这里的不对等,并不是指的不公平,而是信息的不对等。测试更加偏重与业务知识,开发更加偏重于实现。这样往往会造成信息不对称,比如开发人员修改了 2 行代码,可能测试人员就需要把整改业务回归一遍,资源在浪费,产品发布迭代的周期在变长。
一个周期完成了,开发提供了可交付物是代码,测试提交了可交付物是用例,业务对应着代码,我们的用例也应该对应着代码。
开发人员的代码完成了,可以由测试证明没有问题。那么测试完成了,我们应该由谁来证明。
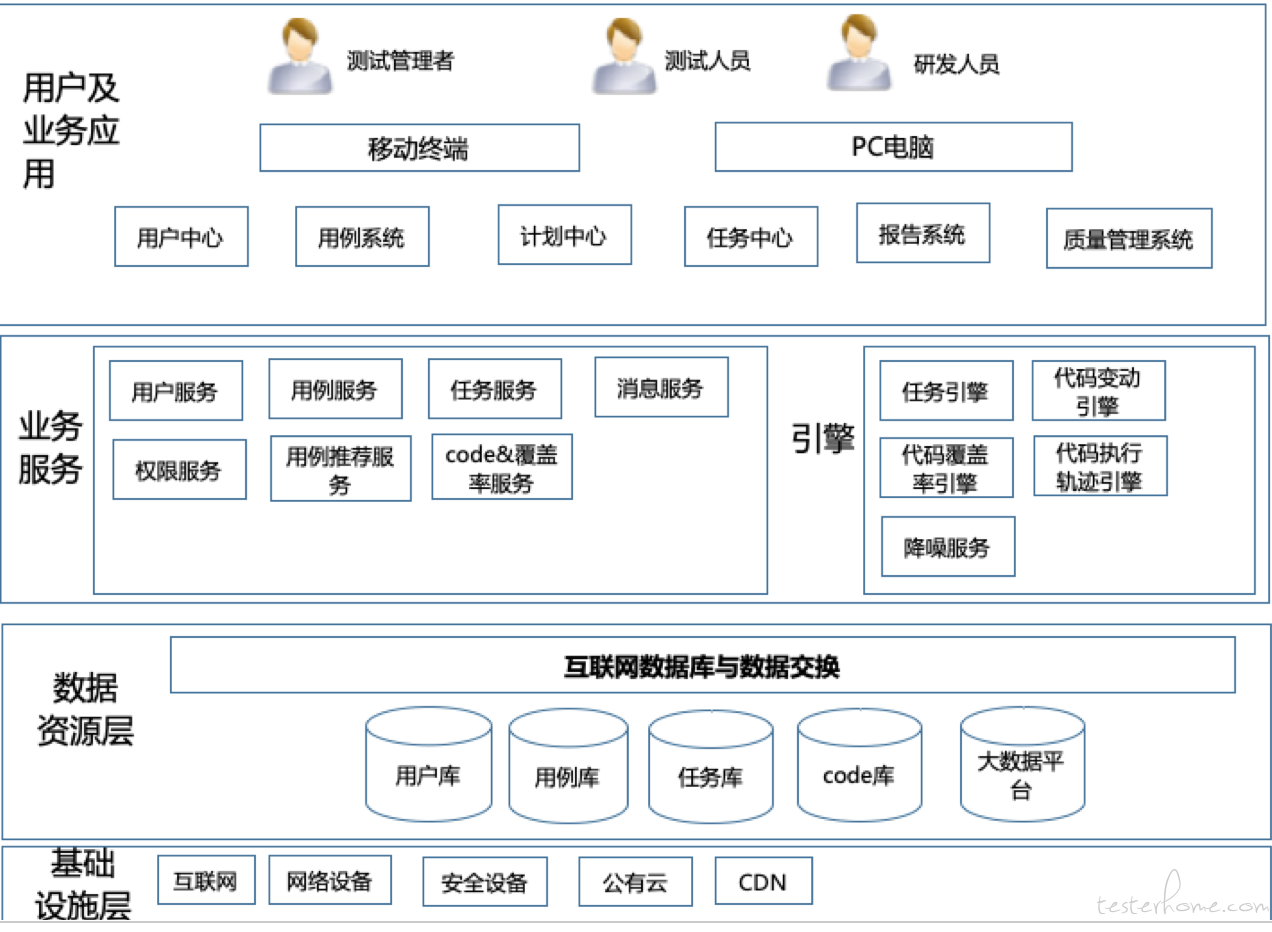
开发了用户中心、权限模块、用例模块、任务/计划模块、报告模块、覆盖率能力构建
- 精准分析
在基础模块实现的基础上,建立专业化的度量指标,用例评测测试过程质量。
实现覆盖率服务化,以及差异化的覆盖率功能。对新代码,可以查看新代码覆盖情况。修改代码,可以看差异化的代码测试情况。
- 精准推送
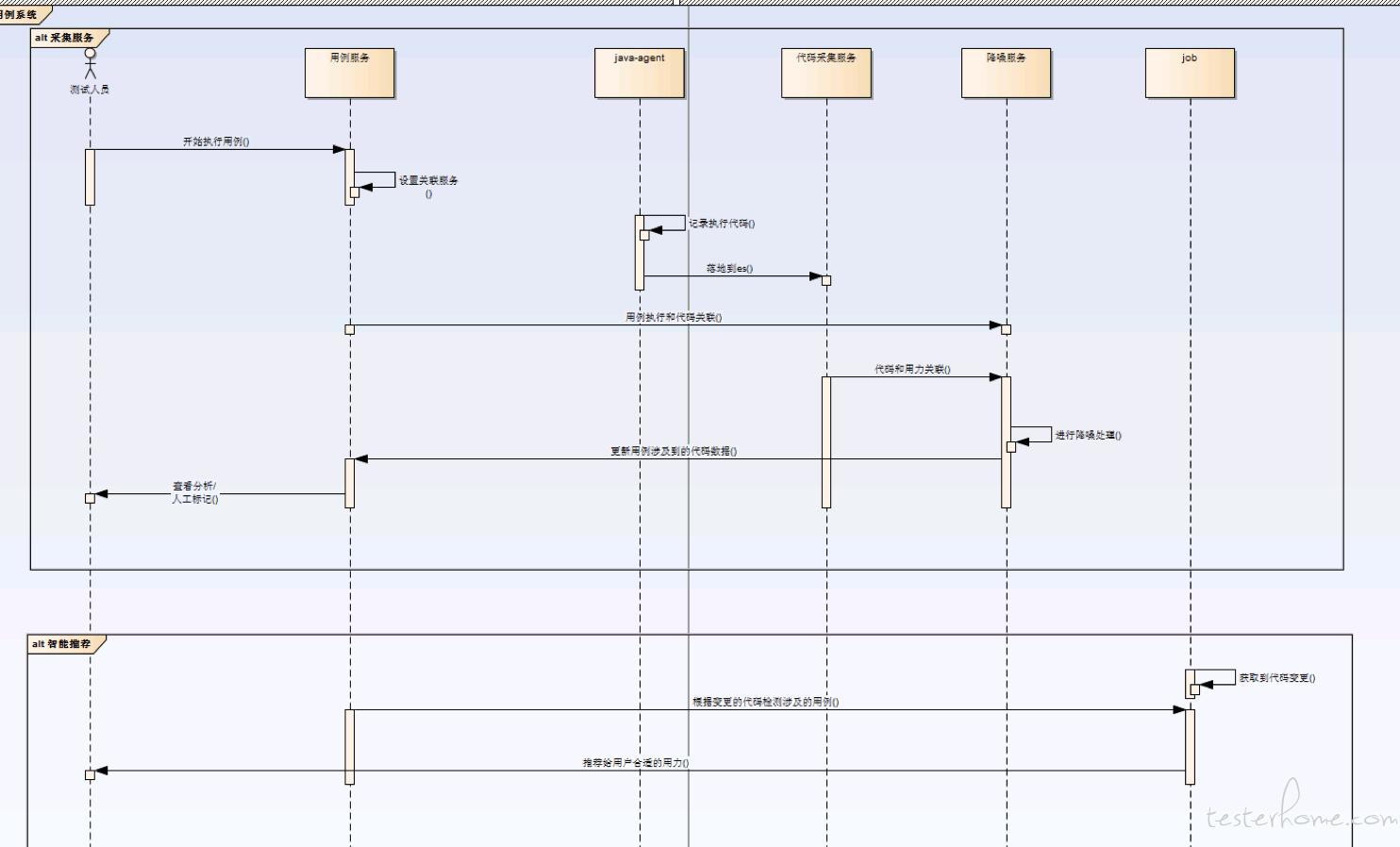
利用 java-agent 以及 bytebuddy 进行执行过程代码(类、方法)拦截,采用沙箱和主程序隔离,并且采用 flume-kafka-es,实现代码落地到 es 中。
采用降噪服务,关联用例和拦截到的执行代码,给用户推荐最合适用例/代码绑定关系,并且支持用户进行人工标准。
采用 svn-diff,按时间/构建来获取代码差异(类、方法),根据绑定关系给用户推荐合适用例。从而实现用例的精准推送。
