Wings 提供了一种自动生成驱动函数的单元测试方法,其中主要包含以下几个步骤:

单元测试是保证软件质量非常有效的手段,无论是从测试理论早期介入测试的理念来看或是从单元测试不受 UI 影响可以高速批量验证的特性,所以业界所倡导的测试驱动开发,这个里面提到的测试驱动更多的就是指单元测试驱动。但一般开发团队还是很少的系统化的执行单元测试,针对应用软件的测试更多是由专业测试团队来执行黑盒测试。单元测试的最大的难点不在于无法确定输入输出,这毕竟是模块开发阶段就已经定好的,而在于单元测试用例的编写会耗费开发人员大量的工时,按照相关统计单元测试用例的时间甚至会远超过功能本身开发的时间。其次,功能需求还不稳定,写单元测试的性价比不高。换句话说,万一明天需求一变,那不光功能代码废了,单元测试也废了。如果不写单元测试,那这部分工夫就不会白费。
制约测试用例采用程序自动生成,最关键的底层技术是复杂的参数解析技术。即:能够在编译器层面对于任意复杂的类型,任意定义嵌套层级的递归解析。如果没有这个关键技术的突破,那么测试用例自动生成系统要么无法商用,要么将以极低的效率来演化、产生合规的测试数据。例如著名的模糊测试工具 American Fuzzy Lop,它并不能够识别用户的程序所需要的结构类型,需要从最外层进行基于搜索算法的演化。程序的特性是接口层面的输入和内部某个模块的数据要求距离很远,外部数据通常是经过层层复杂转换才可以成为内部模块所需要的数据结构类型,因此从外层探索所需要的计算量和时间将是难以想象的。基于 American Fuzzy Lop,为了能够生成一个合法的 SQL 语句,让程序内部模块能够通过外围数据校验需要探索时间以天数计,远非分钟或者小时可以生成。另外一个制约性条件是:每个程序能够接手的输入都是经过精心结构编制、含有大量规则的数据,而这些数据通过随机 + 探索的方式生成是非常不现实和极其耗时的。所以,从黑盒以及最外层输入产生自动产生用例是不可行的。
如果从软件内部结构分析产生用例驱动,就需要对软件的编译结构进行深度理解。可行的测试用例生成系统,应该是基于程序的中间(关键入口)作为测试切入最为合适。这些模块的输入,已经将模糊的输入转化为高度结构化的参数。只要能够识别这些复杂结构,将复杂数据类型一步步降解为简单数据类型,同时完成参数构造,就可以自动完成驱动用例的生成。
基于模块的测试,可以划归为传统的单元测试,它是将缺陷发现并遏制在研发阶段最好的方法。但受限于单元测试需要开发大量的驱动程序,在行业内的推广和应用受到了极大的限制。当然单元测试也可以在系统集成完毕后执行,避免构建虚拟的桩程序。
一款单元测试用例自动生成 Wings 工具,现分享给大家。
(1)程序参数深度分析问题
Wings 通过编译器底层技术,将输入的源文件,按照函数为单位,形成模块对象。对象中包含函数的输入参数,返回值类型等信息,供驱动函数模块和测试用例模块使用。每个文件作为一个单元,针对其中的每个函数的每个参数进行深度解析,对于嵌套类型,复杂类型等都可以实现精确的解析和分解,将复杂类型逐层讲解为基础数据类型,并产生参数结构的描述文件(PSD)。
(2)函数驱动自动生成模块
依据 PSD 文件的格式信息,自动生成被测源程序的所有驱动函数,单元测试过程不再依赖开发人员手动编写测试函数,只需将生成的驱动函数和被测源文件一起编译,即可执行测试并查看测试结果。测试驱动自动生成程序基于 PSD 描述,全自动构建驱动被测程序运行的所有参数,必须的全局变量,并可根据复杂变量的层级结构产生结构化的测试驱动程序,可以节省大量的单元测试用例的编写时间。
(3)测试数据自动生成与管理
用于自动生成测试数据,测试数据与被测函数提取的信息相互对应,数据以一定的层次逻辑关系存储在 json 文件中。数据和经过分解和展开后的数据类型是一一对应的。这些数据用户可以根据业务要求随意边际,并且用 json 文件进行结构化,层次化展示,非常的清晰。其中的测试数据包括全局变量值、被测函数调用时的参数值。
Wings 提供了一种自动生成驱动函数的单元测试方法,其中主要包含以下几个步骤:
通过对源程序的扫描提取出函数的结构信息,使用户不需要关心程序的结构信息,而被测程序的结构信息,主要包含程序中的全局变量以及函数信息,而函数信息主要包括函数的参数个数,参数类型以及返回值类型。而全局变量以及参数,最主要的提取出其中的符号信息,以及类型信息,针对一些复杂的类型,通过层层进行解析为基本数据类型,完成全局变量以及函数参数的构造。
变量的类型一般大致分为基本类型、构造类型、指针类型及空类型。Wings 通过底层编译技术,针对不同的变量类型,进行不同的处理方式。
(1)基本类型,例如 unsigned int u_int = 20 等基本类型,Wings 将解析出变量的名称为 u_int,数据类型为 unsigned int。
(2)构造类型,构造类型大致分为数组,结构体,共用体,枚举类型。
数组类型,例如 int array[2][3],数组名称为 array,类型为 int 以及二维数组的长度,行为 2,列为 3。
结构体类型,针对结构体为数组,结构体链表等,进行不同的标记划分。
(3)指针类型,例如 int **ptr = 0;,解析出指针为 int 类型的 2 级指针。
(4)空类型,解析出类型为 NULL。
(5)系统类型,例如 File、size_t 等,标记为系统类型,不在对其往下进行分析,会添加到模板中,由用户进行赋值操作。
(6)函数指针类型,分析出函数的返回值类型、参数类型以及参数个数
针对被测源程序的每个编译单元,将解析到的函数信息,保存在对应的 PSD 结构中,针对以下源代码实例进行说明:
typedef struct my_structone
{
//基本类型
int i_int;
//数组类型
int array_one[2];
int array_two[3][4];
//指针类型
int *point_one;
int **point_two;
//空类型
void *point;
//位域类型
unsigned int w : 1;
//函数指针是指向函数的指针变量,即本质是一个指针变量
int(*functionPtr)(int, int);
union
{
int a;
char b;
long long c;
}Dem;
enum DAY
{
MON = 1, TUE, WED = 200, THU, FRI = 100, SAT, SUN
}dy;
}myy_structone;
typedef struct my_struct
{
//结构体包含结构体
myy_structone *structone;
//结构体中包含系统头文件的类型
FILE file;
struct my_struct *next;
}myy_struct;
//结构体作为函数参数
void StructTypeTest1(myy_struct m_struct);
void StructTypeTest2(myy_struct *mm_struct);
void StructTypeTest3(myy_struct mm_struct[2]);
void StructTypeTest4(myy_struct mm_struct[2][3]);
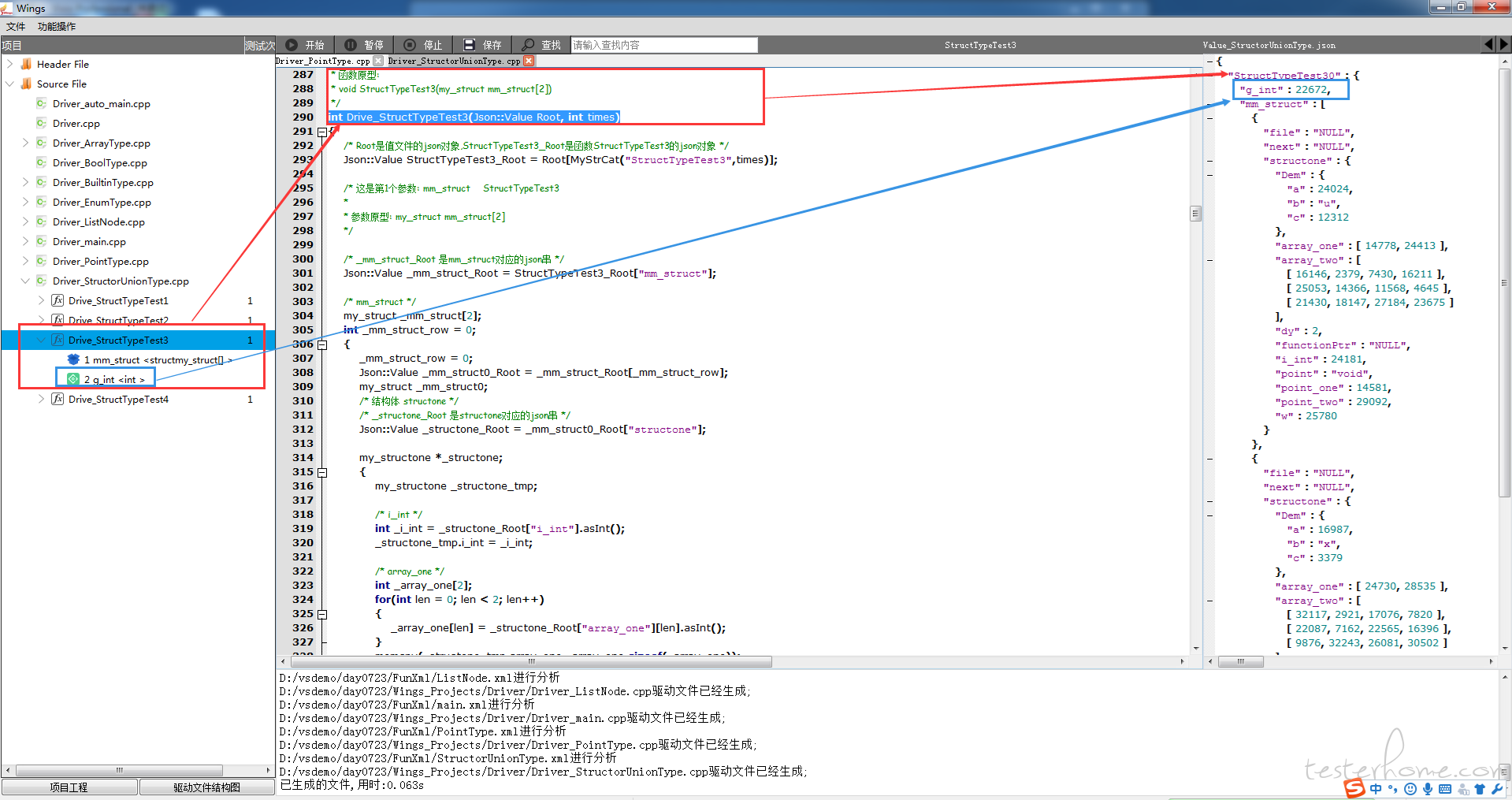
以上程序中,void StructTypeTest3(myy_struct mm_struct[2]) 保存的 PSD 结构如下:
<StructTypeTest3 parmType0="myy_struct [2]" parmNum="1">
<mm_struct baseType1="ArrayType" RowSize="2" type="StructureOrClassType" name="my_struct">
<structone baseType1="PointerType" type="StructureOrClassType" name="my_structone">
<i_int baseType1="BuiltinType" type="ZOA_INT" />
<array_one baseType1="ArrayType" RowSize="2" type="ZOA_INT" />
<array_two baseType1="ArrayType" RowSize="3" baseType2="ArrayType" ColumnSize="4" type="ZOA_INT" />
<point_one baseType1="PointerType" type="ZOA_INT" />
<point_two baseType1="PointerType" baseType2="PointerType" type="ZOA_INT" />
<point baseType1="PointerType" type="ZOA_VOID" />
<w baseType1="BuiltinType" type="ZOA_UINT" bitfield="1" />
<functionPtr baseType1="FunctionPointType" type="ZOA_FUNC" returnType="int" parmType0="int" parmType1="int" parmNum="2" />
<Dem baseType1="UnionType" type="ZOA_UNION" name="NULL">
<a baseType1="BuiltinType" type="ZOA_INT" />
<b baseType1="BuiltinType" type="ZOA_CHAR_S" />
<c baseType1="BuiltinType" type="ZOA_LONGLONG" />
</Dem>
<dy baseType1="EnumType" type="ZOA_ENUM" name="DAY">
<MON type="ZOA_INT" value="1" />
<TUE type="ZOA_INT" value="2" />
<WED type="ZOA_INT" value="200" />
<THU type="ZOA_INT" value="201" />
<FRI type="ZOA_INT" value="100" />
<SAT type="ZOA_INT" value="101" />
<SUN type="ZOA_INT" value="102" />
</dy>
</structone>
<file baseType1="StructureOrClassType" type="StructureOrClassType" name="_iobuf" SystemVar="_iobuf" />
<next NodeType="LinkNode" baseType1="PointerType" type="StructureOrClassType" name="my_struct" />
</mm_struct>
<g_int globalType="globalVar" />
<returnType returnType="void" />
</StructTypeTest3>
其中 PSD 文件各节点代表的意义如下:
● StructTypeTest3 代表函数名,parmType0 代表参数类型,parmNum 代表参数个数
● mm_struct 代表函数参数的符号,baseType1 代表类型的分类(基本数据类型、构造类型、指针类型、空类型),type 代表具体的类型,包括 int,char,short,long,double,float,bool,以及这些类型的 unsigned 类型等基础的类型,还有一些特殊的类型诸如:ZOA_FUN 类型表示函数类型,StructureOrClassType 表示结构体类型,等等,name 代表结构体、联合体、枚举类型的名称
● i_int 代表基本类型,基本类型作为最小的赋值单位
● array_one 代表数组类型,RowSize 代表数组的长度,数组可以划分为一维数组,二维数组等
● point 代表指针类型,指针分为一级指针、二级指针等,一般指针当做函数参数作为数组使用,因此,针对基本类型的指针,采用动态分配数组的方式进行赋值,用户可依据需要,修改对应的值文件。
● w 代表位域类型,bitfileld 代表所占位数
● functionPtr 代表函数指针类型,分别分析出参数类型、参数个数、返回值信息
● Dem 代表联合体类型
● dy 代表枚举类型,value 代表枚举类型的取值
● file 代表结构体类型,SystemVar 代表此变量属于系统头文件中的变量,针对此种类型的变量,Wings 通过添加模板变量的方式,添加在模板库中,用户可依据具体需要进行特殊赋值。例如 File 类型的,处理方式为:
/* 系统内置类型,特殊处理或者模板处理 */
char * fname = "E:/spacial.txt";
FILE * file = fopen(fname,"r");
_st.file = _file;
用户也可自行添加赋值方式。针对系统类型,Wings 可以和普通用户自定义类型进行区分,当解析到系统内置类型的时候就可以停止向下进行递归分析。
● g_int 代表全局变量,globalType 代表全局
● next 代表链表结构体,NodeType 代表此结构为链表
● returnType 代表函数的返回值类型。
在上文中,针对全局变量和函数的结构信息,进行了分析和提取,以下将利用提取到保存在 PSD 中的信息,完成被测源程序的驱动框架整体生成。
生成主要分为以下几个方面:
● 全局变量的声明
● 函数参数的赋值操作,针对函数参数的个数,依次赋值操作
● 全局变量的赋值,针对分析得到函数使用的全局变量的个数,依次进行赋值操作
● 原函数的调用
一些需要注意点如下:
● 驱动生成过程中,针对一些特殊函数,例如 main 函数,static 函数等,因为外部无法访问到,驱动生成暂时不做处理。
● 针对每个被测源文件,生成对应的一个驱动文件。
● 驱动控制包含在 Driver_main.cpp 中,可以通过宏自动配置函数的测试次数
由以上源程序,生成的驱动函数如下:
● 所有变量的命名为在原变量的名称前,添加_
● 通过获取生成对应的测试数据,对变量依次进行赋值操作
● 针对系统内置参数,以及用户比较特殊的参数,通过模板方式统一配置赋值方式。
● 对被测函数进行参数赋值与调用。
测试用例的自动生成,利用提取到保存在 PSD 中的函数信息,进行测试用例数据的生成,以下是图三中 PSD 格式生成的一组数据,每组数据保存为 JSON 格式,更容易看到数据的层次关系。
"StructTypeTest30" : {
"g_int" : 11624,
"mm_struct" : [
{
"file" : "NULL",
"next" : "NULL",
"structone" : {
"Dem" : {
"a" : 20888,
"b" : "A",
"c" : 19456
},
"array_one" : [ 24441, 12872 ],
"array_two" : [
[ 18675, 30300, 32216, 19566 ],
[ 13566, 13319, 11179, 18867 ],
[ 30514, 21664, 21641, 28262 ]
],
"dy" : 101,
"functionPtr" : "NULL",
"i_int" : 18271,
"point_one" : [ 28024, 32245, 2129 ],
"point_two" : [
[ 18165, 32335, 6429 ],
[ 30225, 18252, 2764 ],
[ 3177, 3622, 29789 ]
],
"w" : 16862
}
},
{
"file" : "NULL",
"next" : "NULL",
"structone" : {
"Dem" : {
"a" : 2651,
"b" : "7",
"c" : 12159
},
"array_one" : [ 1274, 24318 ],
"array_two" : [
[ 27944, 1208, 29647, 20840 ],
[ 4972, 27297, 17456, 13614 ],
[ 22441, 1160, 8940, 29420 ]
],
"dy" : 200,
"functionPtr" : "NULL",
"i_int" : 15434,
"point_one" : [ 29394, 3868, 25406 ],
"point_two" : [
[ 13575, 14736, 20728 ],
[ 9132, 2297, 2113 ],
[ 26252, 14896, 10985 ]
],
"w" : 12354
针对每个编译单元,默认生成一组所有函数的对应的测试数据文件,值生成可以通过配置次数进行修改。
如何完成驱动框架的生成,下面针对开源程序 MySQL 完整的生成过程,进行详细说明。
以下是 Wings 测试 Mysql 的主界面图:
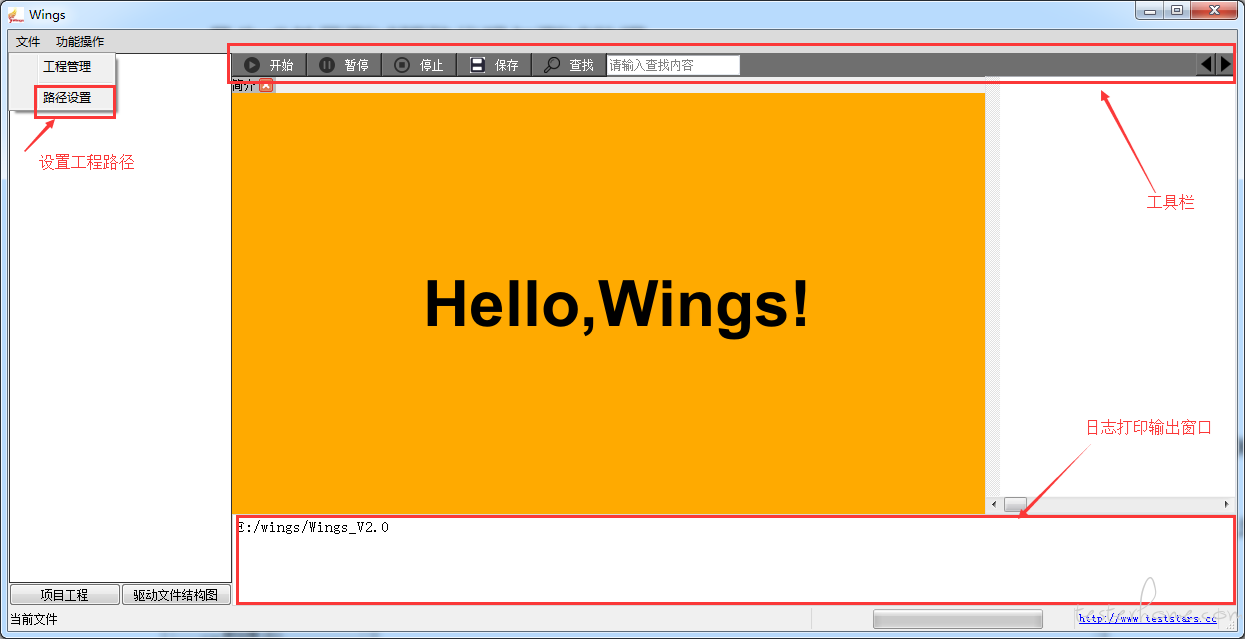
点击文件按钮,设置被测源程序的工程目录。设置完成之后,点击功能操作,功能操作主要包括参数解析、驱动生成、值文件生成以及模板添加四个操作。分析对应生成以下几个文件夹:
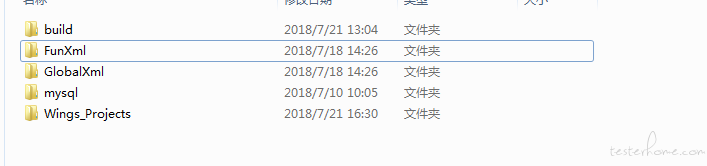
其中,参数解析模块,对应生成 FunXml 以及 GlobalXml,分别存放提取到的每个编译单元的函数信息及全局变量的信息。
驱动生成模块,会对应生成 Wings_Projects 文件夹,其中存放每个编译单元的驱动文件
值生成模块,存放每个编译单元的生成的测试数据。
下图为 Mysql 对应加载的驱动文件结构体信息,左侧导航树为生成的对应驱动文件,包含每个编译单元的函数以及函数的参数、全局变量的信息。点击其中某个编译单元,可以加载对应的驱动文件以及对应的值文件。
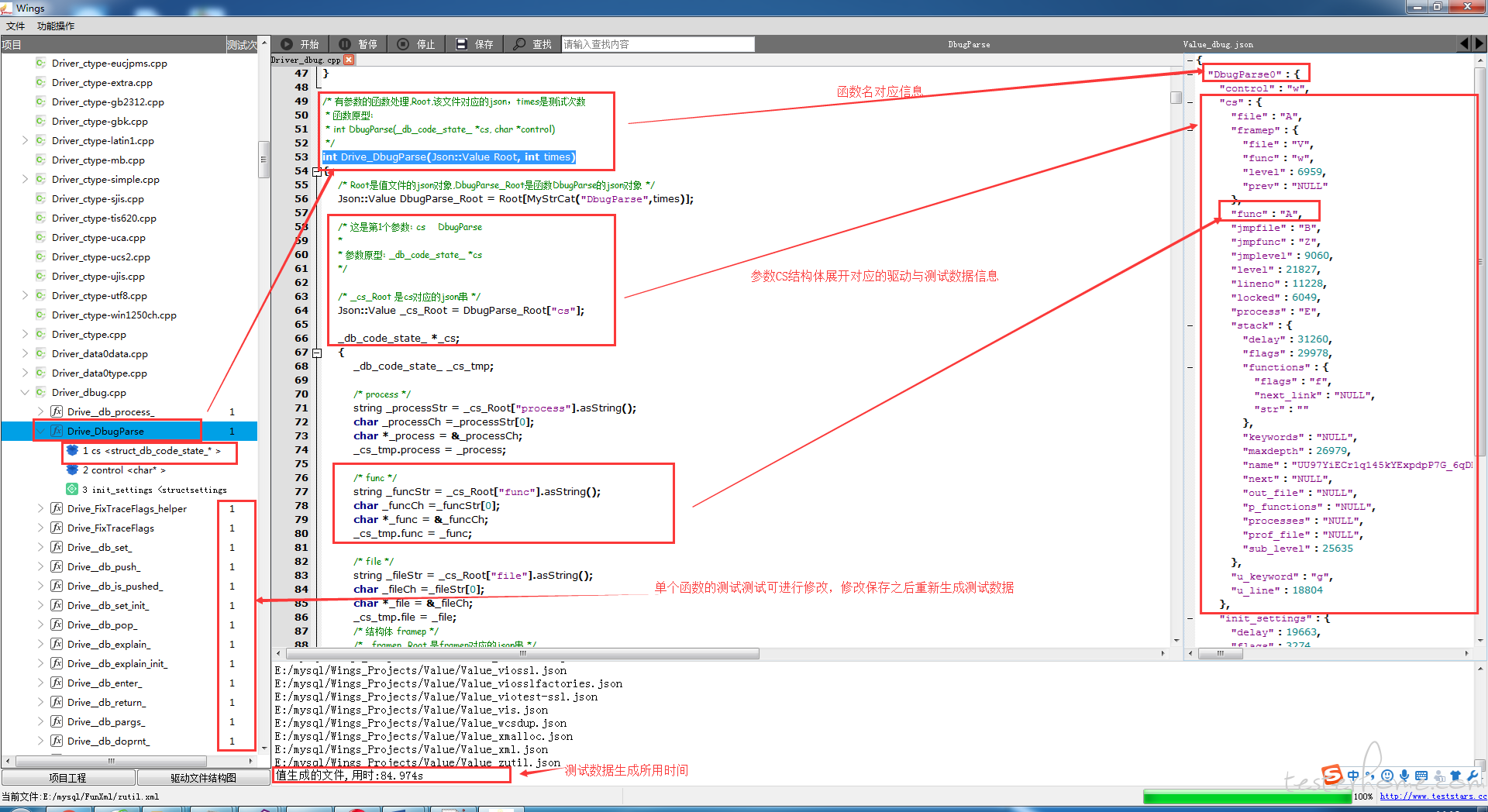
以上是 Mysql 的整体生成对应的驱动文件以及值文件,针对以下代码详细说明驱动文件。
● 针对每个编译单元,全局变量的引用通过 extern 的方式。
● 驱动函数,统一命名为 Driver_XXX 的方式,JSON 作为获取测试数据的方式,times 代表单函数的测试次数。
● 针对每个参数的赋值操作,利用解析到的 PSD 存储格式,对每层结构依次进行赋值操作。
Wings 的应用非常简单,下面是以在 Visual Studio 2015 中可正常编译的 Mysql 代码为例,生成的测试数据的统计指标,整个生成过程无需任何人工介入,仅需要制定所需要生成驱动的源码的路径即可。
| mysql 测试数据 | |
|---|---|
| Mysql 版本 | 5.5 |
| C 语言代码文件个数 | 578 个 |
| 分析所用时间(PSD 生成时间) | 149.099s |
| 驱动生成所用时间 | 27.461s |
| 值生成所用时间 | 84.974s |
| 电脑配置说明: | |
|---|---|
| 操作系统 | Windows7 |
| 处理器 | Inter(R) Core(TM) i7-7700cpu 3.60GHz |
| 内存 | 8.00GB |
| 系统类型 | 64 位 |
以下是使用源码统计工具得到的结果,多达 400 多万行有效的单元测试代码是由 Wings 全自动生成的。更有意思的是:可以看到这些代码采用人工开发的成本高达 1079 个人月,成本更是达到了 1079 万之多。
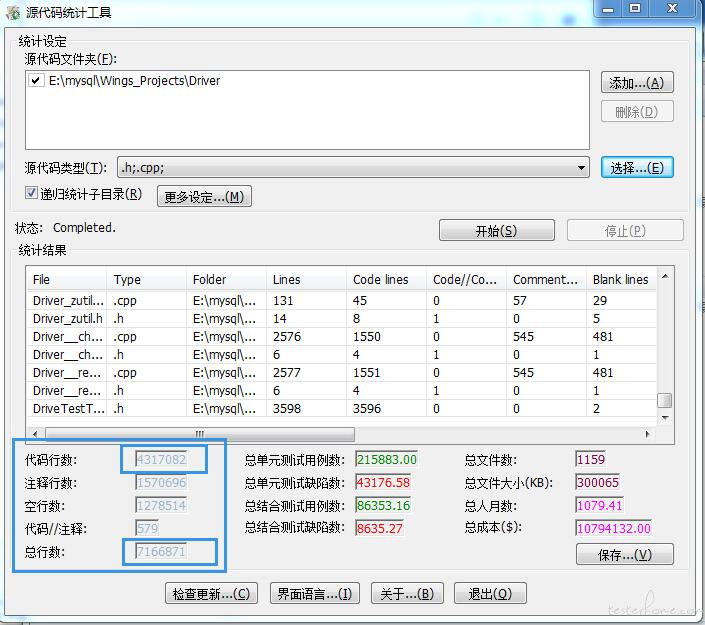
Wings 实现了由程序自动生成程序的第一步,目前发布的是第一版,可能大家对这些数据比较感兴趣,也可能带有怀疑,有兴趣的开发者可以自己体验一下
https://wings.readthedocs.io/zh/latest/about.html?tdsourcetag=s_pctim_aiomsg
