算法之递归(2)- 链表遍历
在递归(1)中,简单的介绍了递归的思想,并且通过一个例子简单阐述了递归是如何工作的,并且递归的实现是以线性结构来表示的。之所以用线性的,是因为其易于理解;如果使用树结构,将加大对问题的难度,不利于初学者理解递归的思想。
为什么用递归
关 于为什么用递归,我个人的理解是递归不要违背算法的初衷,即期待传入 xxx 值,加工后返回 xxx 值。不要为了递归而递归,容易造成对函数语义的奇异。另 外,通过递归,可以让代码更加整洁,短小,精湛,优美。当然,还会存在一定程度的性能损耗;不过,合理的使用,对于那部分的损耗可以忽略不计。
让我们以单链表为例,理解一下递归是如何工作的。
1. 遍历单链表
循环
private void TraveserL(LNode head)
{
if (head == null)
return;
while (head != null)
{
Console.WriteLine(p.data);
p = p.next;
}
}
递归
private void TraveserR(LNode head)
{
if (head == null)
return;
Console.WriteLine(head.data);
TraveserR(head.next);
}
对于循环遍历我想不用多说了吧。不过,值得注意的是递归的遍历,先对数据进行打印,然后遍历下一个节点。有趣的是,如果将打印语句放在递归调用的后面,将是一个逆序的打印。
分析
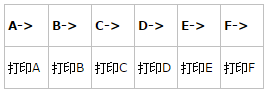
假设链表的结构是这样的
A->B->C->D->E->F
递归调用时将发生如下情形
1.在递归调用之前打印(意味着进入函数体的时候打印)
(1)进入函数(从左到右读)
输出:A, B, C, D, E, F.
(2)当函数退出(从右到左度)
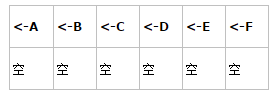
2. 在递归调用之后(意味着只有退出函数体的时候,才进行打印)
(1) 进入函数体(从左到右读)
(2) 退出出函数体(从右到左读)
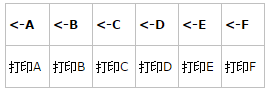
输出:F, E, D, C, B, A
结论,当操作在递归调用之后进行,那么是从后向前对链表执行操作。这也是栈的特性之一。当然,具体何时决定,取决与程序员自己,是想从头开始顺序操作,还是后到前逆序操作,具体问题具体分析。
