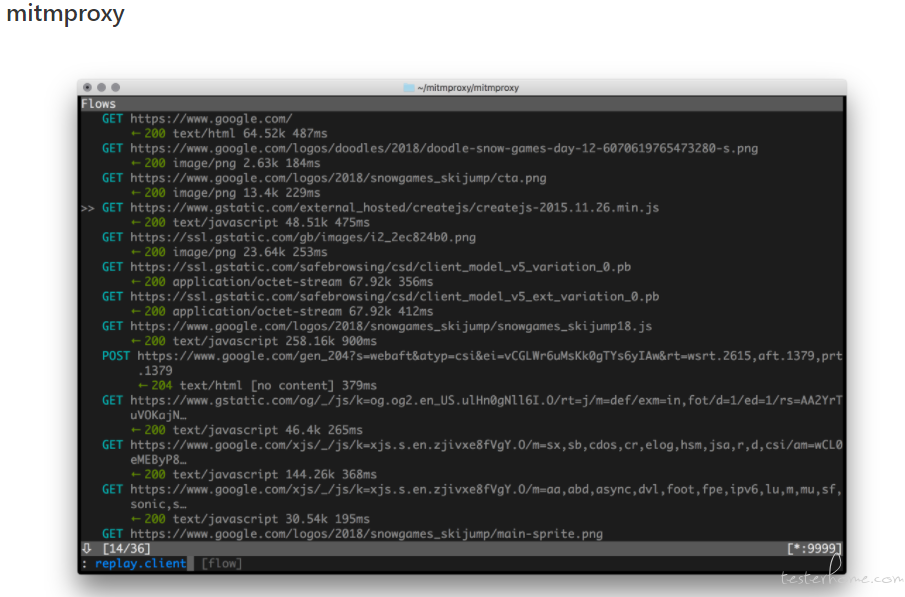
结合之前使用 httprunner 工具,接口转化脚本还是不方便,目前在用的抓包工具 Fiddler,Charles 去导出 har 包生成脚本,比较麻烦。一直在想通过一种更便捷的方式去生成 httprunner 脚本或者找到一款抓包工具能达到一键生成脚本的方式。
看了很多抓包工具,如阿里开源的 anyproxy,可以高度定制的代理服务器,基于 nodejs,无奈 js 不是很熟悉,又在网上看到了 mimtproxy,它是一款免费、开放的交互式 HTTPS 代理工具,基于 Python,决定试试看。
先比较下 mitmproxy 与 Fiddler、Charles:
相同点:
都是用来捕获 HTTP,HTTPS 请求的(其他协议比如 TCP,UDP,IP,ICMP 等就用 Wireshark)抓包、断点调试、请求替换、构造请求、模拟弱网等
不同点:
Fiddler 只能运行在 Windows 系统;Mitmproxy、Charles 是跨平台的,可运行在 Windows、Mac 或 Linux 系统等。Fiddler、Mitmproxy 开源免费、Charles 是收费的(可破解)。mtmproxy 支持命令行交互模式、GUI 界面,Fiddler、Charles 仅支持 GUI 界面
安装
pip install mitmproxy
使用
mitmproxy 提供了三个命令,启动模式不同:
mitmdump : 提供一个简单的终端输出。
mitmweb : 提供一个浏览器界面。
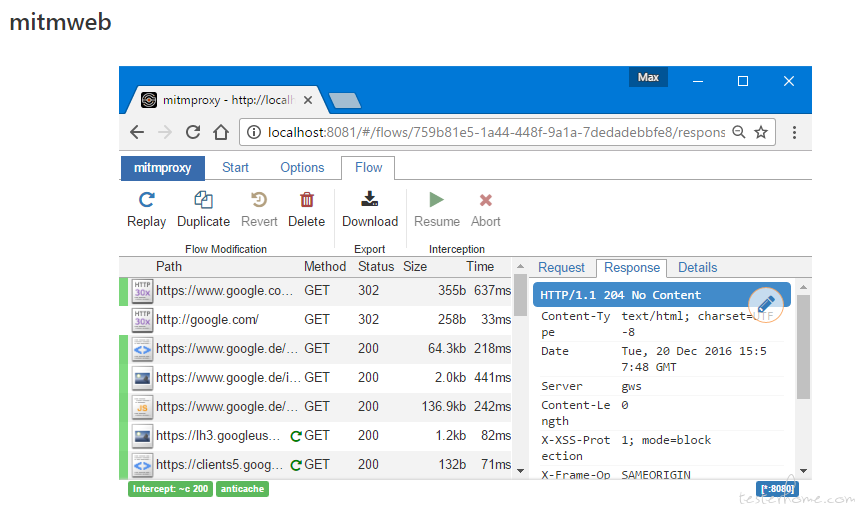
使用蛮简单,推荐看下 bilibili 上的 mitmproxy 视频和官方文档
第一阶段
通过脚本启动 mimtdump,开启代理服务,然后将每个请求的 flow 转化成 har 格式数据,打印出来。
这一阶段主要是了解 mimtproxy flow 对象并从其中获取想要的数据,然后是通过脚本启动代理服务,方便后续集成到其他地方。
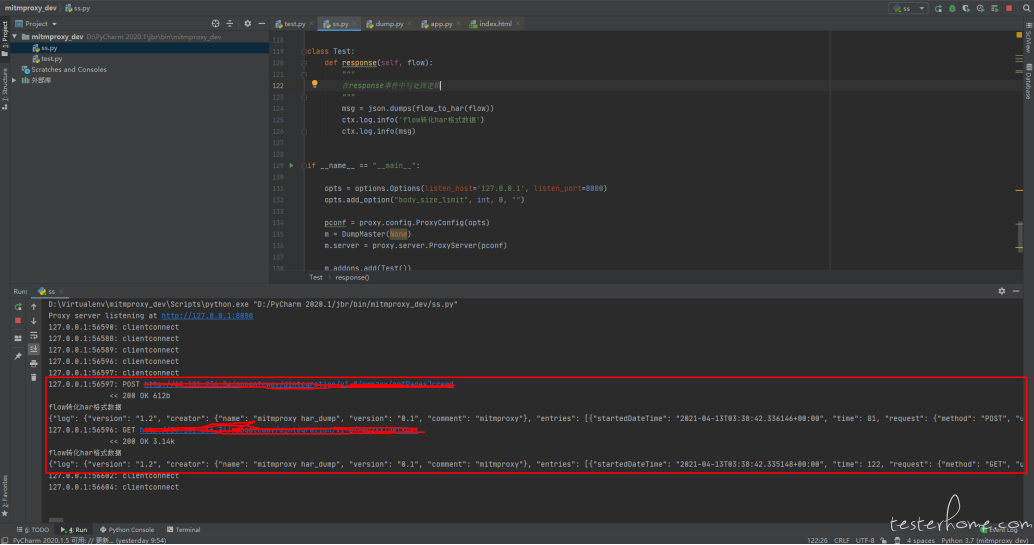
下面的脚本可以直接运行,会在本地 8080 启动代理服务,控制台会打印转化后的 har 格式数据。
注意:电脑要开启本地代理服务,关闭电脑上的其他 VPN。(我是 web 端的)
import json
from datetime import datetime
from datetime import timezone
from mitmproxy import proxy, options
from mitmproxy import ctx
from mitmproxy.tools.dump import DumpMaster
def flow_to_har(flow):
'''
将flow转换成har格式数据
'''
def fromat_cookies(l):
return [{'name': i[0], 'value': i[1]} for i in l]
def name_value(obj):
return [{"name": k, "value": v} for k, v in obj.items()]
HAR = {}
HAR.update({
"log": {
"version": "1.2",
"creator": {
"name": "mitmproxy har_dump",
"version": "0.1",
"comment": "mitmproxy"
},
"entries": []
}
})
ssl_time = -1
connect_time = -1
if flow.server_conn and flow.server_conn:
connect_time = (flow.server_conn.timestamp_tcp_setup -
flow.server_conn.timestamp_start)
if flow.server_conn.timestamp_tls_setup is not None:
ssl_time = (flow.server_conn.timestamp_tls_setup -
flow.server_conn.timestamp_tcp_setup)
timings_raw = {
'send': flow.request.timestamp_end - flow.request.timestamp_start,
'receive': flow.response.timestamp_end - flow.response.timestamp_start,
'wait': flow.response.timestamp_start - flow.request.timestamp_end,
'connect': connect_time,
'ssl': ssl_time,
}
timings = {
k: int(1000 * v) if v != -1 else -1
for k, v in timings_raw.items()
}
full_time = sum(v for v in timings.values() if v > -1)
started_date_time = datetime.fromtimestamp(flow.request.timestamp_start, timezone.utc).isoformat()
response_body_size = len(flow.response.raw_content) if flow.response.raw_content else 0
response_body_decoded_size = len(flow.response.content) if flow.response.content else 0
response_body_compression = response_body_decoded_size - response_body_size
entry = {
"startedDateTime": started_date_time,
"time": full_time,
"request": {
"method": flow.request.method,
"url": flow.request.url,
"httpVersion": flow.request.http_version,
"cookies": fromat_cookies(flow.request.cookies.fields),
"headers": name_value(flow.request.headers),
"queryString": name_value(flow.request.query or {}),
"headersSize": len(str(flow.request.headers)),
"bodySize": len(flow.request.content),
},
"response": {
"status": flow.response.status_code,
"statusText": flow.response.reason,
"httpVersion": flow.response.http_version,
"cookies": fromat_cookies(flow.response.cookies.fields),
"headers": name_value(flow.response.headers),
"content": {
"size": response_body_size,
"compression": response_body_compression,
"mimeType": flow.response.headers.get('Content-Type', '')
},
"redirectURL": flow.response.headers.get('Location', ''),
"headersSize": len(str(flow.response.headers)),
"bodySize": response_body_size,
},
"cache": {},
"timings": timings,
}
entry["response"]["content"]["text"] = flow.response.get_text(strict=False)
if flow.request.method in ["POST", "PUT", "PATCH"]:
params = [
{"name": a, "value": b}
for a, b in flow.request.urlencoded_form.items(multi=True)
]
entry["request"]["postData"] = {
"mimeType": flow.request.headers.get("Content-Type", ""),
"text": flow.request.get_text(strict=False),
"params": params
}
if flow.server_conn.connected:
entry["serverIPAddress"] = str(flow.server_conn.ip_address[0])
HAR["log"]["entries"].append(entry)
return HAR
class Test:
def response(self, flow):
"""
在response事件中写处理逻辑
"""
msg = json.dumps(flow_to_har(flow))
ctx.log.info('flow转化har格式数据')
ctx.log.info(msg)
if __name__ == "__main__":
opts = options.Options(listen_host='127.0.0.1', listen_port=8080)
opts.add_option("body_size_limit", int, 0, "")
pconf = proxy.config.ProxyConfig(opts)
m = DumpMaster(None)
m.server = proxy.server.ProxyServer(pconf)
m.addons.add(Test())
try:
m.run()
except KeyboardInterrupt:
m.shutdown()
界面化
稍微修改脚本,用 mitmweb 替换 mitmdump 启动服务。
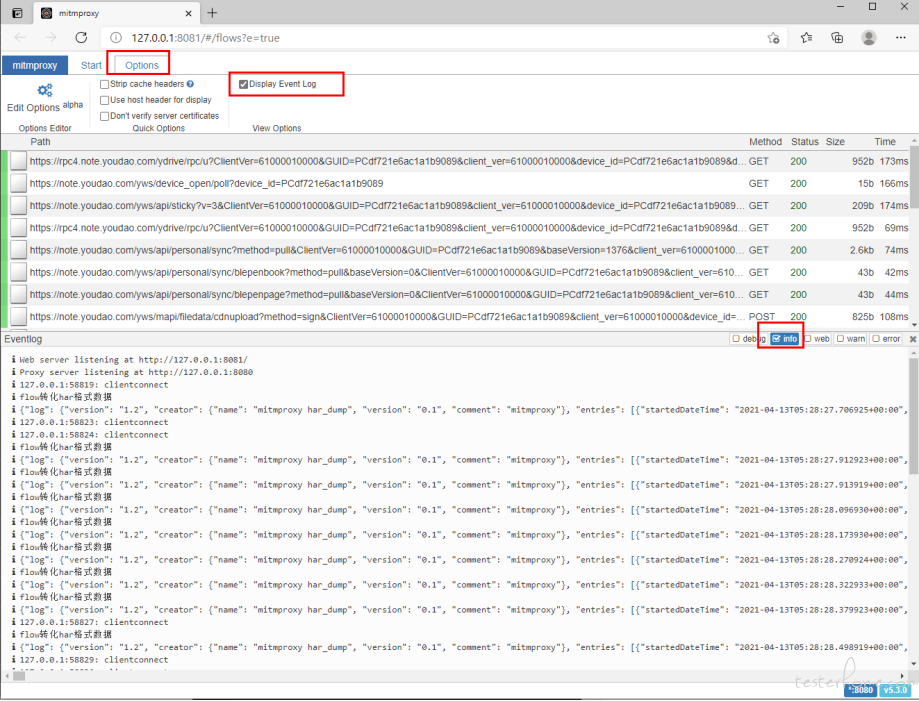
这时会启动在 8080 启动代理服务,在 8081 开启 web UI 的服务。
在 UI 工具的 eventlog 里面会展示 各种级别的 log 信息。脚本里面的 har 数据是用 info 级别打印的,也会展示在里面
if __name__ == "__main__":
from mitmproxy.tools.web.master import WebMaster
opts = options.Options(listen_host='127.0.0.1', listen_port=8080)
opts.add_option("body_size_limit", int, 0, "")
pconf = proxy.config.ProxyConfig(opts)
m = WebMaster(None)
m.server = proxy.server.ProxyServer(pconf)
m.addons.add(Test())
try:
m.run()
except KeyboardInterrupt:
m.shutdown()
第二阶段
har 数据能解析出来了,但是在日志窗口打印,没有过滤,也不易用。尝试在 ui 界面上做一些修改。
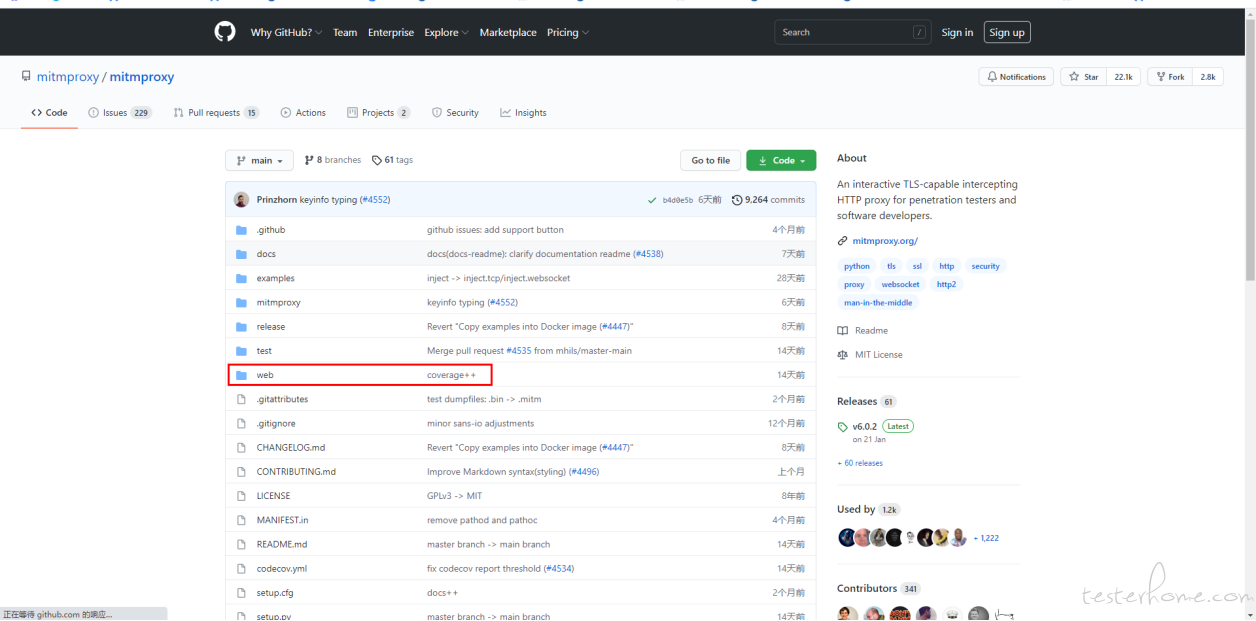
它 webUI 界面是 react+tornado 写的
前端源码
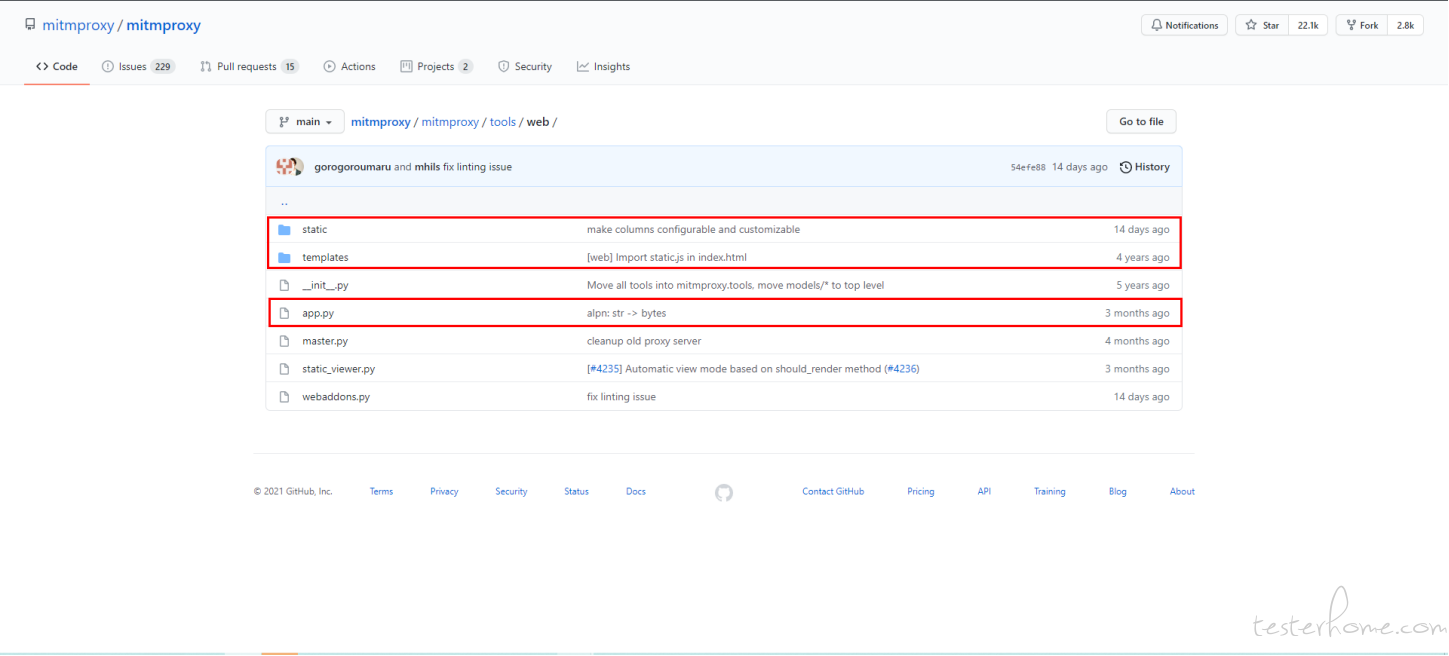
后端源码
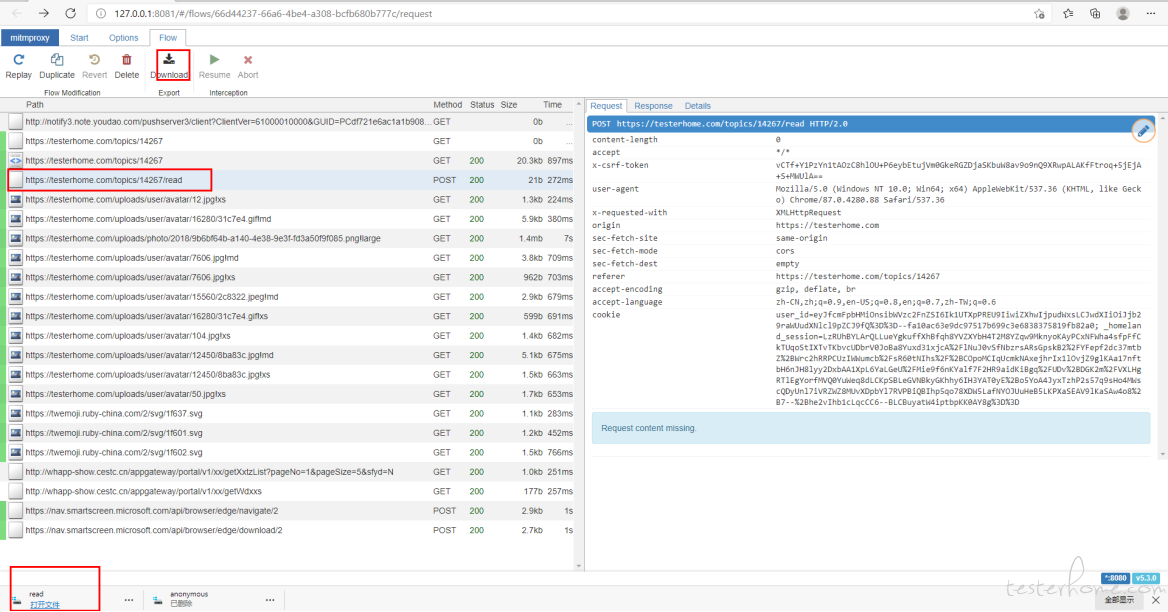
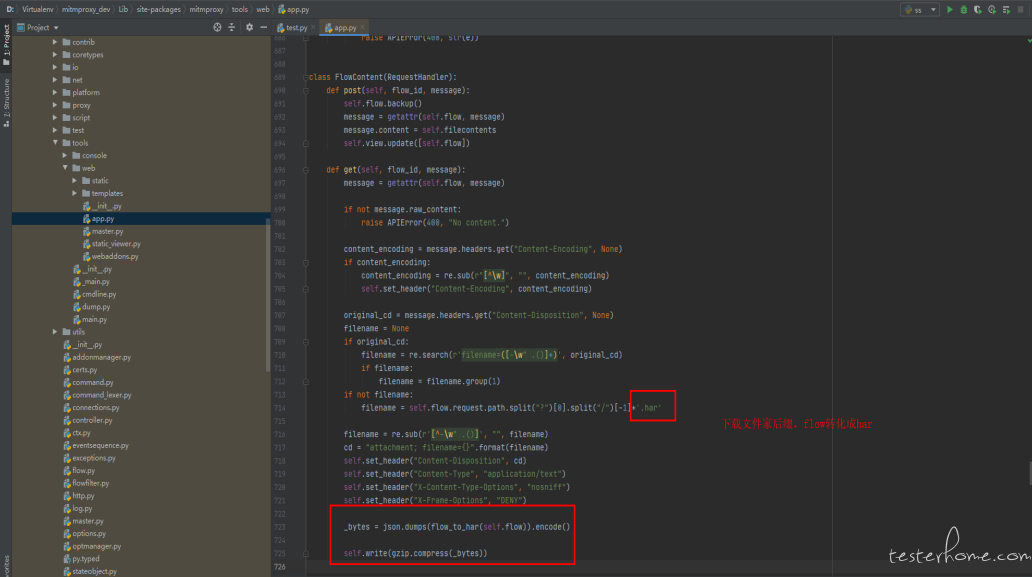
修改一:mimtweb 有个下载的按钮,点击后下载的是 response 的数据。尝试把它改造下,改成下载 har 包。
前端服务修改:
web 目录是前端的源码,复制到本地,在根目录执行
cnpm install
源码中全局搜索 Download 的文本找到这个按钮的代码,改成 DownloadHar。
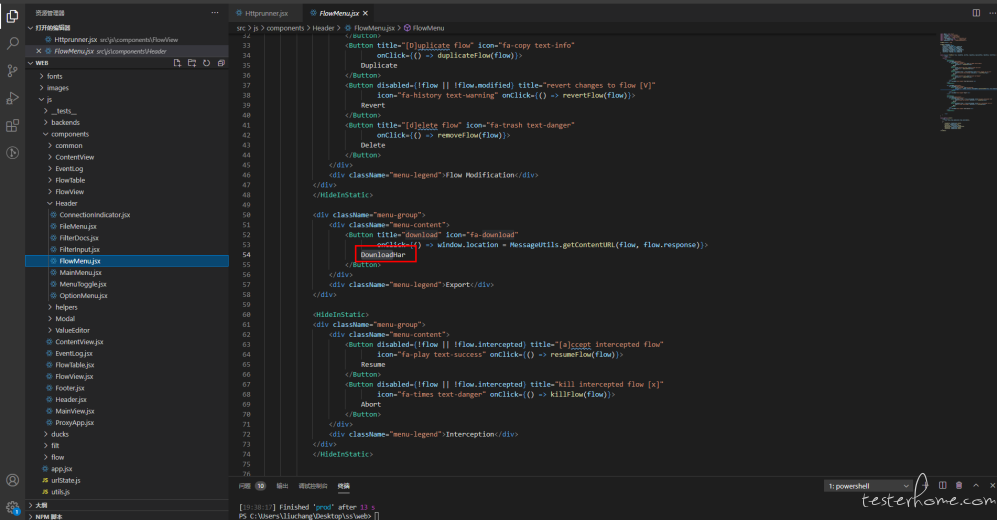
后端服务修改:
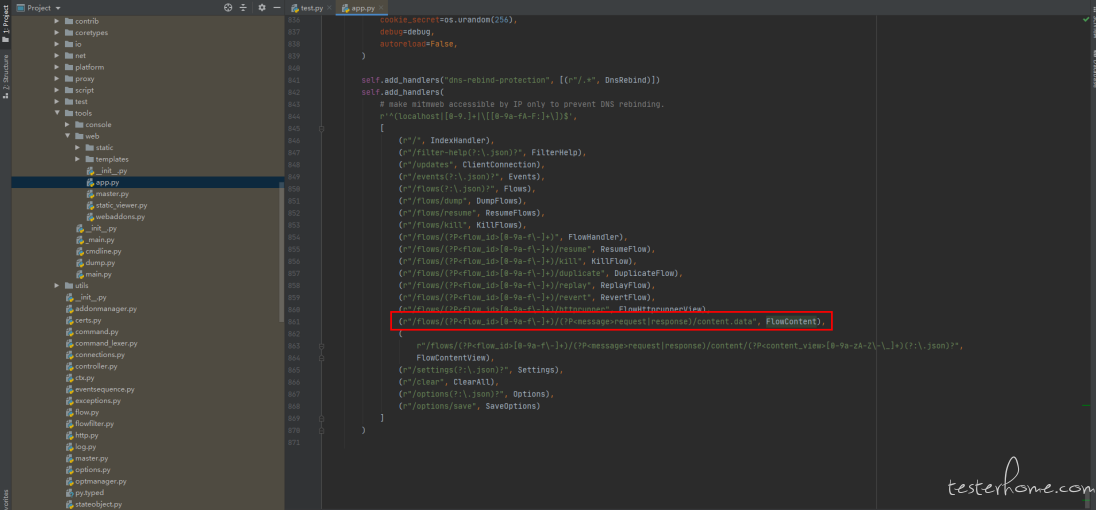
点击按钮触发的后台接口逻辑。F12 查看接口的请求地址,查找该地址的后端方法
xx\mitmproxy\tools\web\app.py 文件中
修改完毕,前端打包
npm run build
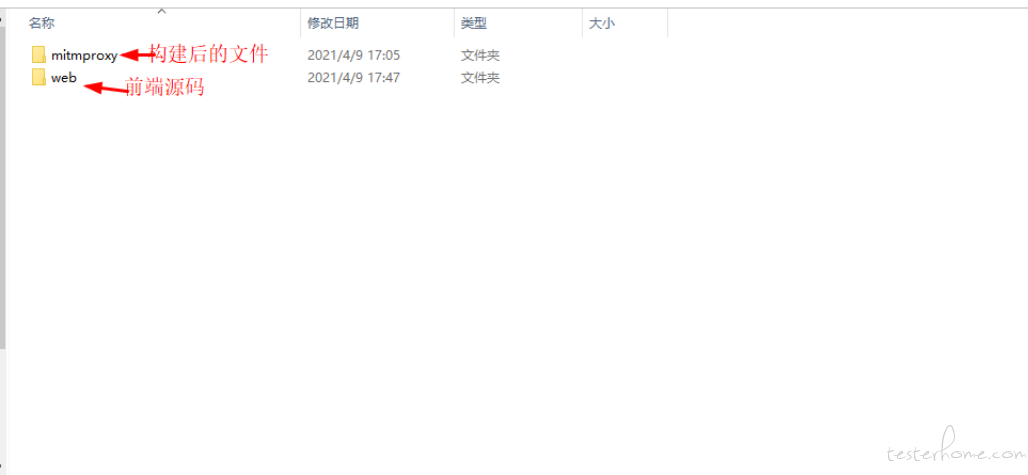
构建完成后会在根目录外层生成一个 mitmproxy 目录,将构建后的包放到 python 虚拟环境的 mimtproxy 库 web 目录中覆盖之前的。
重新启动服务,刷新浏览器缓存。查看页面
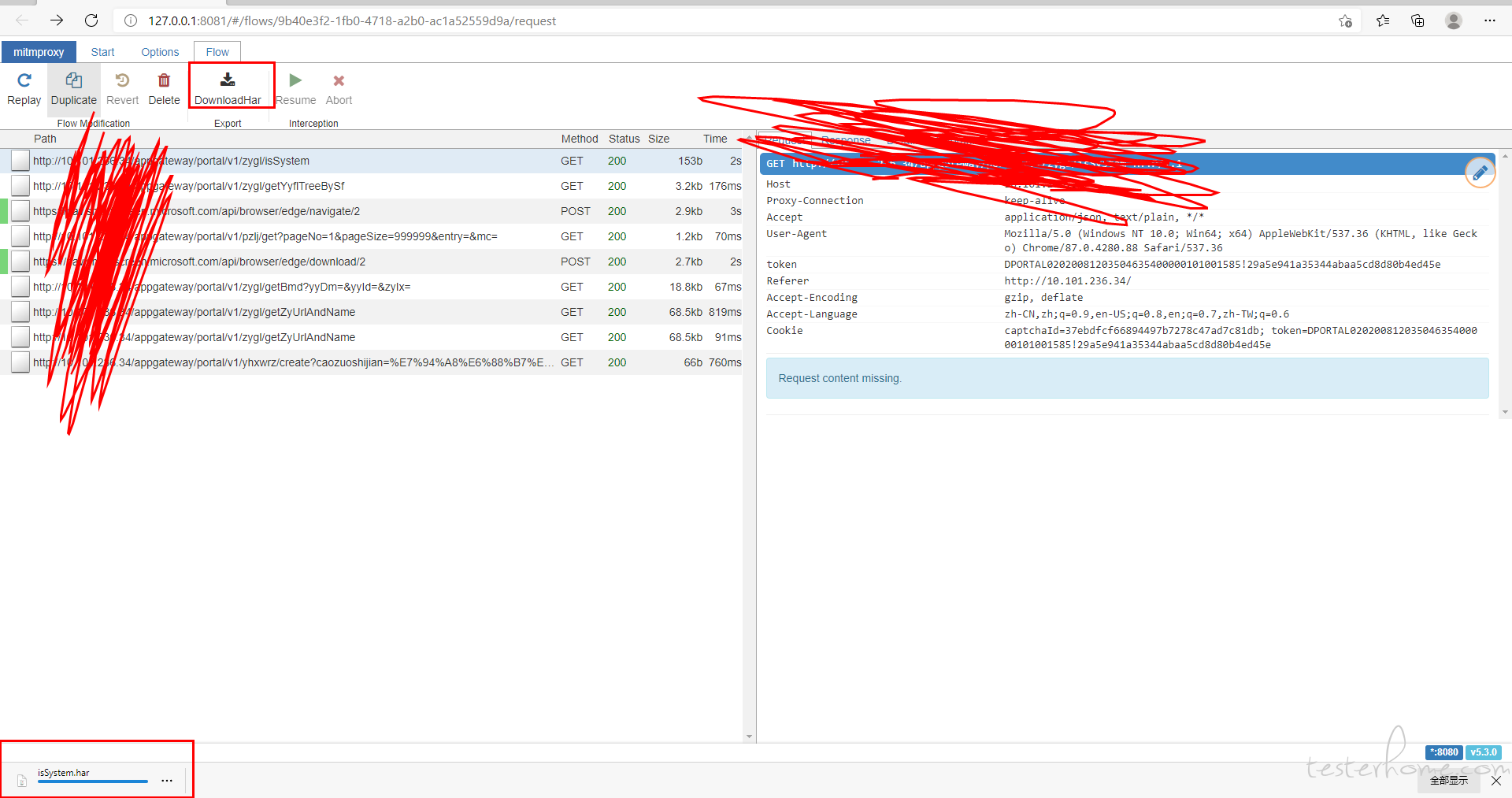
修改二:前端界面加上 tab 页,可以直接看 httprunner 脚本。
前端服务修改:
增加 httprunner 组件,增加 Httprunner tab 页,增加复制按钮。
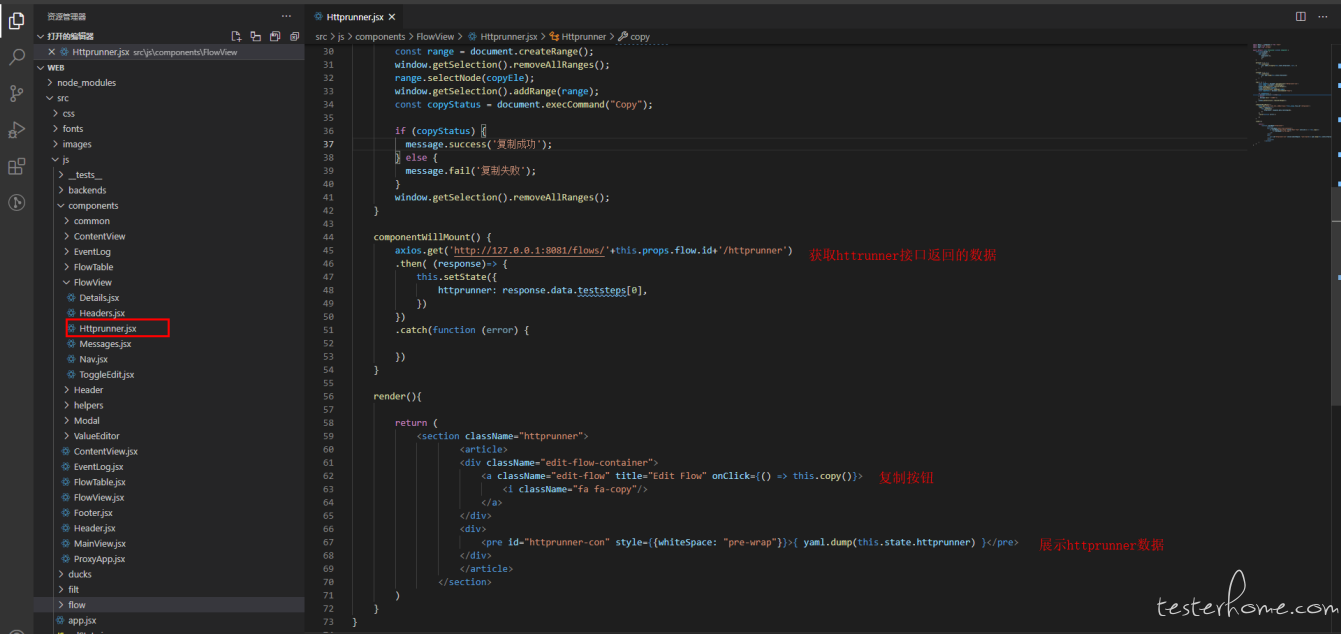
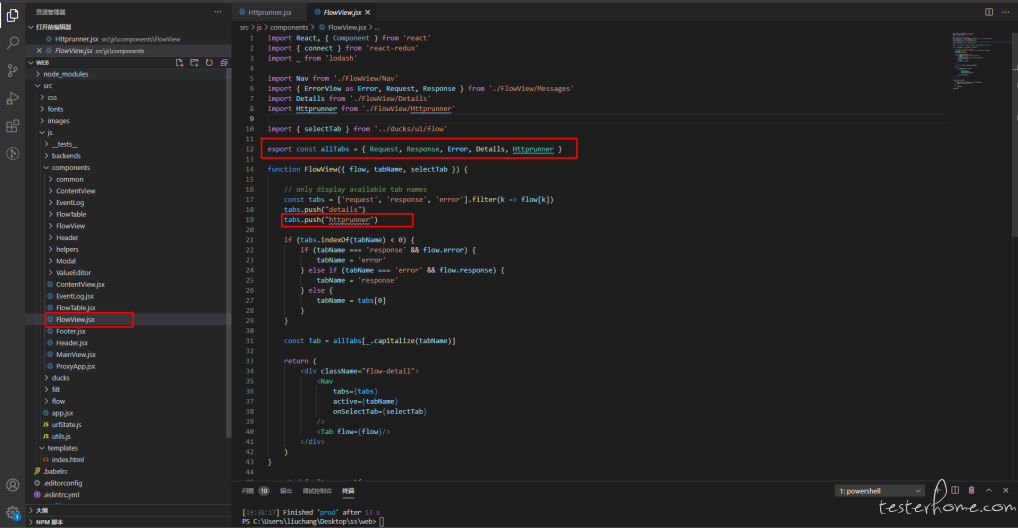
后端服务修改:
xx\mitmproxy\tools\web\app.py 文件中
添加一个接口,HarParser 是用的 httprunner har2case 库 稍微做了改动
class FlowHttprunnerView(RequestHandler):
def get(self, flow_id):
har_pars = HarParser(flow_to_har(self.flow))
httprunner = har_pars.make_testcase()
self.write(httprunner)
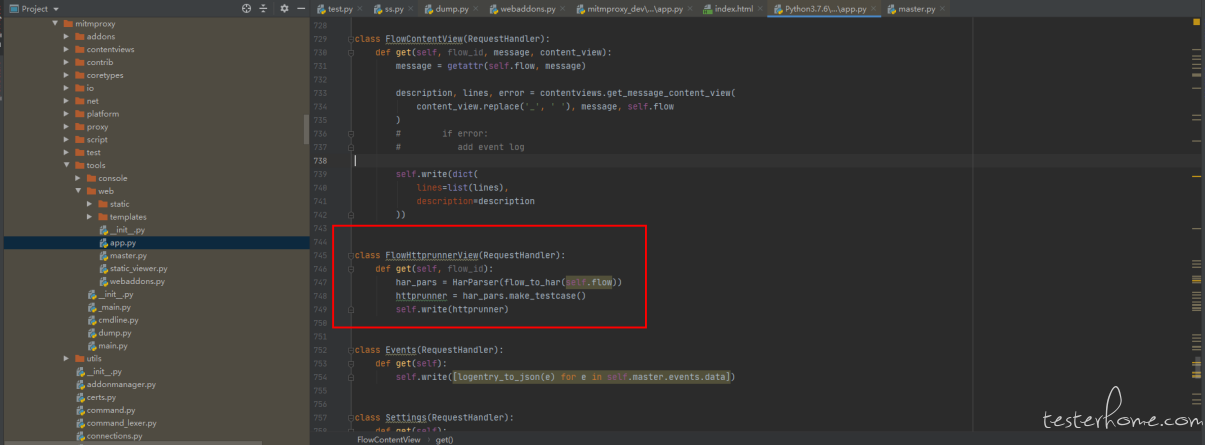
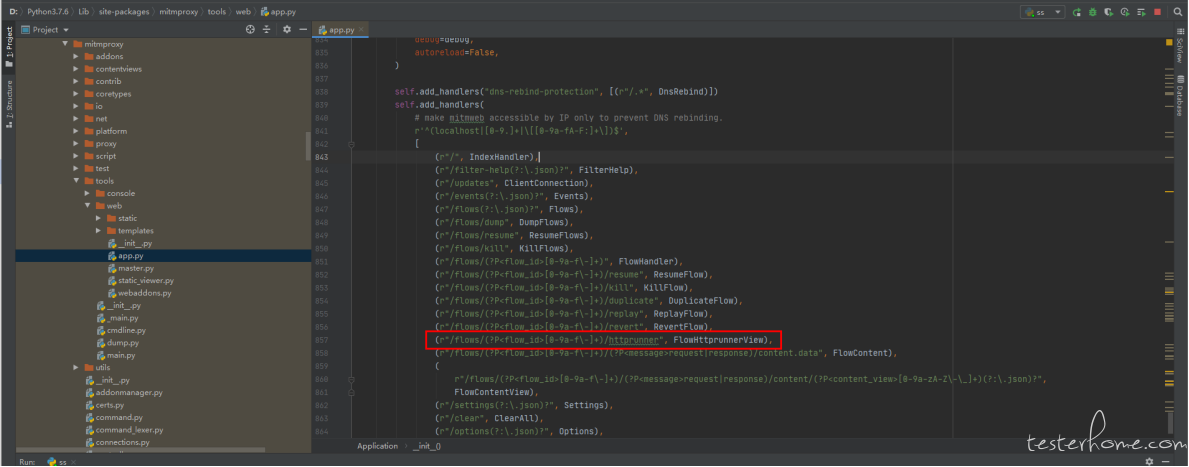
配置一个路由,每个抓到的接口都有一个 flow_id,通过 flow_id 去获取 flow
(r"/flows/(?P<flow_id>[0-9a-f\-]+)/httprunner", FlowHttprunnerView)
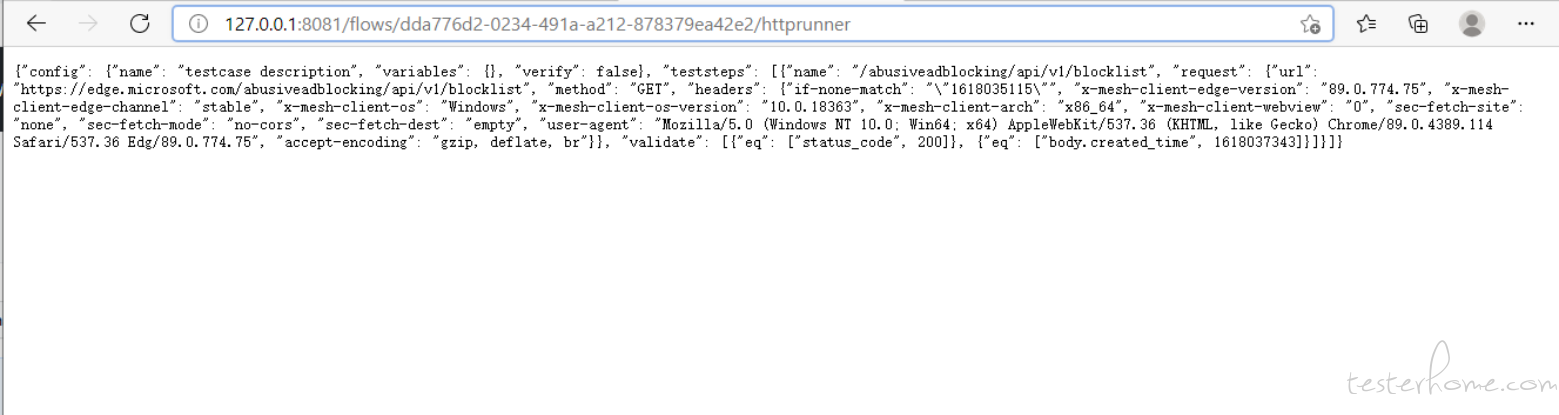
验证接口
修改完毕,前端打包
npm run build
构建完成后会在根目录外层生成一个 mitmproxy 目录,将构建后的包放到 python 虚拟环境的 mimtproxy 库 web 目录中覆盖之前的。
重新启动服务,刷新浏览器缓存。查看页面
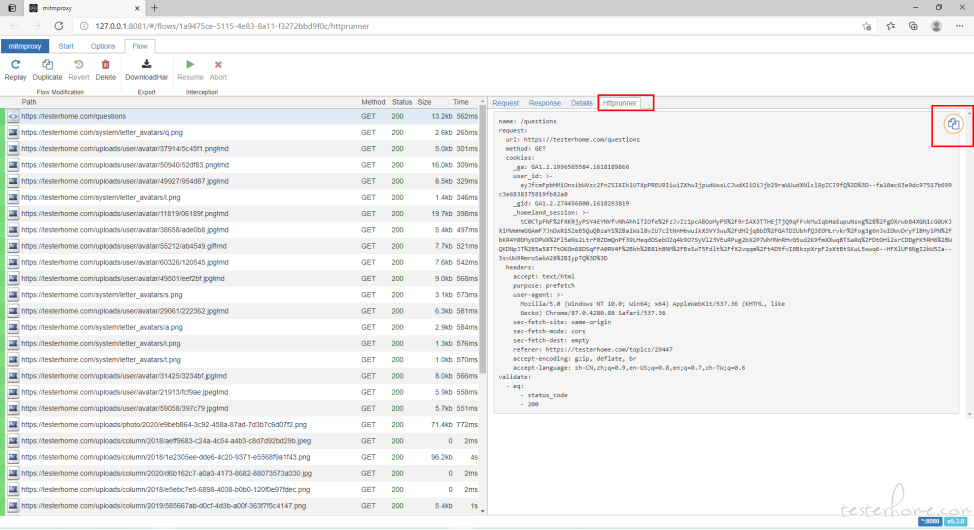
第三阶段
和自己的工具对接,一键生成 httprunner 脚本,前面的都调通了,前端就是再增加一个按钮,对接的工具写一个接口,点击按钮就把当前请求的 httprunner 数据发送个对接工具,转化成工具上的脚本。
现有工具对接,点击按钮,选择 poc3 的项目发送脚本。
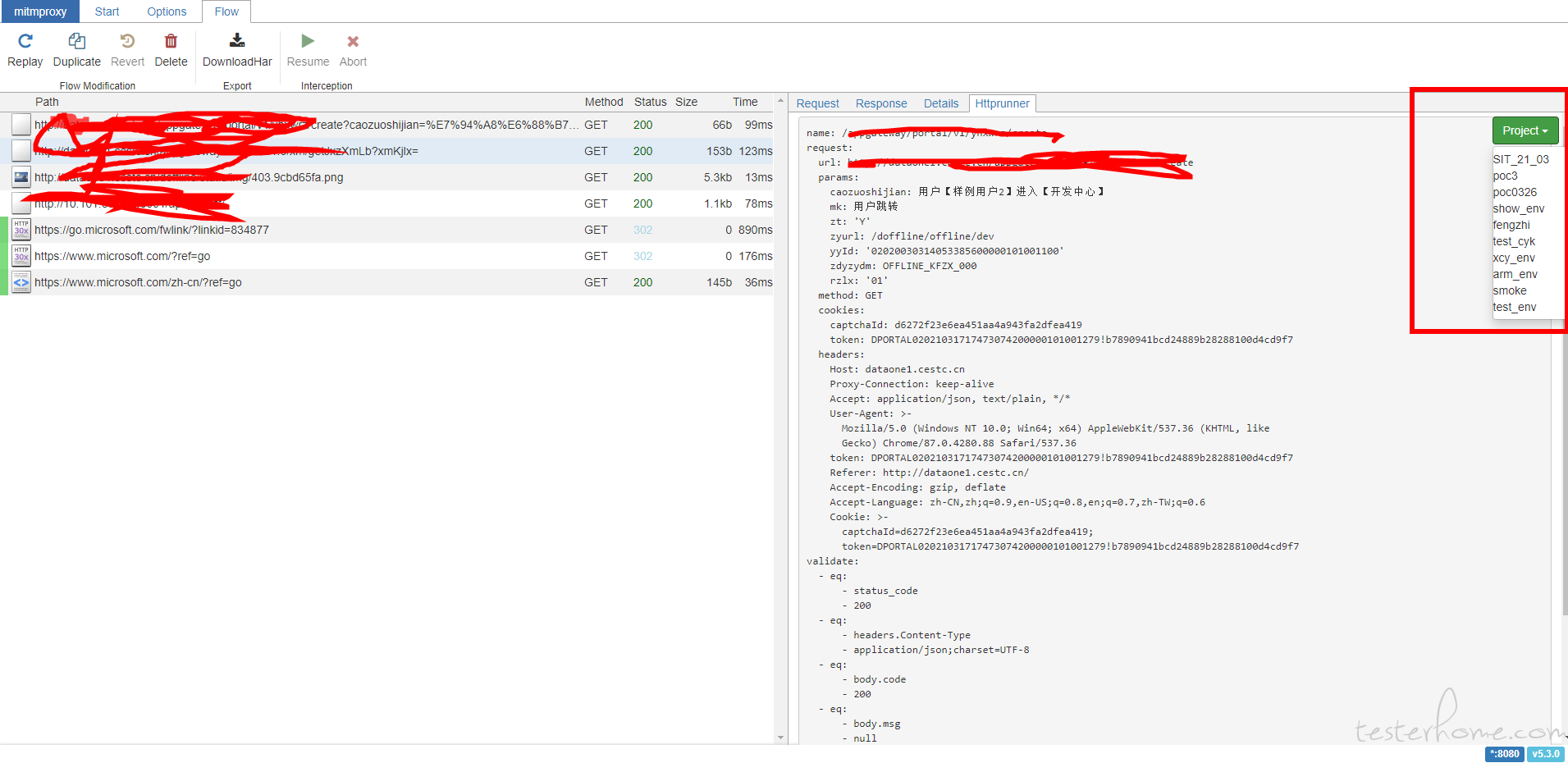
登录工具查看脚本生成情况
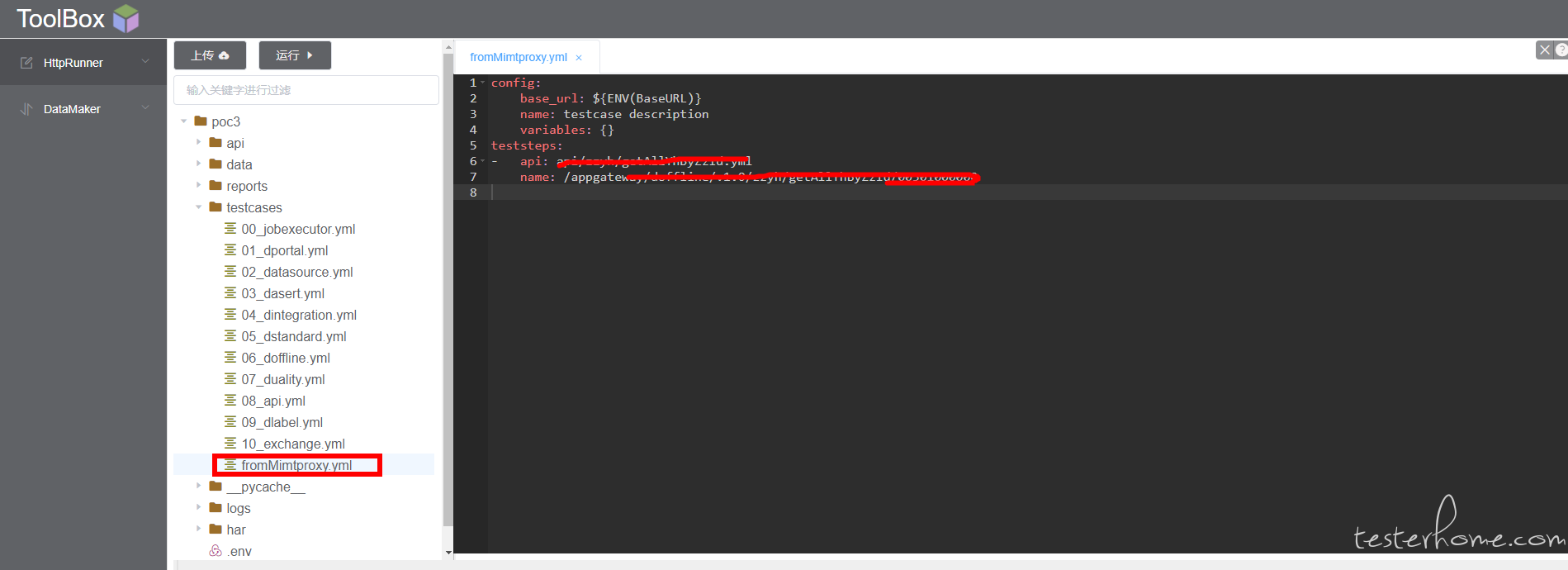
修改后的 mitmproxy 库代码 可以直接放到其他地方使用,当一个本地抓包工具用。
使用方法:
安装 python 包
pip install mitmproxy
pip install har2case
然后把 python 环境中 site-packages 目录下的 mitmproxy 替换为修改后的 mitmproxy 库代码。
在命令行执行 mitmweb 就能使用了。
求教下:markdown 怎么上传压缩包呀?~~
