 是不是很丑陋?
是不是很丑陋?这篇写好一段时间了,一直也没发布上来,今天稍微整理下了交下作业,部分科普内容偷懒摘用了其他文章的内容。
使用 Jenkins 做持续集成/持续交付,当业务达到一定规模的时候,Jenkins 本身就很容易成为整条流水线的瓶颈,各个业务端都依靠 Jenkins,部署 Jenkins 服务时如何保障服务的高可用变得尤为重要。
以微医为例,目前 Jenkins 的业务承载量:>1,000 Build Jobs>5,000 Buils/Day,光依靠单 master 已经无法承载高并发的性能压力,瓶颈来自多方面,不仅仅是 Jenkins 应用本身占用 memory 和 CPU 资源,也包括各个 job 编译、测试、部署等的资源开销,随着 job 数量的增加,大量的 workspace 也会耗尽服务器的存储空间,严重影响整个技术团队的工作效率和部署节奏。
Jenkins 分布式架构是由一个 Master 和多个 Slave Node 组成的 分布式架构。在 Jenkins Master 上管理你的项目,可以把你的一些构建任务分担到不同的 Slave Node 上运行,Master 的性能就提高了。
Master/Slave 相当于 Server 和 agent 的概念。Master 提供 web 接口让用户来管理 job 和 slave,job 可以运行在 master 本机或者被分配到 slave 上运行构建。
一个 master(jenkins 服务所在机器)可以关联多个 slave 用来为不同的 job 或相同的 job 的不同配置来服务。
传统的 Jenkins Slave 一主多从式会存在一些痛点。比如:
是不是很丑陋?由于以上种种痛点,我们渴望一种更高效更可靠的方式来完成这个 CI/CD 流程,而虚拟化容器技术能很好的解决这个痛点,下图是基于 Kubernetes 搭建 Jenkins 集群的简单示意图。
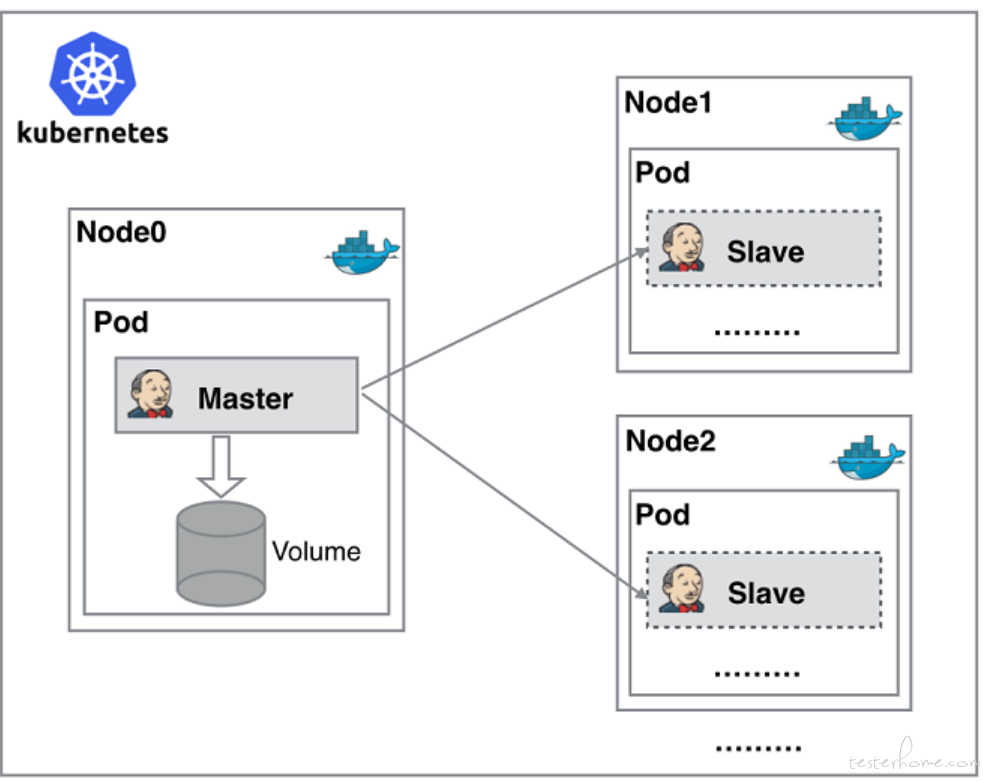
Jenkins Master 和 Jenkins Slave 以 Docker Container 形式运行在 Kubernetes 集群的 Node 上,Master 运行在其中一个节点,并且将其配置数据存储到一个 Volume 上去,Slave 运行在各个节点上,并且它不是一直处于运行状态,它会按照需求动态的创建并自动删除。
这种方式的工作流程大致为:当 Jenkins Master 接受到 Build 请求时,会根据配置的 Label 动态创建一个运行在 Docker Container 中的 Jenkins Slave 并注册到 Master 上,当运行完 Job 后,这个 Slave 会被注销并且 Docker Container 也会自动删除,恢复到最初状态。
这种方式带来的好处有很多:
在保证 Jenkins Master 高可用的前提下,可以按传统方式 war 包方式部署,可以使用 docker 方式部署,也可以在 Kubernetes Node 中部署,这部相对简单,不再展开详述。
管理员账户登录 Jenkins Master 页面,点击 “系统管理” —> “管理插件” —> “可选插件” —> “Kubernetes plugin” 勾选安装即可。
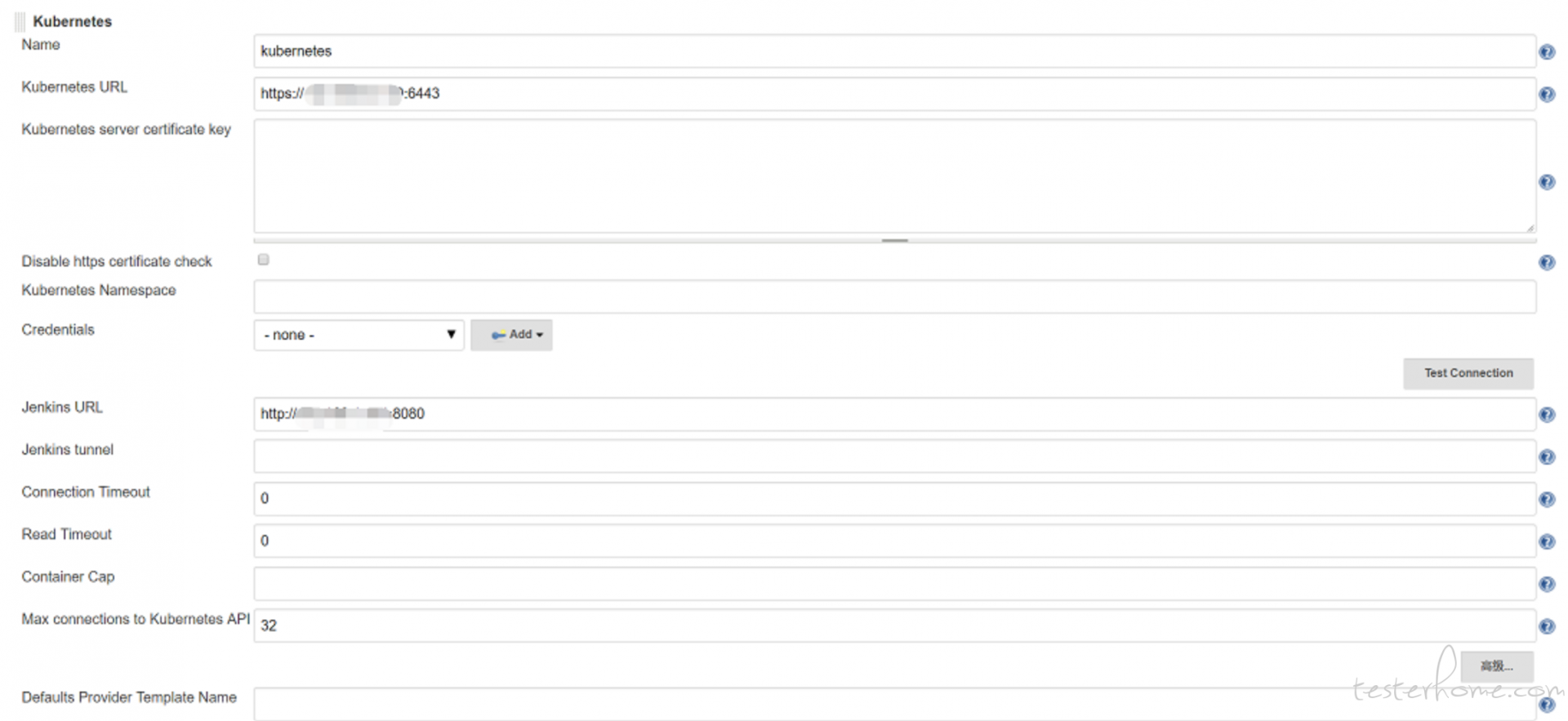
安装完毕后,点击 “系统管理” —> “系统设置” —> “新增一个云” —> 选择 “Kubernetes”,然后填写 Kubernetes 和 Jenkins 配置信息。
接下来,我们可以配置 Job 测试一下是否会根据配置的 Label 动态创建一个运行在 Docker Container 中的 Jenkins Slave 并注册到 Master 上,并且在运行完 Job 后,Slave 会被注销并且自动删除 Docker Container。
创建一个 Pipeline 类型 Job 并命名为"pipeline_kubernetes_demo1,然后在 Pipeline 脚本处填写一个简单的测试脚本如下:
pipeline {
agent {
kubernetes {
//cloud 'kubernetes'
label 'k8s-jenkins-jnlp'
containerTemplate {
name 'jnlp'
image 'harbor.guahao-inc.com/base/jenkins/jnlp-slave:latest'
}
}
}
stages {
stage('Run shell') {
steps {
script {
git 'https://github.com/nbbull/demoProject.git'
sh 'sleep 5'
}
}
}
}
}
执行构建,此时去构建队列里面,可以看到有一个构建任务,第一次构建的时候会稍慢,因为 k8s 的 node 需要去下载 jnlp-slave 的镜像。
稍等一会就会看到 k8s-jenkins-jnlp-8gqtp-j9948 的容器正在创建,然后开始运行,Job 执行完毕后,jenkins-slave 会自动注销并删除容器,我们通过 kubectl 命令行,可以看到整个自动创建和删除过程,整个过程自动完成。
[root@kubernetes-master1 ~]# kubectl get pods|grep jenkins
k8s-jenkins-jnlp-8gqtp-j9948 0/1 ContainerCreating 0 4s
[root@kubernetes-master1 ~]# kubectl get pods|grep jenkins
k8s-jenkins-jnlp-8gqtp-j9948 1/1 Running 0 18s
具体的构建日志参考如下:
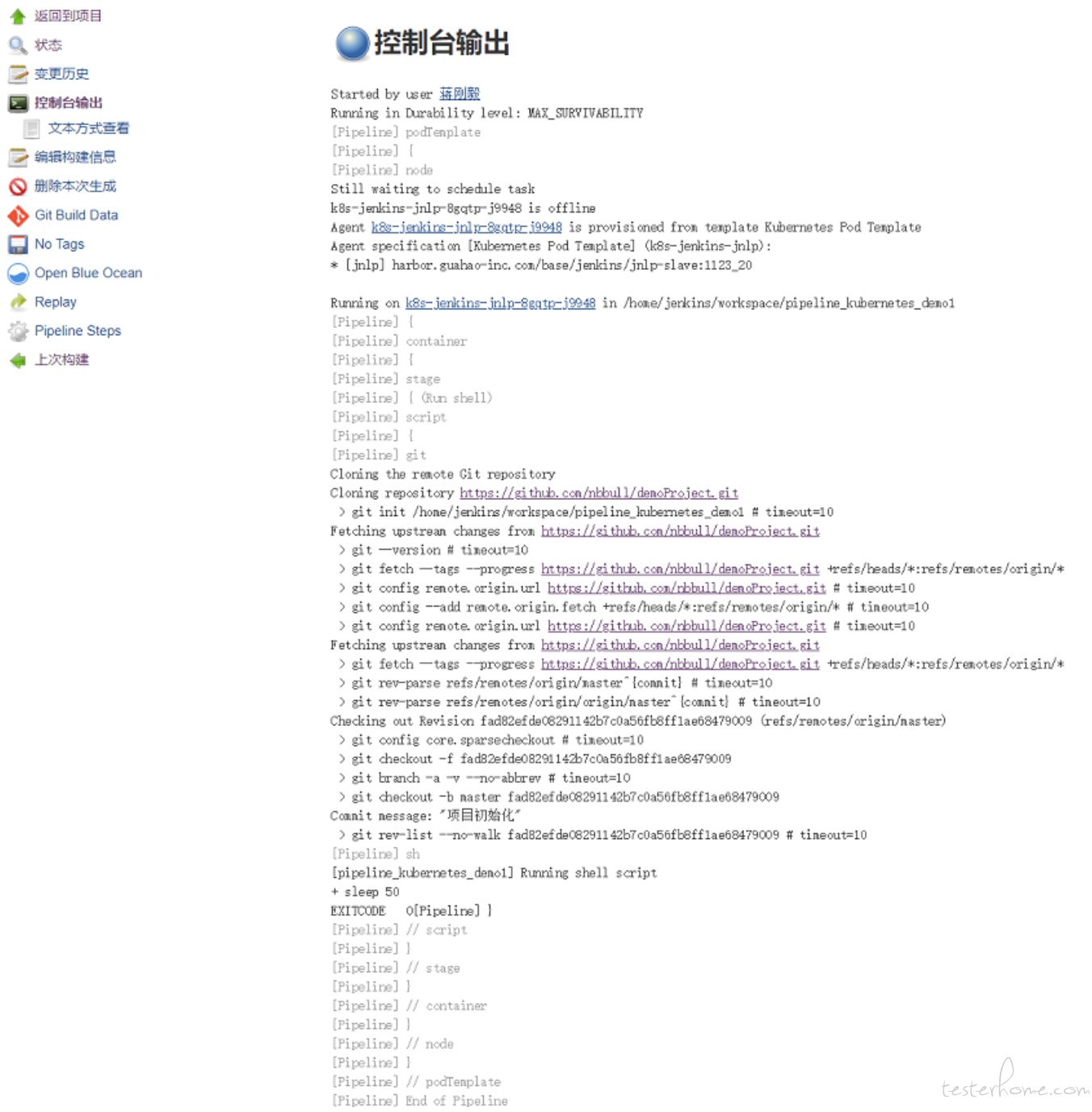
通过 kubernetest plugin 默认提供的镜像 jenkinsci/jnlp-slave 可以完成一些基本的操作,它是基于 openjdk:8-jdk 镜像来扩展的,但是对于我们来说这个镜像功能过于简单,比如我们想执行 Maven 编译或者其他命令时,就有问题了,那么可以通过制作自己的镜像来预安装一些软件,既能实现 jenkins-slave 功能,又可以完成自己个性化需求,dockfile 如下:
FROM harbor.guahao-inc.com/base/jenkins/jnlp-slave:latest
USER root
//下载安装必要组件
RUN apt-get update && apt-get install -y sudo && rm -rf /var/lib/apt/lists/*
RUN apt-get update && apt-get install -y vim && apt-get install -y sshpass
//下载和配置maven
COPY apache-maven-3.2.6-GH /usr/greenline/install/apache-maven-3.2.6-GH
RUN ln -s /usr/greenline/install/apache-maven-3.2.6-GH /usr/greenline/maven3
//下载和配置jdk
COPY jdk1.8.0_91 /usr/greenline/install/jdk1.8.0_91
RUN ln -s /usr/greenline/install/jdk1.8.0_91 /usr/greenline/jdk_1.8
ENV JAVA_HOME=/usr/greenline/jdk_1.8
ENV CLASSPATH=.:/usr/greenline/jdk_1.8/lib/dt.jar:/usr/greenline/jdk_1.8/lib/tools.jar:/usr/greenline/jdk_1.8/lib/rt.jar
ENV PATH=/usr/greenline/jdk_1.8/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/usr/greenline/maven3/bin
USER jenkins
ENTRYPOINT ["jenkins-slave"]
除了在 Pipeline 中定义 slave 的 image,我们也可以使用非 Pipeline 类型指定运行该自定义 slave,那么我们就需要修改 “系统管理” —> “系统设置” —> “云” —> “Kubernetes” —> “Add Pod Template” 修改配置 “Kubernetes Pod Template” 信息如下:
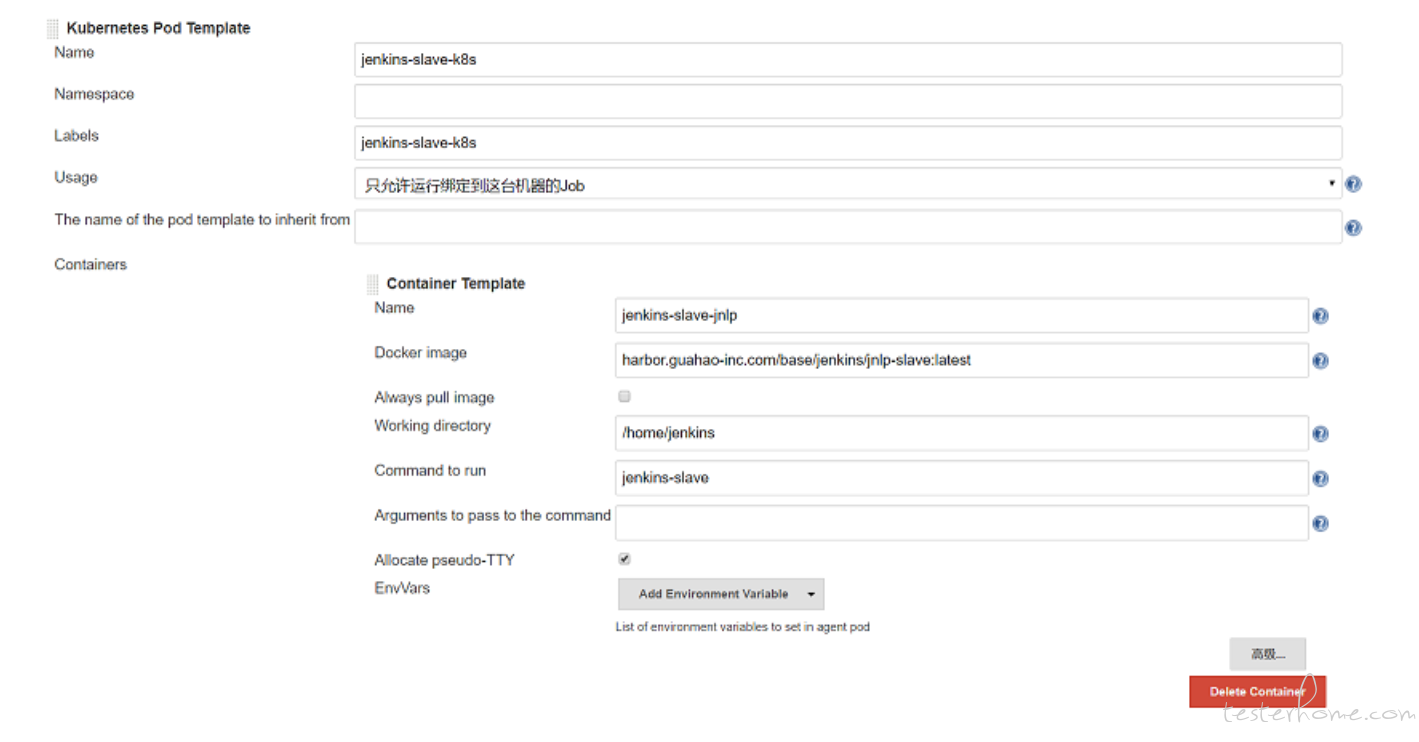
默认情况下,Jenkins 保守地生成代理。比如,如果队列中有 2 个构建,它将不会立即生成 2 个执行程序。它会产生一个执行器并等待一段时间让第一个执行器被释放,然后再决定产生第二个执行器。Jenkins 确保它产生的每个执行者都得到最大限度的利用。如果要覆盖此行为并立即为队列中的每个构建生成执行程序,可以在 Jenkins 启动时参加一下参数:
-Dhudson.slaves.NodeProvisioner.initialDelay=0
-Dhudson.slaves.NodeProvisioner.MARGIN=50
-Dhudson.slaves.NodeProvisioner.MARGIN0=0.85
Jenkins 的日常工作包括大量的编译构建,构建过程中会涉及到大量依赖包的下载(比如 jar 包,npm 包等),采用原生容器的方式由于没有持久化本地仓库,每次构建都需要对这些依赖包重新下载,严重影响效率。
这里需要解决公共依赖包持久化存储的问题,一种做法是配置宿主机目录挂载的方式,把文件挂载到宿主机,这样虽然方便但是不够安全,而且 Kubernetes 集群一般有多个 Node 节点,如果容器在挂了被重新拉起的时候被调度到其他的 Node 节点,那映射在原先主机上的数据还是在原先主机上,新的容器还是没有原来的数据。
所以推荐的方法一般都是把数据存储在远程服务器上如:NFS,GlusterFS,ceph 等,目前主流的还是使用 GlusterFS。事实上,Kubernetes 的选择很多,目前 Kubernetes 支持的存储有下面这些:
GCEPersistentDisk
AWSElasticBlockStore
AzureFile
AzureDisk
FC (Fibre Channel)
FlexVolume
Flocker
NFS
iSCSI
RBD (Ceph Block Device)
CephFS
Cinder (OpenStack block storage)
Glusterfs
VsphereVolume
Quobyte Volumes
HostPath (就是刚才说的映射到主机的方式,多个Node节点会有问题)
VMware Photon
Portworx Volumes
ScaleIO Volumes
StorageOS
Kubernetes 有这么多选择,GlusterFS 只是其中之一,但为什么可以脱颖而出呢?GlusterFS,是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数 PB 存储容量和处理数千客户端。GlusterFS 借助 TCP/IP 或 InfiniBand RDMA 网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS 的 Volume 有多种模式,复制模式可以保证数据的高可靠性,条带模式可以提高数据的存取速度,分布模式可以提供横向扩容支持,几种模式可以组合使用实现优势互补。
安装环境: 192.168.XX.A , 192.168.XX.B
GlusterFS 集群的部署比较简单,在各台机器分别安装
# yum install centos-release-gluster
# yum install glusterfs-server
# /etc/init.d/glusterd start
在一台上面建立信任关系
# gluster peer probe 192.168.XX.B #后面跟另外一台的IP
# gluster peer status
创建名称为 “jenkins_public” 的分布式卷:
# gluster volume create jenkins_public 192.168.XX.A:/data/exp1 1192.168.XX.B:/data/exp2 force
# gluster volume info 查看逻辑卷信息
# gluster volume start jenkins_public #启动逻辑卷
Kubernetes 用 PV(PersistentVolume)、PVC(PersistentVolumeClaim)来使用 GlusterFS 的存储。PV 与 GlusterFS 的 Volume 相连,相当于提供存储设备;PVC 消耗 PV 提供的存储,由应用部署人员创建,应用直接使用 PVC 进而使用 PV 的存储。
官方文档对配置过程进行了介绍:https://github.com/kubernetes/examples/blob/master/staging/volumes/glusterfs/README.md
data1-volume-pv-cluster.json:
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "data1-volume-pv-cluster"
},
"subsets": [
{
"addresses": [{ "ip": "192.168.XX.A" }],
"ports": [{ "port": 20 }]
},
{
"addresses": [{ "ip": "192.168.XX.B" }],
"ports": [{ "port": 20 }]
}
]
}
备:该 subsets 字段应填充 GlusterFS 集群中节点的地址。可以在 port 字段中提供任何有效值(从 1 到 65535)。
##创建端点:
[root@k8s-master-01 ~]# kubectl create -f data1-volume-pv-cluster.json
##验证是否已成功创建端点
[root@k8s-master-01 ~]# kubectl get ep |grep data1-volume-pv-cluster
glusterfs-cluster 192.168.XX.A:20,192.168.XX.B:20
我们还需要为这些端点 (endpoint) 创建服务 (service),以便它们能够持久存在。我们将在没有选择器的情况下添加此服务,以告知 Kubernetes 我们想要手动添加其端点
data1-volume-sv-cluster.json:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "data1-volume-pv-cluster",
"namespace": "default",
}
},
"spec": {
"ports": [
{
"protocol": "TCP",
"port": 20,
"targetPort": 20
}
]
}
}
创建服务
[root@k8s-master-01 ]# kubectl create -f data1-volume-sv-cluster.json
##查看service
[root@k8s-master-01 ]# kubectl get service | grep data1-volume-sv-cluster
创建 jenkins-public-pv.yaml 文件,指定 storage 容量和读写属性
jenkins-public-pv.yaml:
kind: PersistentVolume
apiVersion: v1
metadata:
labels:
name: jenkins-public-pv
namespace: default
name: jenkins-public-pv
spec:
capacity:
storage: 600Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
glusterfs:
endpoints: data1-volume-pv-cluster
path: jenkins_public
readOnly: false
然后执行:
[root@k8s-master-01 ~]# kubectl create -f jenkins-public-pv.yaml
## 查看pv
[root@k8s-master-01 ~]# kubectl get pv|grep jenkins-public-pv
创建 jenkins-public-pvc.yaml 文件,指定请求资源大小
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: jenkins-public-pvc
namespace: default
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 600Gi
selector:
matchLabels:
name: jenkins-public-pv
然后执行:
[root@k8s-master-01 ~]# kubectl create -f jenkins-public-pvc.yaml
## 查看pvc
[root@k8s-master-01 ~]# kubectl get pvc|grep jenkins-public-pvc
修改 pipeline,把 pvc 挂载到容器内的/home/maven_repository,下面是完整的 Pipeline:
pipeline {
agent {
kubernetes {
cloud 'kubernetes'
label 'k8s-jenkins-jnlp'
defaultContainer 'jnlp'
yaml """
apiVersion: v1
kind: Pod
metadata:
labels:
node-label: "k8s-jenkins-jnlp-${UUID.randomUUID().toString()}"
spec:
containers:
- name: jnlp
image: harbor.guahao-inc.com/base/jenkins/jnlp-slave:1123_20
volumeMounts:
- mountPath: /home/maven_repository
name: docker-socker-file
volumes:
- name: docker-socker-file
persistentVolumeClaim:
claimName: jenkins-public-pvc
"""
}
}
stages {
stage('Run shell') {
steps {
script {
git 'https://github.com/nbbull/demoProject.git'
sh 'sleep 50'
}
}
}
}
}
可以把 agent 的逻辑统一抽象到共享库,就可以实现所有的 job 都通过 K8S 进行构建,至此部署完成。
除了结合 K8S 搭建 Jenkins 集群保证高可用以外,最后再补充总结一些 jenkins 自身的性能调优技巧,这里不再展开,具体可在使用中去体会和补充。
• 使用 Pipeline 方式比配置方式运行更快。
• 让 Pipeline 做中间组织的工作,而不是取代其他工具。
• 能用脚本实现的,就不要用插件。
• 根据资源情况限制并发执行的 job 数量。
• 使用共享库抽象公共的代码并持续优化。
• 不要写太复杂的 Pipeline 脚本(>1000 行),包括共享库代码在内。
• 不要对外网环境有强依赖(万恶的墙)。
• 使用 “@NonCPS” 注解高耗代码方法。
• 使用 SSD 硬盘等高性能硬件
• Durability/Speed Options
主帖直达:https://testerhome.com/topics/9977
