性能测试中,对服务端的指标监控也是很重要的一个环节。通过对各项服务器性能指标的监控分析,可以定位到性能瓶颈。
后端性能指标有 CPU,内存,网络,jvm,I/O 等等
整体系统 CPU 利用率
内存利用率
磁盘 I/O 的利用率和延迟
网络利用率
监控命令:vmstat、sar、dstat、mpstat、top、ps
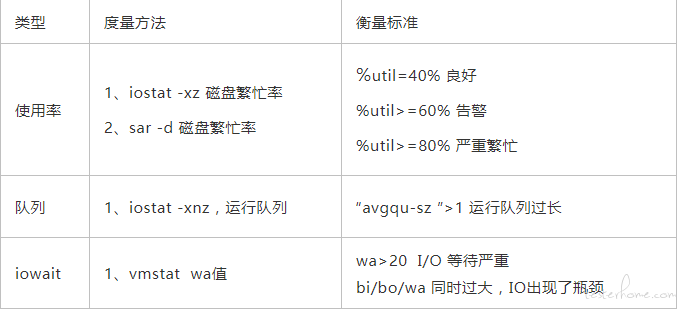
| 类型 | 度量方法 | 衡量标准 |
|---|---|---|
| 利用率 | 1、vmstat 统计 1-%id 2、sar -u 统计 1-%idle 3、dstat 统计 1-%idle 4、mpstat -P ALL 统计 1-%idle |
user%+sys%<70%(好) 70%<user%+sys%<=85%(坏) |
| 负载 | 1、vmstat 的 r 值 2、sar -q ,“runq-sz” 3、load average 4、pidstat -p【pid】-w 1 10 |
r 长期>cpu 个数,cpu 不足 runq-sz 长期>cpu 个数,cpu 不足 load average>cpu 内核数(cpu 繁忙) nvcswch/s 较大,cpu 时间片不足 |
物理内存不够时就会使用 swap 分区,所以性能测试过程中需要关注 swap 和 mem 的使用情况。物理内存不够,大量的内存置换到 swap 空间,可能导致 CPU 和 I/O 的瓶颈。
监控命令:vmstat、sar、dstat、free、top、ps
监控命令:sar、ifconfig、netstat,以及查看 net 的 dev 速率。
通过查看发现收发包的吞吐率达到网卡的最大上限,网络数据报文有因为这类原因而引起的丢包、阻塞等现象都证明当前网络可能存在瓶颈。
为了减小网络对性能测试的影响,一般我们都在局域网中进行测试执行。

I/O 的 TPS、平均 I/O 数据、平均队列长度、平均服务时间、平均等待时间、IO 利用率(磁盘 Busy Time%)等指标
监控命令:sar、iostat、iotop
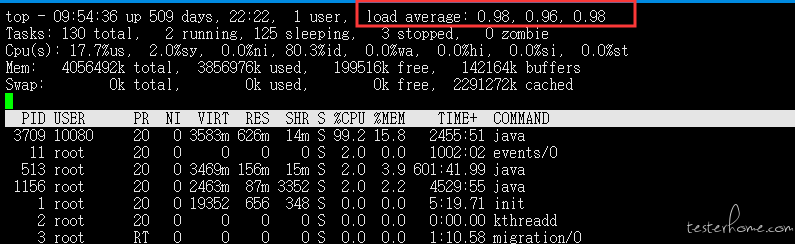
1:top 看 CPU 负载,vmstat 看 CPU 利用率。下面三种情况说明 cpu 没有正常工作,需要看 cpu 在做什么
1)负载过高,利用率过低
2)负载过低,利用率过高
3)负载过低,利用率也低
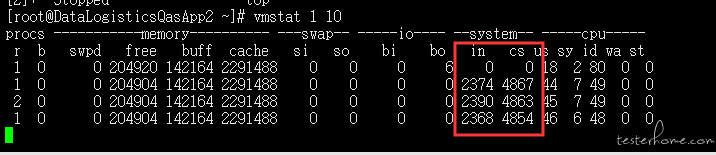
1:vmstat 看 in 和 cs 是否过高,如果过高,说明中断和上下文切换频繁
2:vmstat 看 usr 和 sys 百分比。
1)如果 sy 百分比过高,说明 cpu 大部分时间花在了内核的系统调用
2)如果 us 百分比过高,说明 cpu 大部分时间花在了代码执行

3:vmstat 看运行队列
1)运行队列 r 值远超 cpu 数,说明 cpu 负载过高
2)b 值过高,说明大量进程处于 IO 等待,IO 可能存在瓶颈
1:pidstat -p【pid】-w 1 10 看进程的主动和被动切换。

1)如果主动切换(cswch/s)过高,说明可能 IO,内存资源可能不足
2)如果被动切换(nvcswch/s)过高,说明进程过多,cpu 时间片不足
2:watch -d cat /proc/interrupts 查看系统中断