
Crash 率是衡量一款 APP 质量好坏的重要指标之一,不仅会影响用户体验,也可能影响用户存量。一旦出现问题,可能会给企业带来严重损失。
本文由美团技术专家谌天洲分享美团 APP Crash 率从千分之一到万分之一治理过程中所做的大量实践工作。
美团作为一个平台化的 APP,背后有 20+ 团队设计和 30+ 业务。
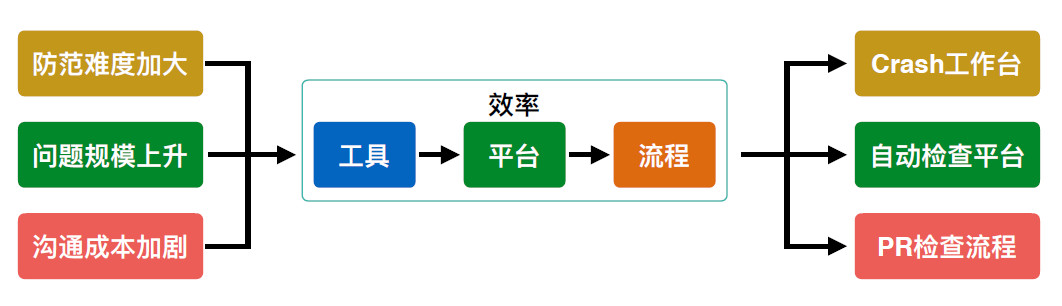
在 Crash 治理过程中面对的挑战有三项:体量大、迭代快和日活高。这三项挑战带来的直接影响是沟通成本上升和防范难度加大。因此在实际治理过程,主要围绕基础能力、治理效率两个层面进行探索和优化建设。
Crash 治理的基础能力主要体现在三个层面:能发现、能定位和能修复。
在发现能力层面,美团有一套异常监控退出系统,可发现除 Java&JNI Crash&ANR 以外其他类型的异常退出。在定位能力层面,有可提供内存泄漏路径及 OOM 时的内存快照的内存监控体系,有可提供线程现场及任务现场的线程管控体系。除此以外,还有动态日志系统提供额外的方法调用链及参数信息。
内存问题最典型的呈现形式是 OOM,其中 80% 通过 Leak 监控系统发现预防,另外 20% 的内存问题,对于大体量 APP 需要从全局对内存资源问题进行监控和调查分析。
美团的内存监控体系分为线下和线上两个场景。线下通过 Leak 监控系统能预防发现 80% 的 OOM 问题,线上建立随时获取 OOM 内存现场的监控能力。

美团 APP 经常会遇到用户个性化的使用场景无法复现和定位的问题。对此,美团提出了一套动态日志系统——
在编译期对应用代码通过插桩实现代理,运行期同步记录,出现异常时可主动触发上报,也可以由服务端主动回捞。基于插桩实现的代理逻辑,可实施获取原方法执行时的方法名、入参和返回值信息,再将这些信息序列化后存储到数据库,由此可在必要的时候获取到较完善的方法调用栈历史,进而定位问题。


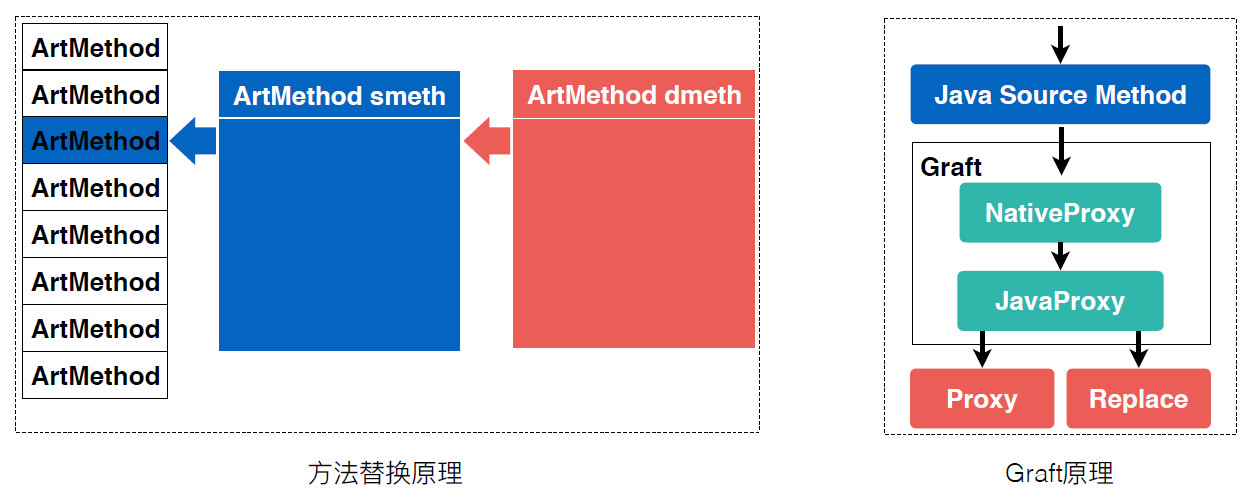
在修复能力层面,美团 APP 一度深受机型多、系统杂带来的 framework 层的问题困扰。此外,美团 APP 也经常会遇到常规日志体系无法覆盖的接口问题。
针对这两类问题,参考热修复的方法替换原理,开发并完善了一套小工具——“Graft”。它的基本原理是在 native 层通过方法替换实现对 Java 层方法的 hook 和代理,进而在 Java 层实现方法代理和方法替换。
这套工具可以动态代理或替换几乎所有 Java 层的方法(包括 framework 层),使得美团 APP 的修复能力从自有代码和第三方代码有效覆盖到 framework 层。

为了提高治理效率,实际治理过程逐渐形成 PR 检查流程、自动检查平台和 Crash 平台三大流程和平台。
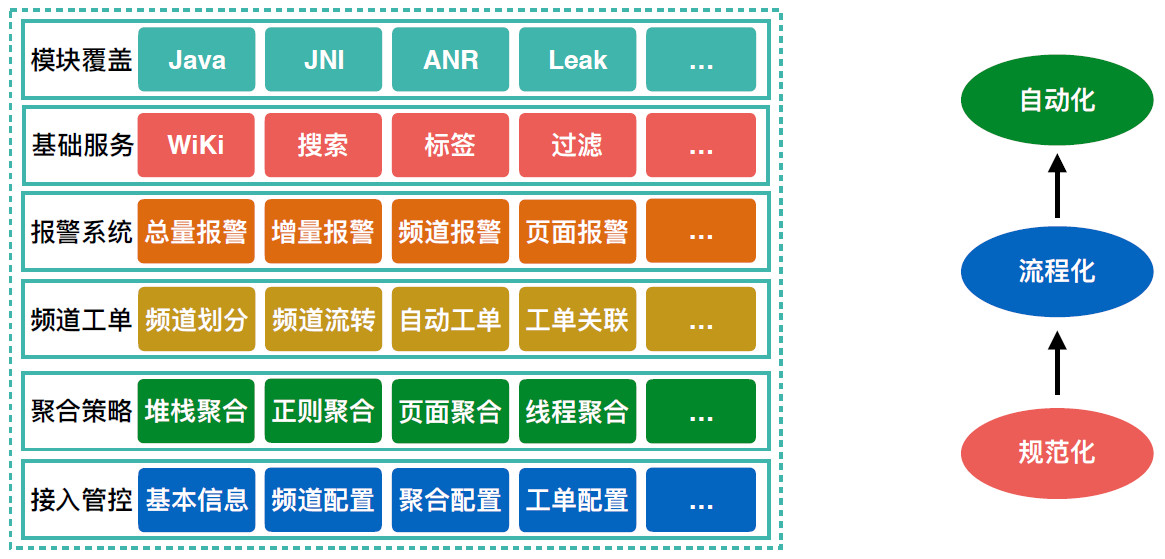
PR 检查流程主要针对 PR 阶段进行代码规范性检查、代码准入检查和稳定性案例检查;自动检查平台针对以往案例进行定制化防范检查。Crash 平台是整个稳定性治理的核心,在建设的考量中主要遵循规范化、流程化、自动化,它主要涵盖接入管控、聚合策略、频道工单、报警系统、基础工具、模块覆盖,可以通过强大的复用能力快速接入并管理几乎所有稳定性相关的问题。
Crash 平台是整个稳定性治理的核心,在建设的考量中主要遵循规范化、流程化、自动化,它主要涵盖接入管控、聚合策略、频道工单、报警系统、基础工具、模块覆盖,可以通过强大的复用能力快速接入并管理几乎所有稳定性相关的问题。
在 PR 阶段,PR 检查流程可自动识别出增量代码是否被现有体系覆盖,并通过 Crash 平台的接入管控系统督促增量代码的责任人完善基本信息、频道信息、聚合配合及自动工单配置等等。
在开发或全量过程中一旦发现异常,Crash 平台会自动完成堆栈聚合、频道识别、报警评估及工单跟踪等工作。
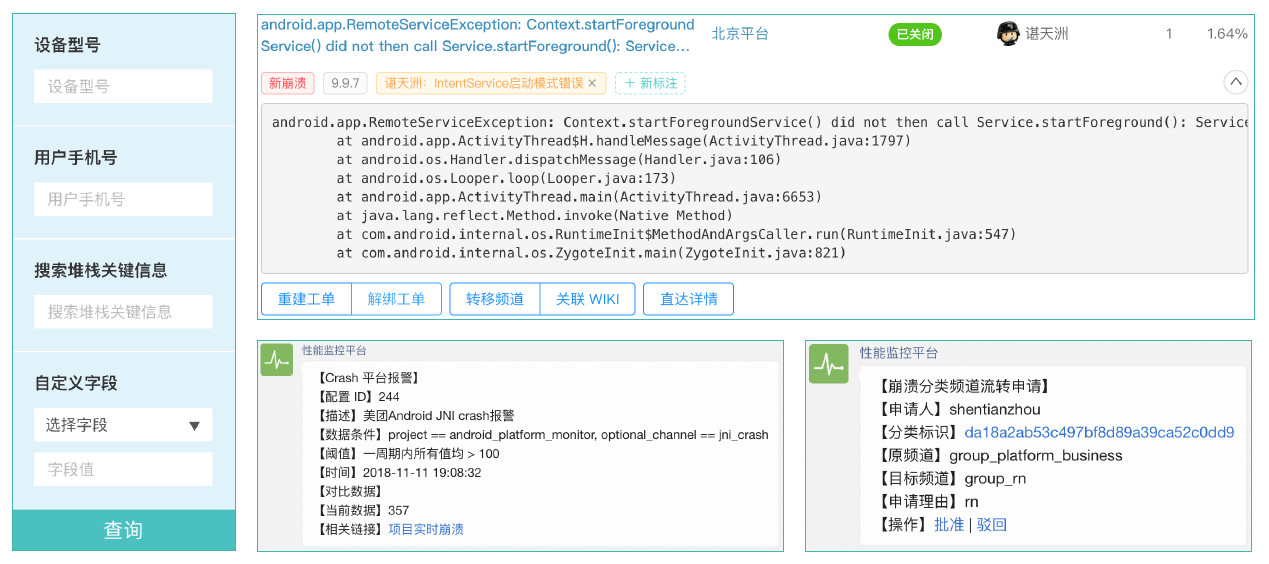
Crash 率是 APP 最重要的指标之一,谌天洲建议开发者建立解决 Crash 的长效机制,找到最合理的解决方案。随着版本的不断迭代,Crash 治理之路才能离目标越来越近。
对于美团 Crash 治理的实践分享,开发者觉得有哪些值得借鉴和可以改进的地方呢?欢迎留言说出您的看法~
