在一个遍历服务中,同时运行 5 个设备执行遍历任务时,快速出现如下错误
容器ExitCode :137, 原因:OOMKilled
该服务是通过 python 程序唤起执行 Java 任务
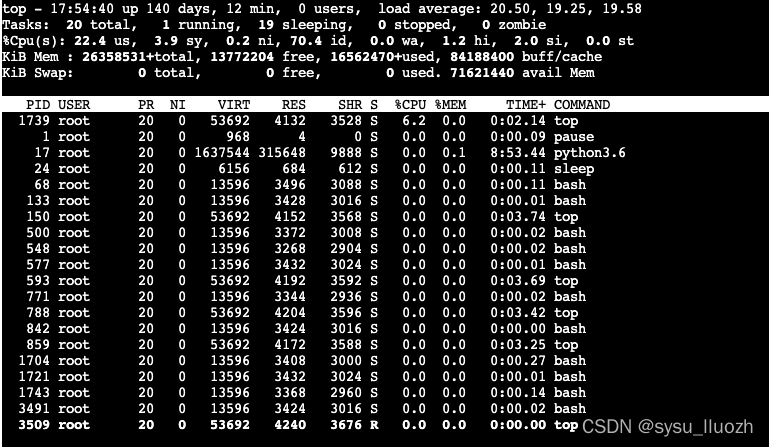
既然是 OOM,得确认资源占用情况
发现系统中总内存使用较低,且 python 和 Java 进程的内存使用不高,那为什么会出现 OOM 的情况呢?
注:其实这里查看的是整个服务器的内存占用,该服务器内容总共 25G,所以内存占用不高

容器的最大内存 500M
但是从这些信息中并未得到较高的内存占用
使用 memory_profiler 分析 python 的内存使用
from memory_profiler import profile
@profile
def compatibility_task(task_id):
# do compatibility job
python task.py
获取具体的执行信息
内存占用 200M 以内,应该问题不大 (这里其实有个大坑,导致后面折腾一通)
既然不是 python 的性能问题,那么接下来分析一下 java 的内存
使用命令获取 hprof 文件
jmap -dump:format=b,file=/app/temp/test11.hprof pid
很开心的使用MAT 工具分析dump 文件
发现内存占用正常没有问题
配置 OOM 时自动触发 headdump
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/app/temp/heapdump.hprof
在 OOMKilled 时并未触发生成 dump 文件,那是否是因为并不是 Java 程序的 OOM 呢?
好吧。还是需要详细分析究竟是哪个进程的内存占用的问题
同时执行 5 个设备遍历,在运行时获取各个进程的内存使用
ps aux | awk '{print $6/1024 " MB\t\t" $11}' | sort -n
得到信息
0 MB COMMAND
0.00390625 MB /pause
0.667969 MB sleep
0.972656 MB awk
2.29688 MB sort
3.34766 MB /bin/bash
3.41406 MB /bin/bash
3.66016 MB ps
4.05469 MB top
9.15625 MB java
53.5156 MB java
487.68 MB python3.6
竟然是 python 的程序内存撑满导致容器直接 OOM
回到 python 内存分析这一步,为什么在内存分析中并未找到问题呢?
问题在于获取内存数据是在本地调试执行,且执行的是 1 个设备执行遍历任务
还是不能偷懒,先撸一遍遍历时 python 的执行逻辑吧,简化的相关逻辑如下:
比如任务列表中需要执行的任务数 10,那么接下来 10 个线程每个线程都处理的任务如下:
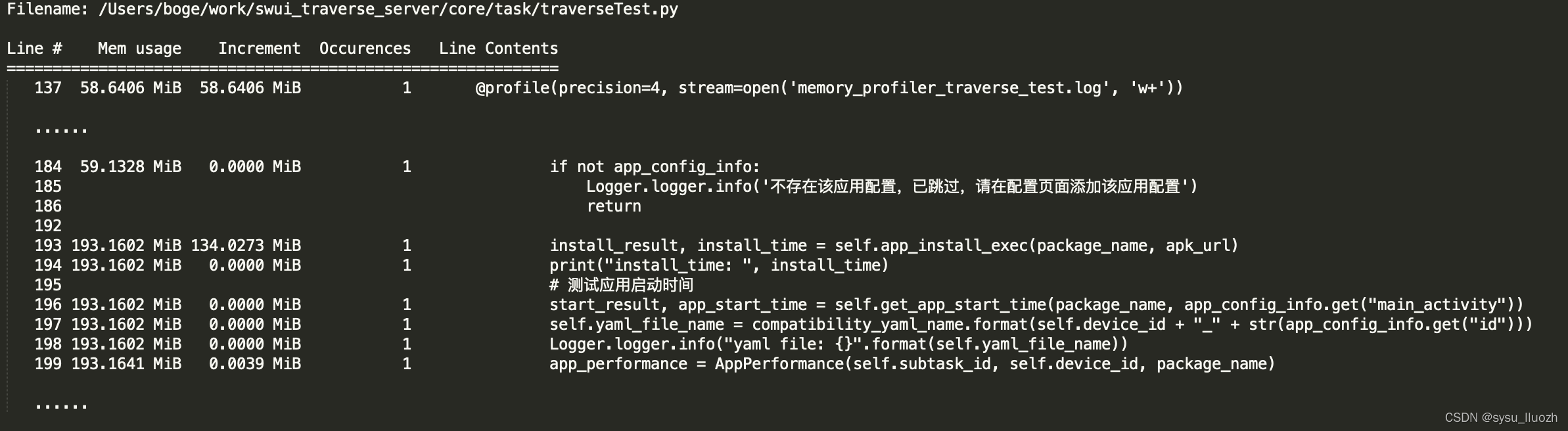
从 python 内存分析中也可以看到
Line # Mem usage Increment Occurences Line Contents
============================================================
137 58.6406 MiB 58.6406 MiB 1 @profile(precision=4, stream=open('memory_profiler_traverse_test.log', 'w+'))
......
184 59.1328 MiB 0.0000 MiB 1 if not app_config_info:
185 Logger.logger.info('不存在该应用配置,已跳过,请在配置页面添加该应用配置')
186 return
192
193 193.1602 MiB 134.0273 MiB 1 install_result, install_time = self.app_install_exec(package_name, apk_url)
194 193.1602 MiB 0.0000 MiB 1 print("install_time: ", install_time)
195 # 测试应用启动时间
196 193.1602 MiB 0.0000 MiB 1 start_result, app_start_time = self.get_app_start_time(package_name, app_config_info.get("main_activity"))
197 193.1602 MiB 0.0000 MiB 1 self.yaml_file_name = compatibility_yaml_name.format(self.device_id + "_" + str(app_config_info.get("id")))
198 193.1602 MiB 0.0000 MiB 1 Logger.logger.info("yaml file: {}".format(self.yaml_file_name))
199 193.1641 MiB 0.0039 MiB 1 app_performance = AppPerformance(self.subtask_id, self.device_id, package_name)
......
在安装操作self.app_install_exec(package_name, apk_url)时内存飙升,那么着重看一下安装的代码逻辑:
def app_install(self, download_url):
get_response = requests.get(download_url, timeout=60)
if get_response:
app_content = get_response.content
res = requests.post(
"http://{}:{}/mobile/{}/installApp".format(self.agent_ip, self.agent_port, self.device_id),
files={
"app": app_content
}
)
OMG!安装的过程是直接 requests.get 将数据包下载下来,然后再将包内容 content 直接下发给手机设备 mobile 执行安装操作
这种处理方式太诡异了,有几个问题:
其实现在问题已经很明显了,后面验证了 5 台、10 台、20 台设备时再次验证了从源码中的分析的原因
问题修复方式只要将 apk 包的链接地址传给 mobile,mobile 自行下载然后执行安装逻辑即可
