导读
本为转自,本人之前博客园上的原创。先从云化说起,再谈谈云化形态下,除了常规的功能测试,云化的测试,还需要有几个必须要 get 到的硬核指标,最后在分别详解这些关键点硬核指标是什么,和如何测试呢。这是个值得深思的问题,希望所有测试人都 get 到这些,且比贴子说提到的做得更多,提炼出更多 check point。
先回顾一下云化的掘起之大势
前两年 oracle 裁掉整个中国研发中心,正闹得沸沸扬扬,一关键原因是,oracle 受云计算等新兴技术冲击,自身业务成长乏力甚至下滑,所以更关注成本控制,从而进行战略性人事调整,为云计算腾出更多资源;今天,阿里云已超越微软 Azure,成为仅次于亚马逊 AWS 的世界第二大云计算公司,10 年前在百度和腾讯都不看好的情况下,马云认为云计算是未来,每年投入 1 亿,不知道猴年马月咸鱼翻身的情况下,马云就这样投了王坚的阿里云 10 年,最后真的把马化腾说要 1000 年才做成的事给办了!但是当时全中国没有一家公司愿意投入云计算这种 “虚无缥缈” 的事业中,最艰难的时候,80% 的工程师因各种原因离开了阿里云,十年前的王坚博士,在很多人眼中就是一个不折不扣的 “骗子”。
早期云厂商,主要提供的云资源偏重于 iaas 层,当前随着云计算的深入发展,从 iaas,到 paas ,serverleess 加容器技术,已经成为云厂商标配产品,云化是一个不可逆转的趋势,已被大众所接受,当然受一些非技术因素的限制或是一些历史包袱的限制,混和云,多云和公有云一道将长期存在。越来越多的公司把服务放在云端,小公司可能只是仅仅把服务搬到云端(也就是把先前的本部署,搬到云端),实际上这是不真正的云计算,当然容灾备份能力有质的提升,saas 厂商,或是大厂商,会在云厂商的 pass 平台上,构建一个胶水层, 整合 PAAS 和 SAAS 形成自己的云管理平台,透明实现弹性计算,横向扩展和可视化运维监控等非功能性的管理需求。
云化测试这些非功能性必测的硬核关键点必须 get 到
这些非功能性硬核关键点和云计算的特性有着必然的关系,同时也和服务的可靠性,服务的计量和治理有着密切的关系。简单来说你要保证你的云服务的可靠性,可用性,可管理性,必须具有一些云化后的非功能性指标,因为你业务功能再好用,不可靠,对用户来说是没有保障的,如下 8 个硬核点就是云化的非功能指标,后续一节再分别讲述,这些硬核点的的定义以及如何来测试这些点,特别是第 1,第 2,第 3,这三个缺一不可,否则你的软件只是搬到云端,并不具备任何云计算的特性,也就是假云。
第 1 弹性,也叫自动伸缩;
第 2,服务无状态;
第 3 ,多租户支持;
第 4,故障转移/隔离;
第 5 ,服务限流保护;
第 6 ,应用安全;
第 7 ,调用链追踪,
第 8 ,可视化服务治理(可观测,可自动健康检查,服务优雅关闭等)
用一个示例来说明 8 个硬核点以及测试方法或手段
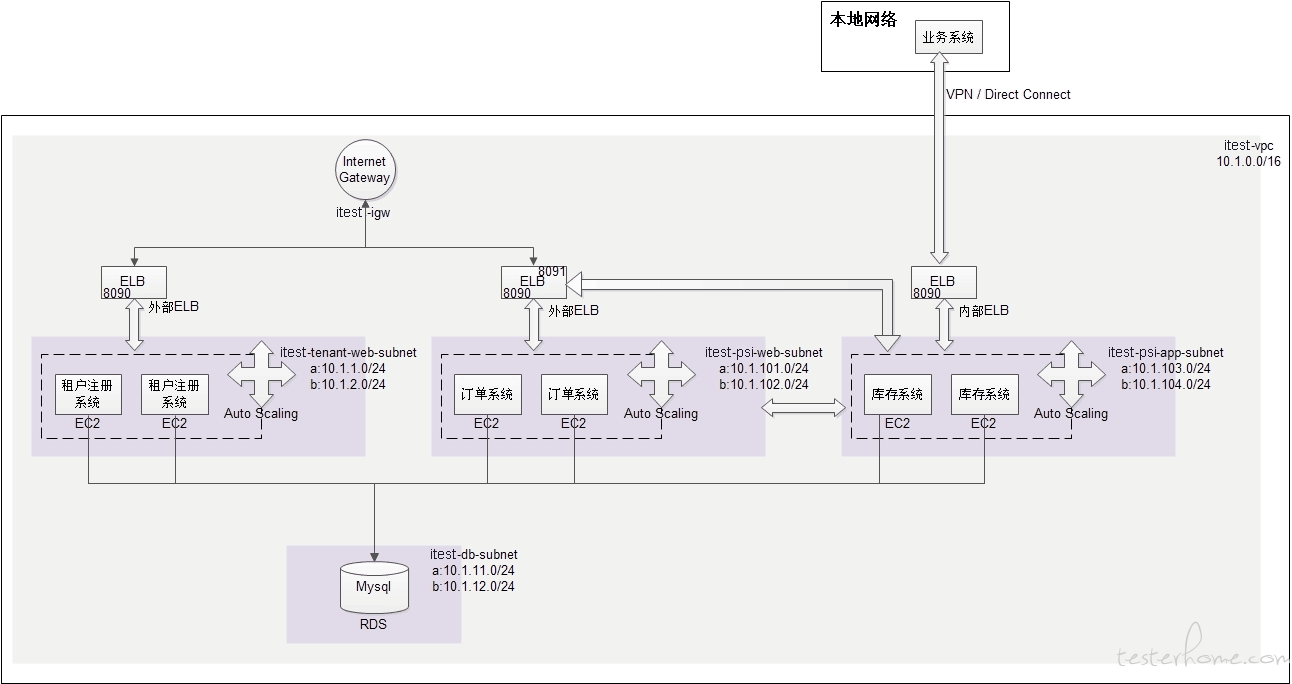
下图是一个在 aws,建一个 VPC 且通过 VPN 和本地服务组成一个混合云的网络架构图,
创建 4 个子网,分别用于部署:租户注册 Web 程序、数据库、进销存 Web 程序、进销存 App 程序;,为了实现高可用性,每种类型的子网按照可用区各创建 a、b 两个。
租户注册成功后,调用 CloudFormation 接口,自动部署的云进销存业务系统。(实际是物理隔离)
再回到前述 8 个硬核指标
第 1 弹性,也叫自动伸缩
说起弹性,先从常说的云服务器,ecs 说起,它就是 Elastic Compute Service 的缩写 ,是一种处理能力可弹性伸缩的计算服务器,这是从 IAAS(更偏硬件资源:CPU,内存,磁盘,网络)层来实现弹性,这解决了硬件或是底层资源的弹性;实际从提供云服务的软件层现来看,还要有软件自身的弹性也就是 saas 或是 paas 层的弹性,例如,需要根据时间或是其他的策略 (基于流量,或是硬件资源的特定基线) 横向扩展,如高峰期,挂号服务需要 10 个节点才能保证支撑高峰期的并发量,非高峰期,再减少挂号服务节点,腾出计算资源做其他事情。在云上,实现集群节点的扩展是很简单的事,配置好扩展策略即可。测试的时候, 必须把弹性作为一个 check point ,如何验证,从前面其定义就能明白,这里就不再重复了。现在问题来了,动态扩的服务,如何让集群感知,且可用呢,请看如下第 2 项
第 2,服务无状态;
接上一个问题,动态扩的服务,如何让集群感知,且可用呢?让集群感知有两个办法,一是服务在横扩的时候,向 ELB(负载均衡)动态注册 (如果扩展了节点,需要手动配置并重启负载均匀相关组件,这不叫弹性),或是通过服务发现注册组件来实现,这有很多成熟的技术,这里就不多说明,重点是,新横扩出来的服务,加到集群后,要让他能对外提供服务,这要求服务是无状态的 ( 比如会话 session ,或其他上下文,不依赖服务所在属主容器,如 tomcat ,jetty,weblogic ,iis 等),否则某个请求被路由到新扩的服务节点时,可能会为因为会话或上下文的问题,导致服务在业务上不可用。测试的时候, 必须把服务无状态作为一个 check point,如果服务实现方,是通过在负载均衡上通过 “ 黏住” 策略,来实现会话共享,的话,有一个大问题,当服务节点减少,或是某些服务节点挂掉时,之前这些服务节的服务的客户端后续的请求,转移到其他节点,session 就会丢失,通常做法是,把 session 或上文下外置在服务线程所在容器 (tomcat ,jetty,weblogic ,iis 等) 之外,如 memcache 中,redis 中。
如何验证这个无服务的检查点呢?假定是一个 Web 程序,通过关闭单一节点,再重启检查,是否为同一个 session。测试这个完全可以在非云环境来验证,用一个单单一节点来测试(非集群模式),比如先登录,进入到某页面,且准备做某个对 session 有依赖的操作,这时,停下正要操作的功能,先停掉这个节点,然后重启这个节点,,重启后再在之前登录的页面上,接着做这前的作操作,并没有提示要重登录,或是 session 过期,操作成功,可以验证;当然也可以用两个节点来验证 (集群模 式),每个节点上,放两个相面的页面,在上面,打印出 session id ,以及节点的名称,先请求这页面,记下打印的 session id 及节点名,关掉任意一个节点,再刷新这页面,看看打印的 session id 一样不,如一样,只是节点名变了,说明服务是无状态的。还有其他方法,这里只是抛砖引玉,提供一下思路。如纯后台 API ,只要检认证信息是否过期,或是是否是同一个认证信息。
第 3 ,多租户支持;
既然是云上的服务,必须要求不同的客户(租户/单位/组织)都能使用,且互不影响,实现多租户,通常有两种隔离方式,逻辑隔离和物理隔离;逻辑隔离指,大家其用一套系统,只是在数据库层在表中加一个字段,数据所属租户;物理隔离,这每个租户单独部一套系统。测试的时候, 必须把多租户支持作为一个 check point,测试方法,通过对隔离的阐述,自然就知道如验证,支不支持多租户,以及是以什么方式隔离。上面示例中,租户注册成功后,调用 CloudFormation 接口,自动部署的云进销存业务系统,这实际是物理隔离。
第 4,故障转移/隔离;
云服务,一定会有出故障的时候,为了保政故障产生的影响最小,必须有应对故障的策略,故障转移也分两个层面的,,一个是 IAAS 层的,一个是业务服务自身的故障转移。如整个系统宕机,或是有故障,利用镜像,自动重新实例化一个实例,只是网络属性未变,这是 IAAS 层面的,在 PAAS 看来,实际是和之前是无差别的,相当于,传统方式下,快速启用冗余或备用的服务器、系统、或者硬件接替它们工作;另一个是软件层面,业务服务系统,在服务不可用时,支持的重试逻辑,同时支持重试,就要求保持幂等性(简单说,对同一个数据做同一个操作,做一次和做 N 次,结果是一样的),或对出错的服务进行隔离,不隔离会引发雪蹦效应,或是采用服务降低的错施。一句话,测试的时候, 必须把故障转移/隔离作为一个 check point, IAAS 层的转移,只需向云厂商确认即可,基本上云厂商这层面都已实现,软件方面的故障处理,需要根据隔离策略来执行相应的测试,细节具体根据具体应用再详查,主要是不要漏过这个测试点。
第 5 ,服务限流保护;
既然是公有云,面向的是所有你的客户,某些情况下,访问量会爆增,或是受到恶意的访问攻击,这时服务的可靠性,隐定性也必须得到保障,通过对并发访问/请求进行限制或者一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务或者排队等待,从而使服务不会引过多的访问而崩溃,这就是限流。
测试方法,通过压测,或是增加到并发量,到系统支持的极限后,系统有没有因访问量太大而崩溃。测试的时候, 必须把服务限流保护作为一个 check point
第 6 ,应用安全;
服务放云上,面向整个互连网,除了要应对恶意的攻击,还要防止服务器被劫持,还要保证数据安全,和授权内访问等等,安全是一个很专业的一个方向,测试的时候, 也必须把安全作为一个 check point, 测试人员在这方面,只能做一些常规的安全测试,如 SQL 注入,XSS 跨站攻击,敏感信息是否明文传输, API 的访问是否要通过验证,一些等存级别高的业务,还需要双向认证,甚至实名认证等,其他的则需要请专业的安全公司进行全面的安全测试,他们能扫描出系统存在的安全漏洞和不安全的因素,并给出好的整改建议。
第 7 ,调用链追踪,
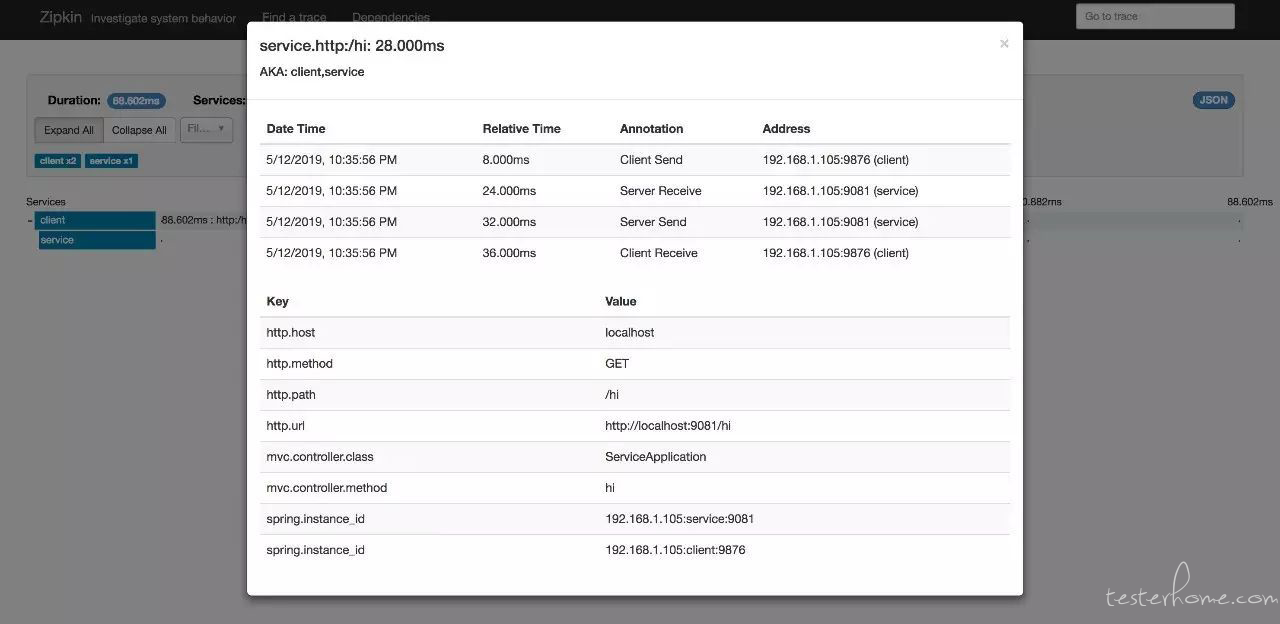
这要看服务是否是一个分布式应用,分布式应用中,系统存在互相调用的情况,形成一个 调用链,通常一个请求,会引发 A 组件,调用 B,组件,B 组件调用 C ,C 调用 D,可能还有更长的调用链,实话说,调用链追踪,有点偏向于运维,在测试时,分布式环境下,不借助调用链追踪有些问题根本没法定位,比如说,某个请求出错了,实际是错调用链的哪个节点上,或是某个功能很慢,慢在哪,不借助于调用链追踪,你都没办法跟程序,就算让研发自己打断点,也要搞死人的,分布式加集群,同一个服务,每次调用时,调用链都可能不一样。上云的应用,通常是分布式用,作为测试人员,也有必要把调用链追踪作为一个 check point,才能在分布式场景下,提出定位更准,更专业的问题,而不只在 BUG 的表像上。开源调用链追踪有 zipkin,pinpoint,skywalking 等。调用链跟踪需要研发那边来集成,测试这边要 get 到这个点和会使用。下图是昨天用 zipkin 的一个截屏示例
第 8 ,可视化服务治理(可观测,可自动健康检查,服务优雅关闭等)
服务治理,也是偏运维的东东,他自身的定义,各位可以自行百度;在这里,我只简单场景上来说明,服务治理的大概意思,你的服务在云上,可靠性要有保障,主要在于预防,不能抓瞎,真正问题发生了,就炸锅了,需要通过可视化的方式,观测到服务的状态,健康状态,流量情况,响应速度,并发量,资源使用情况等,并根据于些,采用自动或半自动的方式启动弹性扩展,或是采取隔离,熔断等措施,以保障服务的可用性。在 devOps 大行其道的当下,测试人员向运维多靠一点不是坏事,会给测试提供更多灵感和带来更多测试手段。云上的服务。服务优雅关闭,顺带提一下,要关闭某个服务时,正在服务中运行相关业务线程会同进被关掉,也就意味着这些业务操作肯定要失败,与之相反服务优雅关闭,指在关闭前,他会拒绝新的进求进来,同时要完成当前的所有业务后,才关闭,有点像银行的窗口,不接受业务了,但要把当前正办理的业务处理完。测试人员以此作为一个 check point ,可用来验证云服务实现水平的高低,又能为服务的可靠性测试提代相关测试手段/方法,这个点也要 get 到。
总结来说,就是测试云上应用,除了业务功能自身的测试,还要测试上述提到的 8 个非业务功能硬核点,特别是前 3 点,是区分真云,假云最关键点;云化绝对是不可你逆转的趋势,测试人的相关观念也要以时具进,才能跟上发展的需要。当然个人水平有限,认知有限,论述后可能会存在偏颇之处,欢迎拍砖和补充。
