性能分析尽量从左往右进行分析
性能问题可能涉及到上面任何一个环节
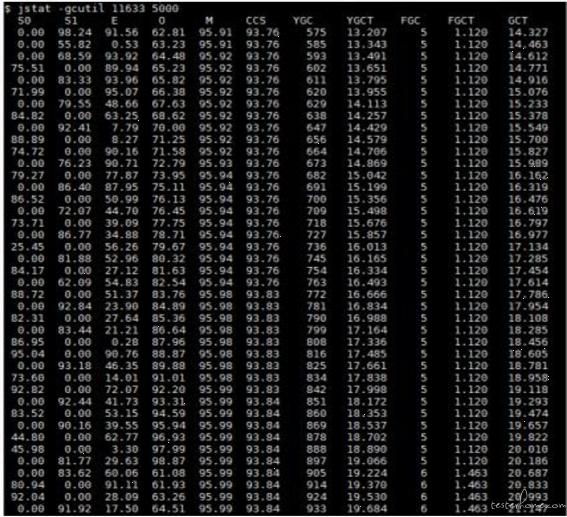
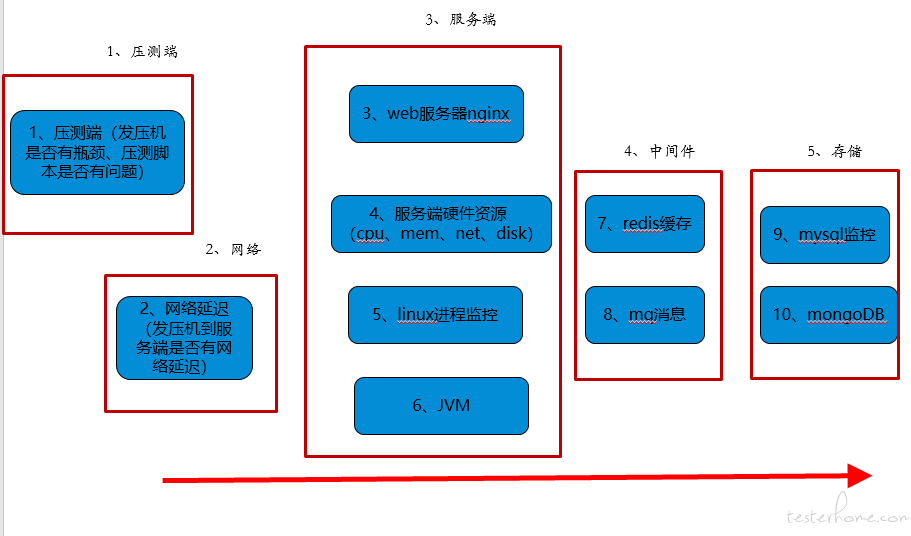
首先介绍下性能分析思路
性能分析尽量从左往右进行分析
性能问题可能涉及到上面任何一个环节
1、问题描述
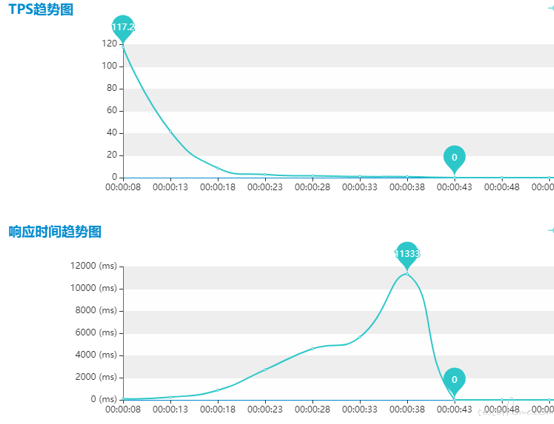
某系统接口压测不到一分钟,TPS 从 120 笔/S 骤降为 0,并且持续为 0。RT 响应时间突然上 升 20 秒后,骤然下降为 0,并且持续为 0,服务处于假死状态。 服务进程挂掉,客户端的所有请求都无响应, 影响整个 app 用户使用
2、问题原因
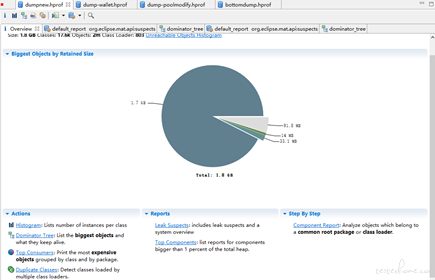
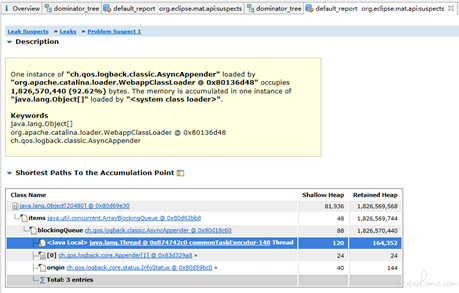
打印 JVM 内存 dump 分析得到:logback 框架 AsyncAppender 类里 ArrayBlockingQueue 队列里存放 20480 个 LogingEvent 对象实例,占据总堆内存的 96.62%

查询某服务 logback 配置文件内容如下

3、AsyncAppender 技术解读
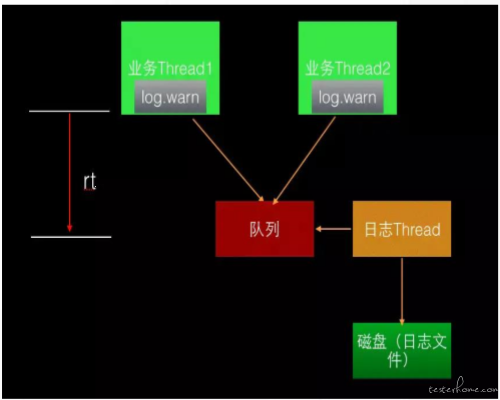
AsyncAppender 关注的重点在于高并发下,把日志写盘变成 日志写内存,减少写日志的 RT appender 之间构成链,AsyncAppender 接收日志并放入其内部的一个阻塞队列,专开一个线程从阻塞队 列中取数据(每次一个)丢给链路下游的 appender(如 FileAppender);
4、根因分析
日志总量分析:单条日志大小平均在 164k,20480*0.164M = 3,358.72 MB
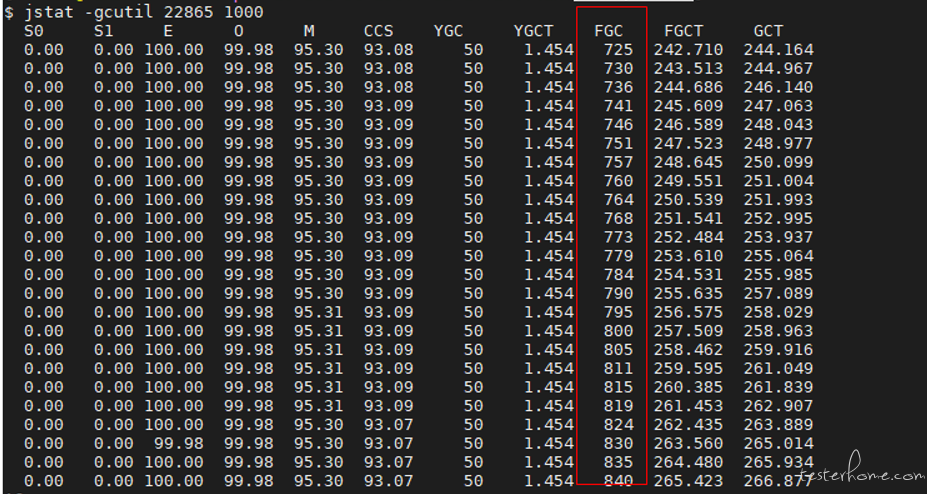
JVM 分析:压测阶段 JVM 堆内存大小设置为 2G,队列大小很快把 JVM 内存沾满,造成 JVM OLD 区频繁回收, 导致频繁 FGC
5、优化方案