问题现象
最近,笔者负责测试的某个算法模块机器出现大量报警,报警表现为机器 CPU 持续高占用。该算法模块是一个优化算法,本身就是 CPU 密集型应用,一开始怀疑可能是算法在正常运算,但很快这种猜测就被推翻:同算法同学确认后,该算法应用只使用了一个核心,而报警时,一个算法进程占用了服务机器的全部 8 个核心,这显然不是正常计算造成的。
定位步骤
首先按照 CPU 问题的定位思路进行定位,对 Java 调用堆栈进行分析:
使用
top -c查看 CPU 占用高的进程:
,从 top 命令的结果看,19272 号进程 CPU 占用率最高,基本确定问题是该进程引起,可以从 Command 栏看到这正是算法模块程序,注意图是线下 4C 机器上复现时的截图。-
使用
ps -mp pid -o THREAD,tid,time命令定位问题线程。ps -mp 19272 -o THREAD,tid,time USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME USER 191 - - - - - - 00:36:54 USER 0.0 19 - futex_ - - 19272 00:00:00 USER 68.8 19 - futex_ - - 19273 00:13:18 USER 30.2 19 - - - - 19274 00:05:50 USER 30.2 19 - - - - 19275 00:05:50 USER 30.2 19 - - - - 19276 00:05:50 USER 30.1 19 - - - - 19277 00:05:49 USER 0.4 19 - futex_ - - 19278 00:00:05 USER 0.0 19 - futex_ - - 19279 00:00:00 USER 0.0 19 - futex_ - - 19280 00:00:00 USER 0.0 19 - futex_ - - 19281 00:00:00 USER 0.4 19 - futex_ - - 19282 00:00:04 USER 0.3 19 - futex_ - - 19283 00:00:03 USER 0.0 19 - futex_ - - 19284 00:00:00 USER 0.0 19 - futex_ - - 19285 00:00:00 USER 0.0 19 - futex_ - - 19286 00:00:00 USER 0.0 19 - skb_wa - - 19362 00:00:00从结果可以看到,出现问题的线程主要是 19273-19277。
使用
jstack查看出现问题的线程堆栈信息。
由于 jstack 使用的线程号是十六进制,因此需要先把线程号从十进制转换为十六进制。
$ printf "%x\n" 19273
4b49
$ jstack 12262 |grep -A 15 4b49
"main" #1 prio=5 os_prio=0 tid=0x00007f98c404c000 nid=0x4b49 runnable [0x00007f98cbc58000]
java.lang.Thread.State: RUNNABLE
at java.util.ArrayList.iterator(ArrayList.java:840)
at optional.score.MultiSkuDcAssignmentEasyScoreCalculator.updateSolution(MultiSkuDcAssignmentEasyScoreCalculator.java:794)
at optional.score.MultiSkuDcAssignmentEasyScoreCalculator.calculateScore(MultiSkuDcAssignmentEasyScoreCalculator.java:80)
at optional.score.MultiSkuDcAssignmentEasyScoreCalculator.calculateScore(MultiSkuDcAssignmentEasyScoreCalculator.java:17)
at org.optaplanner.core.impl.score.director.easy.EasyScoreDirector.calculateScore(EasyScoreDirector.java:60)
at org.optaplanner.core.impl.score.director.AbstractScoreDirector.doAndProcessMove(AbstractScoreDirector.java:188)
at org.optaplanner.core.impl.localsearch.decider.LocalSearchDecider.doMove(LocalSearchDecider.java:132)
at org.optaplanner.core.impl.localsearch.decider.LocalSearchDecider.decideNextStep(LocalSearchDecider.java:116)
at org.optaplanner.core.impl.localsearch.DefaultLocalSearchPhase.solve(DefaultLocalSearchPhase.java:70)
at org.optaplanner.core.impl.solver.AbstractSolver.runPhases(AbstractSolver.java:88)
at org.optaplanner.core.impl.solver.DefaultSolver.solve(DefaultSolver.java:191)
at app.DistributionCenterAssignmentApp.main(DistributionCenterAssignmentApp.java:61)
"VM Thread" os_prio=0 tid=0x00007f98c419d000 nid=0x4b4e runnable
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007f98c405e800 nid=0x4b4a runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007f98c4060800 nid=0x4b4b runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007f98c4062800 nid=0x4b4c runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007f98c4064000 nid=0x4b4d runnable
"VM Periodic Task Thread" os_prio=0 tid=0x00007f98c4240800 nid=0x4b56 waiting on condition
可以看到,除了 0x4b49 线程是正常工作线程,其它都是 gc 线程。
此时怀疑:是频繁 GC 导致的 CPU 被占满。
我们可以使用 jstat 命令查看 GC 统计:
$ jstat -gcutil 19272 2000 10
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 22.71 100.00 97.16 91.53 2122 19.406 282 809.282 828.688
0.00 0.00 100.00 100.00 97.16 91.53 2122 19.406 283 809.282 828.688
0.00 0.00 92.46 100.00 97.16 91.53 2122 19.406 283 812.730 832.135
0.00 0.00 100.00 100.00 97.16 91.53 2122 19.406 284 812.730 832.135
0.00 0.00 100.00 100.00 97.16 91.53 2122 19.406 285 815.965 835.371
0.00 0.00 100.00 100.00 97.16 91.53 2122 19.406 285 815.965 835.371
0.00 0.00 100.00 100.00 97.16 91.53 2122 19.406 286 819.492 838.898
0.00 0.00 100.00 100.00 97.16 91.53 2122 19.406 286 819.492 838.898
0.00 0.00 100.00 100.00 97.16 91.53 2122 19.406 287 822.751 842.157
0.00 0.00 30.78 100.00 97.16 91.53 2122 19.406 287 825.835 845.240
重点关注一下几列:
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
可以看到,20s 的时间中进行了 5 次 full GC,仅仅耗费在 GC 的时间已经到了 17s。
- 增加启动参数,展示详细 GC 过程。
通过增加 jvm 参数,更快暴露 GC 问题,并展示 GC 详细过程
java -Xmx1024m -verbose:gc。
[Full GC (Ergonomics) 1046527K->705881K(1047552K), 1.8974837 secs]
[Full GC (Ergonomics) 1046527K->706191K(1047552K), 2.5837756 secs]
[Full GC (Ergonomics) 1046527K->706506K(1047552K), 2.6142270 secs]
[Full GC (Ergonomics) 1046527K->706821K(1047552K), 1.9044987 secs]
[Full GC (Ergonomics) 1046527K->707130K(1047552K), 2.0856625 secs]
[Full GC (Ergonomics) 1046527K->707440K(1047552K), 2.6273944 secs]
[Full GC (Ergonomics) 1046527K->707755K(1047552K), 2.5668877 secs]
[Full GC (Ergonomics) 1046527K->708068K(1047552K), 2.6924427 secs]
[Full GC (Ergonomics) 1046527K->708384K(1047552K), 3.1084132 secs]
[Full GC (Ergonomics) 1046527K->708693K(1047552K), 1.9424100 secs]
[Full GC (Ergonomics) 1046527K->709007K(1047552K), 1.9996261 secs]
[Full GC (Ergonomics) 1046527K->709314K(1047552K), 2.4190958 secs]
[Full GC (Ergonomics) 1046527K->709628K(1047552K), 2.8139132 secs]
[Full GC (Ergonomics) 1046527K->709945K(1047552K), 3.0484079 secs]
[Full GC (Ergonomics) 1046527K->710258K(1047552K), 2.6983539 secs]
[Full GC (Ergonomics) 1046527K->710571K(1047552K), 2.1663274 secs]
至此基本可以确定,CPU 高负载的根本原因是内存不足导致频繁 GC。
根本原因
虽然我们经过上面的分析可以知道,是频繁 GC 导致的 CPU 占满,但是并没有找到问题的根本原因,因此也无从谈起如何解决。GC 的直接原因是内存不足,怀疑算法程序存在内存泄漏。
为什么会内存泄漏
虽然 Java 语言天生就有垃圾回收机制,但是这并不意味着 Java 就没有内存泄漏问题。
正常情况下,在 Java 语言中如果一个对象不再被使用,那么 Java 的垃圾回收机制会及时把这些对象所占用的内存清理掉。但是有些情况下,有些对象虽然不再被程序使用,但是仍然有引用指向这些对象,所以垃圾回收机制无法处理。随着这些对象占用内存数量的增长,最终会导致内存溢出。
Java 的内存泄漏问题比较难以定位,下面针对一些常见的内存泄漏场景做介绍:
- 持续在堆上创建对象而不释放。例如,持续不断的往一个列表中添加对象,而不对列表清空。这种问题,通常可以给程序运行时添加 JVM 参数
-Xmx指定一个较小的运行堆大小,这样可以比较容易的发现这类问题。 - 不正确的使用静态对象。因为 static 关键字修饰的对象的生命周期与 Java 程序的运行周期是一致的,所以垃圾回收机制无法回收静态变量引用的对象。所以,发生内存泄漏问题时,我们要着重分析所有的静态变量。
- 对大 String 对象调用 String.intern() 方法,该方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。而在 jdk6 之前,字符串常量存储在
PermGen区的,但是默认情况下PermGen区比较小,所以较大的字符串调用此方法,很容易会触发内存溢出问题。 - 打开的输入流、连接没有争取关闭。由于这些资源需要对应的内存维护状态,因此不关闭会导致这些内存无法释放。
如何进行定位
以上介绍了一些常见的内存泄漏场景,在实际的问题中还需要针对具体的代码进行确定排查。下面结合之前的频繁 GC 问题,讲解一下定位的思路,以及相关工具的使用方法。
线上定位
对于线上服务,如果不能开启 Debug 模式,那么可用的工具较少。推荐方式:
使用 top -c 命令查询 Java 高内存占用程序的进程 pid。然后使用 jcmd 命令获取进程中对象的计数、内存占用信息。
$ jcmd 24600 GC.class_histogram |head -n 10
24600:
num #instances #bytes class name
----------------------------------------------
1: 2865351 103154208 [J
2: 1432655 45844960 org.optaplanner.core.impl.localsearch.scope.LocalSearchMoveScope
3: 1432658 34383792 org.optaplanner.core.api.score.buildin.bendablelong.BendableLongScore
4: 1193860 28652640 org.optaplanner.core.impl.heuristic.selector.move.generic.ChangeMove
5: 241961 11986056 [Ljava.lang.Object;
6: 239984 5759616 java.util.ArrayList
结果中,#instances 为对象数量,#bytes 为占用内存大小,单位是 byte,class name 为对应的类名。
排名第一的是 Java 原生类型,实际上是 long 类型。
另外,要注意的是结果中的类可能存在包含关系,例如一个类中含有多个 long 类型数据,那 long 对应的计数也会增加,所以我们要排除一些基本类型,它们可能是我们程序中使用导致的计数增加,重点关注我们程序中的类。
如果仅仅有 jcmd 的结果,其实很难直接找到问题的根本原因。如果问题不能在线下复现,我们基本上只能针对计数较多的类名跟踪变量的数据流,重点关注 new 对象附近的代码逻辑。观察代码逻辑时,重点考虑上述几种常见内存泄漏场景。
线下定位
如果内存泄漏问题可以在线下复现,那么问题定位的工具就比较丰富了。下面主要推荐的两种工具,VisualVM & IDEA。
这里主要讲一下 IDEA 调试定位思路:
使用 IDEA 调试器定位内存泄漏问题
如果以上过程依然不能有效的分析出问题的根本原因,还可以使用 IDEA 的调试功能进行定位。
配置好程序的运行参数,正常复现问题之后,对程序打断点并逐步追踪。
重点关注的是程序需要大量运行时间的代码部分,我们可以使用调试暂停功能获得一个内存快照。
然后在此运行并暂停,这时候在调试的 Memory 视图中可以看到哪些类在快速增加。基本上可以断定问题的原因是两次运行中 new 该对象的语句。
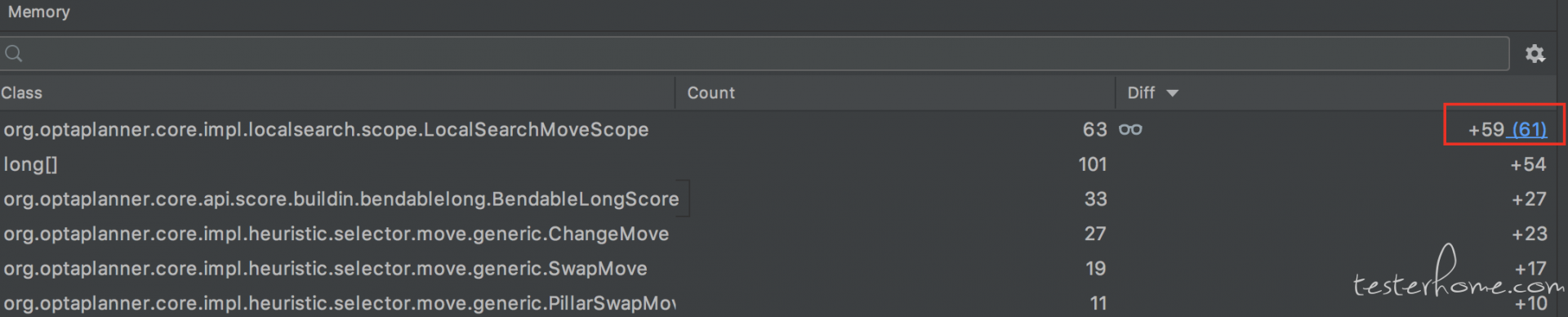
定位结果
经过上述定位步骤,最终发现问题的根本原因,在求解器的 LocalSearch 阶段,如果使用了禁忌搜索(Tabu Search)策略,并且长时间找不到更好的解,会不断把当前经历过的解加到禁忌表中。对应的代码部分,finalListScore 是一个 list,在 55 行代码不断的添加 moveScope 对象,导致了内存泄漏:

解决方案
在求解器该处代码对 finalListScore 进行长度限制,添加对象前发现达到了上限就清空,彻底避免内存泄漏的发生。由于出问题的是一个开源求解器框架:optaplanner,为了方便以后维护,按照开源项目贡献流程,把改 fix 提 PR 给项目即可,如何给开源项目提 PR 可以参考社区文章:https://testerhome.com/topics/2114。
细节参考 PR 链接:https://github.com/kiegroup/optaplanner/pull/726。
项目维护者从代码维护的角度没有接受这个 PR,但是使用了类似的 fix 思路最终修复了这个存在了几年 bug:https://github.com/kiegroup/optaplanner/pull/763。
最后,算法模块升级到最新版本的 optaplanner 依赖即可修复该问题。
 以后我可以给他指一下方向了
以后我可以给他指一下方向了