixture 在 parametrize 里顺利运行并拿到了 函数的所有相关信息。
坏消息是,pytest 又又又又在收集阶段,报错了
TypeError: 'function' object is not iterable
为什么不执行 fixture 啊?是我用法错了,还是 pytest 设计就是这样?
又是一番苦苦搜索,终于在 Stack Overflow 上找到一个类似的提问,恍然大悟。
原来在 pytest 收集阶段, 当 parametrize 识别到 fixture 时, 并不会执行该 fixture。只有在运行测试的时候它才会开始执行并返回对应的数组,而这时早已错过 parametrize 参数化的时机了。
所以在 kwargs 看来,我们只是把一个普通的函数传给了它。这才报了上面那个错。
悟是悟了,但是接下来怎么办呢?幸好,在这篇帖子最后,有位大佬给了我们一条线索,让我们用 pytest_generate_tests 这个 hook 函数。
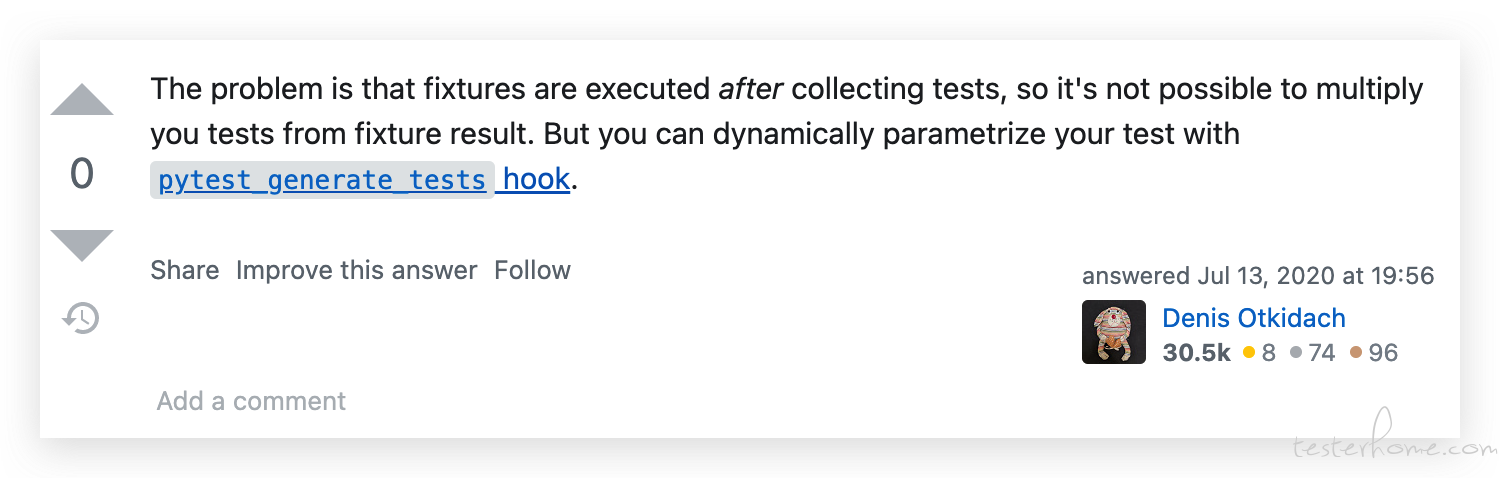
用了这么久 pytest,终于要接触传说中的 hook 钩子函数了,还有点小激动。先上代码,我们边看边聊。
# conftest.py
def pytest_generate_tests(metafunc: "Metafunc") -> None:
"""Generate (multiple) parametrized calls to a test function."""
# 获取到模块名、函数名
cur_module = f"{str(metafunc.cls).split('.')[-2]}.yml"
cur_func = str(metafunc.definition).split(' ')[1][:-1]
# _auto_supply会根据输入的yml名称和key值 返回对应的数据
harry = _auto_supply(cur_module, cur_func)
# 识别到指定 mark 标记后,手动进行参数化
param_name = 'auto_kwargs'
name_list = (make.name for make in metafunc.definition.own_markers)
if param_name in name_list and 'parametrize' not in name_list:
metafunc.parametrize(param_name, harry, scope="function")
首先我们在 conftest.py 中定义 1 个 pytest_generate_tests 函数,注意函数名字和签名都不能错。
pytest 在运行的时候会函数元数据都传给 metafunc 这个对象,我们通过它可以拿到 模块名、函数名等信息。
光是拿到函数信息还不够,要知道这个 hook 函数是帮我们生成测试用例的,也就是说会和 pytest.mark.parametrize() 冲突,所以我们还需要在里面自己手动进行参数化。
别担心,metafunc 也为我们提供了对应的方法进行处理。
接下来,我们只要给 test_save_match_enable 方法上面加上一个自定义的 mark 标记(这里用 auto_kwargs ),就能在 pytest 执行 pytest_generate_tests 这个钩子函数的时候,给这个方法进行参数化了。
# test层/test_zues.py
@ pytest.mark.auto_kwargs
def test_hook_supply_dict(self, auto_kwargs):
# 拿到 auto_kwargs 后就可以随意发挥了,然后传给 api 层
auto_kwargs['name'] = 'allen'
resp = user.add(auto_kwargs)
assert resp.status_code = 200
点击运行,完美通过!
经过前面几轮优化完善,我们这个工具已经能基本满足接口测试的编写和运行了。
编写接口测试代码也不再像之前那样劳心劳神,同时还能兼顾灵活性。
更重要的,随着我们对 pytest 功能、细节的了解逐渐深入,我们对 pytest 的使用也越来越得心应手。曾经看起来遥不可及的 hook 钩子函数,经过实践也变得亲切了很多。
然而,这还只是我们探索之旅的第一站,后面的路还很长。
有多长呢?
革命尚未成功,同志仍需努力!
欲知后事如何,请听下回分解。
