项目管理系统主要目的最开始是为了解决提高 PMO 手动出人效的效率.
我司的项目管理比较乱,核心数据存在了外部购买的系统上"teambition",比如项目排期、测试用例、bug 等数据.PMO 同学在做数据统计的时候,先要从 teambition 倒出一份原始数据,再按照 pmo 约定的规则计算人效,计算的效率极低.
由于 PMO 计算人效的公式是内部协商出来的:
1、当研发阶段的时候,开发人效 +1
2、当测试阶段的时候,开发人效 +0.5、测试人效 +1
3、当前上线阶段,开发人效 +0.5、测试人效 +1
等等还有一些公式
1、经过调研在 teambition 开发,如果达成 pmo 的效果,需要给 teambition 提需求,经过沟通比较难实现.
2、自研项目管理系统,通过同步 teambition 把数据存储到研项目管理系统,把计算人效逻辑封装到后端服务中.
自研系统好处:
1) 锻炼前端后端开发技术
2) PMO、产品、研发共建系统,拉起目标
3) 向上管理工具
自研系统缺点:
1) 产品大多没有架构设计
2) bug 多,代码难维护
3) 代码服务没分层
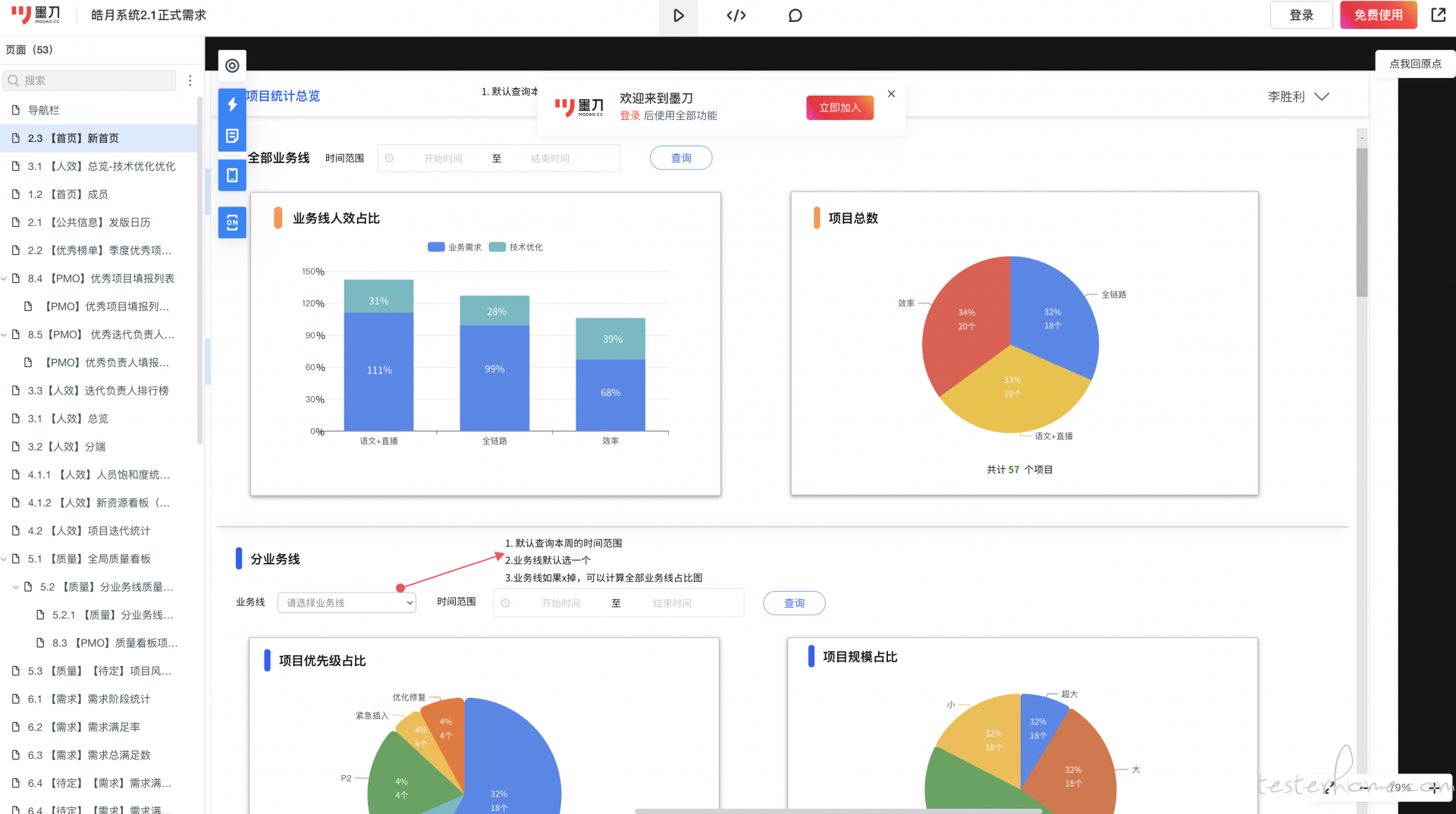
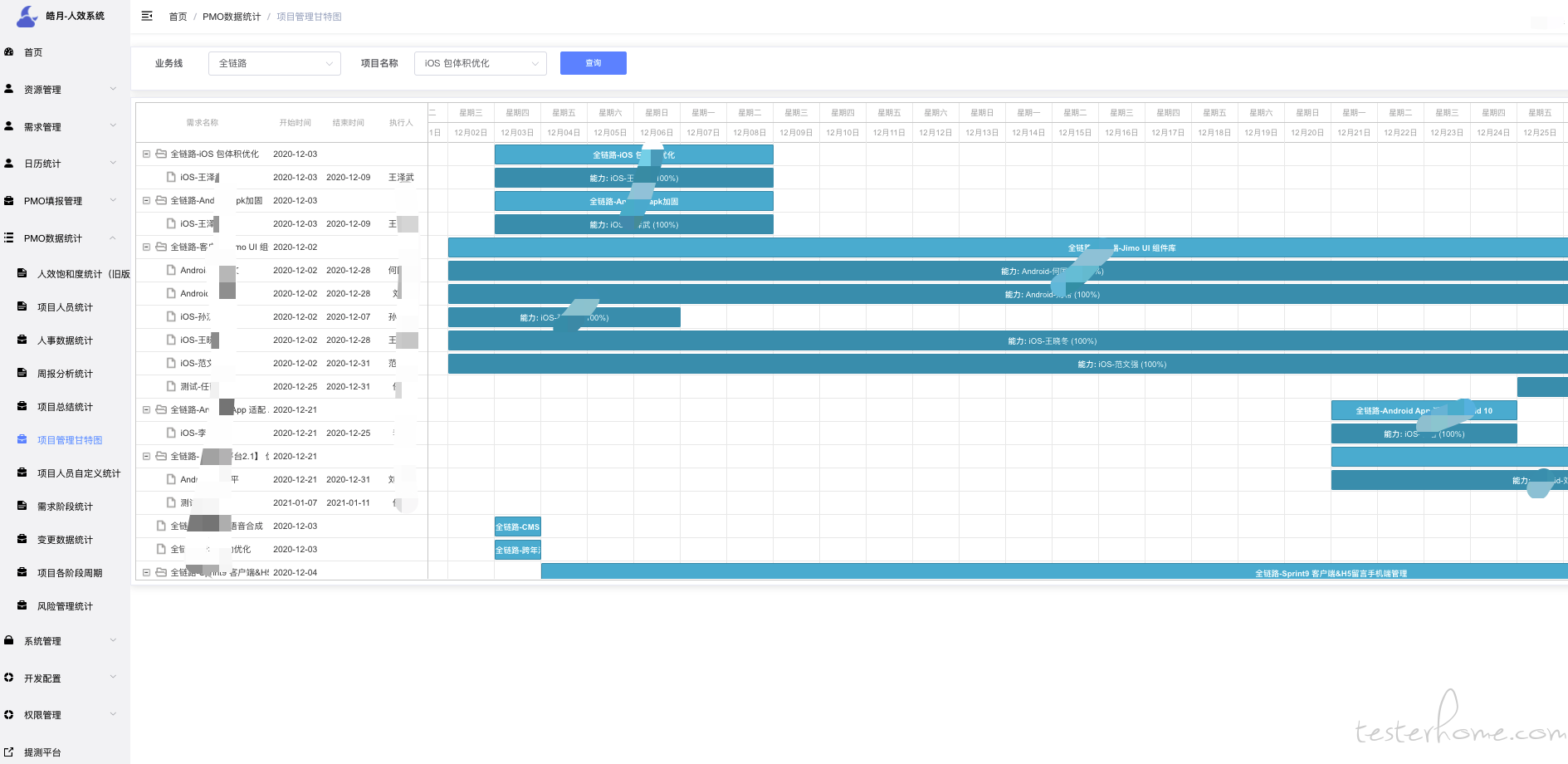
如下图是当时 pmo 设计得产品原型图,包含从项目管理角度出发覆盖研发效能到质量分报告,涉及得功能模块比较全.
首页图表
需求维度
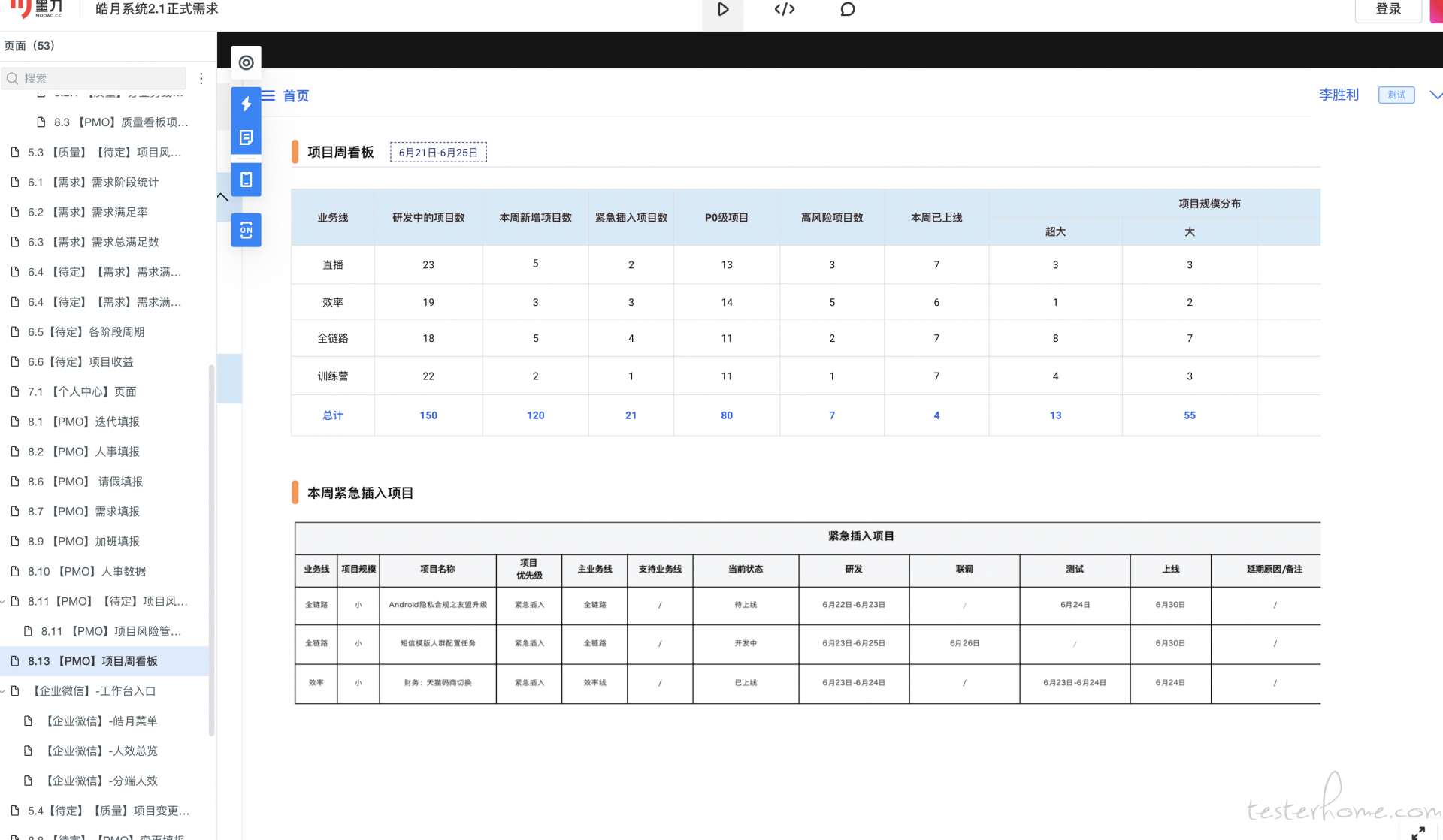
质量分报告
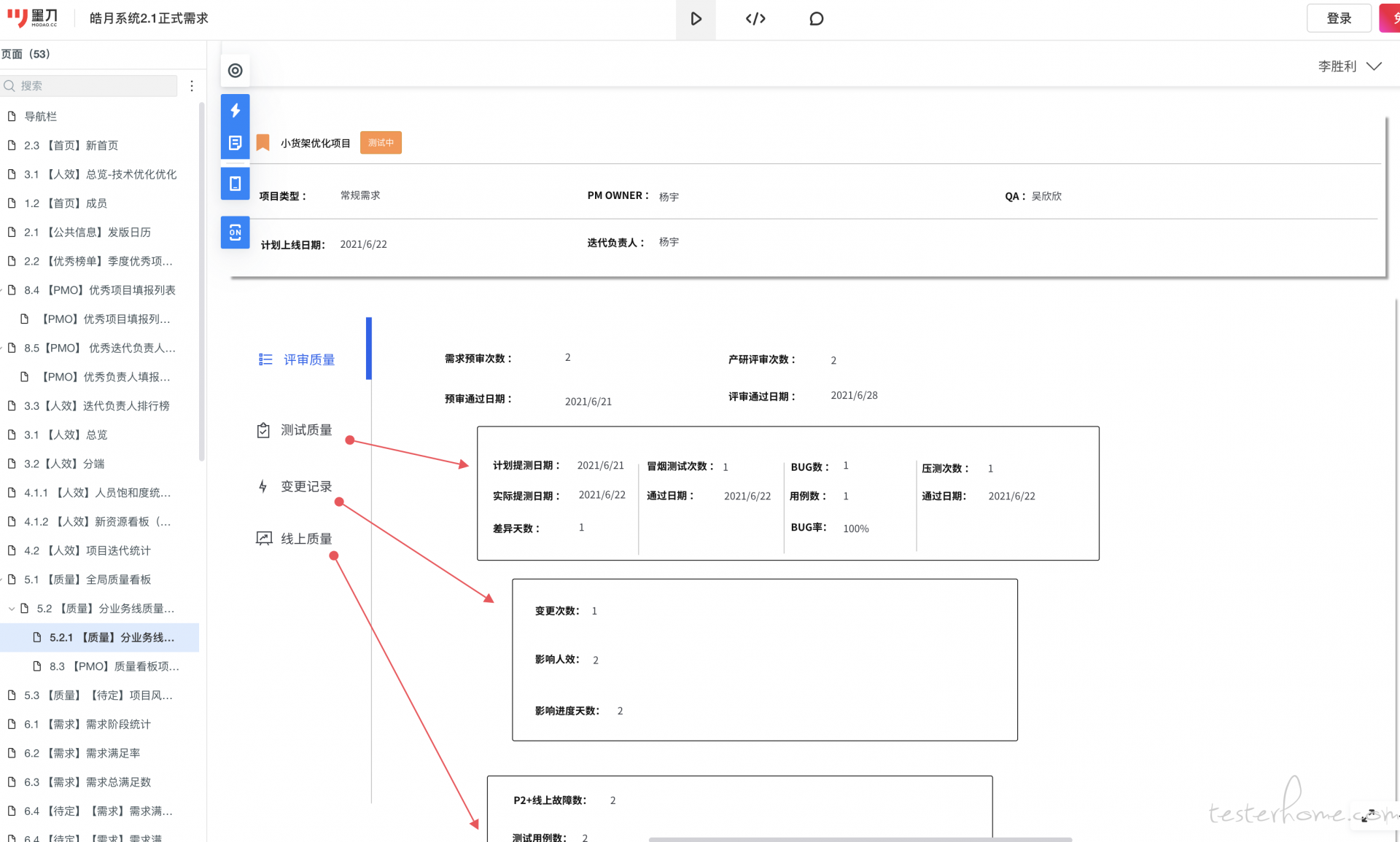
如下图是产品架构
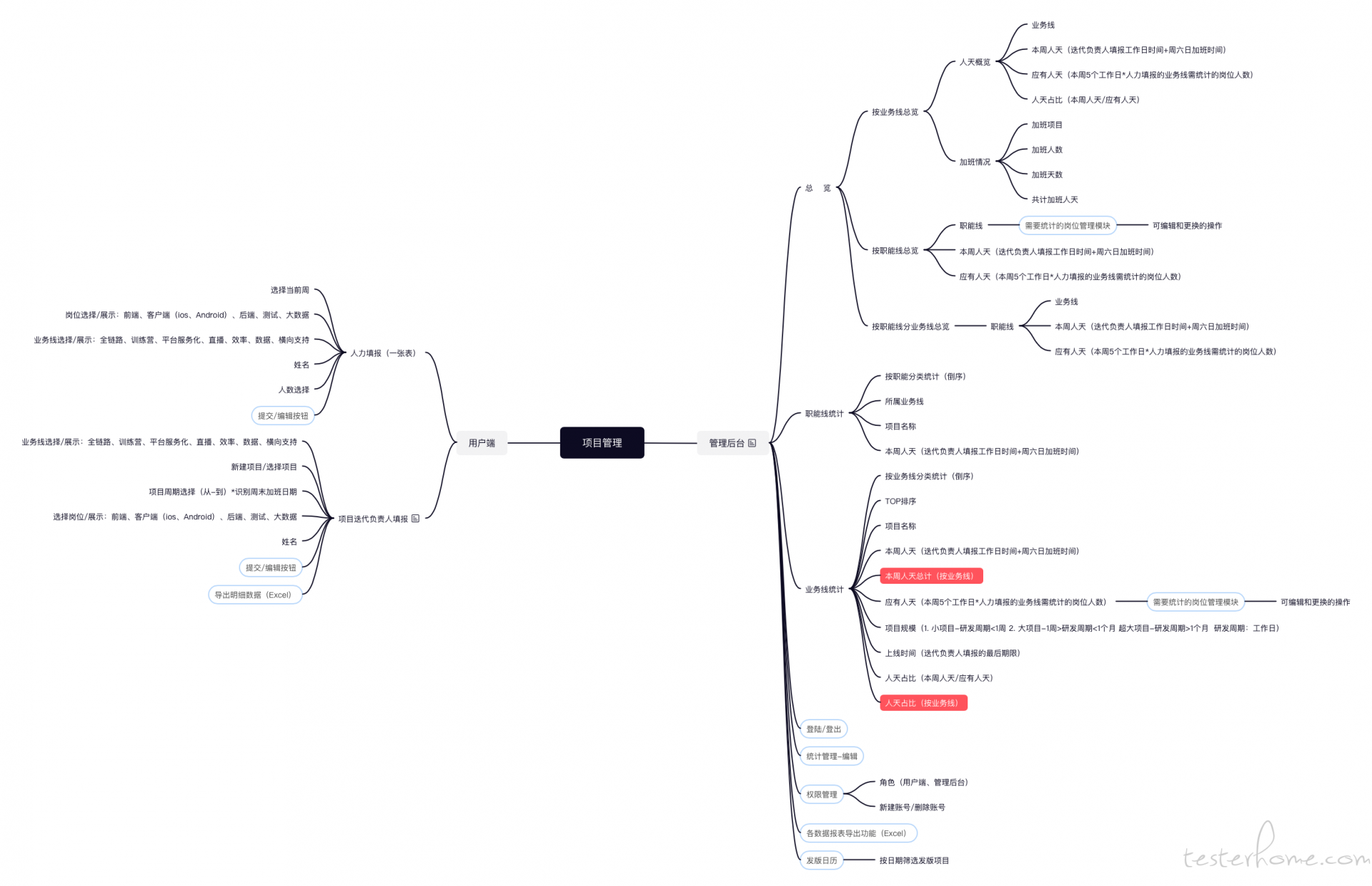
参考 vue admin 平台,隐藏不需要代码即可,开箱即用.
https://github.com/PanJiaChen/vue-element-admin
依赖如下库
vue2.x、axios、echarts、element-ui、stylus等库
后端系统主要使用 django 全家桶开发,类库比较多、并且 ORM 功能强大、部署方便.
django全家桶、 mysql 、 redis 、 request 、gunicorn等库
经过几个迭代以后,代码越来越多,所有功能模块都写到一个服务上,变的越来越重.应该考虑微服务架构解耦代码问题.
1、jenkins
jenkins 主要做同步数据脚本使用,配置方便
2、apscheduler
apscheduler 库,为了实现内部方法做定时任务使用.
每个公司为了统一账号密码登录控制,都会由运维部门统一认证后,才能登录各个子系统.目的在于安全、统一管理账号密码.
下图是单点登录的首页,支持账号密码登录或者扫描二维码登录.
接入后,登录后可以拿到姓名、岗位等信息,方便后续权限管理模块开发.
接单点登录系统,一般需要和单点登录系统注册,注册后会把给 client_id 和 client_secret 两个参数,为了安全性考虑.
需要在前端启动首页的时候,如果没有登录就去访问登录首页.
在 router.beforeEach 函数中,从 cookie 中获取 token,如果没有 token 跳转到登陆页面.
登陆页面的逻辑,首页会判断是有 code,没有的话调用接口获取 code,code 参数通过前端页面拦截获取,所以这样是很安全的.拿到 code 再去换 token,最后获取用户信息的接口携带 token 参数,跳转到首页.
内部有很多系统都接入了单点登陆系统,为了能登陆一次系统后,再登陆其他系统就不需要再登陆,需要共享登陆状态.
如果设置 cookie 的话,把 cookie 种在根域下就可以,这样就通过 cookie 完成了共享登陆状态.
由于我们和"teambition"第三方公司签约到很久,需求数据、bug、测试用例都存在了
"teambition"平台.所以需要使用对接"teambition"的 api 完成数据同步.
teambition 接口鉴权这款还是比较复杂的,首先有管理员账号并且生成对应的 token.
使用 jwt 对参数进行编码解码等一系列操作生成 token,放在请求的 header 中.
def get_token():
"""
生成token
:return:
"""
payload = {}
iat = math.floor(int(time.time()) / 3600 * 3600)
payload['iat'] = iat
payload['_appId'] = appId
headers = {
"alg": "xxx",
"typ": "JWT"
}
token = jwt.encode(payload, appSecret, headers=headers).decode('utf-8')
return token
teambition 的官方接口文档,如果对接第三方系统,没有好的接口文档,开发的过程中会很痛苦.
https://open.teambition.com/help
查询任务,只需要把 task id 传过去就行了
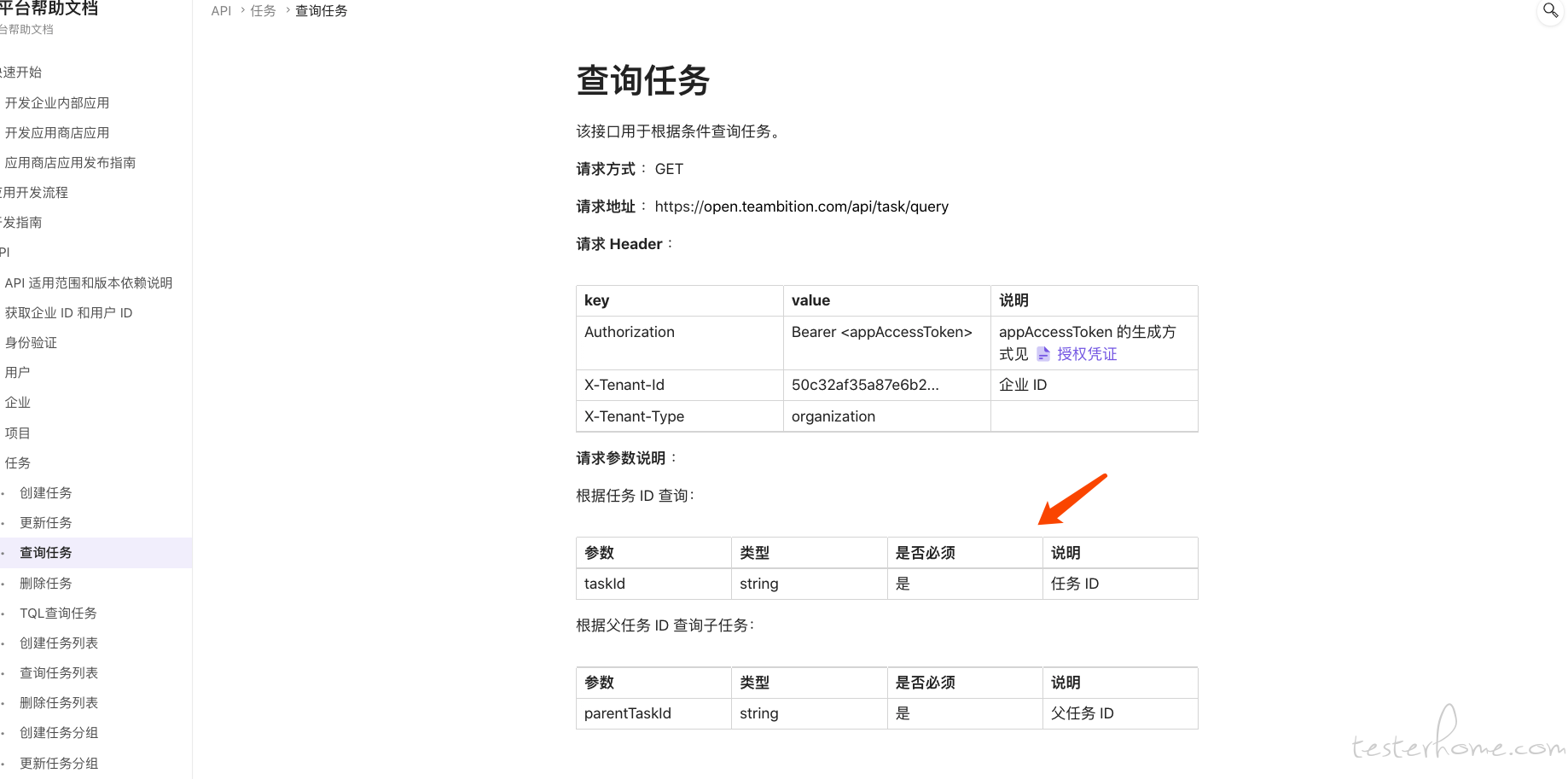
还支持 tql 查询,扩展性比较强

因为增量同步可以减少同步时间,但是可能会存在同步数据存在误差.
主要有几个原因,需要保持新增、删除、变更的数据一样,这样就需要同步脚本有大量的逻辑判断,所以写完脚本,需要测试各种场景保障数据的一致性.
这种用的比较少,暴力做法就是删库重新同步.
当"teambition"得数据发生变化,主动给我们服务发送请求告知数据变化.
这种可以满足数据实时更新,但是需要服务端有逻辑判断.
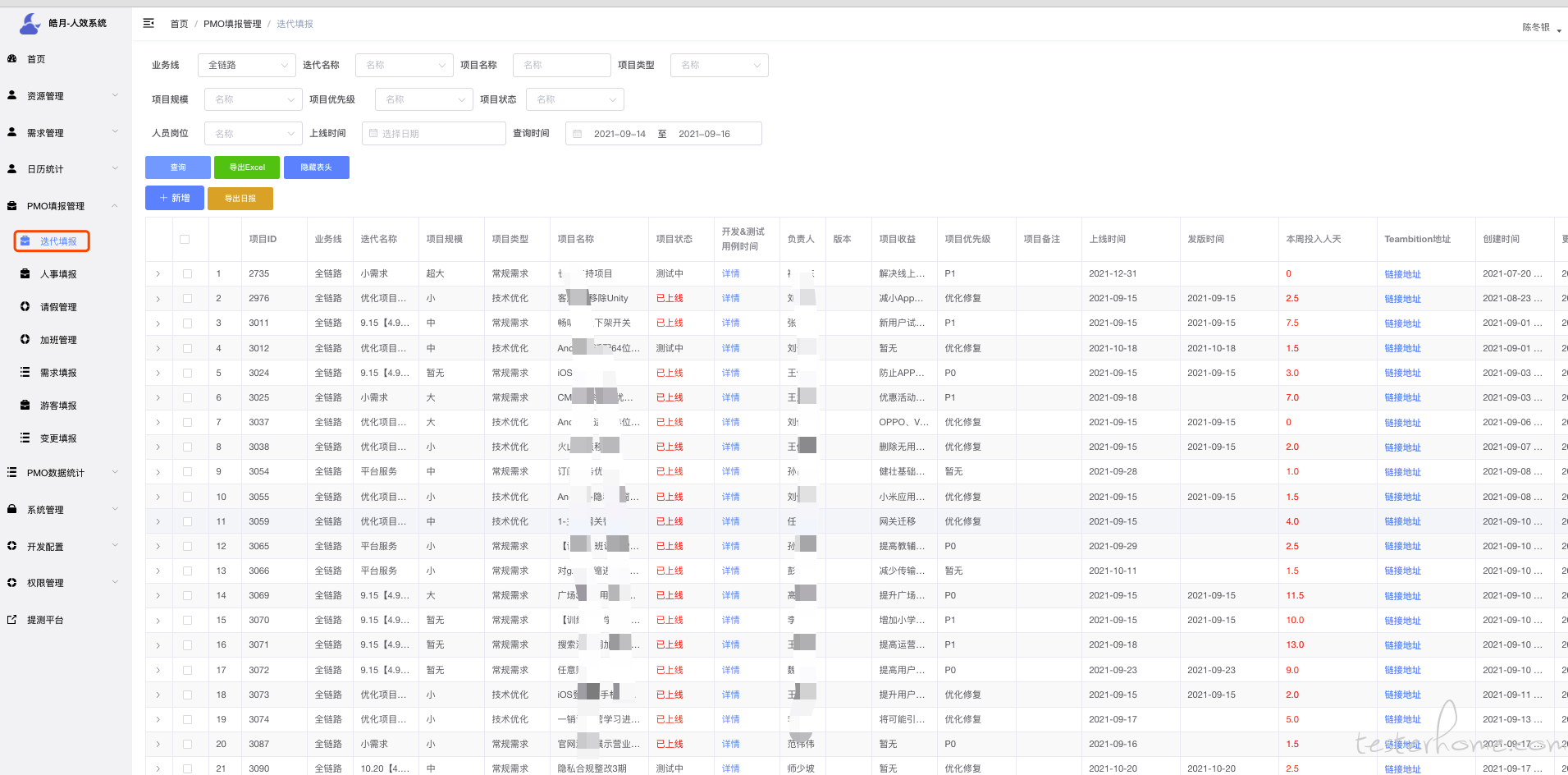
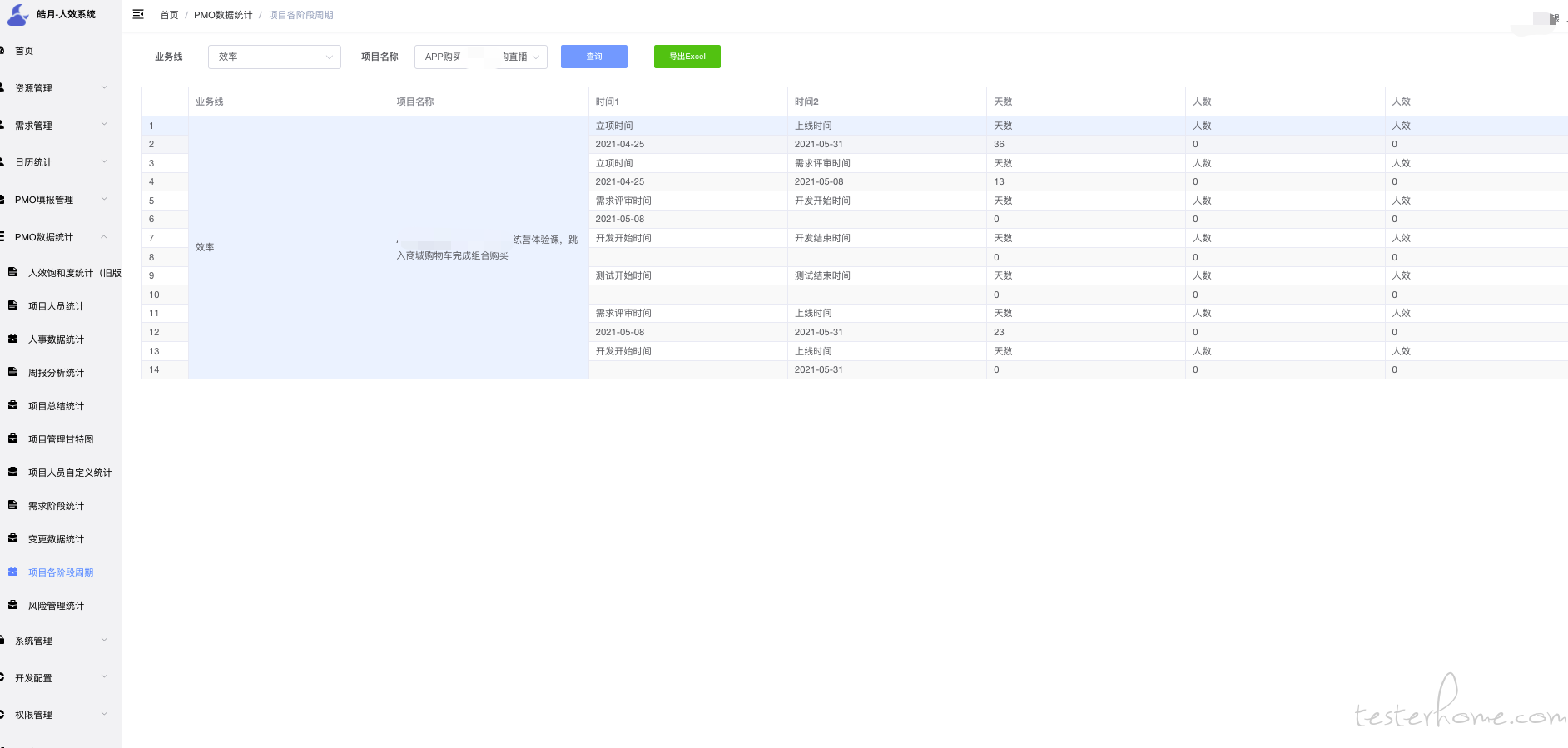
迭代填报主要是从"teambition"同步过来的数据,这里只做展示,一般不会手动改数据.
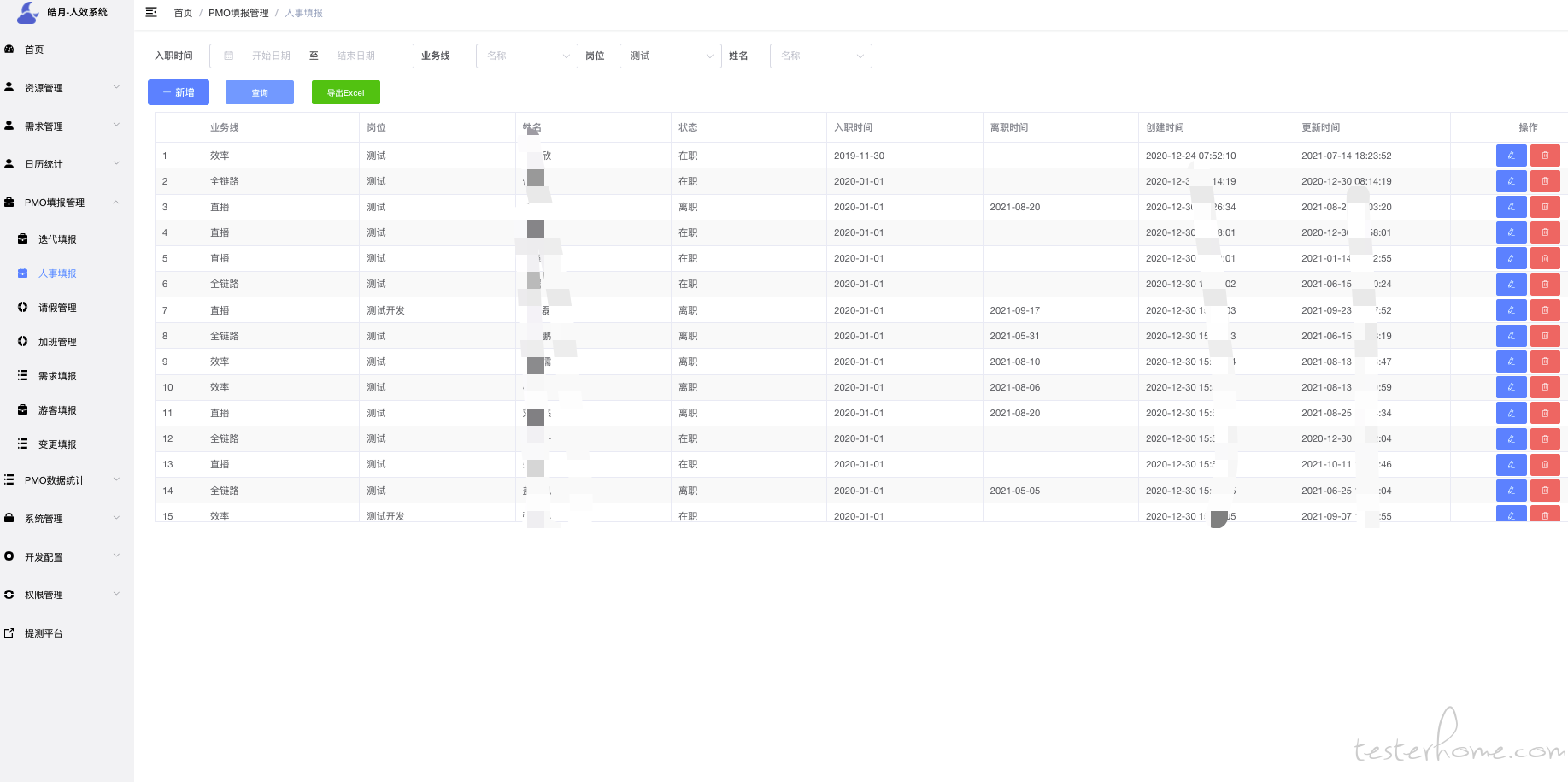
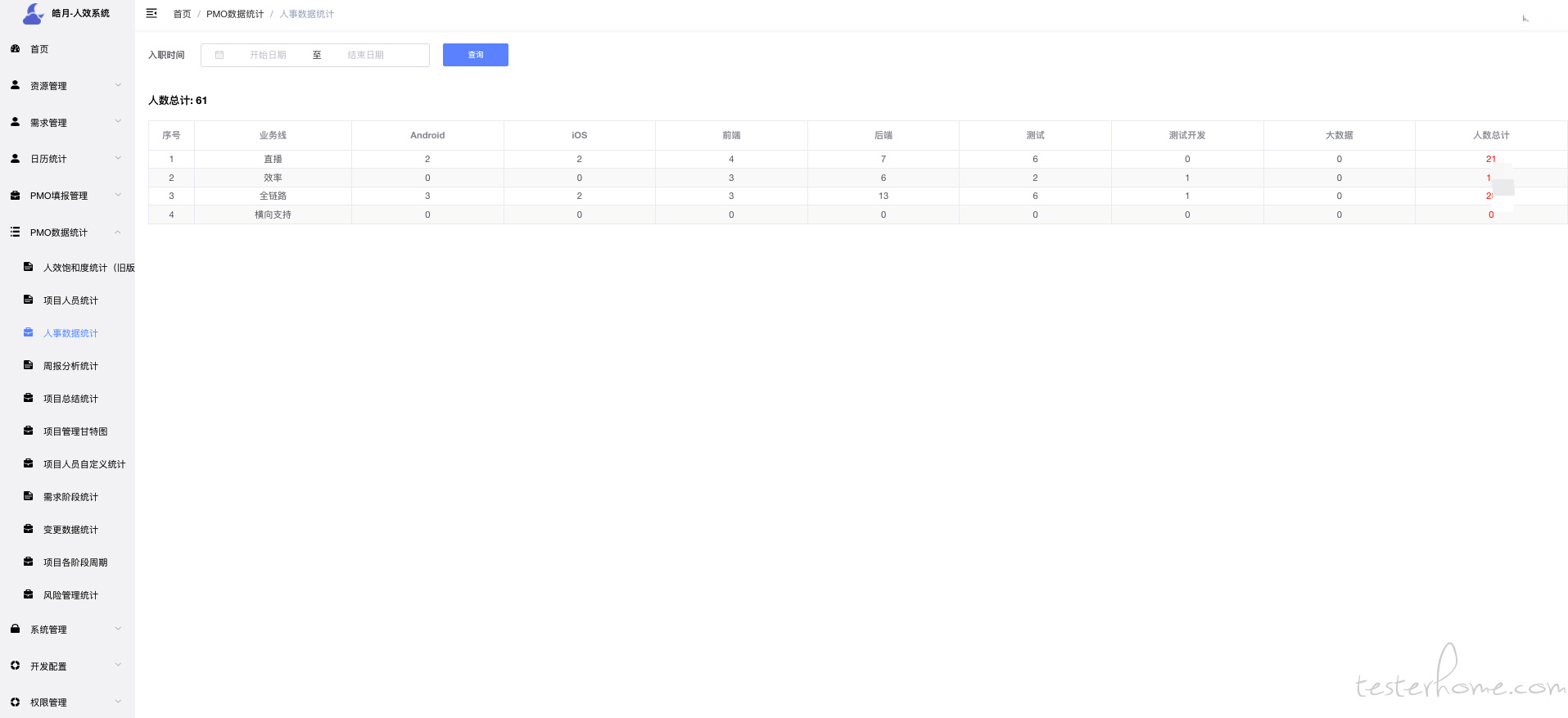
人事管理对接了"薪人薪事"系统,可以拿到人员状态等信息.
请假管理需要手动填报,因为很多人请假不走"薪人薪事"系统,每周五 pmo 手动统计.
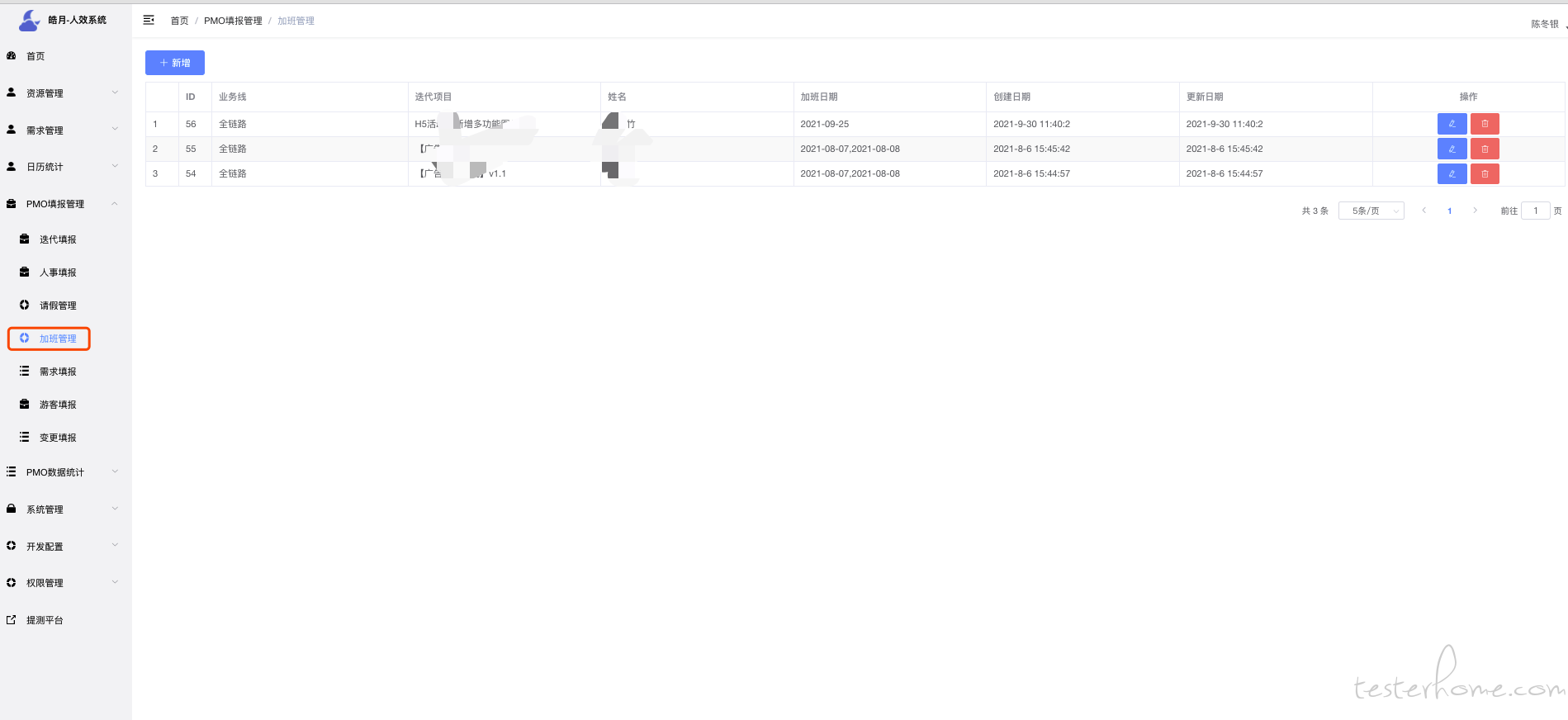
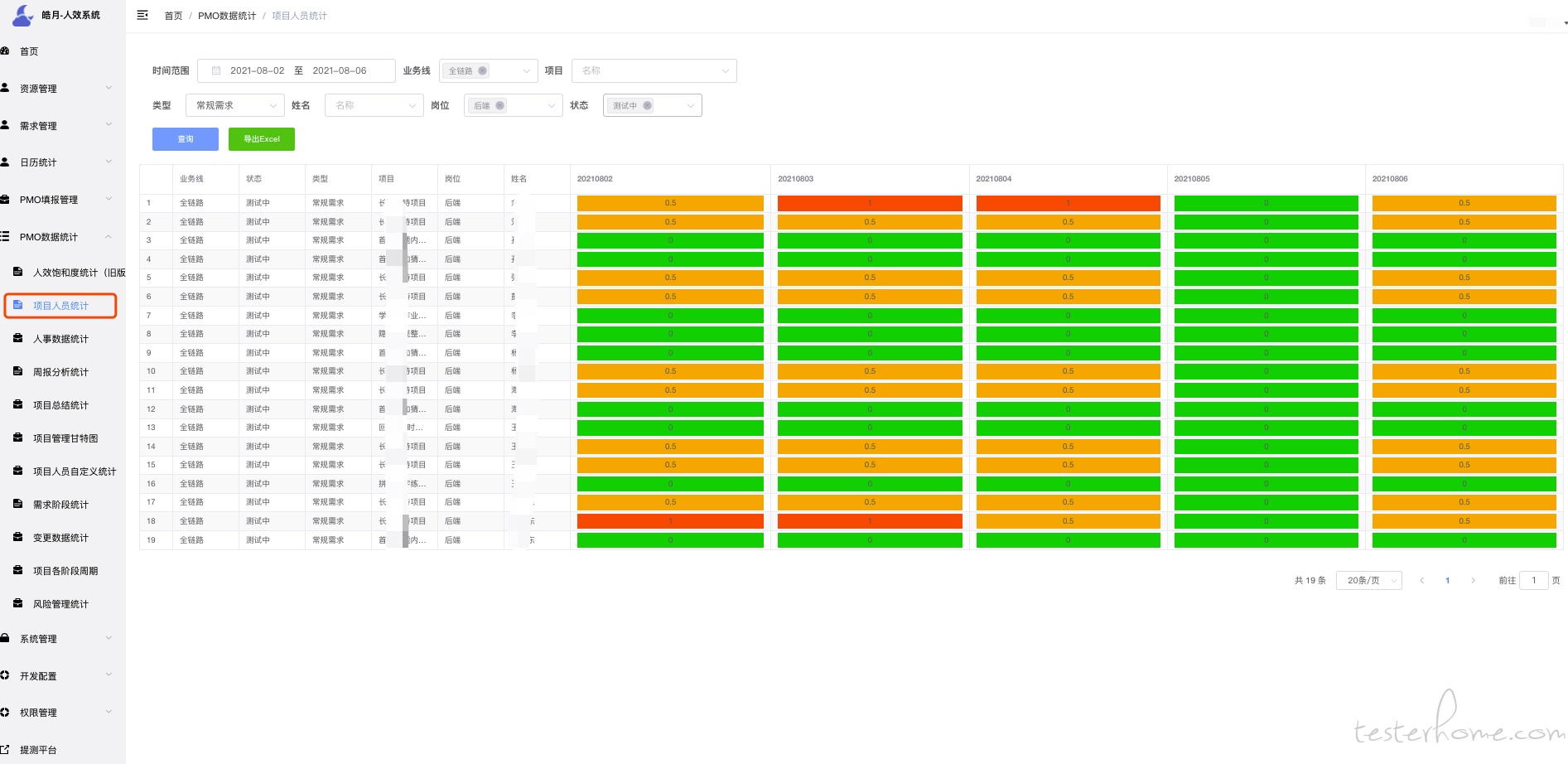
需求管理也是同步"teambition"空间的数据,需求有几种流转状态,当状态变更的时候需要记录.
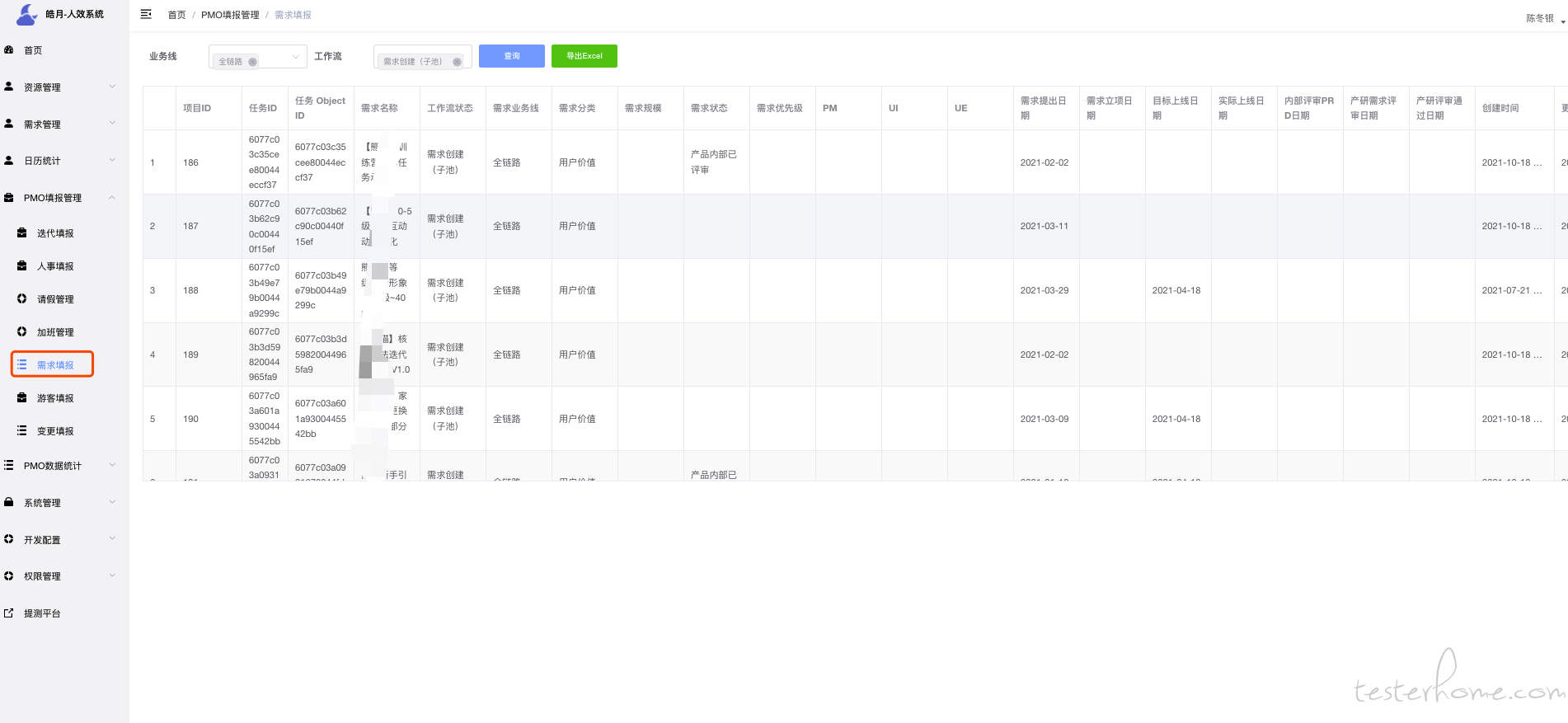
从业务线唯独可以清晰得知道,每个业务线得数据
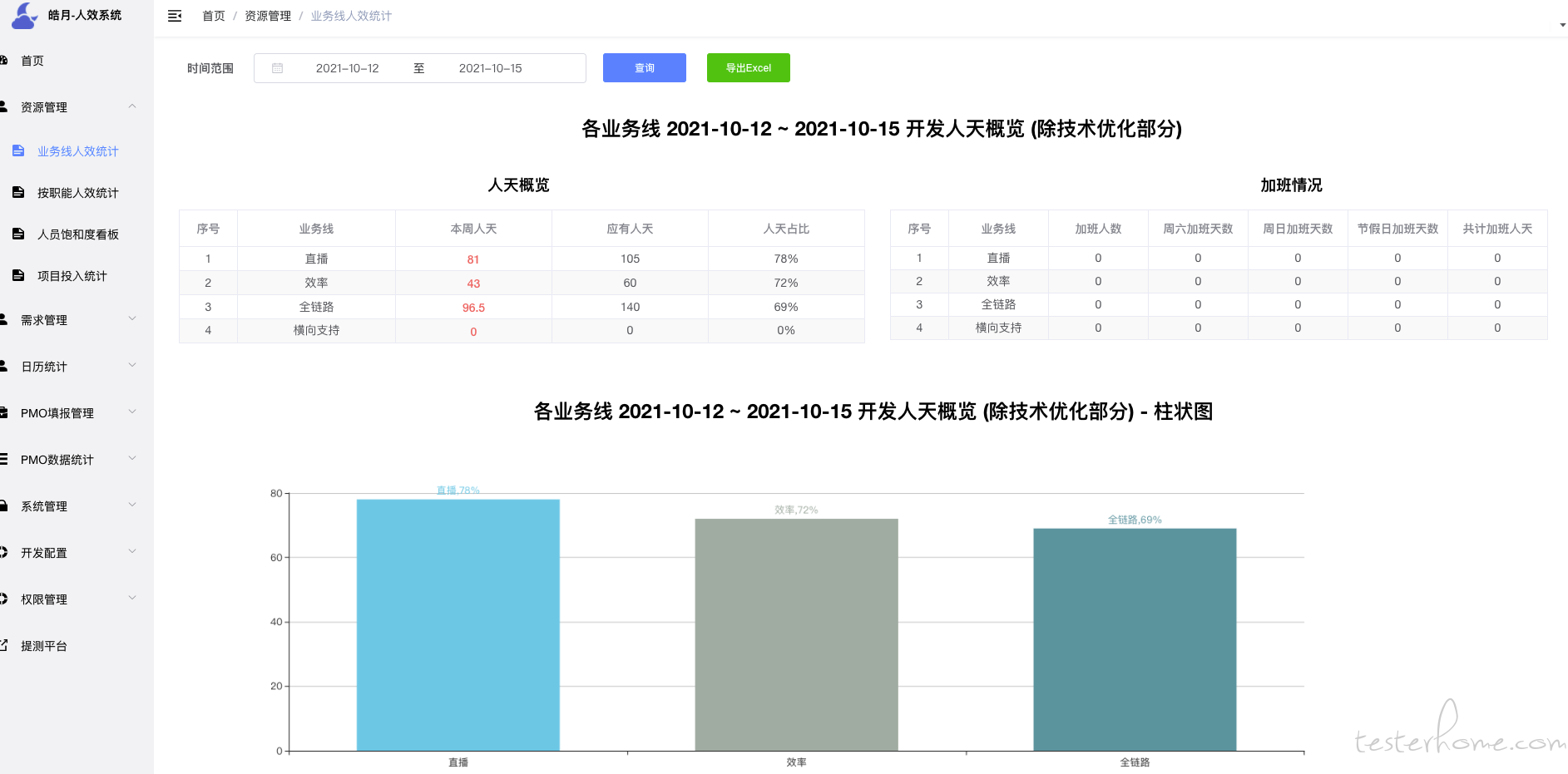
因为我们公司前端在业务线干活,但是隶属统一前端 leader 管理,职能人效可以发现谁不忙就让谁补其他人得需求开发.
人员饱和度主要是想细化到每人身上,关注每个人得产出.
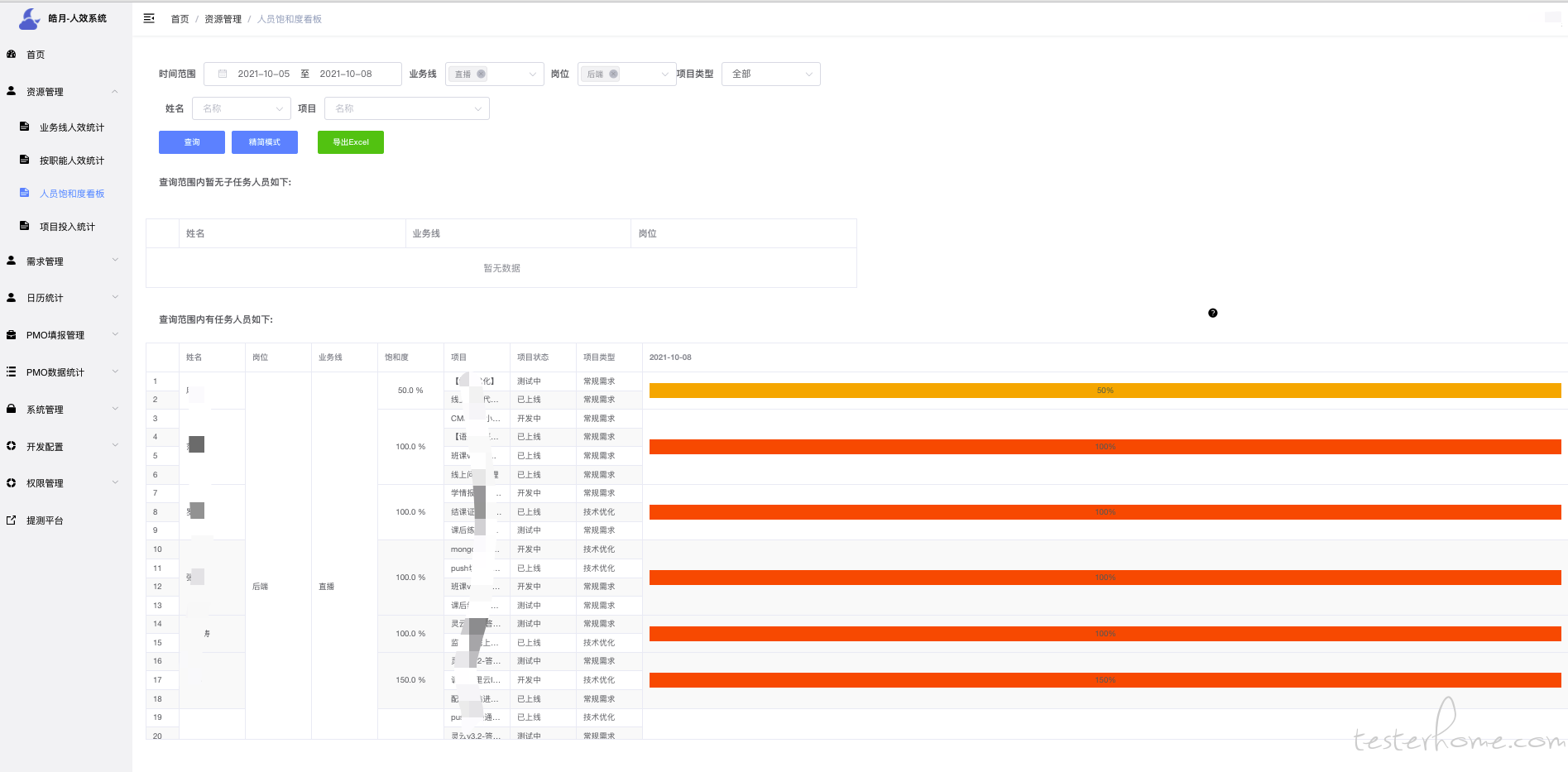
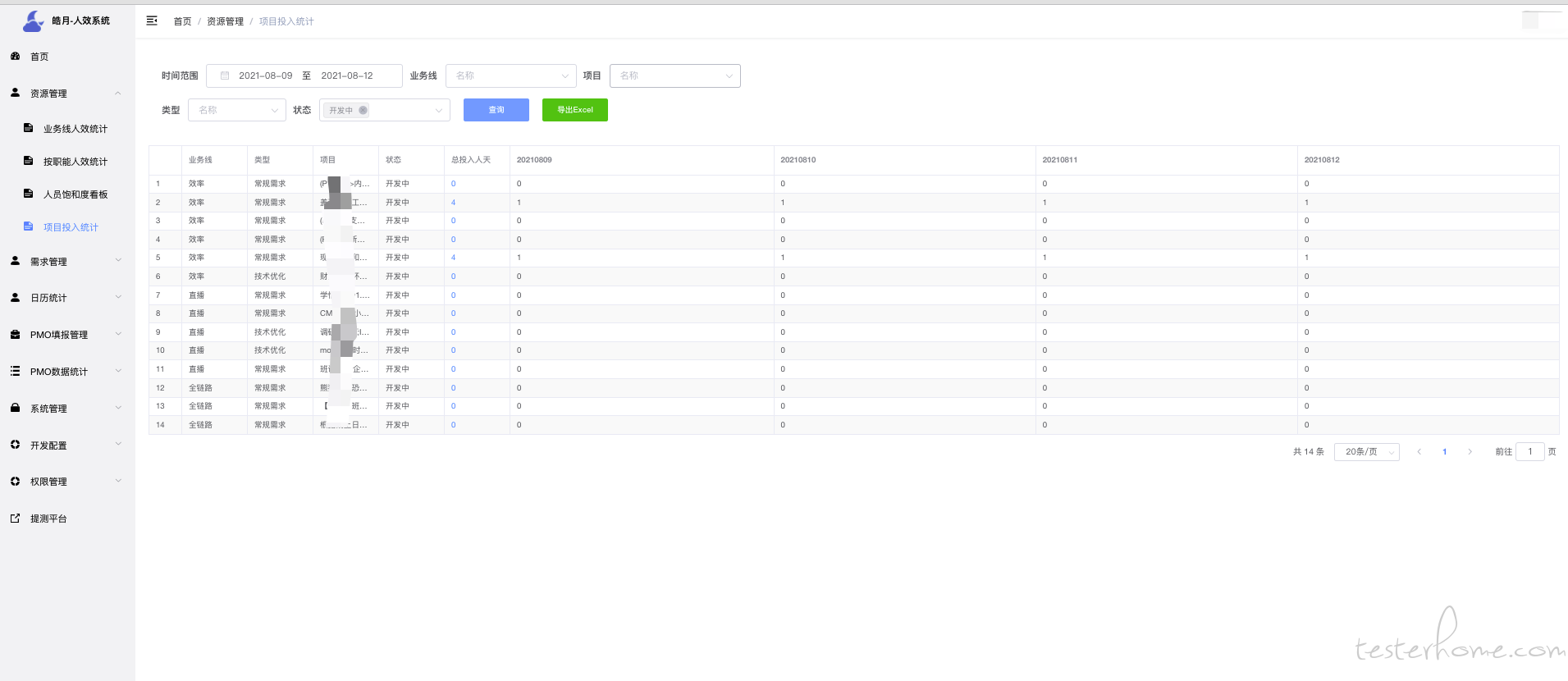
App 发版日历主要想看本次发版的需求,共涉及多少个需求.




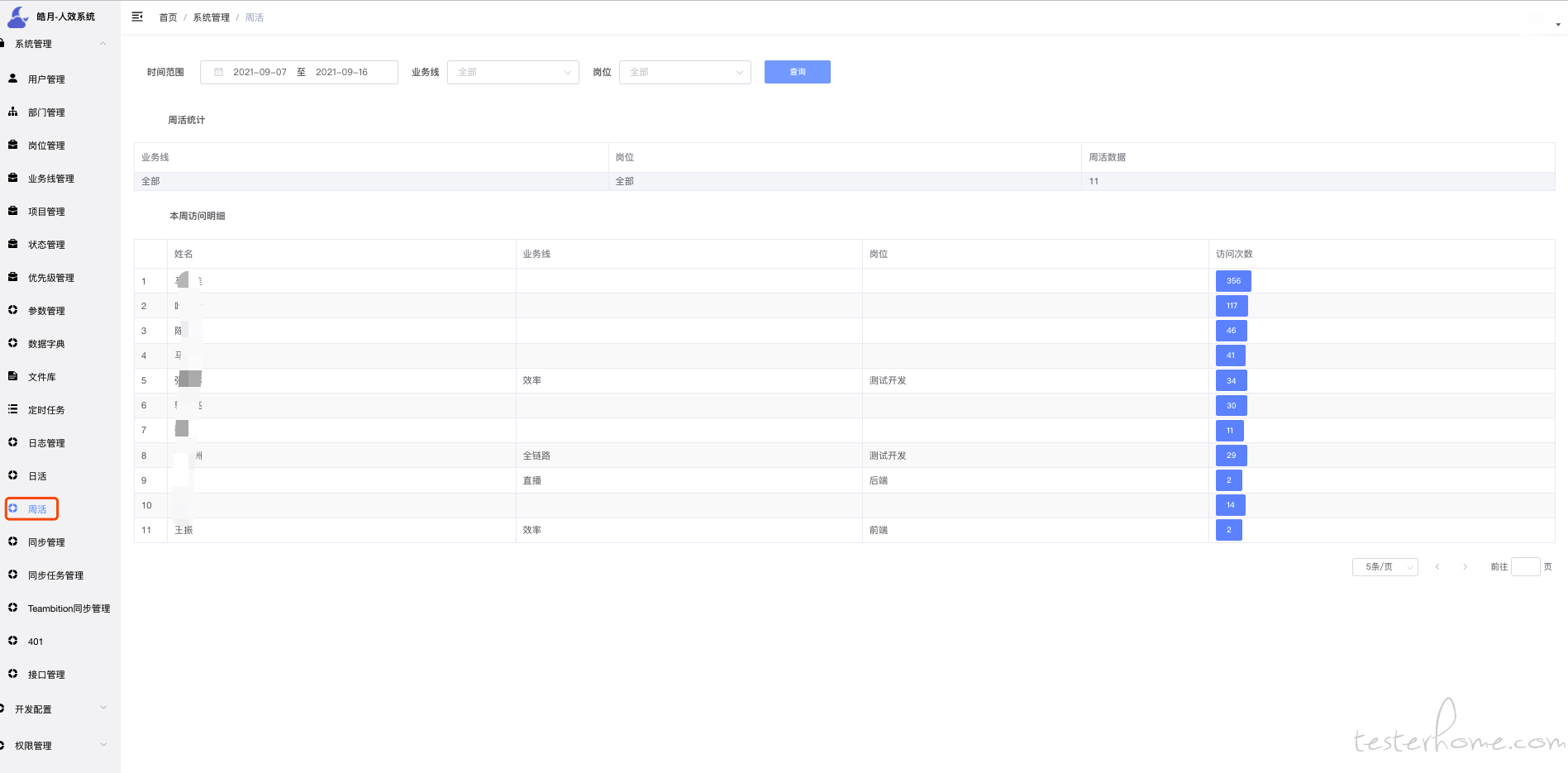
当时有个 OKR 是,想统计我们系统使用率,所以做了埋点数据统计.
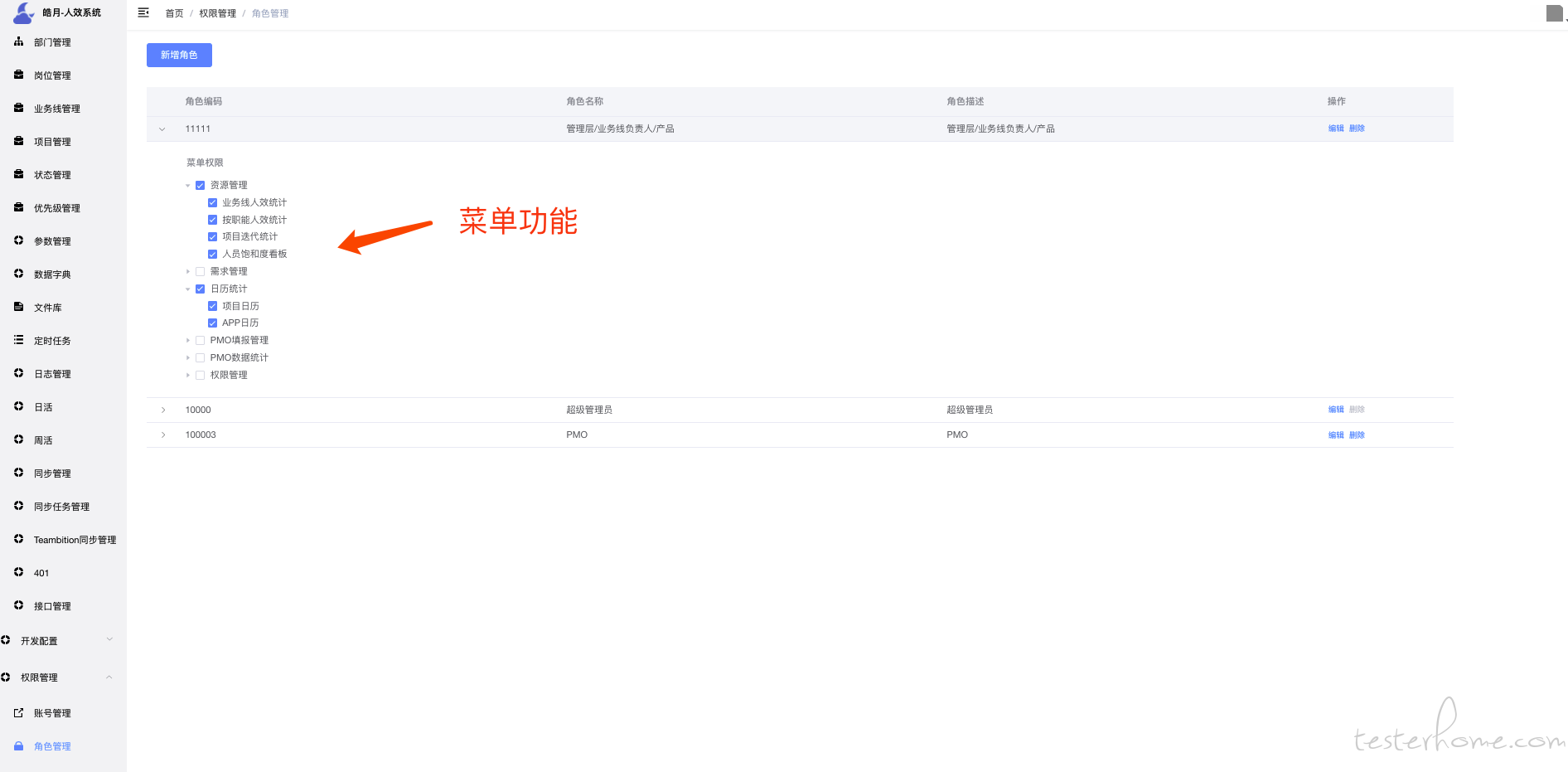
权限管理是通过 vue 动态路由实现和并且结合自定义指令控制按钮权限.
1、每次版本开发前,pmo 会做立项会.
2、每次版本发布前,pmo 会做产品发布会.
3、内部系统一样做好技术文档沉淀.
4、项目完成后做复盘.
5、测试环境和线上环境隔离.
6、内部系统一样提 bug,标明优先级.
有几点用:
1、老板的确很喜欢这种系统
2、通过数字化、图表化,反应研发效率.
3、产品也喜欢看谁有排期.
不好得点:
1、开发很 diss 这个系统,也能明白.
研发效能开发会是未来趋势,大厂都开始自研内部效能系统了并且开始商业化了,为啥大家不计成本开始做研发效能呢,我觉得可能有几点思考:
1、随着自动化测试体系搭建,需要有一套流水线串联自动化测试
2、需求迭代过程产生得数据需要被存储归档
3、项目过程需要被度量
4、通过效能平台打通各个内部系统,串联研发流程.
回到项目管理系统本身,在小公司可能测开就去完成了,但是是否能成一个比较好得产品还是比较难,在大厂会是研发效能去当一个产品迭代开发,服务整体研发团队.从另外一个角度来开,QA 应该从这个研发效能去看问题,这样才能看到更多团队内得问题.
