由于最近公司的实时数据处理引擎再向 Flink 迁移,所以专门设计、总结了一篇 “基于 Flink 的实时数据消费应用/功能质量保障方法”。欢迎大家一起分享探讨在大数据方面的测试方法和经验。
Apache Flink 是由 Apache 软件基金会开发的开源流处理框架,其核心是用 Java 和 Scala 编写的分布式流数据流引擎。Flink 以数据并行和流水线方式执行任意流数据程序,Flink 的流水线运行时系统可以执行批处理和流处理程序。此外,Flink 的运行时本身也支持迭代算法的执行。
Flink 是目前唯一能同时集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架。Apache Spark 只有高吞吐、高性能。因为 Spark Stream 做不到低延迟,本质还是微批处理。Apache Storm 只有低延迟、高性能,但达不到高吞吐。
关于 Flink 的基础介绍可以查看链接:https://flink.apache.org/
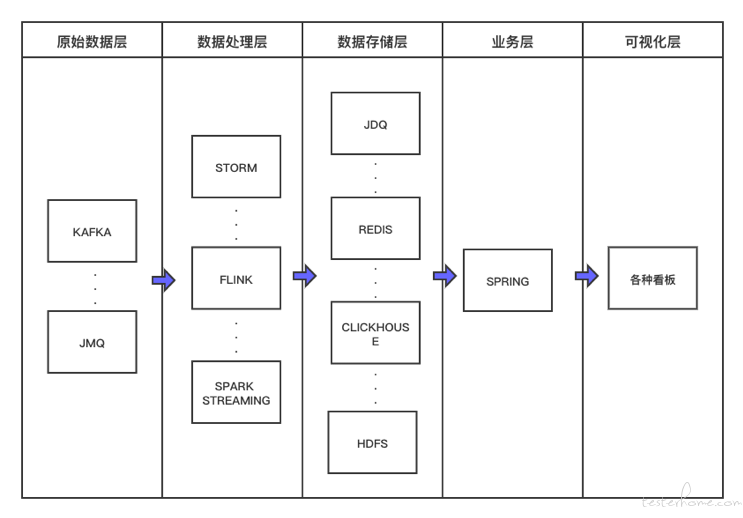
要保障实时数据消费应用的质量,首先需要清楚基于实时数据加工的业务链路是怎样的,数据流转路径是怎么样的。
根据实时数据的应用场景和实时数据相关业务链路,实时数据消费应用的质量目标包括以下几点:
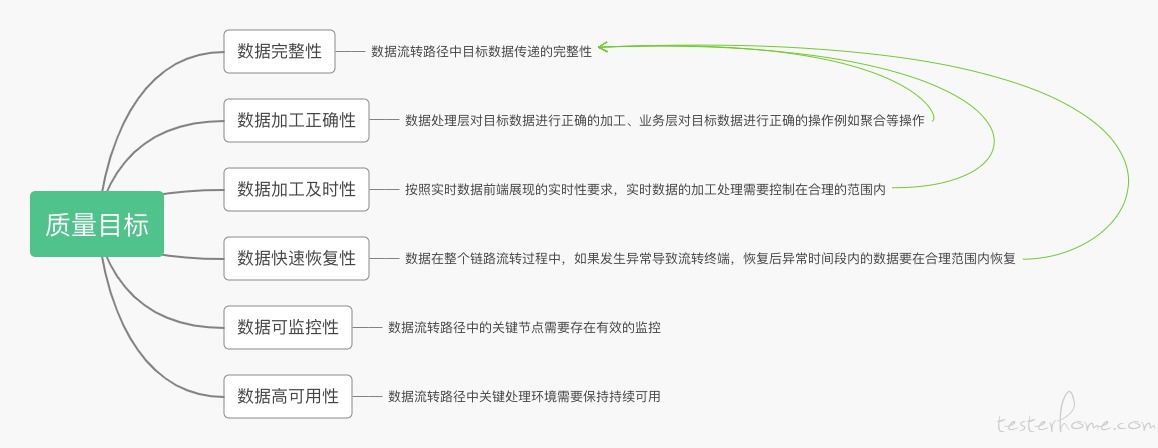
在整个实时数据加工流程中,并不是所有的环节都需要达成相同的质量目标。将质量目标分布在不同的加工环节上;

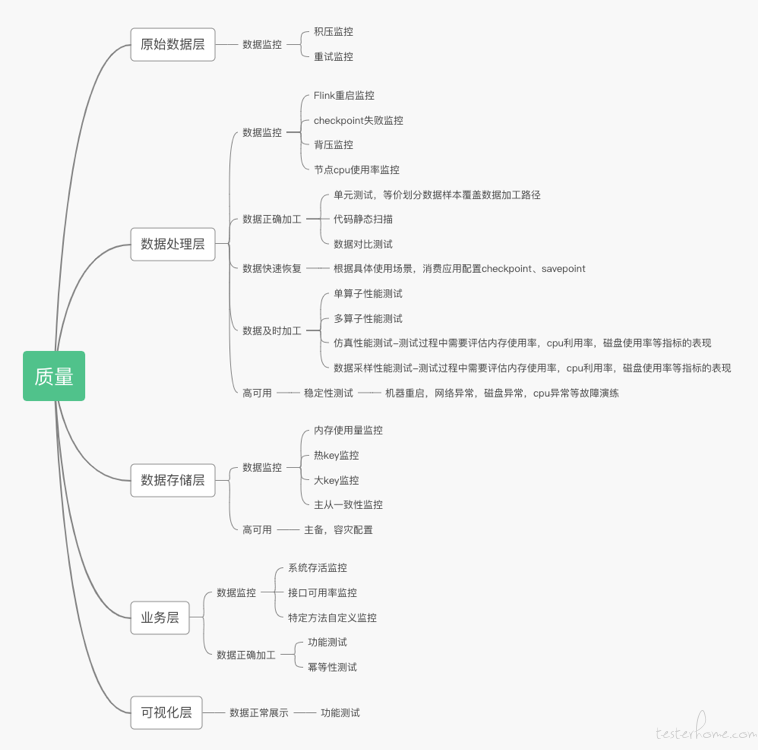
从质量目标的分布上看质量目标主要集中在数据处理层,这也客观的反映了在整个实时数据消费应用的数据流转路径中 “数据处理层” 是核心的特点。
由于 “原始数据层” 在整个数据流转路径中担任的是原始数据提供方的角色且具体的数据产生逻辑和方式对于下游来说完全是个黑盒。所以在这里我们需要做好对数据源的监控,至少需要具备消息积压监控,且积压阈值需要准确的设置,设置过高会导致下游数据延迟时间已经超时合理范围但上游积压告警还未出现。
基于 Flink 的实时数据消费应用是不存在功能接口供测试人员从功能角度进行验证的,且复杂场景下,对一条消息的处理会存在多个计算逻辑(多个算子),因此如何保障加工逻辑的覆盖度变得非常重要。
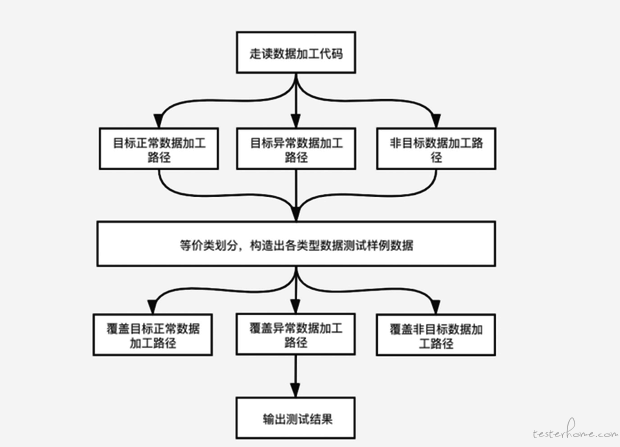
要保证加工逻辑的覆盖度就需要清理出数据加工路径,按照等价类划分的方法构造出不同路径下的样例数据,进行覆盖。确保线上运行时正常,异常数据应用都可以正常处理。至于覆盖测试如何进行可以使用 Flink-spector,一种应用于 Flink 程序的单元测试框架。为了进一步保证程序的健壮在数据加工路径覆盖测试完成后可以对代码进行静态扫描。以上是从白盒角度对加工路径进行覆盖进行加工准确性的保证。另一种是从黑盒功能性的角度进行加工准确性的验证;
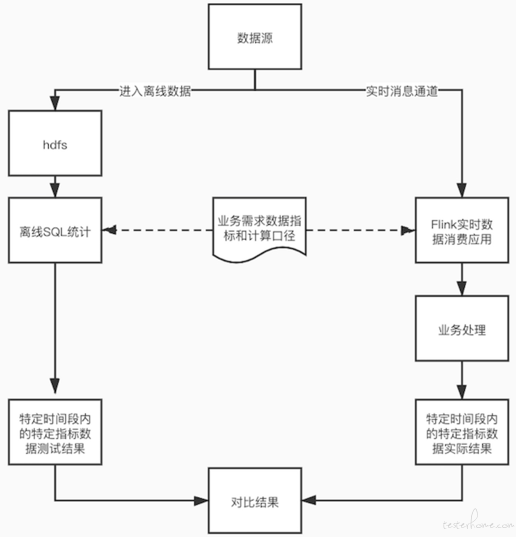
Flink 实时消息消费应用通过不同算子对数据的加工,这些算子可以转换成 SQL,测试人员可以根据 PRD 中数据指标的具体口径进行提数和实时加工应用的数据进行对比。(注意此方法不仅在上线前可以当做数据正确加工验证的测试方法,也可以在上线后当做数据正确加工的监控手段。)
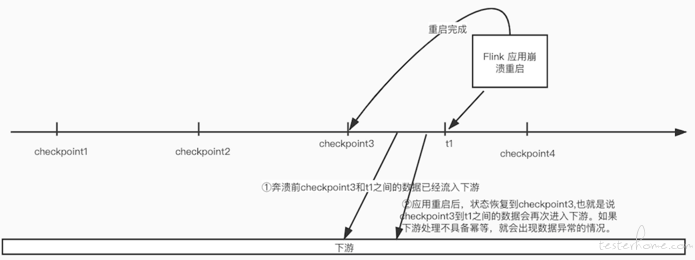
Flink 框架自带保证程序的容错恢复和程序启动时其状态恢复,checkpoint 和 savepoint,测试人员需要根据具体的实时消费场景判断程序是否正确配置了相关内容。
(注意检查完 checkpoint 配置后在测试环境中运行后,一定要在 Flink UI 中查看 Checkpoint 耗时,如果 Checkpoint 配置有问题,或者状态很大的情况发生,会极大的影响消费性能。导致积压)
数据及时加工反应的其实是实时数据消费的性能,对实时消息消费应用的性能测试可以从以下几个方面入口:
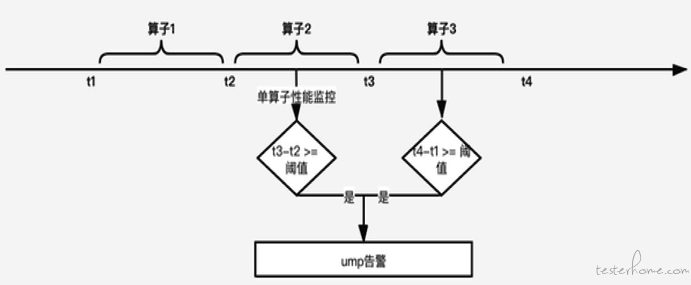
多算子性能测试:多个算子的协作完成了对一条消息的处理,因此需要衡量多个算子处理完一条数据的性能
(注意单算子或多算子的性能在上线前需要测试外,上线后还需要做到持续的监控)如下图:
仿真性能测试:使用真实数据对实时消息消费应用集群进行测试,观察消费的性能表现。目前一般的做法可以是调整上游消息的位点;高保真流量回放
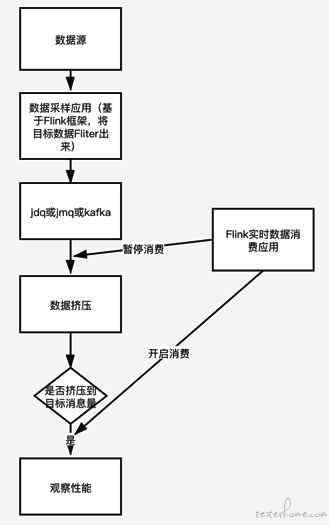
数据采样性能测试:从线上真实数据中取出目标数据,并积累到一定数量后对实时消息消费应用进行测试。在仿真测试中线上流量对应的数据可能有大部分是我们加工逻辑中直接被过滤掉的,这种情况下剩下的部分数据并没有起到性能测试的作用;实现方法如下图:
另外在性能测试中,并不能单单只看消息的积压层度,还需要观察集群的内存使用率,cpu 利用率,网络流入、流出速率,磁盘使用率等指标的展现;
对于支持高并发、多节点,集群物理环境复杂的分布式系统来说,类似磁盘打满、网络延迟等物理节点的异常很难避免。高可用反映的其实是消费应用的稳定性,通常做法就是现在使用到的故障模拟演练。包括机器重启、网络异常、磁盘异常、cpu 异常。在故障发生时应用依然可能正常运行。
数据存储层主要作用是数据存储并没有数据处理的逻辑,因此数据存储层主要质量目标还是存在于监控和高可用上。
业务层会设计数据的二次加工,这部分数据加工的正确性可以使用功能测试完成,也可以进一步的使用单元测试提高覆盖度。
还需要进行幂等性测试,因为 Flink 保证数据一致性,正确性的手段均是针对 Flink 本身。即使 Flink 有 checkpoint 和 savepoint 的保障机制,也需要保证下游数据的幂等性。
根据前几点我们汇总出基于 flink 的实时数据消费应用的质量保障思维导图: