一、前言
我所参与的实际业务中,游戏日志链路为游戏客户端直传,落入 HBase 中,中间会经历一次 kafka 消息队列,正常提测的时候是对 HBase 中已经存入的数据做建模校验,但是此时若发现数据不准确,数据丢失,就已经造成了反外挂服务在提取用户数据分析时的一些不准确预测。针对这种数据链路的场景,我们需要提前介入测试,从游戏客户端直传日志的时候就要开始对游戏日志数据进行测试,因为游戏数据是通过 kafka 直传,所以我们需要直接对 kafka 中的游戏数据进行直接测试。
二、什么是 Kafka
相信很多同学在工作中或多或少都有接触过消息中间件,kafka 就是其中一种,Kafka 是最初由 Linkedin 公司开发,是一个分布式、分区的、多副本的、多订阅者,基于 zookeeper 协调的分布式日志系统(也可以当做 MQ 系统),常见可以用于 web/nginx 日志、访问日志,消息服务等等。
主要应用场景是:日志收集系统和消息系统。采用的是发布 - 订阅模式
这里我们不做过多的 kafka 讲解,介绍一下 kafka 中某些角色以及他们的作用
Broker:Kafka 集群包含一个或多个服务器,服务器节点称为 broker
Topic: 每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)
Pritition: topic 中的数据分割为一个或多个 partition,存储消息的分区。
Producer:生产者即数据的发布者,该角色将消息发布到 Kafka 的 topic 中。
Consumer: 消费者可以从 broker 中读取数据。消费者可以消费多个 topic 中的数据
Consumer Group:每个 Consumer 属于一个特定的 Consumer Group
kafka 的更详细的介绍这里就不展示了,感兴趣的小伙伴可以去 kafka 官网学习
三、如何测试 Kafka 中的数据呢
由于上文已介绍了 Kafka,所以我们只需要开启一个 Consumer 即可消费 kafka 中的数据进行数据测试,这里采用了 kafka-python2.0.1,利用 KafkaConsumer 拉取数据
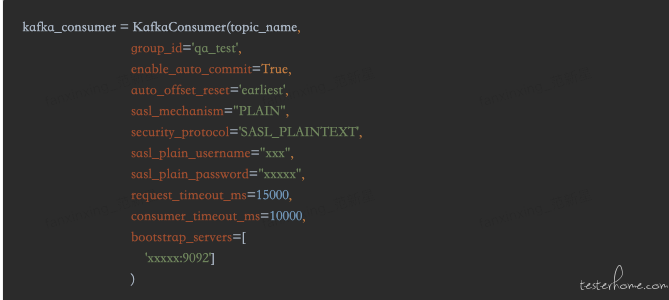
官方定义的配置 config 很多,具体配置还是要根据当前的业务调整,如上文中的 auto_offfset_reset='earliest'配置了即可消费到最早可以消费到的数据,若是要消费最新的数据,即可去掉这一条配置。
基于检测任务,所以还是取最新未消费的数据进行拉取校验。
消费程序开启后,会不定的消费数据,我们的检测任务需要一直运行而不停止吗?在如此大批量的数据情况下,做到每条数据都检查并做结果输出是比较困难的,所有我们采取抽样检查,再启动消费者的时候,可以控制消费的数量来达到一次任务需要检查的日志条数。
Kafka 集群有带认证和不带认证的,小伙伴需要注意两种集群的配置方式。
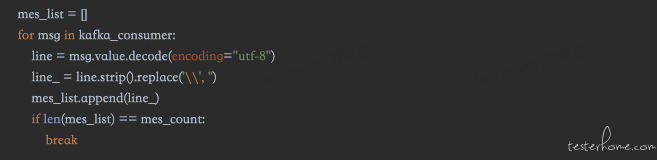
如上,我们可以自定义采集需要的日志数量,当日志数量采集完成后,对采集的日志数据做一次日志解析后进行数据建模测试,具体解析规则,建模规则校验试具体建模需求而定。
如果我们采取了一直消费最新的日志,定义的采集数量比较多,但是数据传送过来比较少怎么办,那我们的采集校验程序需要一直进行下去吗,如何优雅的停止我们的消费程序呢?,上文的 Kafka_Consumer 中 consumer_timeout_ms 的配置可以解决这个问题,自定义超时时间,如果在设定的时间内未采集到数据,那么会自动退出消费程序。
采集好需要检查的日志后,可以自定义异常方法去轮询采集的数据,将不符合采集要求的异常数据以及异常原因保留下来即可完成数据建模测试,并且观察结果可以快速观察每条日志中的数据建模的错误原因。
具体数据解析代码根据各个业务数据做规则解析,这里就不贴代码了。
四、接入的日志任务变多了呢?
这个时候,部门的核心宗旨就体现出来了,测试能力工具化,测试工具平台化。
做成服务化,可以新建执行任务,任务进行周期调度

任务页面可以实时查询检测结果,加入调度任务可对任务数据监控,验证错误即可告警。
五、总结
本文只是从提测数据链路中的上一链路进行了数据保障,真正的数据保障需要做到全链路的数据保障,任重而道远,若有小伙伴有更好的思路或者技术手段,欢迎赐教。

↙↙↙阅读原文可查看相关链接,并与作者交流