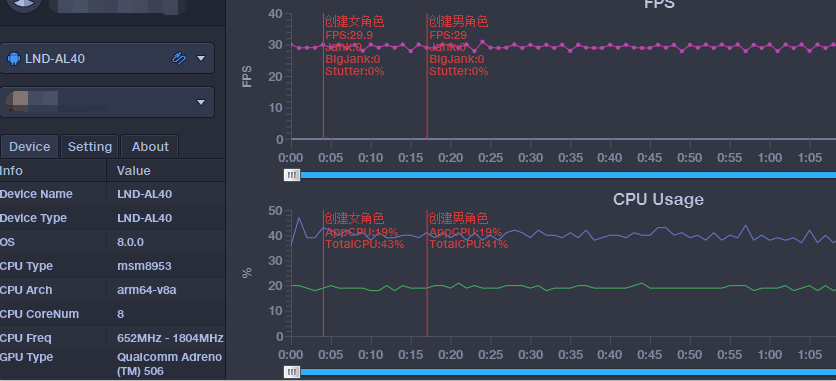
基本使用不提,在整个测试过程我们经常会遇到很多场景,每个场景的性能数据一般都会各有不同,所以为了在报告中看的更明显,我们可以增加批注,比如标记关键节点等。
==鼠标左键双加添加批注==
批注及标定 (鼠标左键双击,则批注。左键双击已生成的批注,则取消。鼠标左键单击,则标定):
2.场景添加标签
文章分两部分
一是自己最近使用 Perfdog 也发现了一些常用的技巧,现在安利给大家一下
二是一些在游戏开发中常见到的优化技巧
1.双击批注
基本使用不提,在整个测试过程我们经常会遇到很多场景,每个场景的性能数据一般都会各有不同,所以为了在报告中看的更明显,我们可以增加批注,比如标记关键节点等。
==鼠标左键双加添加批注==
批注及标定 (鼠标左键双击,则批注。左键双击已生成的批注,则取消。鼠标左键单击,则标定):
2.场景添加标签
为了更加明显区分我们的 测试场景,我们可以对阶段时间增加标签,
==通过标签按钮给性能数据打标签,鼠标左键双击颜色区域可修改对应区域标签名==
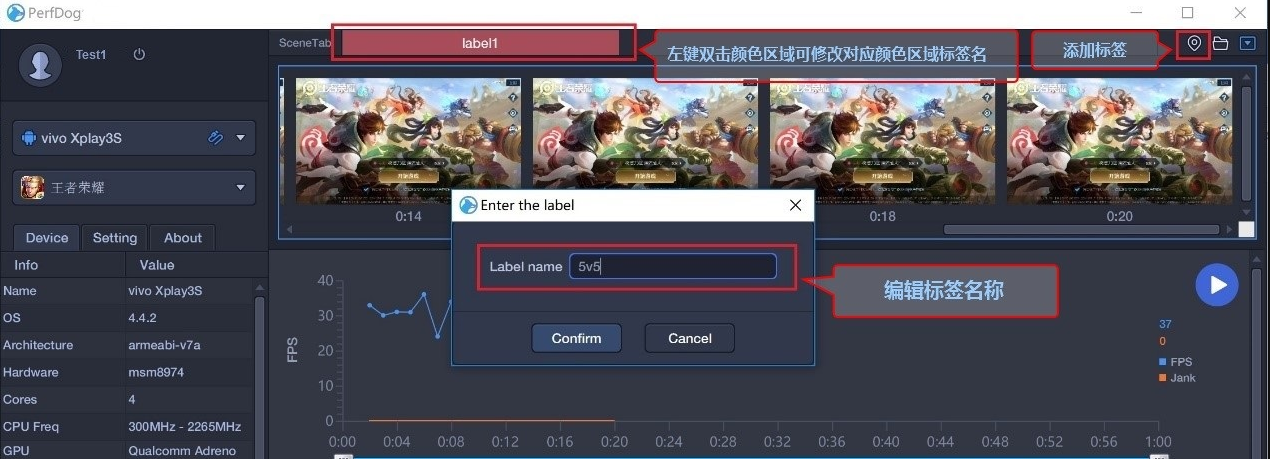
比如我的标记完了就是这样
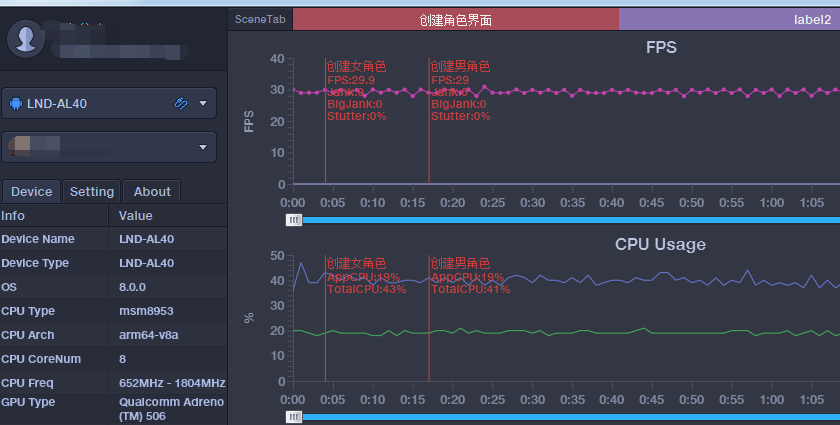
现在我们来看一下报告的样式
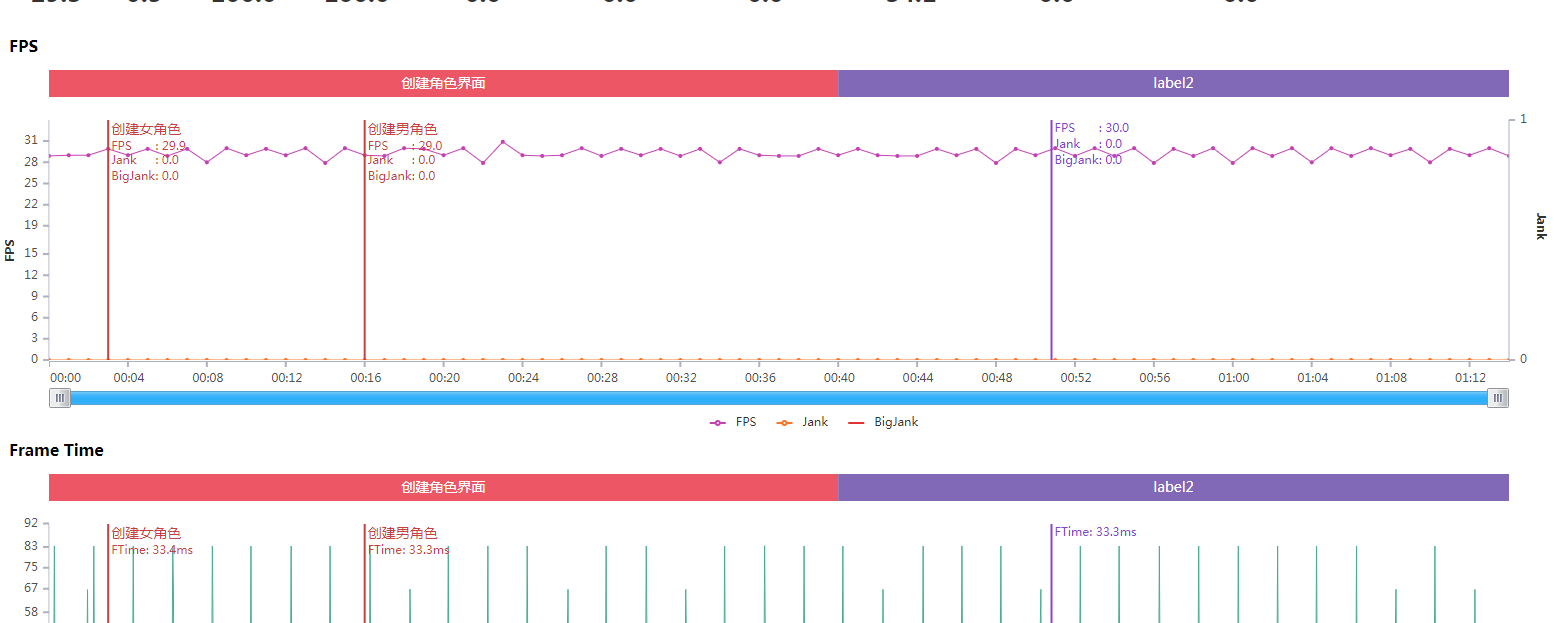
这样对于场景区分是不是明显多了。
3.保存具体数据信息
有时我们需要具体的记录下每一帧运行的具体数据,我们有两种办法:
1.鼠标左键框选后右键存储
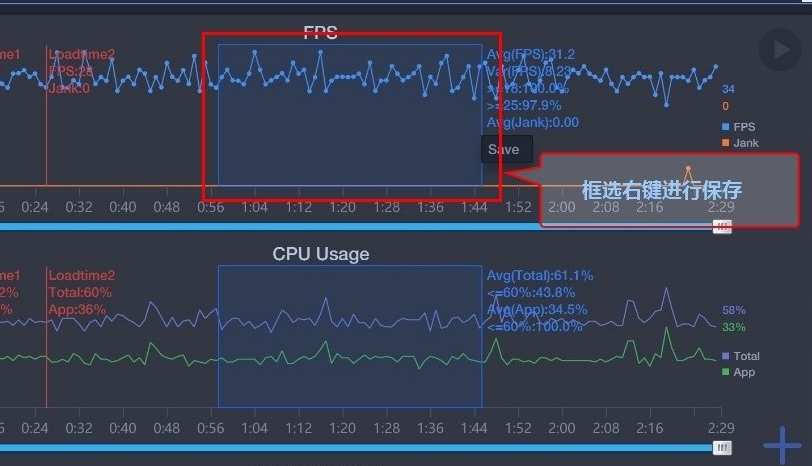
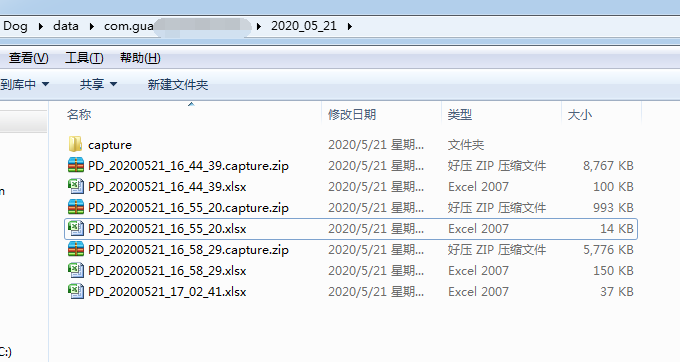
2.是测试完后上传数据到云端时选择同时保存到本地
这样就可以把数据保存到具体的 Xlsx 里,默认在性能狗的 data/测试的应用包名/测试时间文件夹。
4.多进程测试
iOS 平台,APP 多进程分为 APP Extension 和系统 XPC Server。
比如:某电竞直播软件用到 APP Extension 扩展进程 (扩展进程名 LABroadcastUpload)。当然也可能用到系统 XPC Server 服务进程,如一般 web 浏览器会用到 webkit。
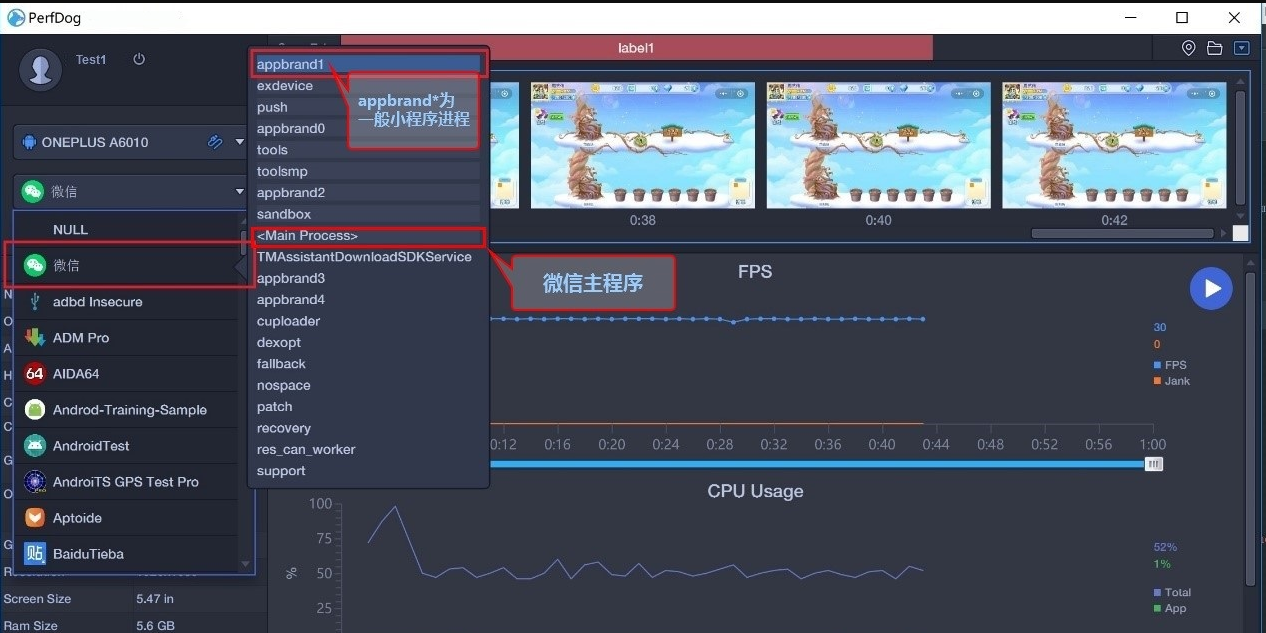
Android 平台,一般大型 APP,比如游戏有时候是多进程协作运行(微信小游戏,微视等 APP 及王者荣耀等游戏多子进程),可选择目标子进程进行针对性测试。默认是主进程;
==子程序进程名高亮显示,表示当前子进程处于顶层==
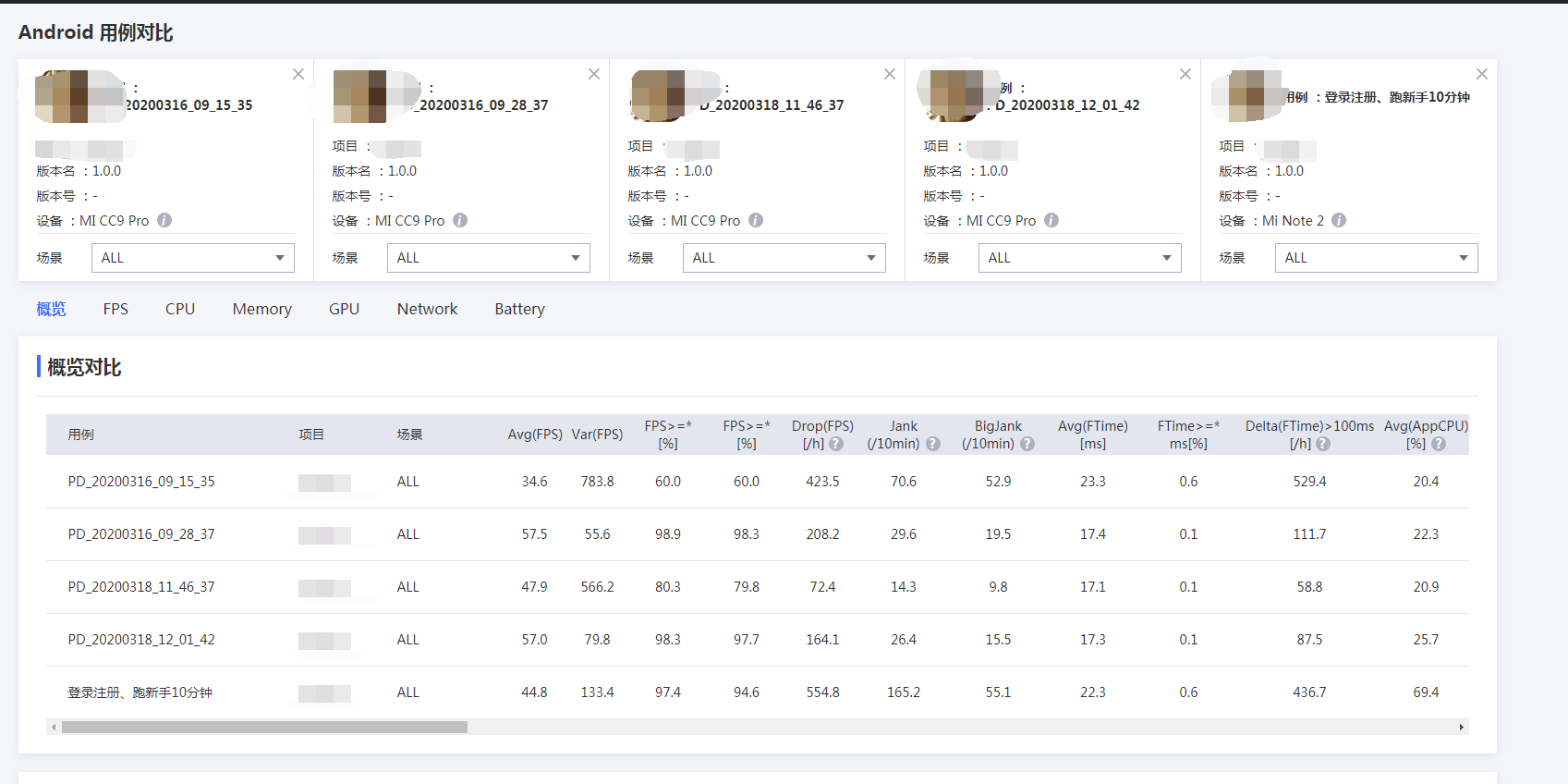
5.数据对比
首先在 web 后台上选择所在比对的数据
 选择完毕后打开对比界面就可以对比历史测试用例的数据啦,FPS,cpu,内存,GPU,网络,耗电量啦都可以对比,十分便捷。
选择完毕后打开对比界面就可以对比历史测试用例的数据啦,FPS,cpu,内存,GPU,网络,耗电量啦都可以对比,十分便捷。
更详细的的使用说明可以在这里查看使用说明
下面简单分享一下在游戏开发中一些细节优化
看一下代码
float f_a = 66666888f;
float f_b = f_a + 0.01f;
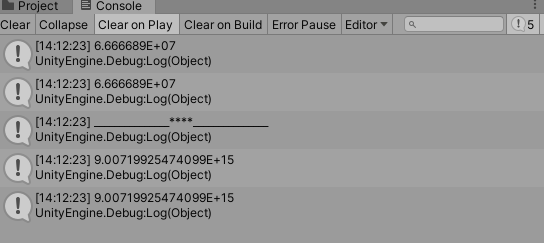
Debug.Log(f_a);//1.677722E+07
Debug.Log(f_b);//1.677722E+07
Debug.Log("_______________****_______________");
double d_a = 9007199254740992f;
double d_b = d_a + 0.01f;
Debug.Log(d_a);//9.00719925474099E+15
Debug.Log(d_b);//9.00719925474099E+15
输出结果;
实际上
一是二者存储结构不同;
二就是就是浮点数精度的问题;
float 把 32 位分成了 3 部分,1 位(符号位)8 位(指数位)23 位(有效数字)那么 1+ 8 + 23 等于 32 吧,所以 float 的 32 位是这么来的。23 位有效数字就表示 float 真正能存的精度,23 位小数部分是反被储存的部分,所以它是有 24 位存储的,224(2 的 24 次方)=16777216 。
如果程序中有一个 float 的数值运算后的小数部分,如果超过 16777216.xxx 后运算的结果就会不准确;
double 则是 1 位符号位 +11 位指数 +52 位有效数字 = 64 位
有效数 253(2 的 53 次方)=9007199254740992,超过 9007199254740992.xxx 后运算的结果就会不准确;
而浮点数计算结果不同的 CPU 计算出来可能是不一致的,像帧同步等就基本告别浮点数了,尽量用整型代替浮点型,实在需要可以用定点数,但也要注意是否存在定点数转回浮点数的现象;
其实还可以巧用位操作符,
位操作符比传统乘除效率要高,适合大量计算时使用
例如:
int a = 100 >> 1 相当于除 2 取整 结果为 50
int a = 100 << 2 相当于乘 4 取整 结果为 400
不过不必要过分追求位运算,在许多比较老的微处理器上, 位运算比加减运算略快, 通常位运算比乘除法运算要快很多,但现代架构中, 情况并非如此:位运算的运算速度通常与加法运算相同(仍然快于乘法运算)。在现代处理机架构中编译器一般会自动优化为移位运算的。还有很多芯片已经内置了硬件乘法器(乘法器的模型就是基于 “移位和相加” 的算法);
1.MonoBehaviour 中,如果没有相应的事件要处理,要删除默认的空函数;
Update、FixedUpdate、LateUpdate 中,如果没必要每帧的逻辑,可以降低频率
Void Update(){
if(Time.frameCount%6==0){
//要执行的功能函数
}
}
2.如果间隔更长,没必要每帧的逻辑,使用周期性的协程更妥当,例如使用 InvokeRepeating 函数:
InvokeRepeating();
3.Gameobject 不可见时,设置 enabled = false 时,update 就会停止调用。
协程使用 yield return new WaitForSeconds() 将会每帧导致 大概 21Byte GC,而 yield return null 会产生 大概 9 Byte GC;
我们可以简单地通过复用一个全局的 WaitForEndOfFrame 对象来优化掉这个开销:
static WaitForEndOfFrame EndOfTest = new WaitForEndOfFrame();
// Start is called before the first frame update
void Start()
{
StartCoroutine(Test());
}
IEnumerator Test()
{
yield return null;
while (true)
{
//原本是yield return new WaitForEndOfFrame();
yield return EndOfTest;
}
}
实际上实际上,所有继承自 YieldInstruction 的用于挂起协程的指令类型,都可以使用全局缓存来避免不必要的 GC 负担。常见的有:
WaitForSeconds
WaitForFixedUpdate
WaitForEndOfFrame
可以自己新建文件 xxx.cs 这个文件里,集中地创建了上面这些类型的静态对象,使用时可以直接这样:
yield return xxx.GetWaitForSeconds(1.0f);
6.使用内置数据代替新建数据
例如: 使用 Vector3.up 而不是 new Vector(0, 0, 0);

7.缓存组件,缓存 Gameobject,调用 GetComponent 函数会有查找开销,用变量挂载到脚本使用,降低开销 (GetComponent 时如果获取到空的组件也会产生 GC)。在脚本挂载对象引用,可减少查找。
8.查找对象标签用 if (go.CompareTag (“xxx”) 来代替 if (go.tag == “xxx”)。GameObject.tag 会在内部循环调用对象分配的标签属性,并分配额外的内存,并且效率也更低。
9.使用委托机制代替 SendMessage,BroadcastMessage,SendMessageUpwards 这三个函数。
因为它们的实现是一种伪监听者模式,利用的是反射机制,性能非常低。具体的性能大概是委托的十分之一。
需要频繁实例化的 gameobject 比如子弹,需要放入对象池,可以大量减少实例化,销毁的开销。将部分耗时资源进行预载。
设置 Active/Deactive 复杂对象所用的耗时会比较大,这里可以使用一个小技巧,可以将需要 Deactive 的操作变成将 GameObject 移动到比较远的,摄像机之外。然后将 GameObject 上面的全部 Component 的 enabled 属性设置成 false。Active 时再重新设置回来
foreach 每次调用会产生有 40Byte 左右的 GC 数据,产生 GC 的根本原因是使用了 using 语句。(GetEnumerator() 返回值类型,在
using 中装箱了)
数组:内存中是连续存储的,索引速度非常快,赋值与修改元素也很简单。但不利于动态扩展以及移动。因为数组的缺点,就产生了 ArrayList。
ArrayList:使用该类时必须进行引用,同时继承了 IList 接口,提供了数据存储和检索,ArrayList 对象的大小动态伸缩,支持不同类型的结点。
ArrayList 虽然很完美,但结点类型是 Object,故不是类型安全的,也可能发生装箱和拆箱操作,带来很大的性能耗损。
List 是泛型接口,规避了 ArrayList 的两个问题。
