背景
纵然市面上存在大大小小、各种语言的接口自动化工具,但阅览之后,总觉得部分与自己的期望不符(或者说有些自己的业务无法实现),遂有了自己从 0 撸一个的想法。
因为这几年接触的测试团队中,都是代码基础薄弱或者压根没有的伙伴,所以自己对工具有以下期望:
- 无需有代码基础
- Web 界面可视化操作
- 无特殊情况下,无需关心 token 相关
- 适应人群不止测试人员,应包含后端开发、前端开发人员
- 尽可能简单(操作和理解)
技术选型
因为自己编程这方便的能力也不强,Java 了解不多,语言能力方面 Python > Go > Js > Java,所以生态圈自然围绕着 Python 来实现。
所以项目的技术栈是 Flask + Vue(单页面)
部署用的 Nginx + Gunicorn + Supervisord
项目经历
第一行代码始于 2017 年,当时我负责推动这个项目,从想法到需求到实现均为个人完成(后期有一个团队内对代码感兴趣的小伙伴帮忙维护,加一些其他功能)。
但当时由于正常的测试工作干扰(项目多、迭代频繁、人手不足)及自身能力的不足,导致此项目虽具雏形,但在健壮性上做的很差,导致用例维护麻烦,团队内部推广的不是很好,所以就此搁置了。
两年后换了一份工作,做的是性能方面的测试,相对于之前的喋喋不休的业务测试来说,时间上有了部分充裕,但团队性质和之前无异,所以重新又捡起了这个项目,再次经过一番打磨后,相对算是能正常使用了吧,但还是存在一些自己目前不知道怎么能更好的处理的不足,后面会提及。
功能及交互展示
特性
- 支持层级组织
- 支持单个运行、批量运行
- 支持参数化
- 内置封装函数
- 写死的变量
- 动态变量
- 从数据库中获取数据
- 支持链式过滤目标数据
- 支持调试(运行时)的中间记录
- 多种校验方式
- Json 参数格式化
- 变量的嵌套
- 用例与环境解耦
登录
项目本身只部署一套。
为了隔离环境、隔离用户、所有接口调用需要携带 token,所以需要使用各自的账户。
且为了方便一键获取所有 token ,登录的手机号需要同时可以登录运营平台、供应商平台和 APP,且两个平台的密码需要一致(APP 因为没有密码一说,所以不作此要求)。
在登录时,以上三个平台任何一个登录失败都会导致接口测试平台无法登录。此强约束是为了在平台内部进行测试的时候,不用关心环境、平台等因素,只需要录入用例,然后执行。

目前支持三个环境的登录, 选择具体环境后,登录时会去自动调用选择环境下的运营平台、供应商平台、APP,并存储三方 token。在登录的同时,会开启一个线程去轮询各平台下的一个接口,使 token 保持有效期,目前设置的轮询时间为 25 分钟一次。
登录后,右上角会显示当前登录用户和所属环境,在执行用例时,会在此环境下执行。所以用例是和环境不挂钩的,需要在什么环境回归,只需要退出重新选择环境登录即可。
用例组织
目前分为三层,分别是 项目 → 模块 → 接口(用例),所以在录制用例时,必须将其所属于某一项目下的某一模块。当然,这个从属关系是可以灵活变更的
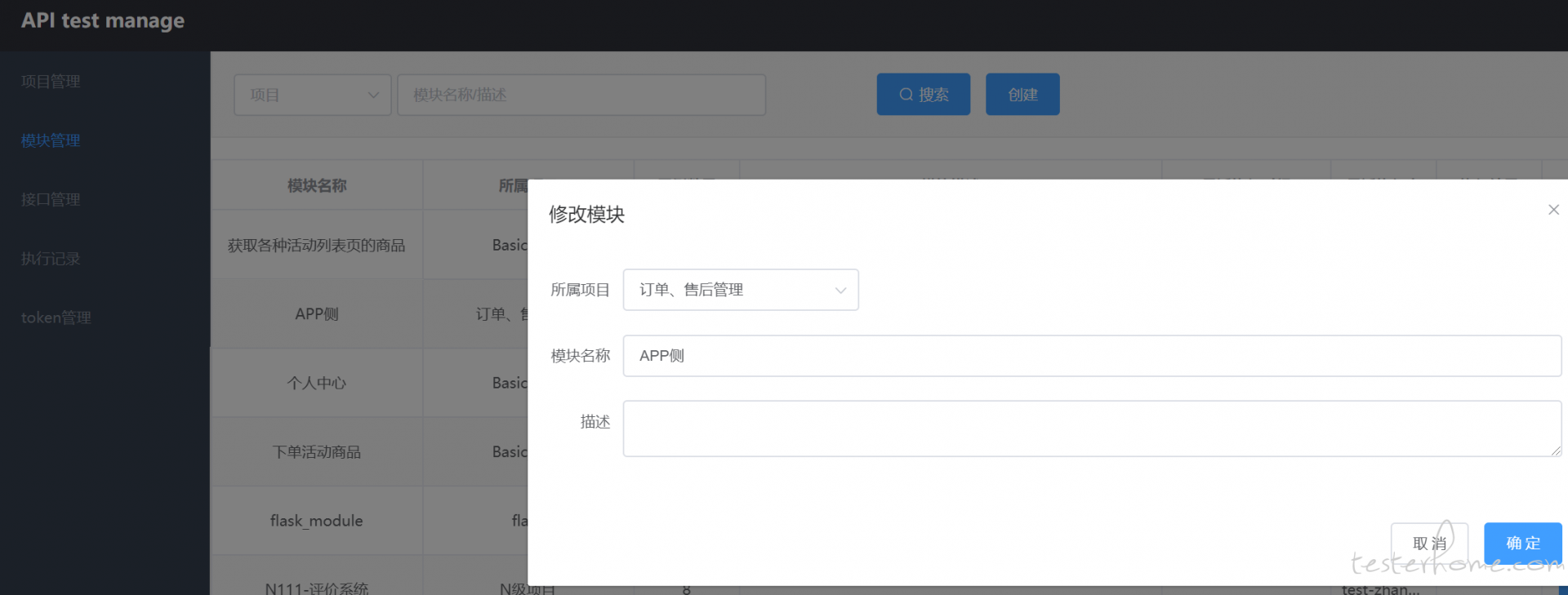
需要变更时,只需要修改用例的所属项目、所属模块或者修改模块的所属项目即可。
用例定义
- 变量定义
- 参数定义:以变量的形式存在,目前支持如下几种类型
- 纯粹作为前置流程中的一环,调用其他接口
- 如某个变量名称为 test, 值为 {"type": "interface", "id": 100},json 中没有指定 data 和 match 等参数,则表示先执行 id 为 100 的接口,此接口的参数就用它自己保存的数据去发起调用
- 作为前置流程中的一环,调用其他接口,并从响应内容中按照指定的过滤规则拿到目标数据赋值给变量
- 变量名称为 test, 值为 {"type": "interface", "id": 100,"data": {"key1": "value1"}, "match": "data.list.1.id"},则表示先执行 id 为 100 的接口,此接口的执行参数为 {"key1": "value1"},并根据 match 的值,按照 response["data"]["list"][1]["id"] 的规则取得 id 值,然后赋值给 test 变量
- 从数据中检索数据,将结果赋值给变量
- 变量名为 test, 值为 @{select user_id, user_phone from test_user.user where user_name = 'xxx' limit 1},则表示执行此 sql, 返回结果为 [user_id, user_phone] 并赋值给 test 变量
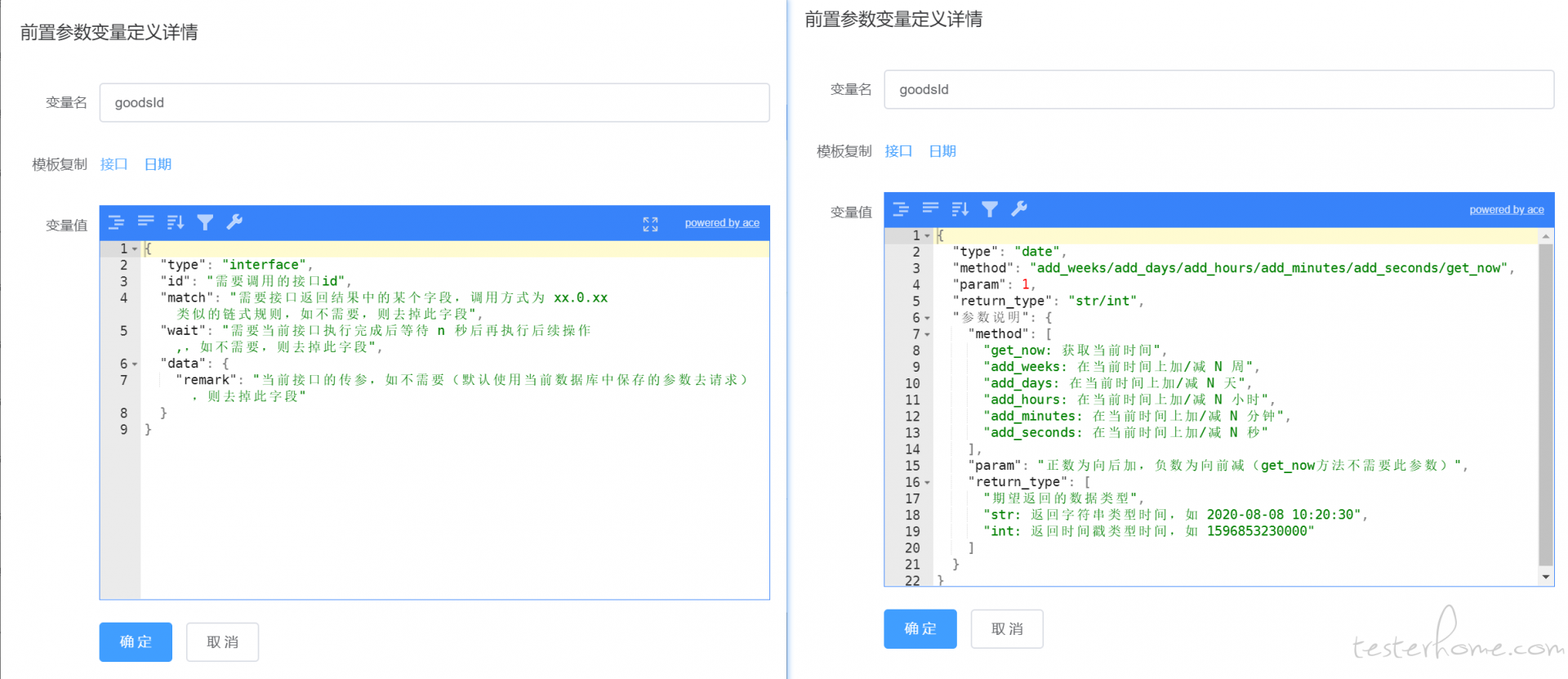
- 提供内置封装的函数调用
- 变量名为 test, 值为 {"type": "date", "method": "add_days", "params": 2, "return_type": "str"},则表示执行内置函数 add_days,传参为 2,返回值类型为 string(获取今天往后 2 天的字符串类型的时间值),然后赋值给 test 变量
- 目前主要用到的内置函数主要是调用其他接口和日期的生成,可以点击模板一键生成,然后改动即可
- 参数值写死(固定的值)
- 变量名为 test, 值为 100,则表示将 100 赋值给 test 变量
- 参数调用
- 在 接口地址 中调用:如 /open/category/index/one?cid=${test} 使用 ${} 标识占位,值为变量名。 ${test} 标识获取变量 test,假如变量 test 的值为 100,则实际的接口地址为 /open/category/index/one?cid=100
- 在 请求参数 中调用:如 {"key1": "${test}"} 使用 ${} 标识占位,值为变量名。 ${test} 标识获取变量 test,假如变量 test 的值为 "value1",则实际的参数值为 {"key1": "value1"}
- 注:参数列表中的所有变量按照列表顺序执行,所以需要按照实际顺序录入。当实际位置与期望执行顺序不符时,列表中拖动当前行到目标位置即可
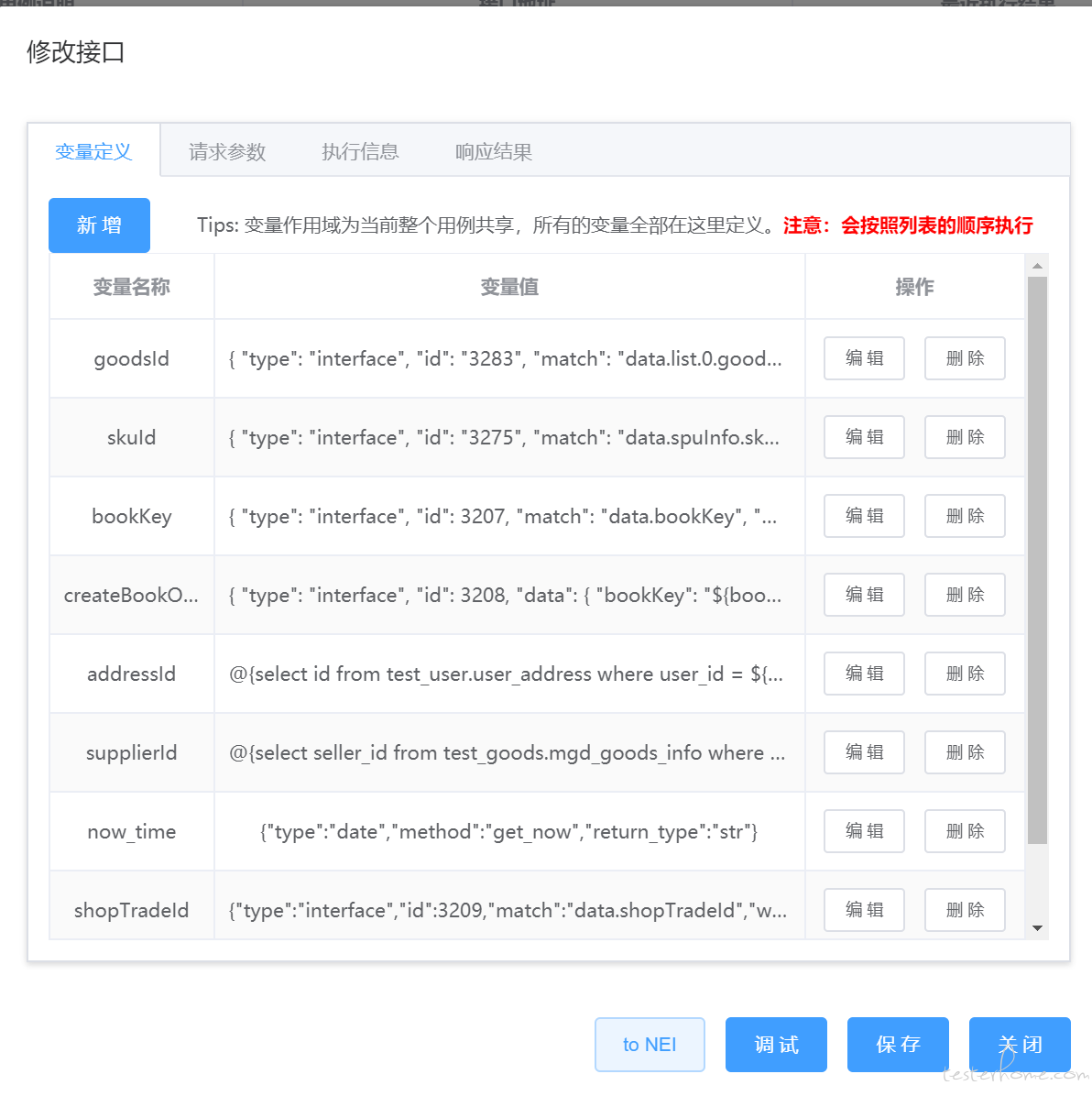

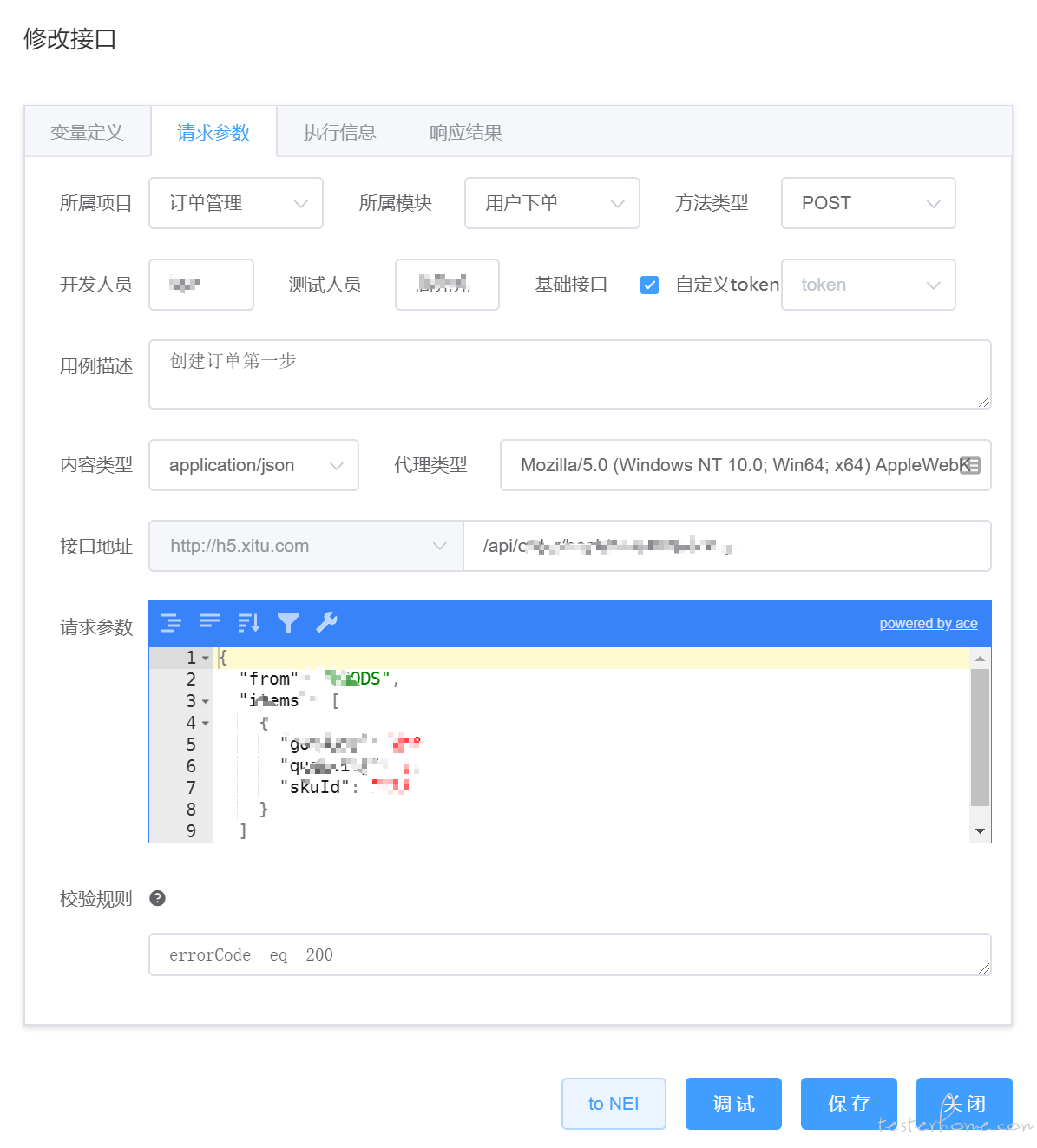
- 请求参数
- 指定当前用例、接口所属的项目和模块
- 为方便维护,指定开发责任人和测试责任人(默认为当前登录用户)
- 添加详细的用例描述(为便于维护,尽可能写详细些,表述这条用例的设计思路以及想要验证什么)
- 指定请求方法类型(GET/POST/DELETE/PUT)、Content-Type(默认为 application/json)、User-Agent(没有特殊需要,保持默认即可)
- 指定 host 以及接口地址,其中 host 去除了和环境的强绑定(公司各环境绑定的不同的域名,host 前缀为环境名称,如 test.xxx.com / dev.xxx.com)
- 指定实际的请求参数,Get 类型无需 Body 体,保持默认为空即可,POST 类型则必须添加
- 是否是基础接口:当勾选时,即表示当前用例被作为基础用例,主要目的是用来被其他用例复用。在批量执行某项目、某模块的所有用例时,此用例不会被单独执行,它们的执行实际往往在其他用例的上下文之中。
- 校验
支持以下几种校验方式
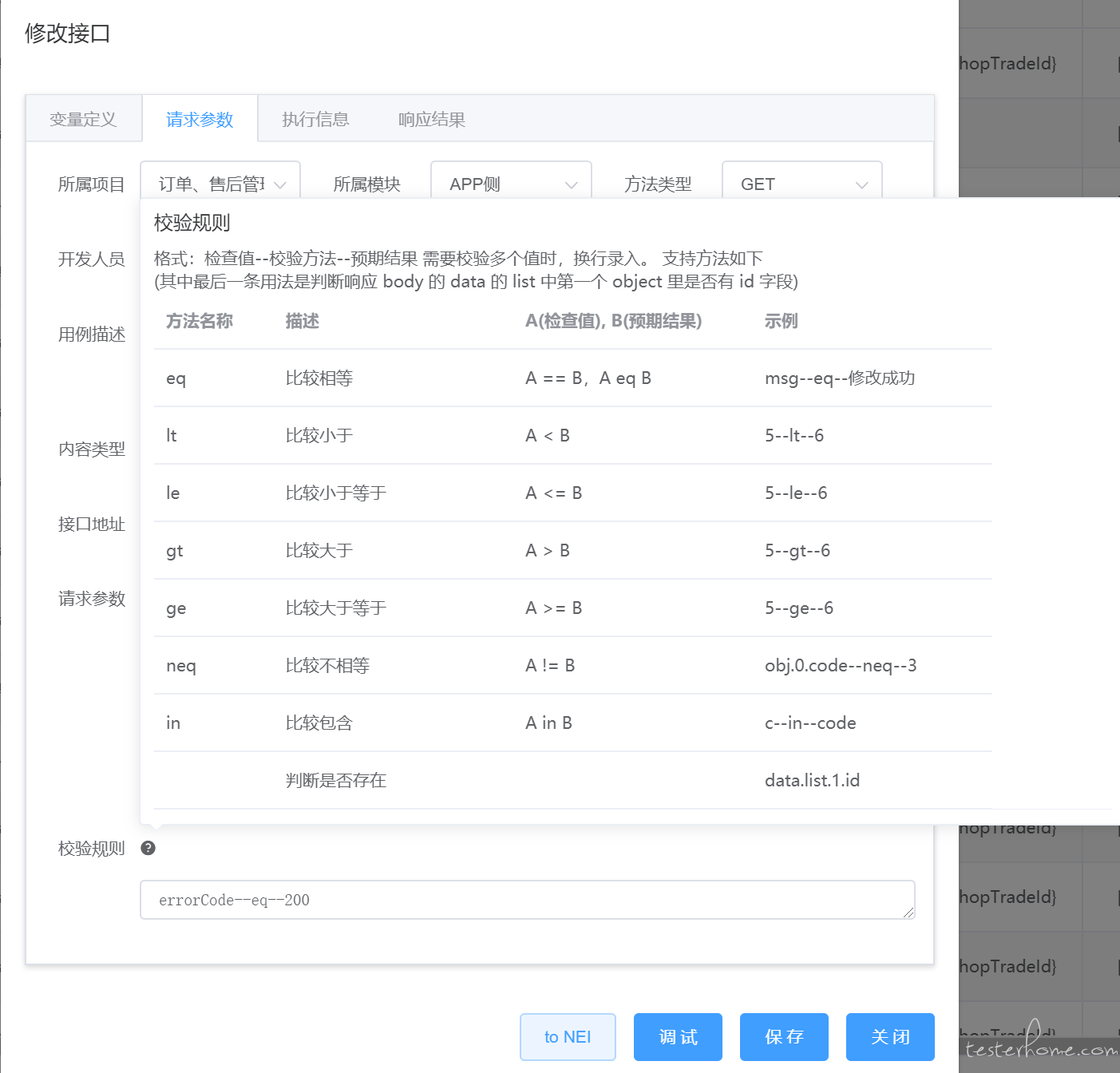
校验规则支持多条(回车新行视为新的校验规则),当存在多条时,前面任意一条不满足,则会终止后续流程,当前用例会被判定为失败。
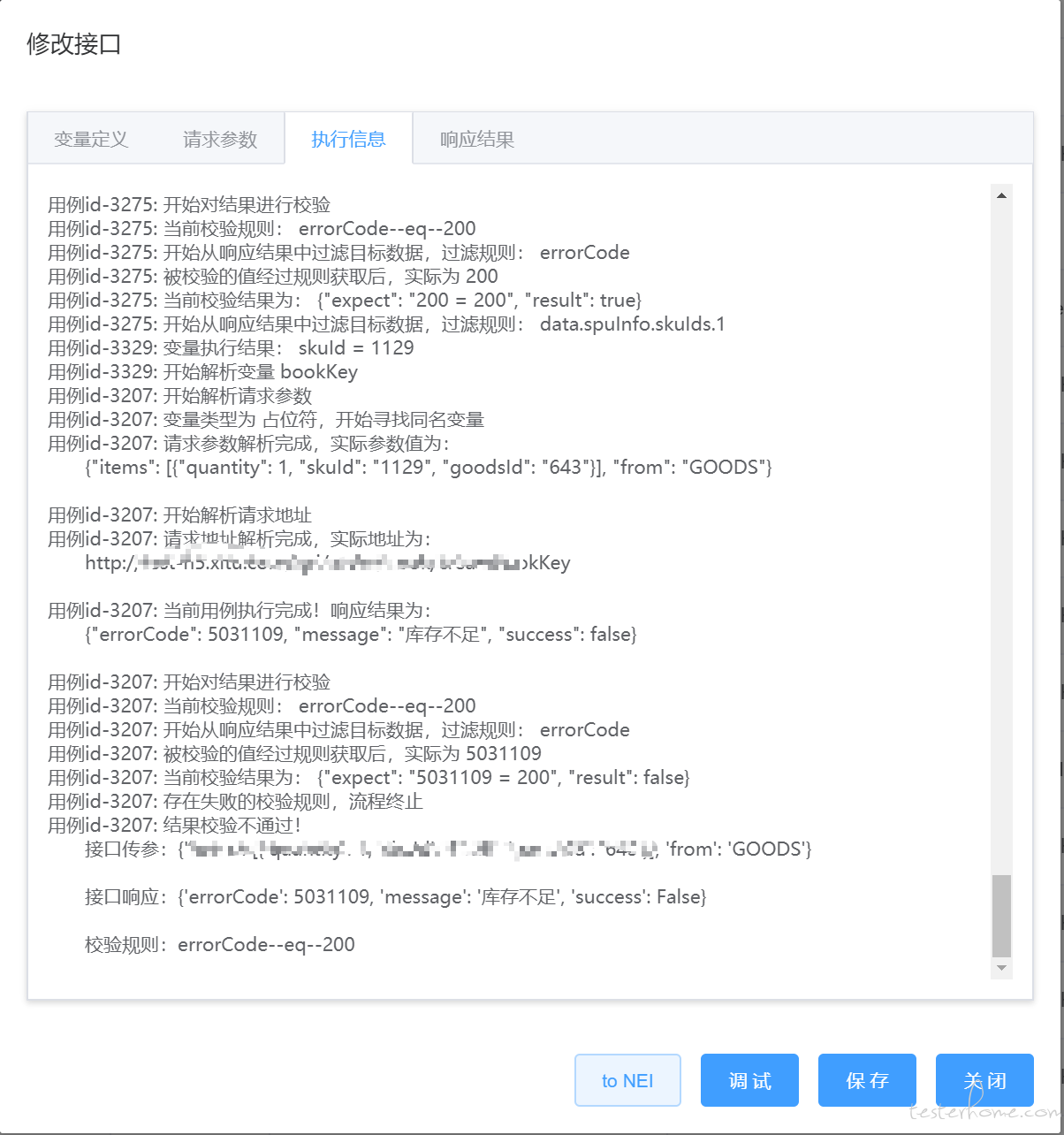
- 执行过程
- 因为支持用例复用,当业务较为复杂时,前置依赖过多,流程会很长,无论是执行还是调试,一旦出现失败会很难定位,所以后台在执行过程中,会将每一步的执行记录传至此面板中供分析定位。包含变量的实际值、接口的实际地址、实际传参、实际响应数据等。
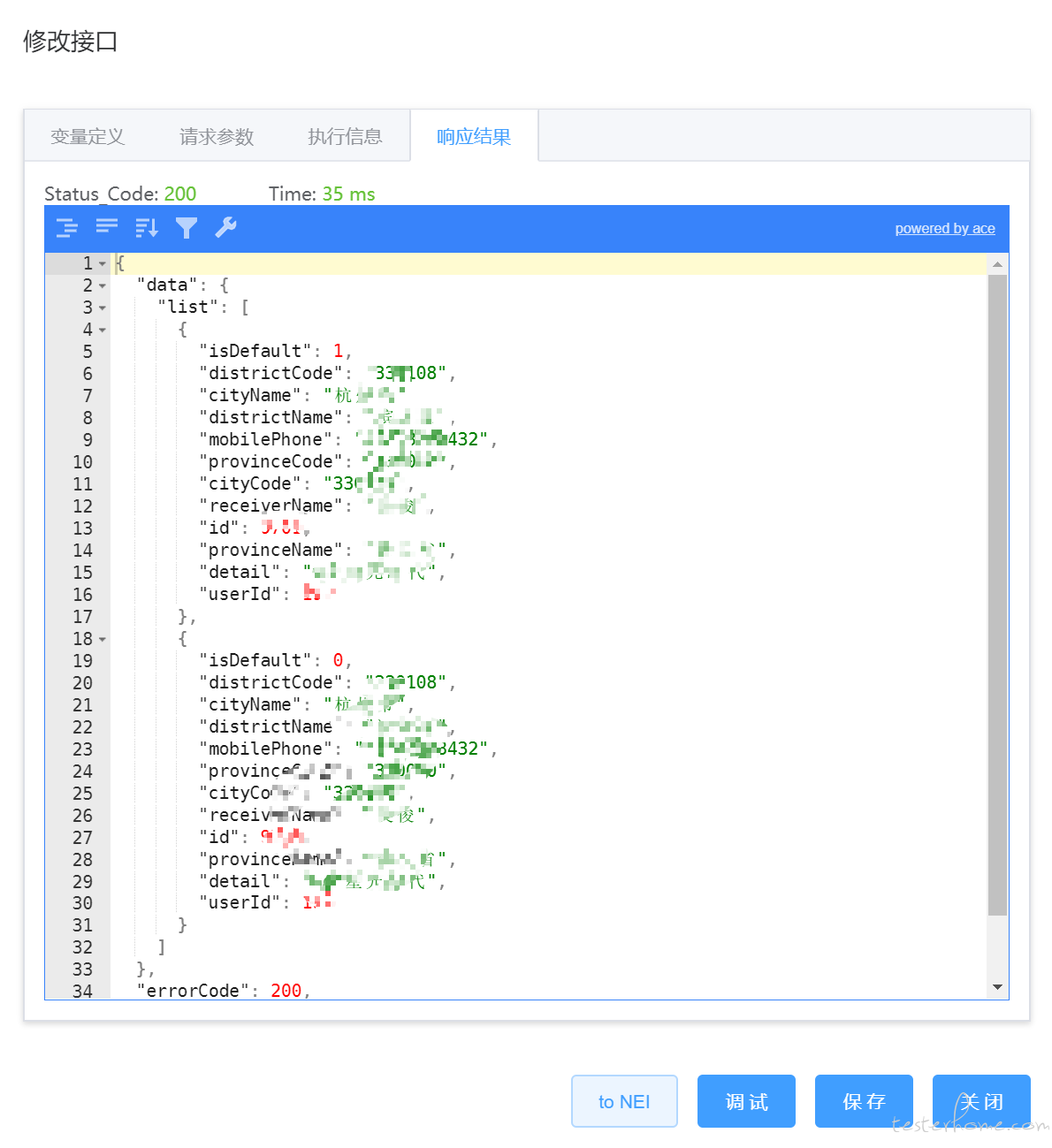
- 响应结果
- 解析并展示实际响应数据,支持对 json 格式数据的展开、收缩等操作。面板中包含响应数据、http 请求状态码以及响应时间
- to NEI 功能会在新 tab 页中打开 nei 系统(网易的 api 管理工具),默认跳转到 当前接口地址的搜索页面。当在自定义参数时,可能需要了解某个参数的具体意思,需要参考 API 文档,此时可以一键跳转查看 API 参数的定义
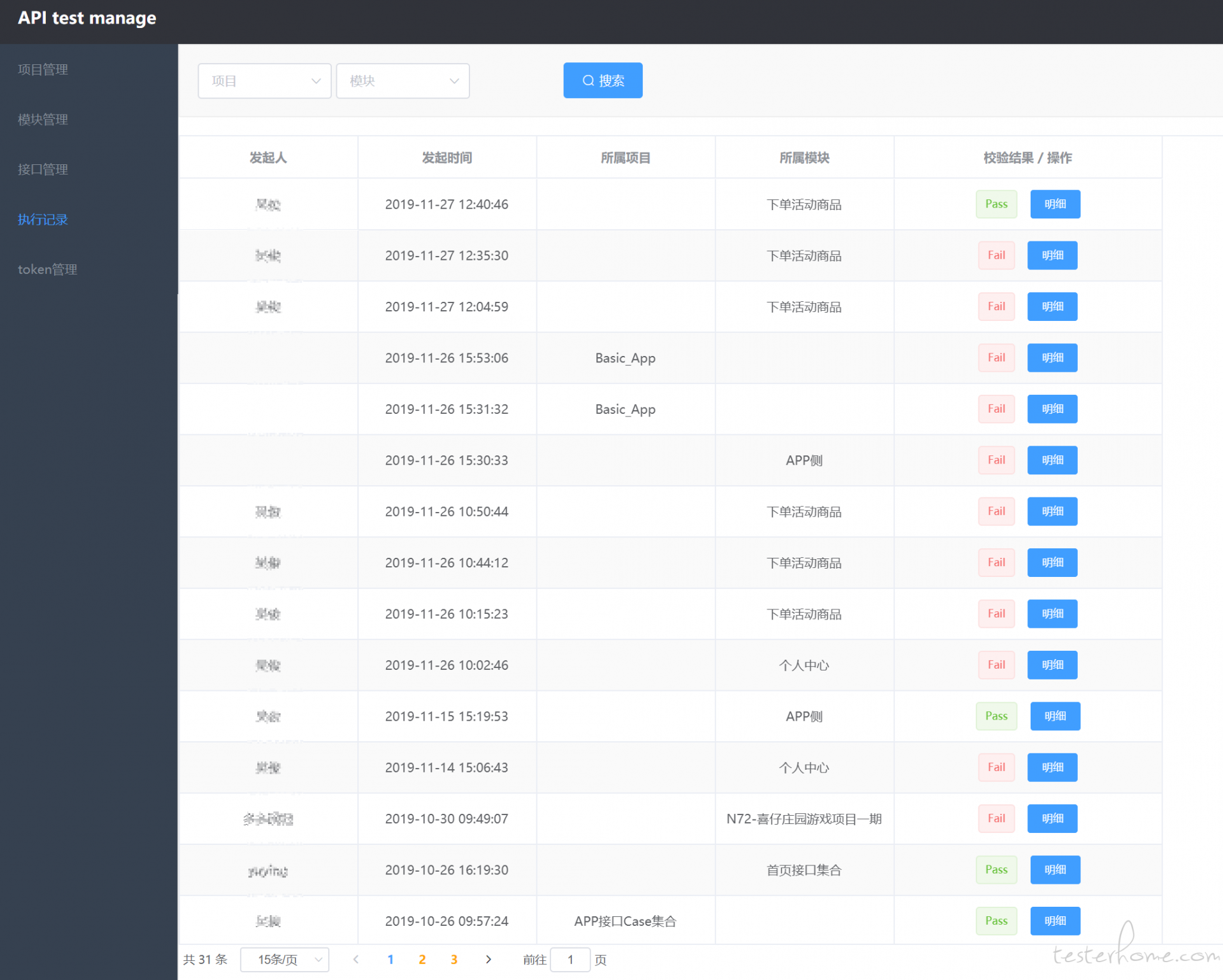
回归
直接在项目页面或者模块页面,搜索出需要回归的项目/模块,直接点击操作列的运行,即可批量、并发去执行项目、接口下的所有有效用例(不包含被标注为基础用例的用例)
视用例数量,可能会执行几秒到几分钟的时间,且执行记录在【执行记录】页面中可以查看(当操作列中没有标识 Fail 或者 Pass 时,则表示当前发起的回归动作还没执行完)
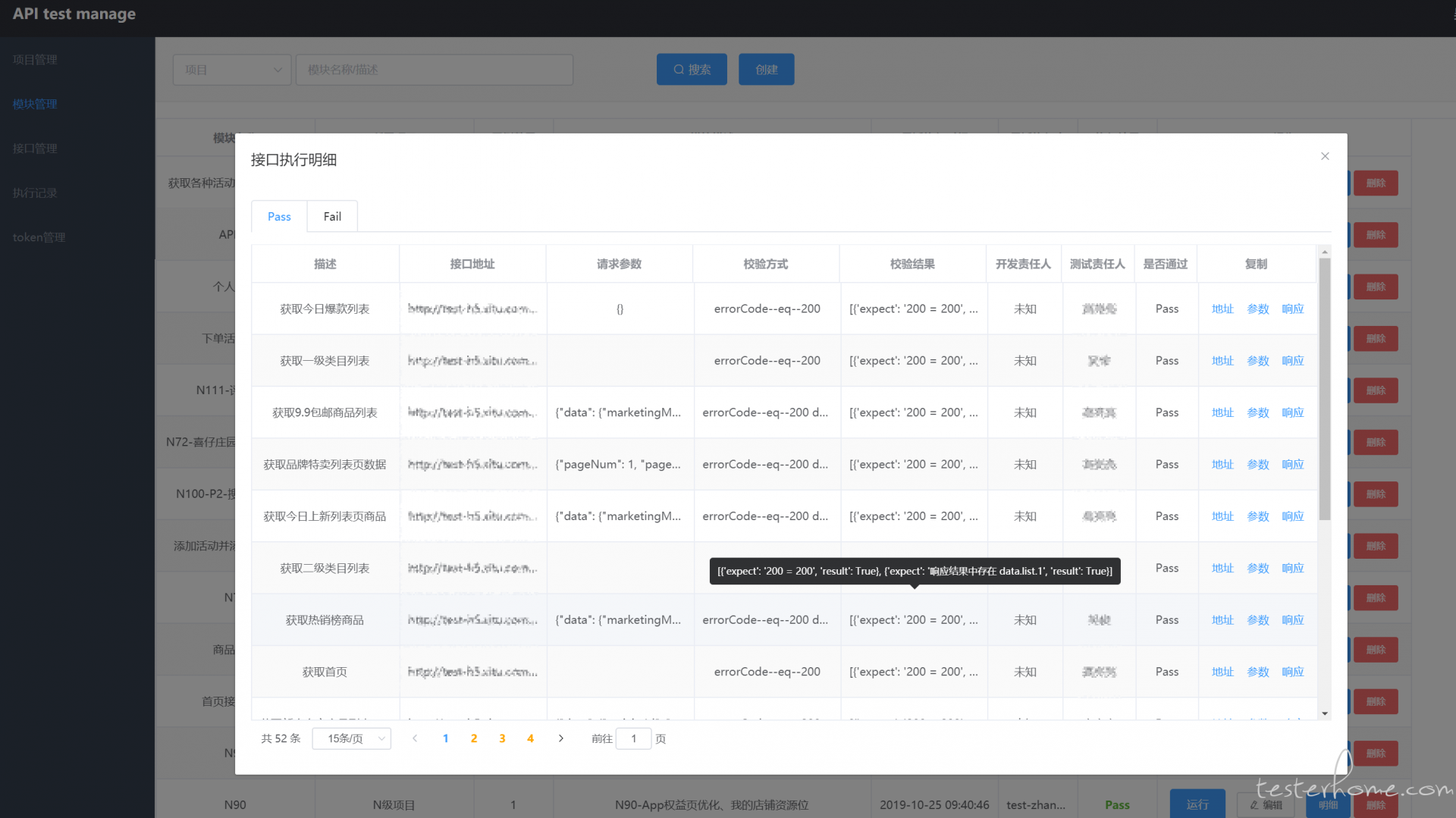
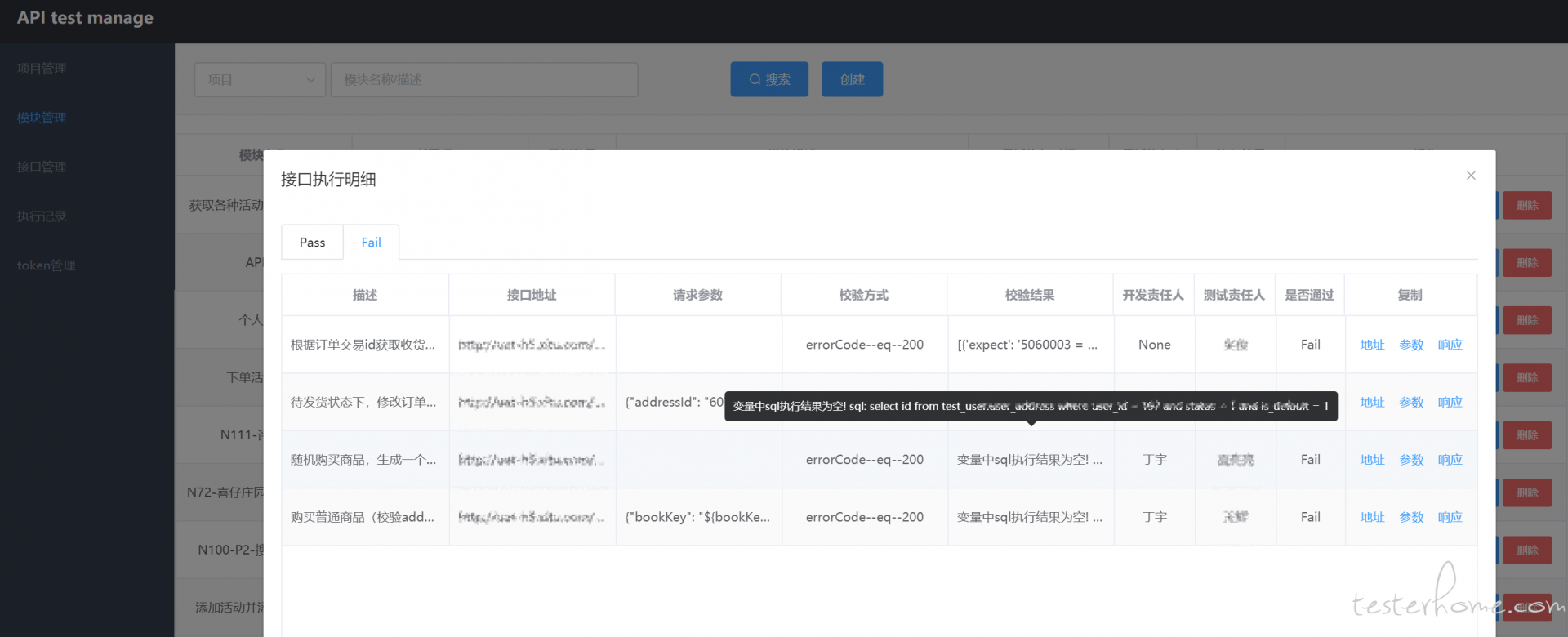
如果操作列为 Pass,则表示此次回归,所有的用例全部校验正常,没有失败用例,当操作列的值为 Fail 时,则表示此次回归存在一个或者多个校验失败的用例,可以点击 明细 按钮,查看失败、成功的用例,默认打开 失败 tab。在复制列中,可以复制运行当时的实际地址、参数、响应、校验内容(不过还是建议在用例列表中搜索当前失败的这条用例,打开详情页进行调试,会有过程数据辅助定位失败原因)
测试报告
没有和现有市场上的测试报告一样,我这里是将每次回归动作记录下来,并将其下所有的用例分为 Pass 和 Fail 面板来统计
可以从单独的记录页面进入,也可以从项目 / 模块列表页进入
不足
- 对于简单逻辑的用例来说,确实很方便,几秒钟就可以录入一条用例。但对于有些复杂业务来说,无法做到有效用例解耦,依赖链路会比较长,且通过 ui 的方式来录入会稍显繁琐
- 没想到好的测试数据构建的方式。通过调用其他接口生成 or 直接写 sql 插入的方式都试过,效果都不太理想
- 其他接口生成会导致强依赖,一旦当前这个接口出现问题,会导致所有依赖这个接口的用例全部 fail
- 直接写 sql:现在的系统已经不仅仅是数据从 mysql 数据库获取了,有的会从缓存,有的会从 es 或者其他 db,在手动生成数据时,必须要明确的知道当前业务背后的实现方式、使用到的中间件。且就拿写 sql 来说,某一条数据可能会关联多张表,且可能会有多个字段在其他表中冗余,一旦你对内部实现不清楚,就是一条脏数据,排查都需要 N 久
- 没有想好较好的类似于 teardown 的清理功能怎么实现(setup 可以理解为前置参数这个功能已经实现了)
特别是测试数据,现在最头痛的就是这个,也看过很多其他人的方案,但都感觉和自己这边不贴合。
所以有在这方面做的自认为比较满意的伙伴贡献下自己公司的方案么。。。

↙↙↙阅读原文可查看相关链接,并与作者交流