1、postgresql 自带提供了一款轻量级的压力测试工具:pgbench
2、可自行编写脚本,按自己的需求对数据库进行性能压力测试
3、postgres 软件安装配置,默认安装的位置是 /usr/pg-10/bin
4、在用 pgbench 操作前,先了解下 pgbench 命令 pgbench –help
-c NUM 数据库客户端并发数(默认:1)
-C(为每个事务建立新的连接)
-D VARNAME=VALUE 通过客户脚本为用户定义变量
-f FILENAME 从文件 FILENAME 读取事务脚本
-j NUM 线程数(默认:1)
-i 写事务时间到日志文件
-M{simple|extended|prepared} 给服务器提交查询的协议
-n 在测试之前不运行 VACUUM
-N 不更新表 “pgbench_tellers” “pgbench_branches”
-r 报告每条命令的平均延迟
-s NUM 在输出中报告规模因子
-S 执行 SELECT-only 事务
-t NUM 每个客户端运行的事务数(默认:10)
-T NUM benchmark 测试时间(单位:秒)
-v 在测试前清空所有的四个标准表
-p 显示每个进程所需要的时间
scale 乘以 10 万:表示测试数据量
range:表示活跃数据量
3、为 pgbench 设置环境变量
export PGHOST=<PostgreSQL实例内网地址>
export PGPORT=<PostgreSQL实例端口>
export PGDATABASE=postgres
export PGUSER=<PostgreSQL数据库用户名>
export PGPASSWORD=<PostgreSQL对应用户的密码>
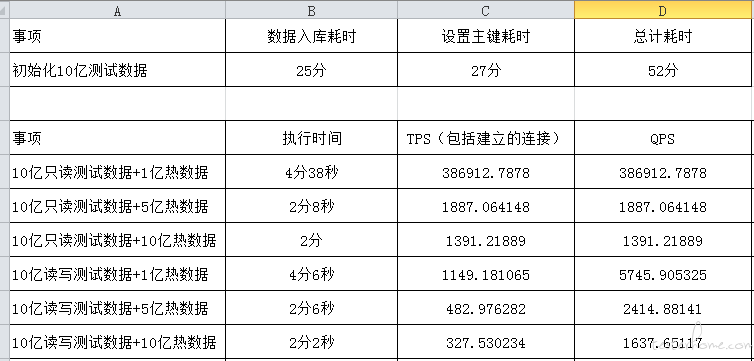
1、根据目标库大小初始化测试数据,具体命令如下:
初始化数据 10 亿:pgbench -i -s 10000 (自动创建一 pgbench 数据库,并自动创建相应的表,以及表数据)
2、用 postgres 账户创建只读脚本
\set aid random_gaussian(1, :range, 10.0)
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
3、用 postgres 账户创建读写脚本
\set aid random_gaussian(1, :range, 10.0)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
END;
1、执行只读脚本
pg.x8.xlarge.2(服务器型号),总数据量 10 亿,热数据 1 亿
pgbench -M prepared -v -r -P 1 -f ./ro.sql -c 32 -j 32 -T 120 -D scale=10000 -D range=100000000
pg.x8.xlarge.2,总数据量 10 亿,热数据 5 亿
pgbench -M prepared -n -r -P 1 -f ./ro.sql -c 32 -j 32 -T 120 -D scale=10000 -D range=500000000
pg.x8.xlarge.2,总数据量 10 亿,热数据 10 亿
pgbench -M prepared -n -r -P 1 -f ./ro.sql -c 32 -j 32 -T 120 -D scale=10000 -D range=1000000000
2、执行读写脚本
pg.x8.xlarge.2,总数据量 10 亿,热数据 1 亿
pgbench -M prepared -v -r -P 1 -f ./rw.sql -c 32 -j 32 -T 120 -D scale=10000 -D range=100000000
pg.x8.xlarge.2,总数据量 10 亿,热数据 5 亿
pgbench -M prepared -n -r -P 1 -f ./rw.sql -c 32 -j 32 -T 120 -D scale=10000 -D range=500000000
pg.x8.xlarge.2,总数据量 10 亿,热数据 10 亿
pgbench -M prepared -n -r -P 1 -f ./rw.sql -c 32 -j 32 -T 120 -D scale=10000 -D range=1000000000
3、根据执行得出的 tps,可算 qps
qps = tps * sql 语句个数
1、在集群为 9999 的节点上创建一 pg_bench 的测试库
pgbench –p 9999 –U postgres –I pg_bench
2、为 pg_bench 创建表结构
psql –p 9999 –U postgres –d pg_bench
由于使用的是默认参数创造的测试表,各表数据量如下:(history 表是记录表,创建时为空)

在创建测试表的时候可以设置测试数据的量如:
pgbench –p 9999 –U postgres –i –F 100 –s 500 pg_bench

pg_bench 工具自带一个读写测试脚本 ,此脚本分别执行了 insert,update,select,可有效测试数据库吞吐能力,和并发效率
3、压力测试
集群上 1 个 session
pgbench –p 9999 –U pg_bench –c 1 –T 20 –r pg_bench
集群上 30 个 session
pgbench –p 9999 –U pg_bench –c 30 –T 20 –r pg_bench
然后在单节点上,5432 上执行:
pgbench –p 5432 –U pg_bench –c 30 –T 20 –r pg_bench
4、自编脚本
自编后,使用命令进行压力测试:
pgbench –p 9999 –U pg_bench –c 1 –T 20 –f /var/lib/postgresql/pgbench_script/readonly.sql
优势:
1.系统自带,与 postgresql 兼容性好,且配置方便
2.工具小,执行速度快
劣势:
1.测量结果浮动较大,就多次实验来看,测量结果从 40tps 到 400tps 都出现过,统计后发现绝大多数执行结果落在 350~400 区间。故使用时须多次执行,取合适的值。
2.无法中断。执行过程中无法中断测试操作,就算 kill 了 pg_bench 进程,他的脚本也已经进入 postgresql,postgresql 依然会继续跑测试。只能等着他跑完。
