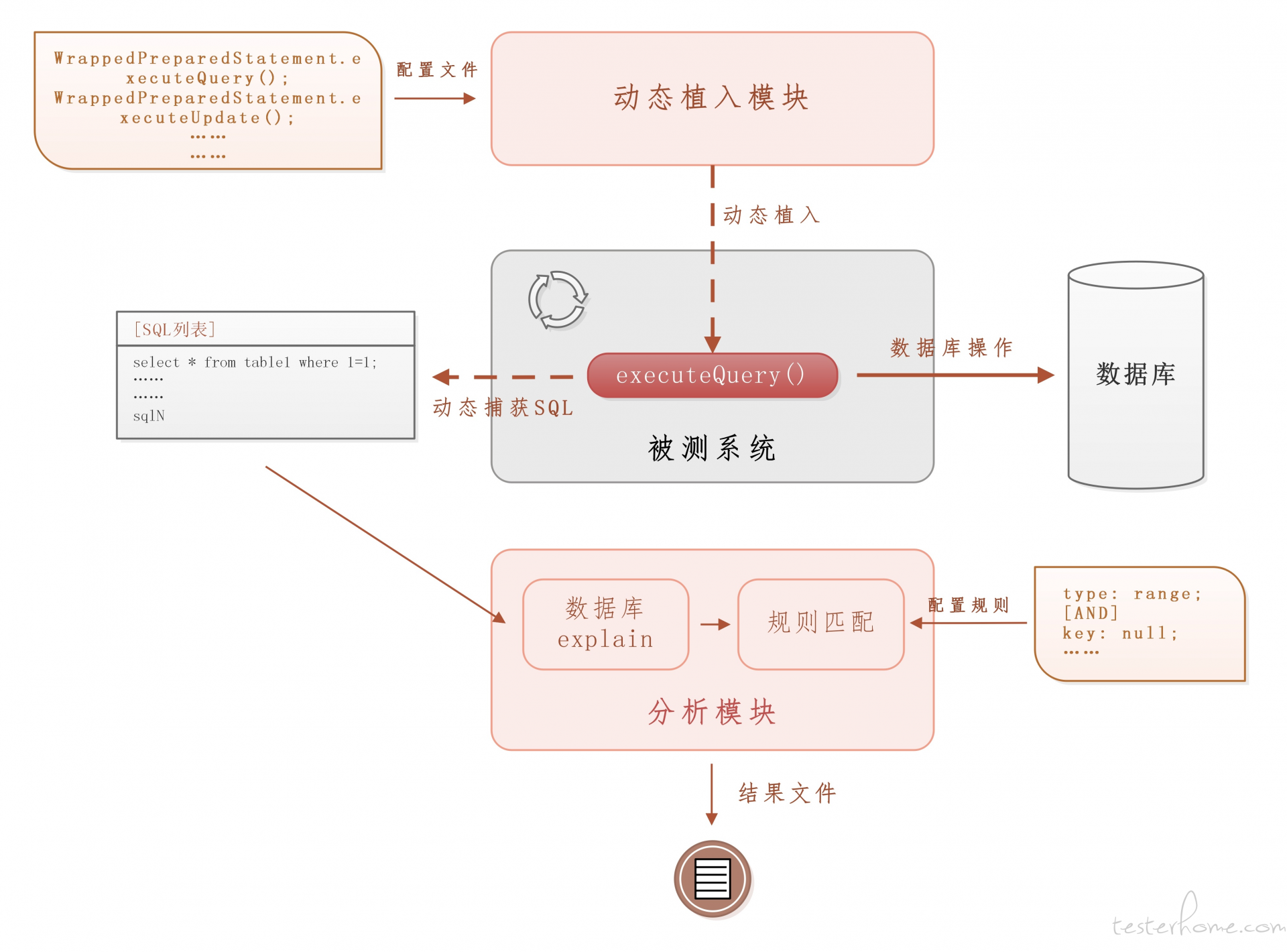
经过分析,识别慢查询语句需要解决两个问题:一是,如何获得系统执行是查询语句;二是,如何分析某个查询是否是慢查询。
解决第一个问题,我们想到了使用插桩技术。
对于一个查询操作,不管上层应用代码如何编写、或使用何种数据库框架,这个操作最终会与目标数据库交互,而交互的时候它一定必须是一个标准的 SQL 语句。基于这一点,我们对这个应用进行了全面的分析,我们的系统部署在 Jboss 上,通过层层剖析,我们找到了这个实际执行查询操作数据库交互的方法,位于 Jboss 的 JCA 包中,共用到以下两处:
前段时间,我负责测试的系统在生产环境运行出现问题。该系统对于响应时间要求较高,问题发生的时候并发很高,出现大量请求超时,超时请求比例随时间推迟越来越高,最后几乎全部请求都失败。滚动重启了所有进程后,很快又出现超时情况。
后经过排查,发现是新版本实现某个功能时修改了一个数据库查询语句,修改后该查询语句的查询条件未使用到索引字段,而所查询的表生产环境中体量巨大,因此这个查询操作耗时从毫秒级变成了秒级,也就是形成了所谓的慢查询,再加上大量并发,悲剧就发生了。
事件发生后,我们测试团队进行了反思,这么严重的问题为何测试环境没有发现?总结了两点原因,一是,测试环境进行功能测试时并发量不高,即使单个请求变慢也不会发生超时现象;二是,测试环境数据库表的数据量较生产环境小很多,所以单个查询操作比生产快很多,这样压力测试中请求也极少超时。
综上所述,想要在测试过程中人为识别一个慢查询很难,为了杜绝这类问题再次发生,在后续版本测试中我们做了一些尝试。
因为我们内部本来就有使用代码扫描的工具,每个版本都会通过扫描来识别一些问题,所以我们首先想到了通过静态扫描原代码,捞出所有的数据库查询语句然后进行分析。实际操作后发现,我们系统在数据库操作上大量使用框架,不同模块使用的框架还不同,捞出的数据库语句千奇百怪,且包含代码元素,并不是能直接执行的语句,对于大型系统而言,人工去分析这些语句工作量太大,这种方法并不可行。
然后我们想到,可以从数据库侧来解决这个问题,通过开启 Mysql 的慢查询日志开关,将功能测试过程中大于 long_query_time 配置时间的数据库查询操作都记录下来,再逐个分析是否存在慢查询问题。过程中我们确实抓到了很多执行较慢的查询语句,但经过分析后发现,这些语句绝大部分都是测试人员人工查询数据库的操作,更遗憾的是,由于测试数据数量级较少,之前发生生产问题的查询语句在测试环境的执行时间并没有超过 long_query_time,由此并不能被识别出来。由此可见,这种方法误报和漏报概率很大,也不可行。
现有工具无法满足我们识别慢查询语句的需求,于是我们决定自己做了一套工具。通过大量的分析和实验,我们得到了一个高效、准确性、且通用性极好的解决方案:
经过分析,识别慢查询语句需要解决两个问题:一是,如何获得系统执行是查询语句;二是,如何分析某个查询是否是慢查询。
解决第一个问题,我们想到了使用插桩技术。
对于一个查询操作,不管上层应用代码如何编写、或使用何种数据库框架,这个操作最终会与目标数据库交互,而交互的时候它一定必须是一个标准的 SQL 语句。基于这一点,我们对这个应用进行了全面的分析,我们的系统部署在 Jboss 上,通过层层剖析,我们找到了这个实际执行查询操作数据库交互的方法,位于 Jboss 的 JCA 包中,共用到以下两处:
① org.jboss.jca.adapters.jdbc.WrappedPreparedStatement.executeQuery()
② org.jboss.jca.adapters.jdbc.WrappedStatement.executeQuery()
通过大量的实验,我们确定我们这个系统所有数据库查询操作必定会调用①②中的一个来完成(实现逻辑不同其他系统可能调用的是 JCA 的其他方法)。再通过在①②设置断点 bebug 我们发现,在①②方法内部 SQL 语句是完全可见的。
接下来我们利用的 Java Instrument Api 及其衍生的开源组件,搭建了一个 agent 程序。启动 agent,agent 在应用系统程序运行时动态的往这两个地方分别插个桩,桩的内容非常简单:将当前方法体内存中正在执行的 SQL 语句打印到某个固定位置(假设我们把 SQL 语句输出到日志文件 A 中)。相对于在①②方法体内部多写一句 print,仅仅只做一个打印的操作,不会对业务逻辑产生任何干扰。
于是我们就完成了这样一个事情:当应用系统要进行数据库查询操作时,它会调用①②中的一个来执行这个查询 SQL,①②被调用时,会将正在执行的 SQL 语句输出到日志文件 A 中。这样,每一个查询操作,都会将实际的查询语句记录在日志文件 A 中,也就完成了查询语句的收集啦。
通过插桩我们获得了大量的 SQL 语句,接下来解决第二个问题,如何判断一个查询语句是否为慢查询。
由于测试和生产数据数量级的差异,用执行时间来判断显然不科学。同时,我们一共获得了几万条 SQL 语句,直接进行人工分析显然不可行。
我们想到了 Mysql 提供的 explain 命令来扩展 SQL 语句,通过 Mysql 的执行计划来科学判断执行的快慢。每条可执行 SQL 语句都可以直接用 explain 命令获得
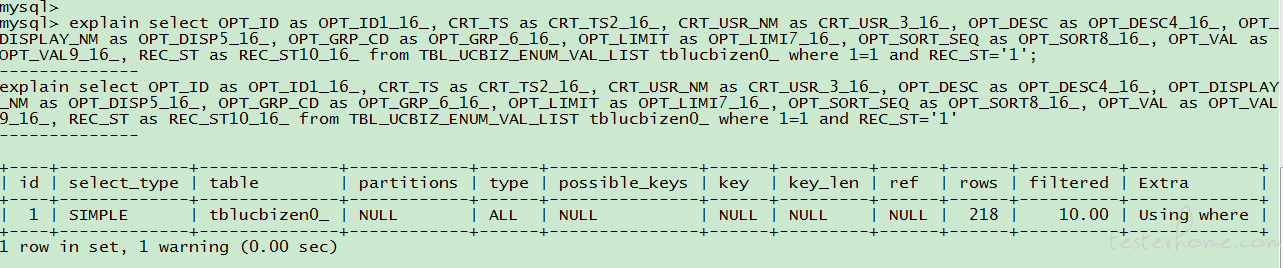
执行计划中的每一个列标签都可以作为匹配环节的关注项,我们称其为指标项,我们用到了与查询效率相关的指标项中最重要的两个:
1、key:表示这个 SQL 语句执行时会使用的索引的键;
2、type:访问方式,表示执行 SQL 语句是在数据库表中找到所需行的方式,可能的值如下:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
从 system 到 ALL,性能从好到差,一般来说应保证至少达到 range 级别。
第一步,我们将日志文件 A 中所有的 SQL 语句逐条转换成执行计划;
第二步,根据系统实际需求,建立一套规则,对执行计划进行筛选,找出可能是慢查询的语句;
我们系统匹配慢查询的规则是:
key in [NULL]
OR
type in [range,index,ALL]
OR
Rows >= 1000
这个规则表示:如果一个 SQL 语句它未经过索引、或者访问方式为 range、index、ALL 之一、或者预估扫描行数大于等于 1000 条,那么它可能是一个慢查询。
第三步,对可能是慢查询的语句进行人工分析。
通过第二步的筛选,我们将需要分析的 SQL 语句数量从几十万条降到了十几条,后续再人工逐一分析。
如此,我们完成了系统的慢查询测试工作。之前导致生产问题的 SQL 语句完美命中,其他疑似慢查询语句结合查询频率、生产数据表数量级等因素,人工判定为非慢。
后来,通过实现 agent 插桩位置、慢查询筛选规则的可配置,我们将这套解决方案优化为一个通用框架,并推广到部门的多个系统使用,并发现了若干慢查询隐患。
对于这套基于插桩的慢查询测试方法,总结优势如下:
1、SQL 语句覆盖全面,且准确性较高。只有插桩点分析准备,可以保证捕获程序运行时执行的所有 SQL 语句(由于实际执行过的 SQL 语句才能被捕获,因此依赖于功能测试的完整性),而以执行计划为基础的分析更具有科学性,且不受数据量大小的影响,准确性更高。
2、有极好的通用性。插桩位置可配置,不同系统只需修改配置既能使用。桩点一般为底层实现与数据库交互的数据库驱动包某一些特定的类和方法,与具体应用程序实现方式不相关,也就是说,无论程序功能是什么、无论使用了什么数据库框架,只要配置正确的数据库交互类及其方法,都能适配。
3、非侵入、可插拔,被测应用无感知。agent 启动,则动态插桩,agent 停止,则桩点消失。无需对被测应用源码做任何修改,检测过程对功能无影响,可在功能测试中悄无声息的完成。
