性能测试工具 locust 性能压测工具问题求助???
大家上午好:
今天用 locust 工具简单的压测一下接口。
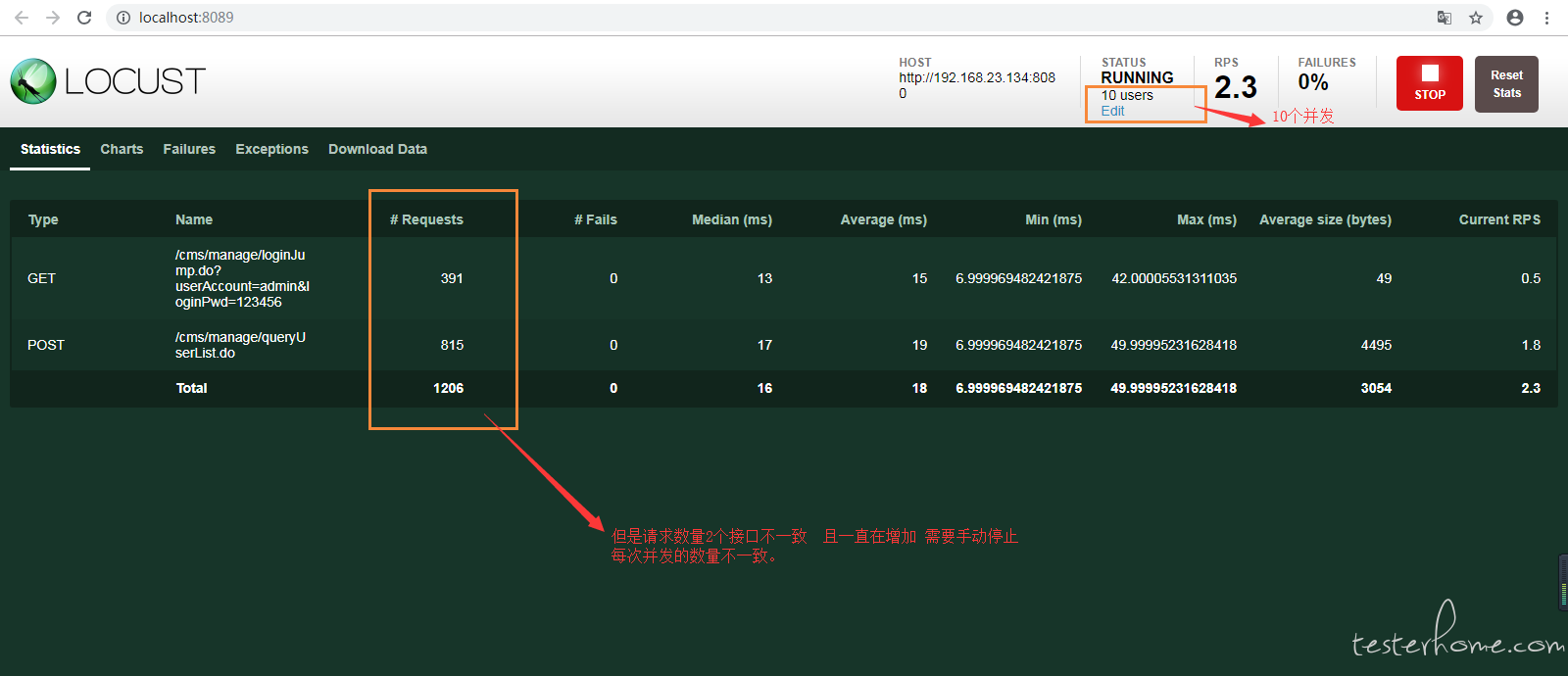
发现几个问题 我先设置集合点等待 10 个用户加载进来然后一起并发 发现这个 locust 的发送请求和 jmeter 里面的不一样
jmeter 里面是设置了集合点后等待所有的用户加载完假如 10 个并发会请求同一个接口 10 次然后就停止了,用察看结果树
可以看到这 10 个用户在同一时间访问这个接口的并发情况,但是用 locust 去做并发发现我设置了 10 个并发等待所有的用
户加载进来后 requests 请求会一直在增加。而且我对 2 个接口进行压测每个接口的请求数还不是一样的,关于这块有没有
大佬帮你解释一下。
如下为代码部分:
coding=utf-8
import requests
from locust import HttpLocust,TaskSet,task
import os
from locust import events
from gevent._semaphore import Semaphore
all_locusts_spawned = Semaphore()
all_locusts_spawned.acquire()
def on_hatch_complete(**kwargs):
all_locusts_spawned.release() #创建钩子方法
events.hatch_complete += on_hatch_complete #挂载到locust钩子函数(所有的Locust实例产生完成时触发)
class Cms(TaskSet):
# 访问cms后台首页
@task(1)
def cms_login(self):
# 定义请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36"
}
req = self.client.get("/cms/manage/loginJump.do?userAccount=admin&loginPwd=123456", headers=header, verify=False)
if req.status_code == 200:
print("success")
else:
print("fails")
@task(2)
def cms_queryUserList(self):
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36"
}
queryUserList_data = {
"startCreateDate": "",
"endCreateDate": "",
"searchValue": "",
"page": "1"
}
req = self.client.post("/cms/manage/queryUserList.do",data=queryUserList_data)
queryUserList_url = 'http://192.168.23.132:8080/cms/manage/queryUserList.do'
if req.status_code == 200: #u'查询用户成功!'
print("success")
else:
print("fails")
def on_start(self):
""" on_start is called when a Locust start before any task is scheduled """
# self.cms_login()
# self.cms_queryUserList()
all_locusts_spawned.wait() #限制在所有用户准备完成前处于等待状态
class websitUser(HttpLocust):
task_set = Cms
min_wait = 3000 # 单位为毫秒
max_wait = 6000 # 单位为毫秒
if __name__ == "__main__":
import os
os.system("locust -f lesson8.py --host=http://192.168.23.134:8080")
'''
semaphore是一个内置的计数器:
每当调用acquire()时,内置计数器-1
每当调用release()时,内置计数器+1
计数器不能小于0,当计数器为0时,acquire()将阻塞线程直到其他线程调用release()
'''
「原创声明:保留所有权利,禁止转载」