算法领域也是测试同学在逐步介入和深入的领域,但这个领域的测试具有极为明显的特殊性——输出具有不确定性,算法设计技术思路和一般的工程类项目不同,允许有 badcase 存在,结果短期内不一定可见等。因为广告、信息流等业务跟算法结合紧密,团队内也在探索算法测试的方案,方法。本文给出了实际工程中最为常用的算法——推荐算法、最优化算法、预估算法、分类算法以及它们的应用场景,想入门算法领域的同学可以作为一个入门参考 list,有一定的算法基础的人可以略过。后续会基于调研和实际工作中遇到的场景,分享我们对启动算法测试的一些思考,欢迎大家持续关注
要对算法进行测试,首先应该了解目前工程中常用的算法有哪些种类,及相应算法的应用主要应用场景有哪些。工程中的需求可能是某种算法单独完成的,也可能是几种算法合作完成,而且某种算法可能可以胜任多种不同场景。
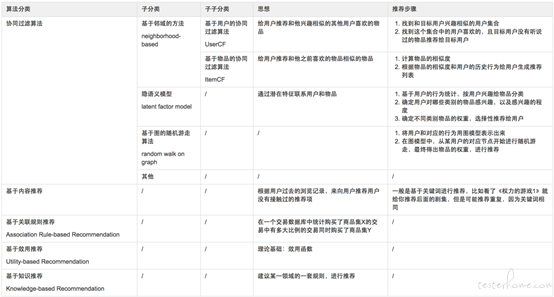
核心思想是根据现有数据集合扩展出相似数据集合或者其他有关联的数据集合。在工业应用中要求可以根据用户兴趣和行为特点,向用户推荐所需的信息或商品,帮助用户在海量信息中快速发现真正所需的信息或商品,提高用户黏性,促进信息点击和商品销售。最为大家常见的就是购物网站或者新闻类网站的猜你喜欢模块,搜索广告行业的词包推荐模块等。现有推荐算法基于的维度主要有人口统计学,内容,关联规则,协同过滤,常常基于的数据包括用户,商品,内容,事件。LBS(Location Based Services)。下图是各类推荐算法的思想和实现步骤。
最优化算法顾名思义就是找到特定场景下的最优解,包含有约束最优化和无约束最优化算法,实际工程中一般都是有约束的最优化问题。优化算法的应用场景也很多,比如广告行业广告主如何设置预算、出价可以使得 ROI 最大,地图如何提供指定起始点的最短路径或者用时最短路径问题、图像识别领域的模式识别等。最优化算法的种类一般分为线性规划、非线性规划和现代最优化算法(如模拟退火算法、遗传算法、人工神经网络等)等。需要了解的基础算法有梯度下降法、牛顿法和拟牛顿法、共轭梯度法等。
核心思想是根据现有依据,预测事件在未来时间点发生的概率。应用也很广泛,比如广告行业最核心的 CTR 预估,大型网站的访问量预估,舆情预估,人口增长分析、股价走势预测等等。最常用的预估算法有 LR(Logistic Regression)模式,FM(Factotization Machines)模型,DNN( Deep Neural Network)模型等。
核心思想是将工程中的不同个体按照一定标准分成不同类别,这个类别可能是分类之前划分好的,也可能是通过算法学习后给出的类别。主要场景有,比如广告客户的行业划分,广告受众人群的划分,广告点击数据的反作弊,现阶段各金融平台的信用评估、图像识别、语音识别。主要的分类算法种类有决策树、人工神经网络、遗传算法、朴素贝叶斯、KNN、SVM 等算法。
实际工程中还存在其他算法,待学习。
图 2 是常见推荐算法的整个模型框架,其他算法在业务应用中的框架大体类似,一般都是通过算法处理数据,为业务服务的模式。
推荐系统的主要目的是能吸引更多的用户看内容的详情页、促使单个用户浏览更多内容,所以一般在推荐系统中,主要有三种评测推荐效果的实验方法:
如何判断一个推荐系统好不好,主要的测量指标如下:
最优化算法的校验比较困难,因为确定最优解一直是优化算法界要解决的问题。工程中一些求解结果只能说是相对最优解。
最优解算法的校验方法除了上线后的 AB 测试还未找到合适的校验方法。
预估算法在软件工程界最典型的应用就是 CTR 预估,分为离线评测指标和在线评测指标。通用的 ctr 预估框架如图 3。离线评测指标主要从三个指标着手:AUC, LogLoss,pCTR bias。在线评估一般使用 AB Test 来验证点击率预估模型的有效性。
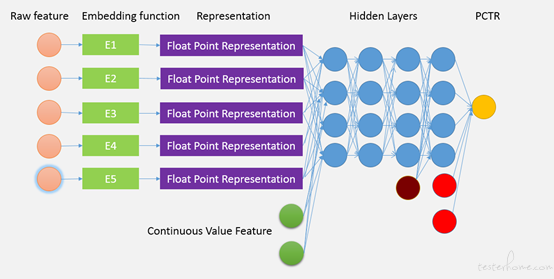
在线评估是必须的,不应该离线评估后直接全部流量使用新模型,原因是模型是在老的模型产生的数据上学习的,验证的,而直接全部新模型上线所产生的数据与之前是不同的,可能在新的数据下效果很差。当然这样解释让 AB Test 也失去了合理性,模型是应该在新的数据上学习,验证的,现在是在新老混杂的数据上学习,新老混杂的数据上验证,似乎也不合理(因为如果只用新数据训练,往往训练样本不够),认为这样是合理的是因为我们认为模型的效果好来源于它对数据的学习能力,而不在于它对特定数据的学习能力。
分类算法的校验目标比较明确,一般是人工标注校验集合,主要从正确率、错误率、灵敏度等角度出发验证分类的效果。
正确率(accuracy)
正确率是我们最常见的评价指标, accuracy =(TP+TN)/(P+N),即被分对的样本数除以所有的样本数,正确率越高,分类器越好;
错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以 accuracy =1 - error rate;
灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力;
特效度(specificity)
specificity = TN/N, 表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力;
精度(precision)
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例, precision=TP/(TP+FP);
召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例, recall=TP/(TP+FN)=TP/P= sensitive,可以看到召回率与灵敏度是一样的。
上述常见的模型评价术语备注如下:
假设分类目标只有两类,计为正例(positive)和负例(negtive)。
开启算法测试的前提是测试人员具备一定的算法基础,对算法设计和算法在工程中的应用有一定的了解。如上篇文章提到的常用算法和其应用场景,算法设计一般来源于统计学和概率论,需要有一定的数学建模和推理基础,同时算法仿真离不开大数据处理,所以最好还要具备一定的大数据处理分析能力。
算法相关的业务和工程产出是经验丰富的算法工程师在进行大量模拟,仿真和实验和自测后得出的结果,大部分测试工程师短期内可能不能达到这一高度;而且每种算法实现思路和应用场景也不一致,不能应用统一的测试方法。实际项目中,算法和策略工程师会对上线的算法工程进行上线前自测和上线后观察,部分开发者会对测试介入有一定的排斥心理。
同时最重要的,算法测试和传统测试方法有着本质的不同,传统测试方法是设计输入数据校验输出是否和期望一致。算法测试的输入和输出都有不确定性。
所以算法测试的全面启动有一定难度。但是算法测试仍有可以切入的点。
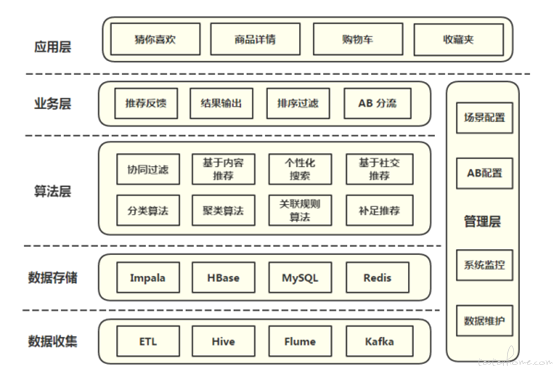
我认为对接业务和算法相关时,比较好的切入方式是先从算法为其他业务模块提供的数据输出入手,结合应用其数据的业务校验输出是否合理,循序渐进,逐渐深入。

即先从上图中的 1,2 模块入手,最后再深入算法处理模块。
举例说明,我们所测的业务曾经有一个场景:广告主在投放广告时,有部分广告主希望自己的预算花费较为均匀,以覆盖不同时段的用户。为了使广告主的消费在一天内分布的比较均匀,算法 server 需要根据广告主当天消费情况、预算、历史消耗分布,为广告主计算最佳的消耗速率值,并提供给引擎,引擎检索时实时根据该值确定是否展示某个物料。为了测试该场景,我们从以下几个步骤出发:
忠告,哈哈,不一定用得到:因为算法设计师算法工程师大量实验和优化后的产出,他们一般都对自己的设计有比较高的自信,初期往往对算法类缺陷接纳度不高。所以开始先不要对算法开发同学设计的算法提出过多质疑,尽量从测试的业务优势上出发,先从业务角度给出建议,因为测试同学是对整个系统和流程最为了解的角色,相较算法同学有优势,然后逐渐深入。测试在同算法同学不断讨论沟通过程中,也会对算法的测试也会不断深入,学习到很多实际工程中算法工程师对算法自测时的方法和思想。
因为算法的产出具有不确定性,导致算法的效果测试不能够用传统测试方法进行验证。实际工程中,对算法合理性的评判维度主要有:
综上,算法测试可以遵从以下框架进行,见下图:
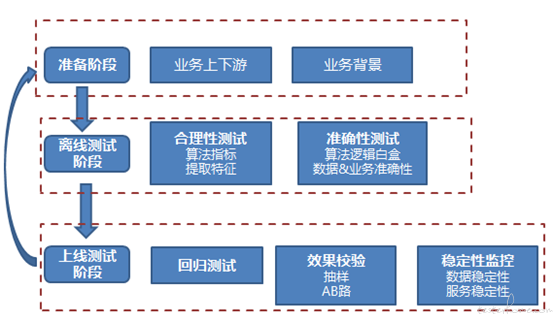
算法测试现在也在追求平台化,流程化,并能够对外提供服务。在这条道路上我们还有很长路要走。
