以图搜图,是日常生活中我们经常会用到,例如在选购一款商品时,想要对比价格,往往会在各个购物 app 上通过搜图的形式来看同一款产品的价格;当你碰到某种不认识的植物时,也可以通过以图搜图的方式来获取该种植物的名称。而这些功能大都是通过计算图像的相似度来实现的。通过计算待搜索图片与图片数据库中图片之间的相似度,并对相似度进行排序为用户推荐相似图像的搜索结果。同时,通过检测图片是否相似也可用于判断商标是否侵权,图像作品是否抄袭等。本文将介绍几种比较常用的相似图像检测方法,其中包括了基于哈希算法,基于直方图,基于特征匹配,基于 BOW+Kmeans 以及基于卷积网络的图像相似度计算方法。
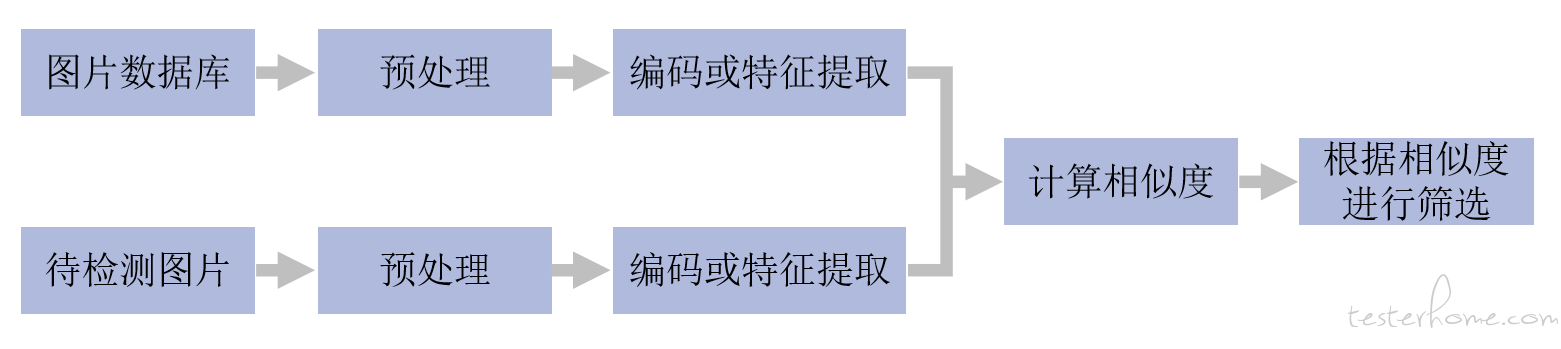
相似图像的检测过程简单说来就是对图片数据库的每张图片进行编码或抽取特征 (一般形式为特征向量),形成数字数据库。对于待检测图片,进行与图片数据库中同样方式的编码或特征提取,然后计算该编码或该特征向量和数据库中图像的编码或向量的距离,作为图像之间的相似度,并对相似度进行排序,将相似度靠前或符合需求的图像显示出来。
哈希算法可对每张图像生成一个 “指纹”(fingerprint) 字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。
常用的哈希算法有三种:
(1)均值哈希算法 (ahash)
均值哈希算法就是利用图片的低频信息。将图片缩小至 8*8,总共 64 个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。将缩小后的图片,转为 64 级灰度。计算所有 64 个像素的灰度平均值,将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为 1;小于平均值,记为 0。将上一步的比较结果,组合在一起,就构成了一个 64 位的整数,这就是这张图片的指纹。
def aHash(img):
img = cv2.resize(img, (8, 8))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
np_mean = np.mean(gray)
ahash_01 = (gray > np_mean) + 0
ahash_list = ahash_01.reshape(1, -1)[0].tolist()
ahash_str = ''.join([str(x) for x in ahash_list])
return ahash_str
均值哈希算法计算速度快,不受图片尺寸大小的影响,但是缺点就是对均值敏感,例如对图像进行伽马校正或直方图均衡就会影响均值,从而影响最终的 hash 值。
(2)感知哈希算法 (phash)
感知哈希算法是一种比均值哈希算法更为健壮的算法,与均值哈希算法的区别在于感知哈希算法是通过 DCT(离散余弦变换)来获取图片的低频信息。先将图像缩小至 32*32,并转化成灰度图像来简化 DCT 的计算量。通过 DCT 变换,得到 32*32 的 DCT 系数矩阵,保留左上角的 8*8 的低频矩阵(这部分呈现了图片中的最低频率)。再计算 8*8 矩阵的 DCT 的均值,然后将低频矩阵中大于等于 DCT 均值的设为” 1”,小于 DCT 均值的设为 “0”,组合在一起,就构成了一个 64 位的整数,组成了图像的指纹。
def pHash(img):
img = cv2.resize(img, (32, 32))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dct = cv2.dct(np.float32(gray))
dct_roi = dct[0:8, 0:8]
avreage = np.mean(dct_roi)
phash_01 = (dct_roi > avreage) + 0
phash_list = phash_01.reshape(1, -1)[0].tolist()
phash_str = ''.join([str(x) for x in phash_list])
return phash_str
感知哈希算法能够避免伽马校正或颜色直方图被调整带来的影响。对于变形程度在 25% 以内的图片也能精准识别。
(3)差异值哈希算法 (dhash)
差异值哈希算法将图像收缩小至 8*9,共 72 的像素点,然后把缩放后的图片转化为 256 阶的灰度图。通过计算每行中相邻像素之间的差异,若左边的像素比右边的更亮,则记录为 1,否则为 0,共形成 64 个差异值,组成了图像的指纹。
def dHash(img):
img = cv2.resize(img, (9, 8))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hash_str0 = []
for i in range(8):
hash_str0.append(gray[:, i] > gray[:, i + 1])
hash_str1 = np.array(hash_str0) + 0
hash_str2 = hash_str1.T
hash_str3 = hash_str2.reshape(1, -1)[0].tolist()
dhash_str = ''.join([str(x) for x in hash_str3])
return dhash_str
相对于 pHash,dHash 的速度要快的多,相比 aHash,dHash 在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。
最后通过计算图像指纹之间的汉明距,算出彼此的相似度:
def hammingDist(hashstr1, hashstr2):
assert len(hashstr1) == len(hashstr1)
return sum([ch1 != ch2 for ch1, ch2 in zip(hashstr1, hashstr1)])
二、单通道直方图和三直方图
单通道图,俗称灰度图,每个像素点只能有有一个值表示颜色,它的像素值在 0 到 255 之间,0 是黑色,255 是白色,中间值是一些不同等级的灰色。三通道图,每个像素点都有 3 个值表示(如 RGB 图),所以就是 3 通道。图像的直方图用来表征该图像像素值的分布情况。用一定数目的小区间 (bin) 来指定表征像素值的范围,每个小区间会得到落入该小区间表示范围的像素数目。可以通过计算图像直方图的重合度,来判断图像之间的相似度。
def calculate_single(img1, img2):
hist1 = cv2.calcHist([img1], [0], None, [256], [0.0, 255.0])
hist1 = cv2.normalize(hist1, hist1, 0, 1, cv2.NORM_MINMAX, -1)
hist2 = cv2.calcHist([img2], [0], None, [256], [0.0, 255.0])
hist2 = cv2.normalize(hist2, hist2, 0, 1, cv2.NORM_MINMAX, -1)
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + (1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree
def classify_hist_of_three(img1, img2, size=(256, 256)):
image1 = cv2.resize(img1, size)
image2 = cv2.resize(img2, size)
sub_image1 = cv2.split(img1)
sub_image2 = cv2.split(img2)
sub_data = 0
for im1, im2 in zip(sub_img1, sub_img2):
sub_data += calculate_single(im1, im2)
sub_data = sub_data / 3
return sub_data
直方图能够很好的归一化,比如 256 个 bin 条,那么即使是不同分辨率的图像都可以直接通过其直方图来计算相似度,计算量适中。比较适合描述难以自动分割的图像。
三、基于特征提取与匹配的方法
(1)ORB 特征
ORB 特征是将 FAST 特征点的检测方法与 BRIEF 特征描述子结合起来,并在它们原来的基础上做了改进与优化。ORB 特征提取速度快,提取的特征直接是二元编码形式,无需使用哈希学习方法就可以直接利用汉明距离快速计算相似度。在大多数情况下,去重效果能够与 SIFT/SURF 持平。
def ORB_img_similarity(img1_path,img2_path):
orb = cv2.ORB_create()
img1 = cv2.imread(img1_path, cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread(img2_path, cv2.IMREAD_GRAYSCALE)
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
matches = bf.knnMatch(des1, trainDescriptors=des2, k=2)
matchNum = [m for (m, n) in matches if m.distance <0.8* n.distance]
similary = len(good) / len(matches)
return similary
(2)SIFT/SURF 特征
SIFT 特征提取是在不同的尺度空间上查找关键点 (特征点),并计算出关键点的方向。SIFT 所查找到的关键点是一些十分突出、不会因光照、仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
def sift_similarity(img1_path, img2_path):
sift = cv2.xfeatures2d.SIFT_create()
FLANN_INDEX_KDTREE=0
indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
searchParams = dict(checks=50)
flann = cv2.FlannBasedMatcher(indexParams, searchParams)
sampleImage = cv2.imread(samplePath, 0)
kp1, des1 = sift.detectAndCompute(sampleImage, None)
kp2, des2 = sift.detectAndCompute(queryImage, None)
matches = flann.knnMatch(des1, des2, k=2)
matchNum = [m for (m, n) in matches if m.distance <0.8* n.distance]
similary = matchNum/len(matches)
return similarity
四、基于 BOW + K-Means 的相似图像检测
BOW 模型被广泛用于计算机视觉中,相比于文本的 BOW,图像的特征被视为单词(word),视觉词汇的字典则由图片集中的所有视觉词汇构成,词袋模型的生成如下图。首先,用 sift 算法生成图像库中每幅图的特征点及描述符。再用 k-Means 算法对图像库中的特征点进行聚类,聚类中心有 k 个,聚类中心被称为视觉词汇,将这些聚类中心组合在一起,形成一部字典。根据 IDF 原理,计算每个视觉单词 TF-IDF 权重来表示视觉单词对区分图像的重要程度。对于图像库中的每一幅图像,统计字典中每个单词在在其特征集中出现的次数,将每张图像表示为 K 维数值向量(直方图)。得到每幅图的直方图向量后,构造特征到图像的倒排表,通过倒排表快速索引相关候选的图像。对于待检测的图像,计算出 sift 特征,并根据 TF-IDF 转化成特征向量(频率直方图),根据索引结果进行直方图向量的相似性判断。

des_list = []
filelist = os.listdir(dir)
trainNum = int(count / 3)
for i in range(len(filelist)):
filename = dir + '\\' + filelist[i]
img = cv2.imread(filename)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
kp, des = sift_det.detectAndCompute(gray, None)
des_list.append((image_path, des))
descriptors = des_list[0][1]
for image_path, descriptor in des_list[1:]:
descriptors = np.vstack((descriptors, descriptor))
voc, variance = kmeans(descriptors, numWords, 1)
im_features = np.zeros((len(image_paths), numWords), "float32")
for i in range(len(image_paths)):
words, distance = vq(des_list[i][1], voc)
for w in words:
im_features[i][w] += 1
nbr_occurences = np.sum((im_features >0) * 1, axis = 0)
idf = np.array(np.log((1.0*len(image_paths)+1) / (1.0*nbr_occurences + 1)), 'float32')
im_features = im_features*idf
im_features = preprocessing.normalize(im_features, norm='l2')
joblib.dump((im_features, image_paths, idf, numWords, voc), "bow.pkl", compress=3)
五、基于卷积网络的相似图像检测
在 ImageNet 中的卷积网络结构(vgg16)基础上,在第 7 层(4096 个神经元)和 output 层之间多加一个全连接层,并选用 sigmoid 激活函数使得输出值在 0-1 之间,设定阈值 0.5 之后可以转成 01 二值向量作为二值检索向量。这样,对所有的图片做卷积网络前向运算,得到第 7 层 4096 维特征向量和代表图像类别分桶的第 8 层 output。对于待检测的图片,同样得到 4096 维特征向量和 128 维 01 二值检索向量,在数据库中查找二值检索向量对应的图片,比对 4096 维特征向量之间距离,重新排序即得到最终结果。其流程如下:

database = 'dataset'
index = 'models/vgg_featureCNN.h5'
img_list = get_imlist(database)
features = []
names = []
model = VGGNet()
for i, img_path in enumerate(img_list):
norm_feat = model.vgg_extract_feat(img_path)
img_name = os.path.split(img_path)[1]
features.append(norm_feat)
names.append(img_name)
feats = np.array(features)
output = index
h5f = h5py.File(output, 'w')
h5f.create_dataset('dataset_features', data=feats)
h5f.create_dataset('dataset_names', data=np.string_(names))
h5f.close()
model = VGGNet()
queryVec = model.vgg_extract_feat(imgs)
scores = np.dot(queryVec, feats.T)
rank_ID = np.argsort(scores)[::-1]
rank_score = scores[rank_ID]
下边展示了不同方法针对一张图标,在同一数据库中进行相似图像检测的效果:

从检测结果中可以看出,针对上述的数据,基于 vgg16 和 sift 特征的检索结果会更加的准确和稳定,基于直方图检索出的图与待检测的图也都比较相似,而基于 BOW 和哈希算法检索出的结果表现则不稳定,基于 orb 特征检索出来的图和待检测图差距很大,效果很不理想。但这不能说明某种方法一定不好,而是针对特定数据而言的,同种方法在不同数据库中的表现也存在着差异。在实践过程中,为了保证检测效果的稳定性,应选取性能较好较稳的方法。
相似图片的检测方法有很多,但不是每种方法都适应于你的应用场景,各种方法在不同的数据上的表现也具有很大的差异。因此,可以根据自身数据的特点和不同方法的特性来综合考虑。也可以根据需求将不同的方法进行结合,进一步提升相似图像检测的准确性和稳定性。如果检测相似图片是为了分析商标是否侵权或是作品是否抄袭等,可适当的设置相似度的阈值,进行筛选。
