
作者 | 王佳泽 导师 | 庄锦弟
大促压测(单场景,多场景,全链路)是基于生产环境和实际业务场景,模拟海量的用户请求和数据对整个业务链进行压力测试,并持续调优的过程。
随着公司业务的不断变更和新增,用户流量也在不断提升,系统框架的规模和复杂性也随之增加。生产环境服务的稳定性也越来越重要,服务性能问题,以及机器资源容量问题也越发明显。为了及时暴露各种性能问题,我们是基于生产环境进行全链路压测。接下来介绍一下双 11 大促,我们是如何做生产环境压测的
1、梳理业务,梳理压测页面、接口
2、分析动态参数、录制接口
3、构造压测动态参数数据
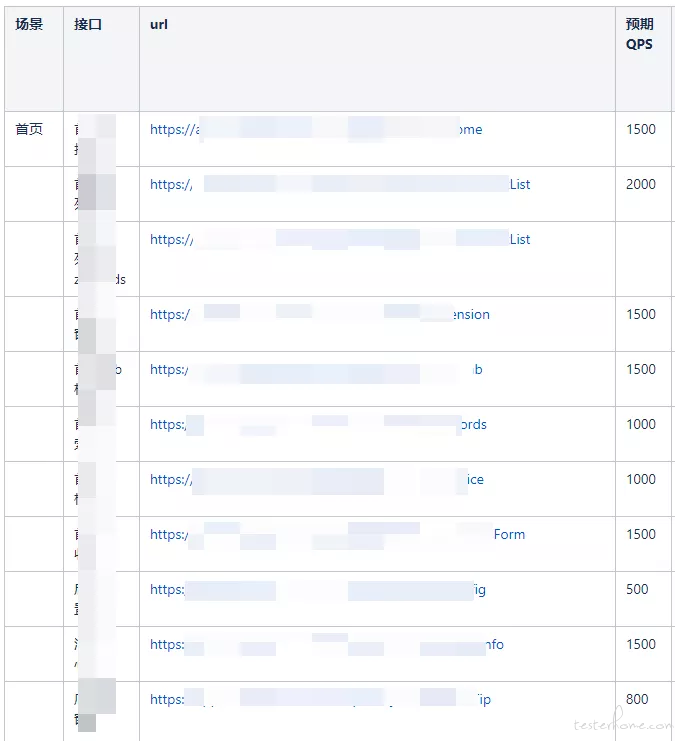
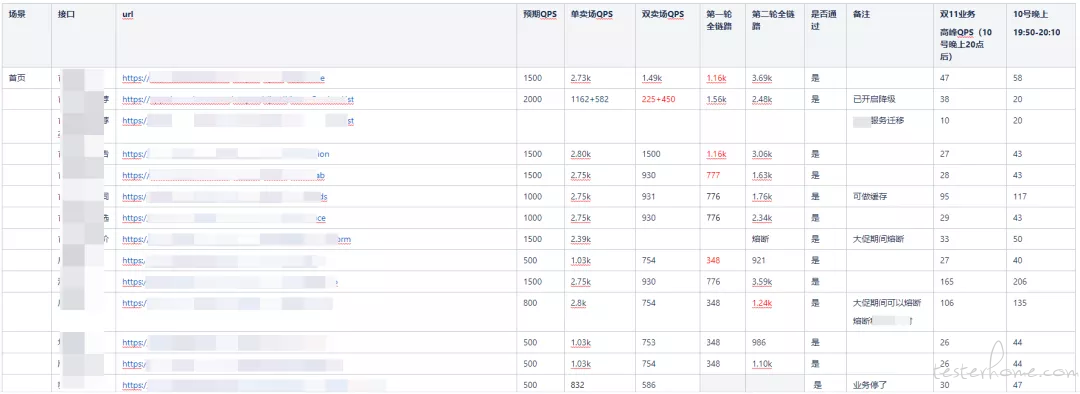
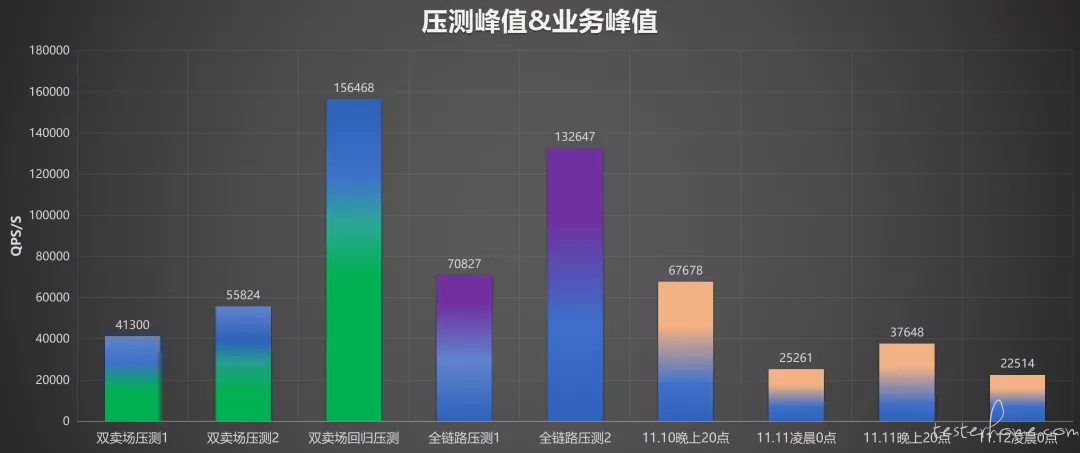
4、设定目标 QPS(zlj-压测接口预期指标&实际结果);
参考去年双 11 和今年 618 接口流量峰值设定双 11 接口目标 QPS(a x b x c):
a:去年双 11&今年 618 接口流量峰值
b:大促等级 1.2 倍
c:预防突发流量,按页面等级 5-10 倍
计算公式:(80%请求数 × 冗余系数) ÷ 20%时间 或 峰值时间 = TPS
1、刷新用户 token,使用中台提供接口,跑 1w 用户时接口报错;token 缓存时间 1h 比较短,需要每小时刷新一次;
2、调试接口时,cookie 中 token 未带双引号,调试过程中出现 token 无效的情况;
1、token 生成可以通过数据构造的方式,调用生成 token 接口,直接生成 csv 文件;
2、压测数据文件的 token 统一带入双引号括起来;
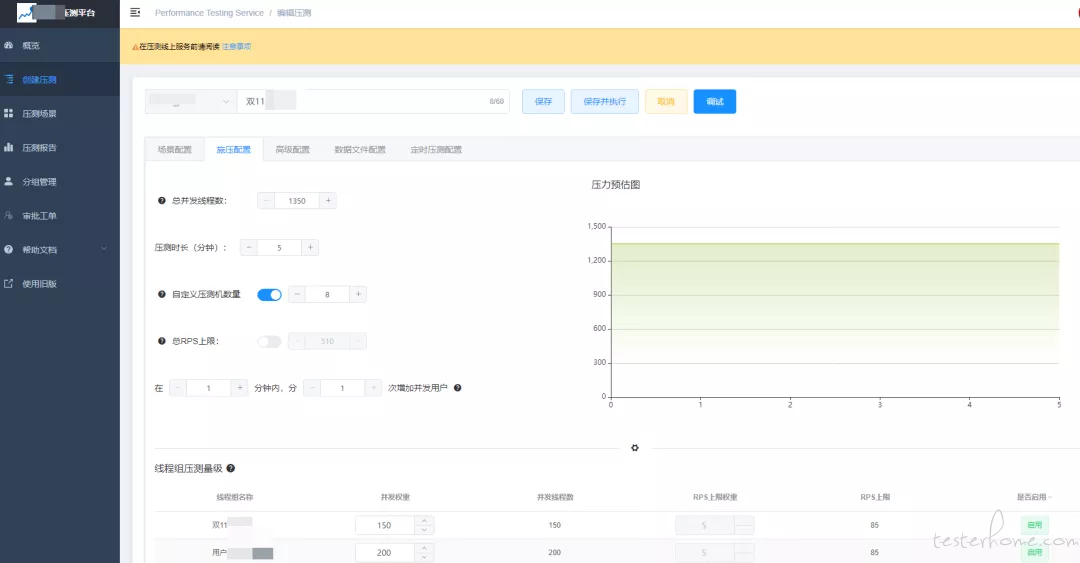
时间周期:10 月 09 日 ~ 11 月 09 日
共执行 9 轮:单卖场 4 轮,双卖场 3 轮,全卖场 2 轮
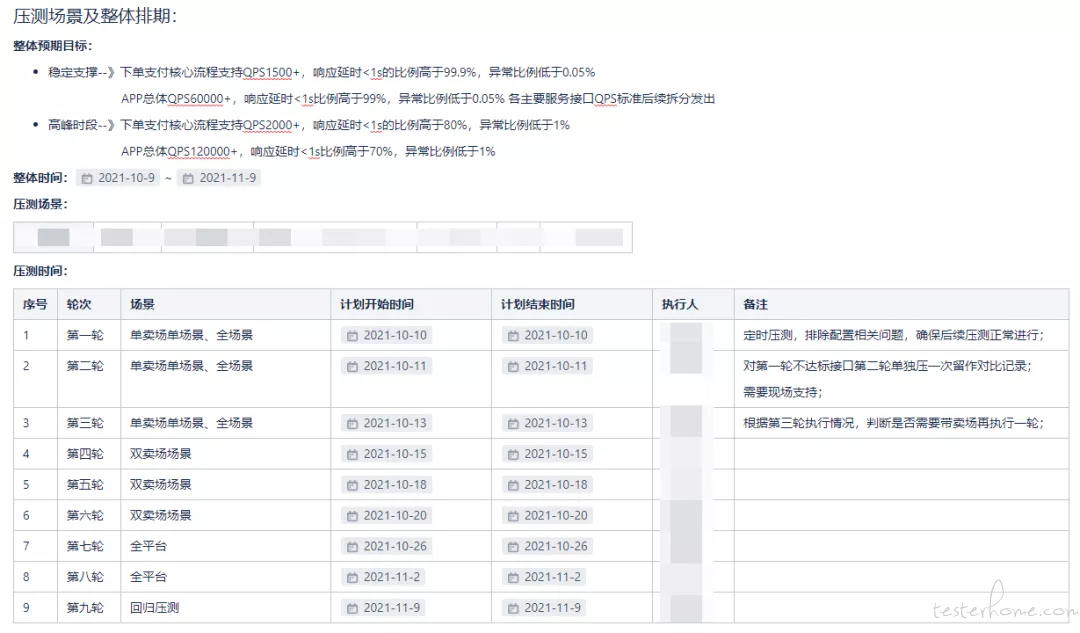
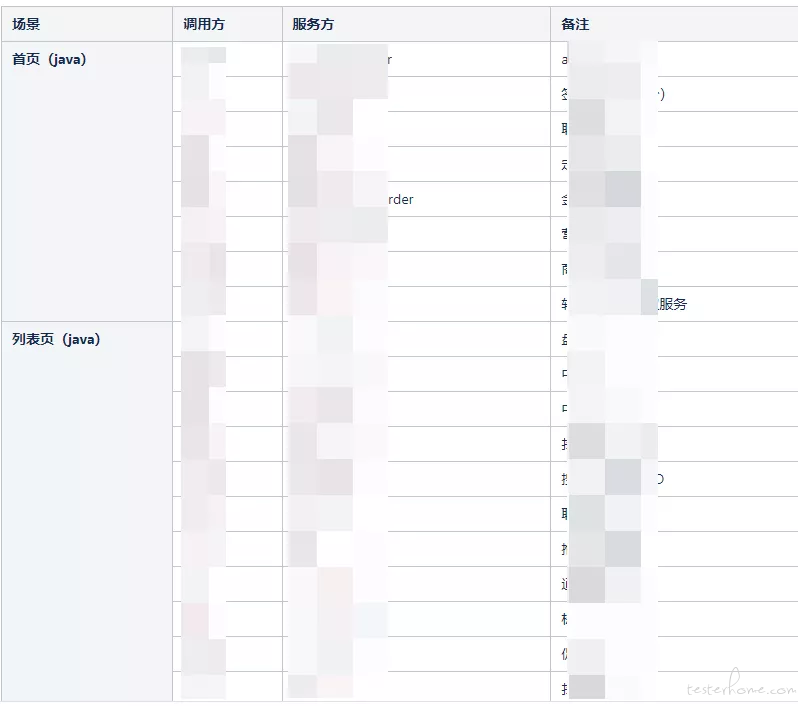
压测目标:解决单接口性能问题,服务依赖限流调整到合适比例,机器调整到合适资源
最终结果:经过 4 轮压测不断优化调整,分别对 zljA 服务,zljB 服务,增加 cpu 核数与容器节点,对 zljC,zljD 增加 cpu 核数,使 QPS 达到预期目标;
卖场接口性能无太多问题,大部分为调用限流熔断,机器资源问题;
1、每次调整限流都会出现遗漏;
2、每次调整完进行新一轮压测,又会出现新的限流服务;
1 轮压测后将不达标的接口罗列出来,将相关依赖服务整理出来,根据当前调用量分析是否需要调整;
压测目标:双卖场接口达到预期,机器调整到合适资源,压出依赖服务瓶颈
最终结果:经过 3 轮压测,双卖场 QPS 均达到预期目标
1、搜索瓶颈,双卖场同时压测线程过大时,搜索推荐服务超时异常较多
2、服务治理平台统计耗时不高,Nginx 报告统计耗时很高,无论线程数与压测机比例如何分配,都无法提升 QPS,最后发现网关对 token 有缓存机制,过期会透过缓存,导致数据库压力过大,且网关耗时没有被统计到;
3、接口录制时,按页面流量比例设置的线程,线程中包含多个接口,导致其中某个接口耗时高时,影响到其他接口
1、搜索、推荐测降级、卖场熔断部分推荐列表、卖场商列做缓存
2、每小时刷新一次 token
3、后续压测全部按单接口单线程录制(吐槽:修改起来会比较麻烦,建议压测平台提供一键修改线程数)
压测目标:接口达到预期
1、会场促销接口耗时较高,陈年代码修复起来比较困难
2、第一轮全场景,搜索推荐服务瓶颈,导致压测无法继续,短时间没有排查出问题
3、红包异常较多,数据库出现瓶颈
各业务线配合优化调用链路和请求调用量
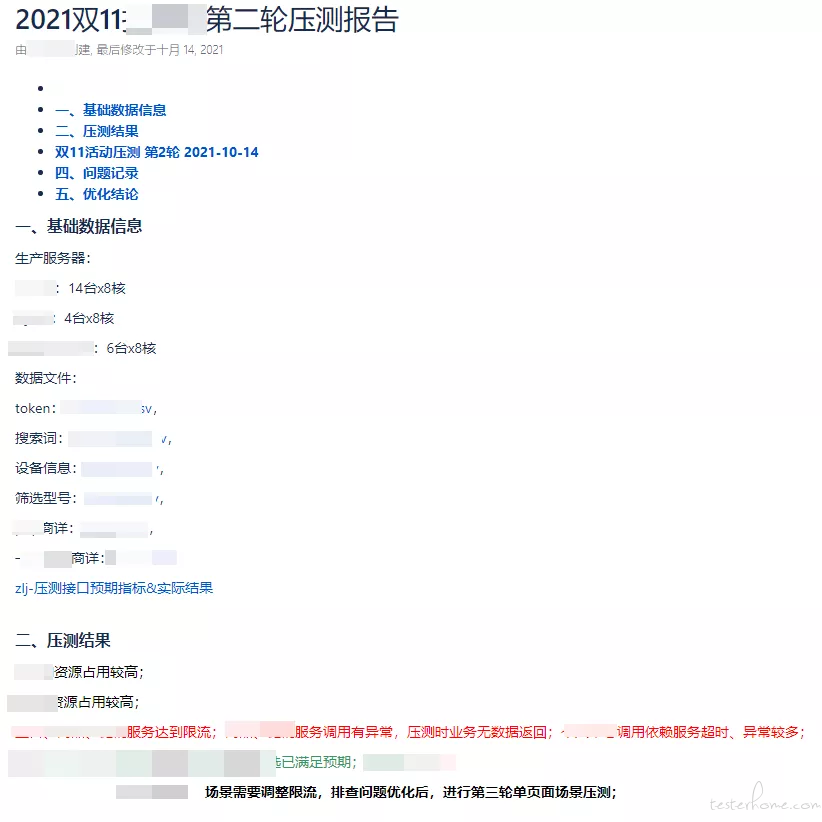
压测报告内容:
资源配置
数据文件
当前轮次压测总结(达标内容,不达标内容,问题原因,需要跟进负责人);上一轮修复问题验证结果
压测记录(标记不符合接口)
统计场景中超时异常较多的接口,依赖服务及调用函数
压测记录截图
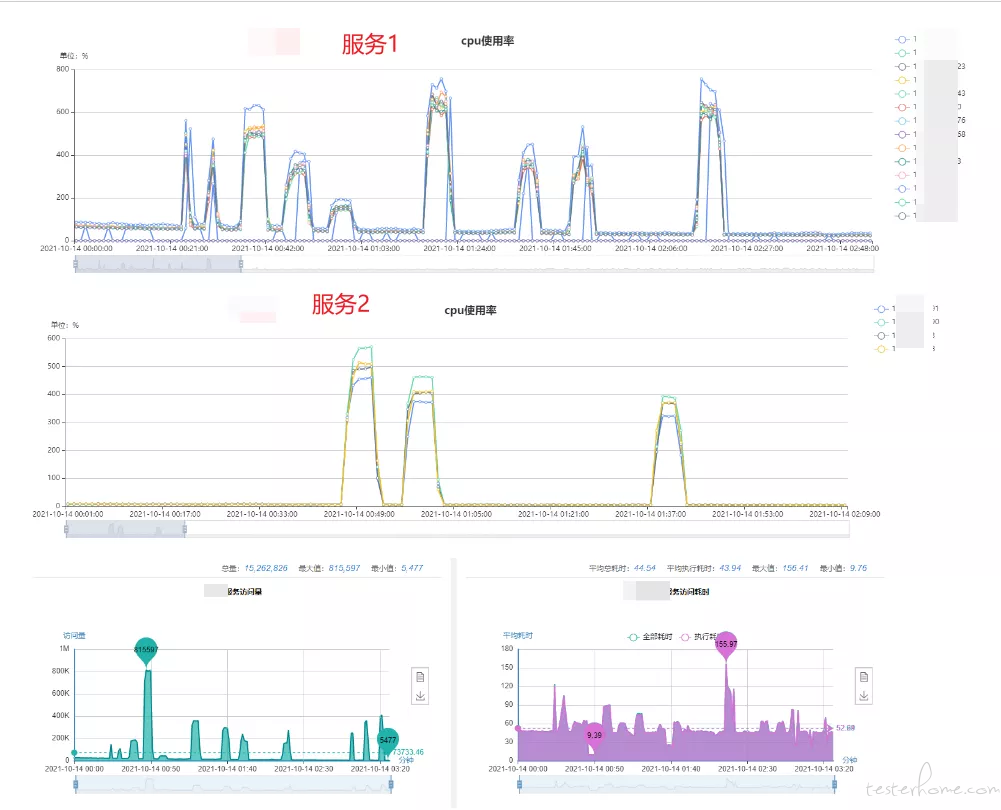
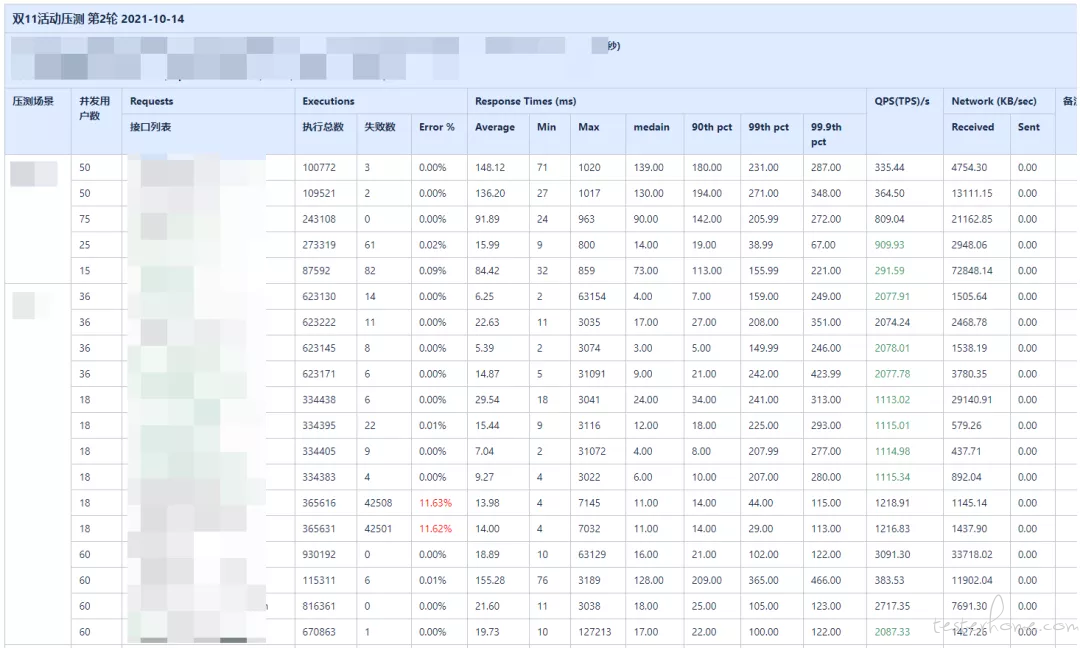
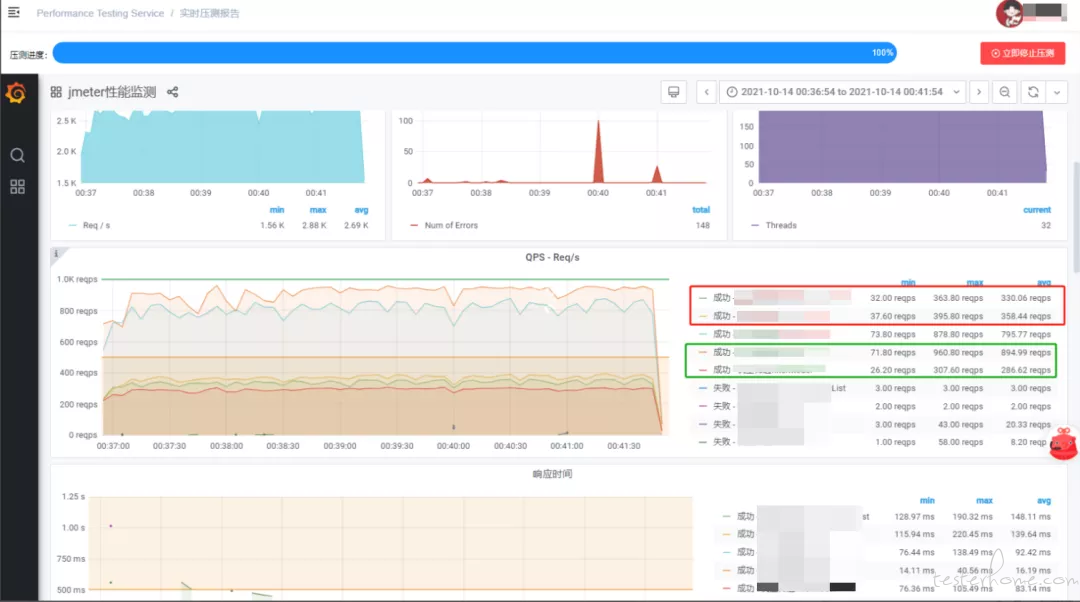
刚接触压测的时候,只知道一些理论知识;接到需求后不知如何设计压测方案,也不知道压测的目标是什么,只能先熟悉压测平台的使用,以及录制压测脚本、执行;看一看服务资源占用,压测报告 QPS,接口耗时;就连压测报告也不知道要输出哪些内容突出哪些重点;
通过几次日常摸底压测,逐渐了解不同的压测目的,制定的目标与计划也有所不同;像新接口的日常摸底需要关注单接口的瓶颈,大促活动的压测需要关注整体的 QPS;在压测过程中逐渐了解各监控平台的使用,开始关注数据在整个链路中各流程节点的消耗;
例如:搜索商列接口,通过服务治理平台,可以了解到它调用的服务,和调用的函数,也可以查到它对应的耗时时间,通过比对依赖服务的耗时,找到可以优化的内容;

学会总结压测过程中经历的问题(配置问题、限流问题、异常问题、GC、耗时较长修复),总结压测过程中可以提高效率的问题(完善压测计划,各监控平台使用),总结遇到问题时开发如何去排查;
可以快速的提升自己对服务之间依赖关系的了解,学会如何利用各监控平台内容去定位问题;
分析每次压测过程中大家关注的内容,整理出可以在压测报告中体现的重点;
通过多次压测后,哪些内容会对压测结果造成影响,可以提前做好配置准备;
例如:提前申请调用量,告知开发开启熔断、降级等等

