这个内部的用例管理工具已经 4 年多了,翻 wiki 时正好有当时写的这篇记录——记录了第 1 次写大项目时怎么摸石头过河式的优化用例搜索的过程。
背景
其实很简单,大部分的用例平台都是以树结构去管理的,提供层级去管理(有些工具限制了层级数量)。我们的业务复杂,层级可以很深
而搜索用例肯定是必须的功能,很久之前的工具是以列表的方式展示,出现重名用例时,判断属于哪个业务就不是很方便,当时就决定直接在用例树结构上直接体现搜索结果。
演变过程过程
最初版本:
【整树结构一次性加载】
过渡版本:
【管理页面:子节点异步加载】
【选择页面:整树一次性加载】
【搜索结果:平铺列表展示】
最终版本:
【管理页面、搜索页面整合:子节点异步加载】
【搜索叶子、叶子定位:由后端提供 “预加载了结果的树形结构” 辅助前端定位】
- 最初的方案是为了验证平台的可行性而出的,而且很好的优点:数据量不大时,可以利用 React 框架 “树组件” 中默认提供叶子名称的匹配查询、展开功能直接达到预期功能。
但随着历史用例的导入,用例层级最大能到 10 层,有 14000+ 个目录,用例有 4000+ 个,目录名称 + 用例名称文本大小就 2M,一次整树加载就得 5s;另外此时前端自带的筛选节点功能也卡;例外一点,想利用其他方法去搜索是不支持。
- 过渡版本是为了不影响大家使用,过渡性的改造,先将管理的地方改成子节点异步加载。
- 最终版本是搜索和管理整合在一起,直接在用例树节点上体现搜索结果(展开并展示结果节点树路径),而且保留异步加载的特性(不含搜索结果的目录不加载其下内容),这个需要在后端根据各种搜索结果构造 “预加载结果的异步树” 的接口。
首先节点结构说明:
noteType 标识是目录、文本用例、图表用例、引用用例;
isResult 标识是否搜索结果,前端根据其来用特殊颜色标识出来
isEmpty 标识这个目录是否有子内容
{
"name": "03 某某业务",
"level": 3,
"id": 847,
"noteType": 0,
"isEmpty": false,
"children": [{
"isResult": true,
"noteType": 1,
"id": "$572",
"name": "01 各模块功能入口检查"
}, {
"isResult": false,
"noteType": 1,
"id": "$573",
"name": "02 首页入口检查"
}
]
}
然后需要告诉前端哪些目录需要默认展开
"expandIds": [
"11",
"12"
]
后端处理(python)
所以这里采用了分步的方式实现:先目录去重划分层级,再至上而下遍历生成树(虽然性能稍微差点,但胜在思路更清晰)
第一步:获取每层需要加载下级的目录
1-由各个 sql 查询获得的搜索结果用例,先获取它们的所有目录(id 及 level 的元祖列表),放入【集合 o】中(利用集合特性去重)
2-由集合中的目录再次查询其各自上层目录(id 及 level 的元祖列表),与【集合 o】做差集获取新的集合【集合 t】
3-【集合 t】如为空(没有发现新的目录),结束递归;
否则合并【集合 t】到【集合 o】中,再拿【集合 t】获取其各自上级目录与【集合 o】的差集生成新的【集合 t】,然后重复此过程。
4-针对【集合 o】,通过程序筛选层级,获得各层目录信息
5-在此过程中,从上往下获取了需要展开的目录节点 (expandIds)
第二步:一次性获取上面目录下级节点信息,由程序进行数据筛选:
1-根目录的目录及用例
2-各个需要展开的目录的下级目录及用例
第三步:从根目录开始一层层遍历,加载需要的数据
1-先加载根目录信息
2-依次遍历下层目录,根据目录 id 从筛选出需要加载的下级目录及用例
3-逐层加载构造出需要的树结构
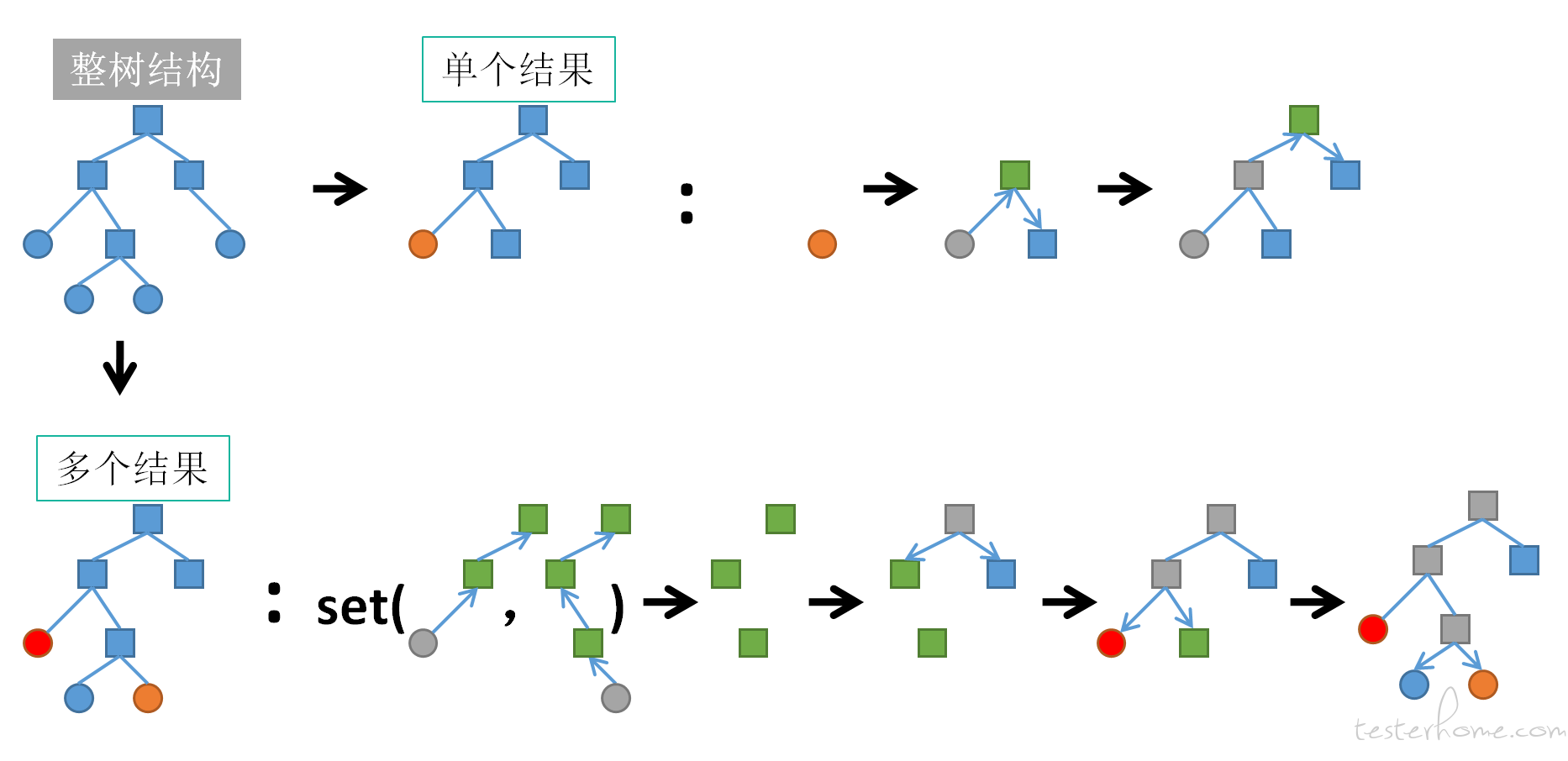
前端处理
前端的小伙伴需要根据后端搜索结果接口生成的 “半整树”,递归渲染节点,比如搜索结果节点标色,目录图标展开或闭合,是否体现空目录.....

↙↙↙阅读原文可查看相关链接,并与作者交流