
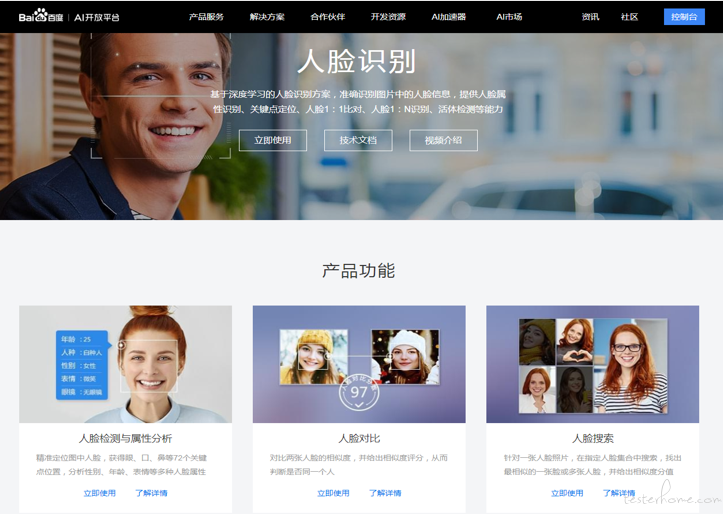
来自百度 AI 平台
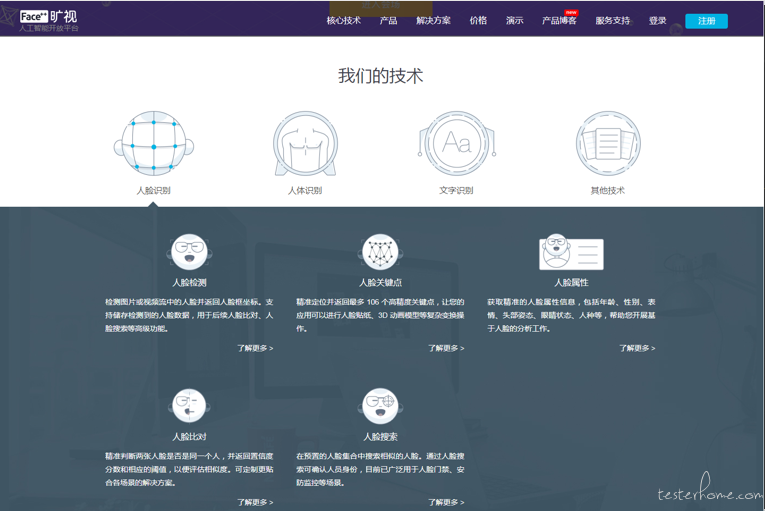
来自 face++
通过上面两张图相信对人脸识别相信有一定理解,想要具体了解概念的,可以百度,谷歌。
而性别识别是人脸属性中其中一种。


算法的输入和输出是什么的内容,格式。
测试人员需要给出的评价指标。
训练数据中男性照片和女性照片数据分别有多少,比例。
照片数据是怎样的(是否有老人,小孩等)。
算法是如何实现的。(整个模型预测流程;数据是如何处理;用的是什么算法)
思考方向:
算法工程师使用男女训练数据比例是否合理?
照片数据中覆盖是否全面?
类比一个输入框的测试,需要测试汉字、字符、表情、数字、字母,组合等多种情况下的。这里也是类似。
主要考虑:
1,需要什么样的测试数据
2,测试数据要多少
思考什么情况下可能会影响到算法识别性别,准备这样的测试数据。
这里给出一些参考:
男性照片和女性照片测试数据比例和训练数据中比例保持一致。
照片数据中包括不同年龄段男女
正常脸部拍摄的照片
包括不同光线照明场景,尤其是弱光,光线不足,暗场景下的照片。
包括不同姿势(偏头、仰头、侧面)场景照片。
被物体(如眼镜、面膜、口罩、手等)遮挡场景照片。
测试数据总数多少参考之前写文章。
本次项目测试主要考虑用户群体,用户场景下拍摄的照片。不使用网络照片。不使用国外人脸数据集。不考虑国外人群,像黑种人性别识别。
进入性别识别前有人脸识别模型判断有没有人脸,多人脸判断等,所以不用考虑非人脸是否会识别出性别的问题。
场景下不会有脸部区域很小的照片。此不考虑。
笔者这里使用 1100 张女性照片,900 张男性照片做为测试数据。
如果是图片是本地.jpg 格式的,在一个文件夹中新建 2 个子文件夹,一个命名 man 存放所有男性照片,一个命名为 woman 存在所有女性照片。
如果图片是 url,所有 url 保存在一个 txt 文档中,分为两列,第一列为 url, 第二列为对应标注 1, 2
测试脚本主要功能:批量运行所有测试数据,记录模型预测值,和标注值进行,计算得出评价指标。保存判断出错的照片。并记录每张照片所预测耗时,计算出平均值、中位值、最大值 、最小值等 数据。
使用 python 编写实现,评价指标使用 sklearn 包,平均值使用 numpy。
查看评价指标。
查看判断出错的照片,是不是标注出错。有没有什么共同特征等。
上面只是描述评价模型的方法。一个项目的测试并不只是有这个,还包括其他如

使用大量照片(不需要标注男女)运行,只关注是否会有运行失败、报错的情况,不关注预测出来的结果是否正确。
大量数据情况下,主要考察是否有些数据会运行报错。
方式为调用百度和 face++ 开放 api,调用试一试
