
作者:段聪,腾讯社交平台部高级工程师
商业转载请联系腾讯 WeTest 获得授权,非商业转载请注明出处。
原文链接:https://wetest.qq.com/lab/view/421.html
近期测试反馈一个问题,在旧版本微视基础上覆盖安装新版本的微视 APP,首次打开拍摄页录制视频合成时高概率出现 crash。
那么我们直奔主题,看看日志:
另外复现的日志中还出现如下信息:
'/data/data/com.tencent.weishi/appresArchiveExtra/res1bodydetect/bodydetect/libxnet.so: strtab out of bounds error

后经过测试,发现覆盖安装后首次使用美体功能也会出现 crash,日志如下:
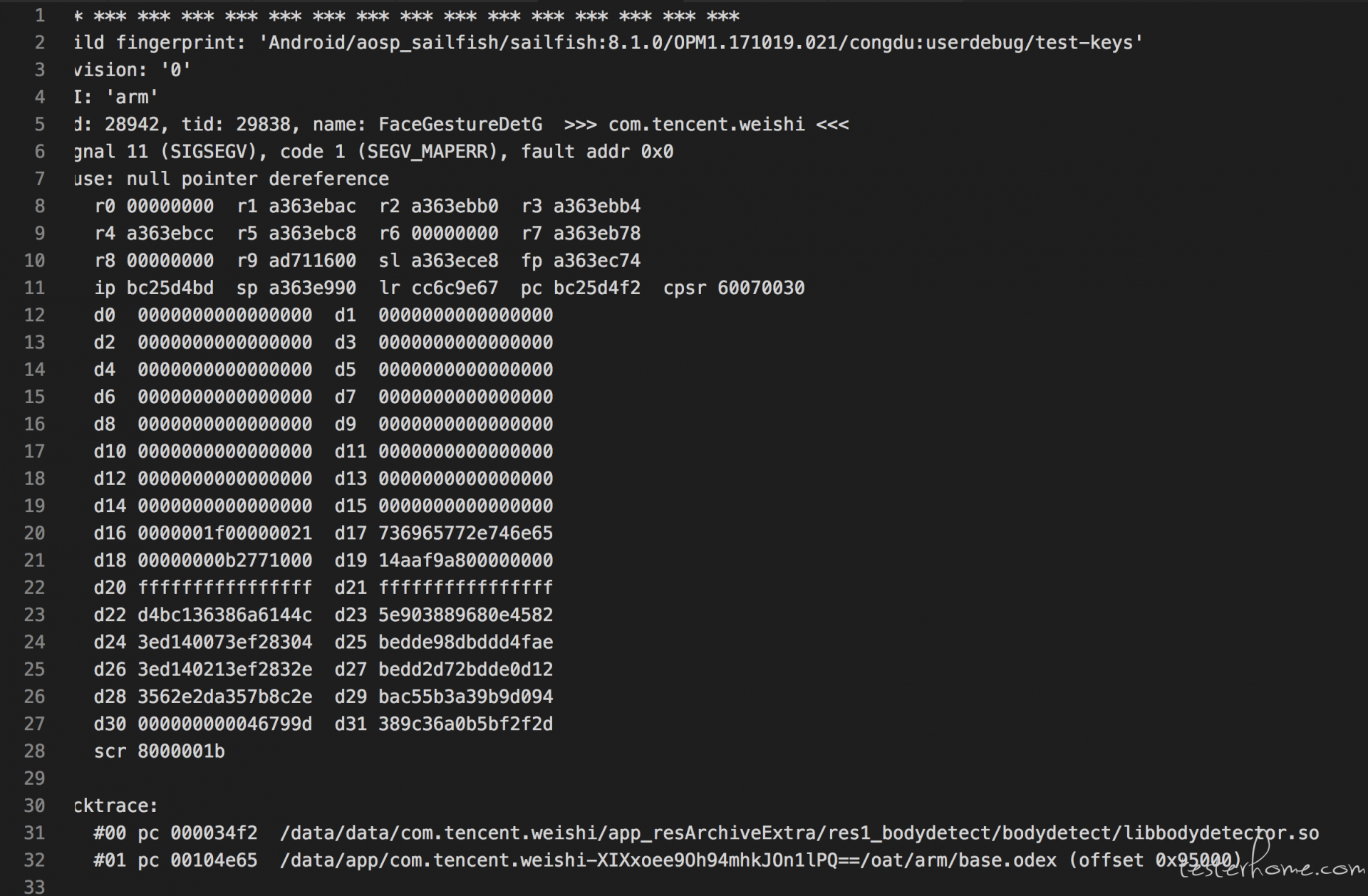
由于出现问题的场景都是覆盖安装首次使用,并且涉及到人体检测相关的 so,似乎存在某种共同的原因。
因此 Abort 异常比起 fault addr 类问题更容易分析,先从前面 Linker 出现 Abort 异常的位置开始着手。
Linker 是 so 链接和加载的关键,属于系统可执行文件,因此分析起来比较棘手。好在手上正好有一台刚刷完自己编译的 Android AOSP 的 Pixel,做一些实验变得更轻松了。
出现异常的 Linker 代码 linker_soinfo.cpp 如下:
const char* soinfo::get_string(ElfW(Word) index) const {
if (has_min_version(1) && (index >= strtab_size_)) {
async_safe_fatal("%s: strtab out of bounds error; STRSZ=%zd, name=%d",
get_realpath(), strtab_size_, index);
}
return strtab_ + index;
}
bool soinfo::elf_lookup(SymbolName& symbol_name,
const version_info* vi,
uint32_t* symbol_index) const {
uint32_t hash = symbol_name.elf_hash();
TRACE_TYPE(LOOKUP, "SEARCH %s in %s@%p h=%x(elf) %zd",
symbol_name.get_name(), get_realpath(),
reinterpret_cast(base), hash, hash % nbucket_);
ElfW(Versym) verneed = 0;
if (! find_verdef_version_index(this, vi, &verneed)) {
return false;
}
for (uint32_t n = bucket_[hash % nbucket_]; n != 0; n = chain_[n]) {
ElfW(Sym)* s = symtab_ + n;
const ElfW(Versym)* verdef = get_versym(n);
// skip hidden versions when verneed == 0
if (verneed == kVersymNotNeeded && is_versym_hidden(verdef)) {
continue;
}
if (check_symbol_version(verneed, verdef) &&
strcmp(get_string(s->st_name), symbol_name.get_name()) == 0 &&
is_symbol_global_and_defined(this, s)) {
TRACE_TYPE(LOOKUP, "FOUND %s in %s (%p) %zd",
symbol_name.get_name(), get_realpath(),
reinterpret_cast(s->st_value),
static_cast(s->st_size));
*symbol_index = n;
return true;
}
}
TRACE_TYPE(LOOKUP, "NOT FOUND %s in %s@%p %x %zd",
symbol_name.get_name(), get_realpath(),
reinterpret_cast(base), hash, hash % nbucket_);
*symbol_index = 0;
return true;
}
从代码上看,是在 so 的 symtab 中查找某个符号时 ElfW(Sym)* s 的地址出现异常,导致 s->st_name 获取到错误的数据。
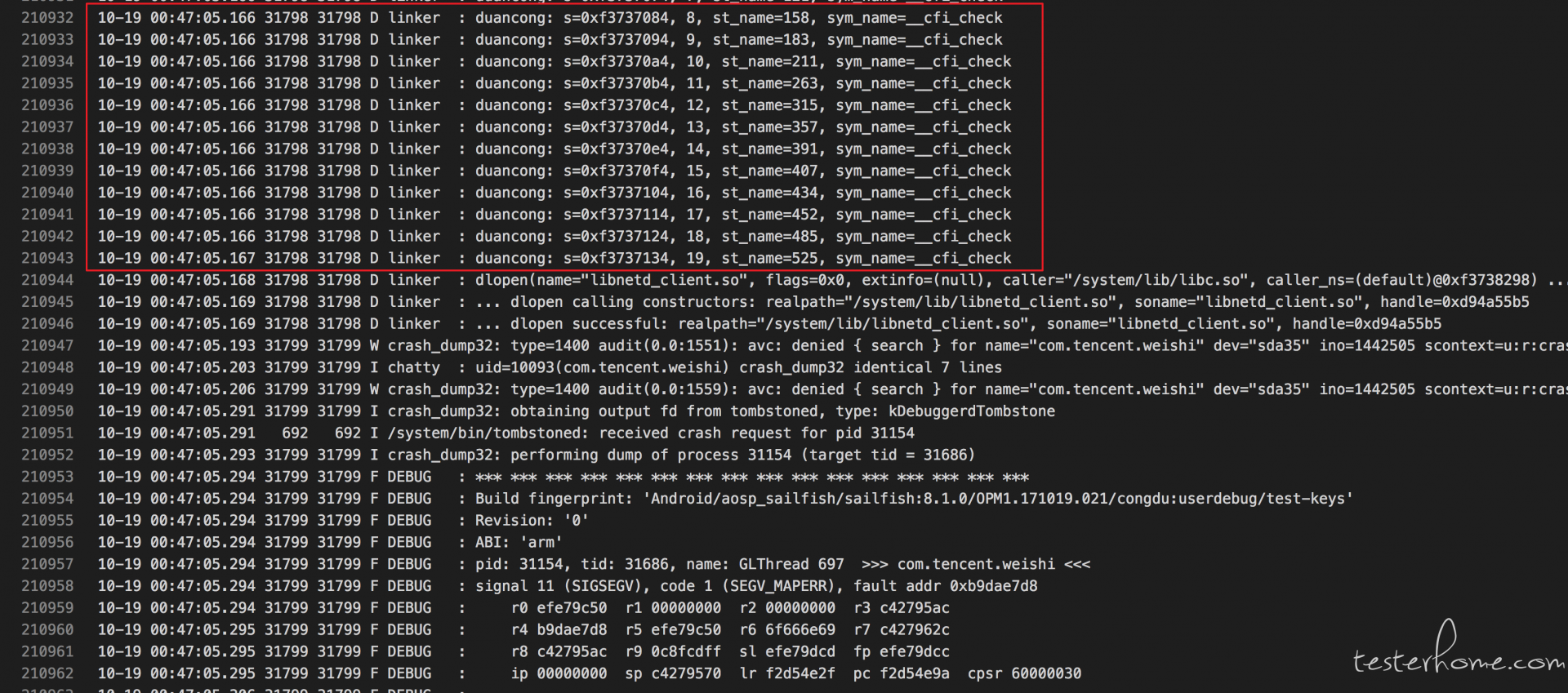
通过复现问题,可以抓到更完整的 /data/tombstone 日志,得到如下完整的信息:
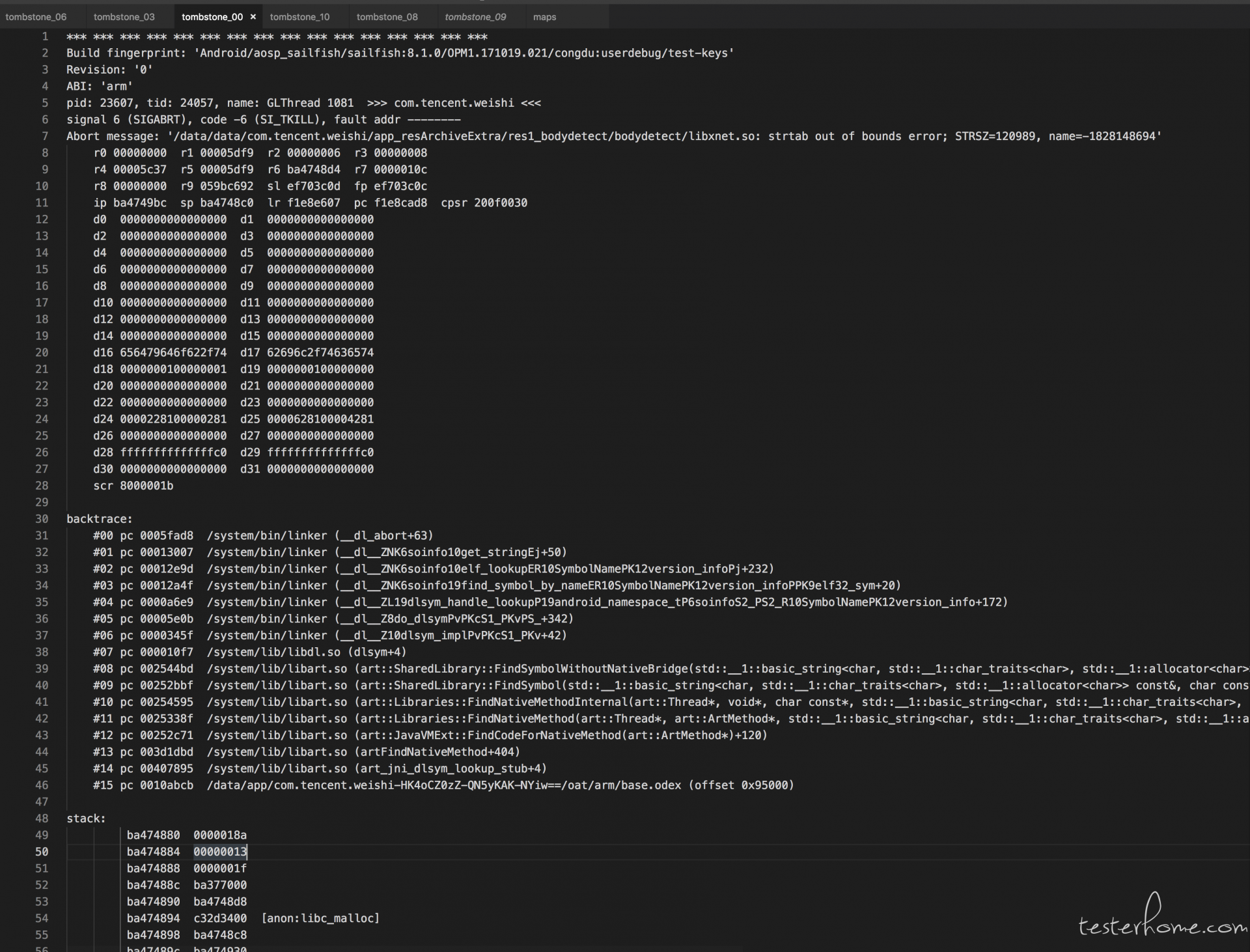
尽管从 tombstone 中我们可以看到一些寄存器数据及寄存处地址附近内存数据,同时也可以看到 crash 时的虚拟内存映射表,仍然无法获取有价值的信息。另外通过几次复现,发现并不是每次 Crash 都是 SIGABRT,也出现不少 SIGSEGV 信号,而调用栈和之前都是一样的,比如这个:
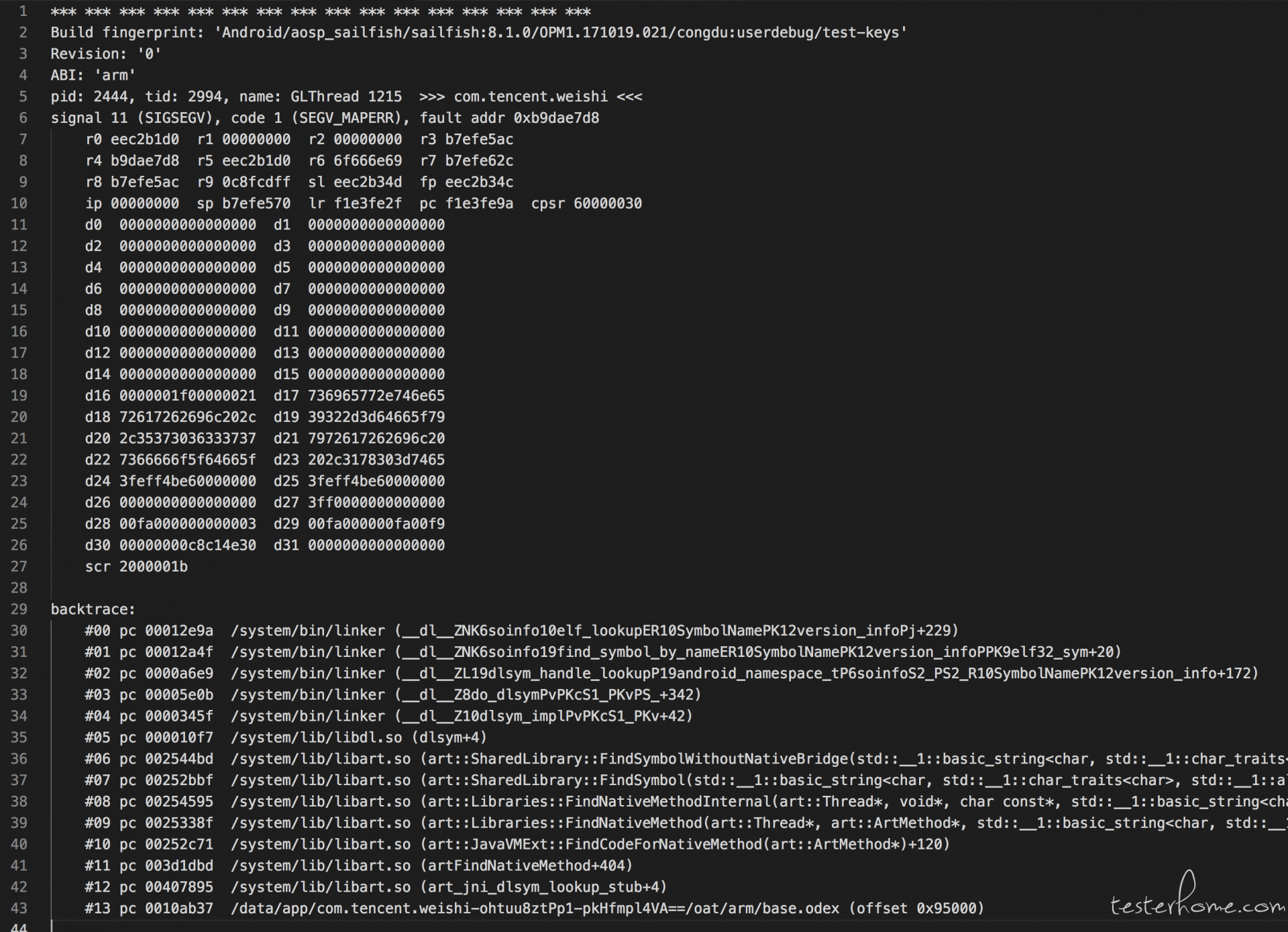
这基本上可以说明,并不是 so 本身的代码存在异常,只可能是加载的 so 出现了文件异常。
另外通过在 linker 中增加日志,并重新编译 linker 替换到/system/lib/linker 中:
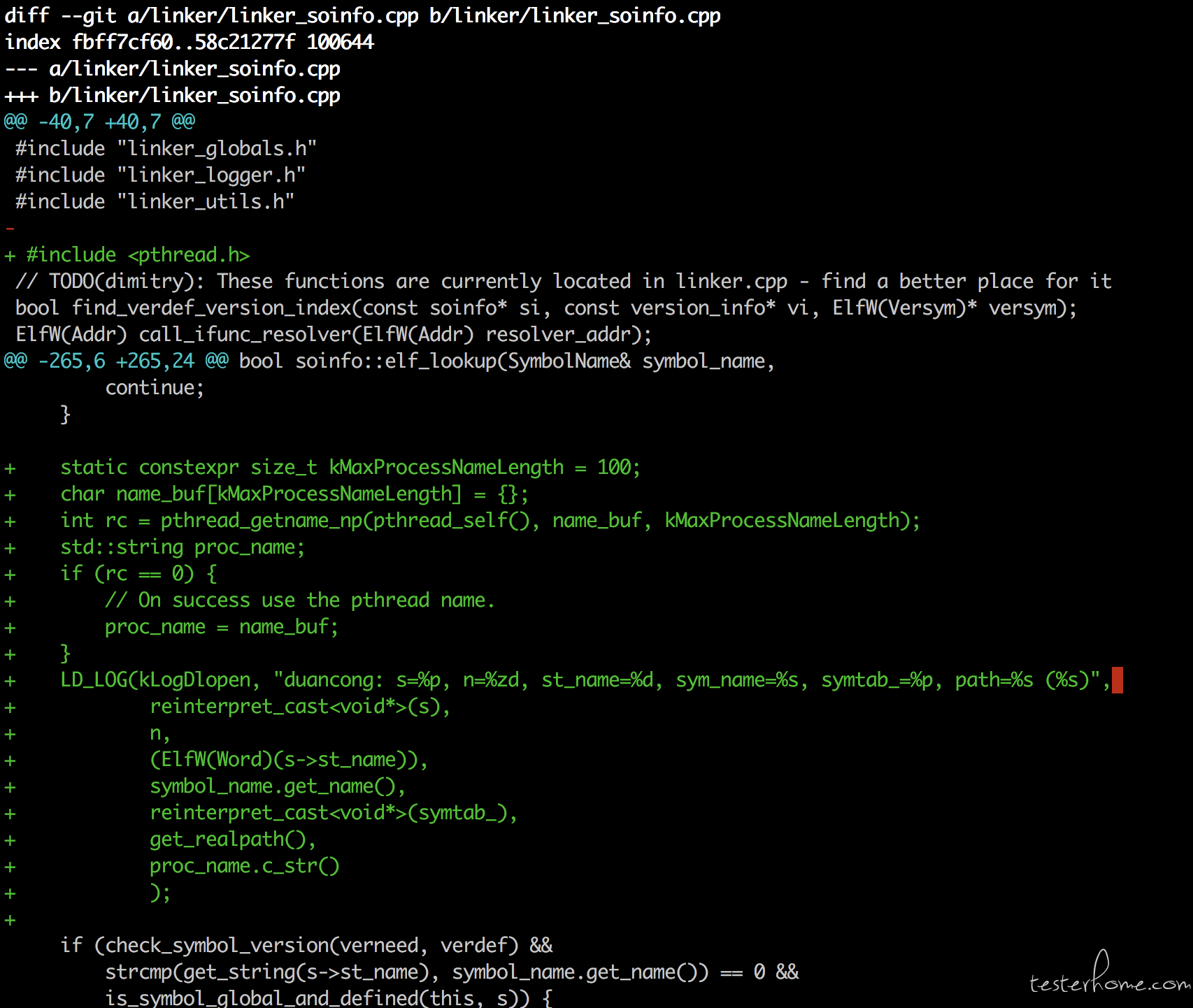
可以获取到如下的地址信息:
通过根据 tombstone 中的/proc//maps 的虚拟内存地址与日志打印的地址进行对比,可以发现最为符号表地址的 s 并没有指向 so 文件在虚拟内存中的地址段,因此可以怀疑,so 加载确实出现了异常。
因为手机 root,可以直接获取到 crash 时的 so 文件 (adb pull /data/data/com.tencent.weishi/appresArchiveExtra/res1bodydetect/bodydetect/libxnet.so),导出来对比 md5,然而发现与正常情况下的 so 是一模一样的:

既然前面的这些实验都没有得出什么有意义的结论,那么我回过头来分析一下,与问题关联的 so 加载到底有什么特殊性。
实际上,微视为了减包,将一部分 so 文件进行下发,由于 so 也处于不断迭代的过程中,新版本的微视可能会在后台更新 so 文件,那么客户端一旦发现新的版本有新的 so,就会去下载 so 并进行本地替换。
那么这个过程有什么问题呢?唯一可能的问题,就是先加载了旧的 so,之后下载新的 so 进行了热更新。
我们先看下微视中是否有这种现象。要观察这种现象,我们可以打开 linker 自身的调试开关,开启 so 加载的日志。通过设置系统属性,我们可以很容易地进行开启 LD_LOG 日志:
adb shell setprop debug.ld.all dlerror,dlopen
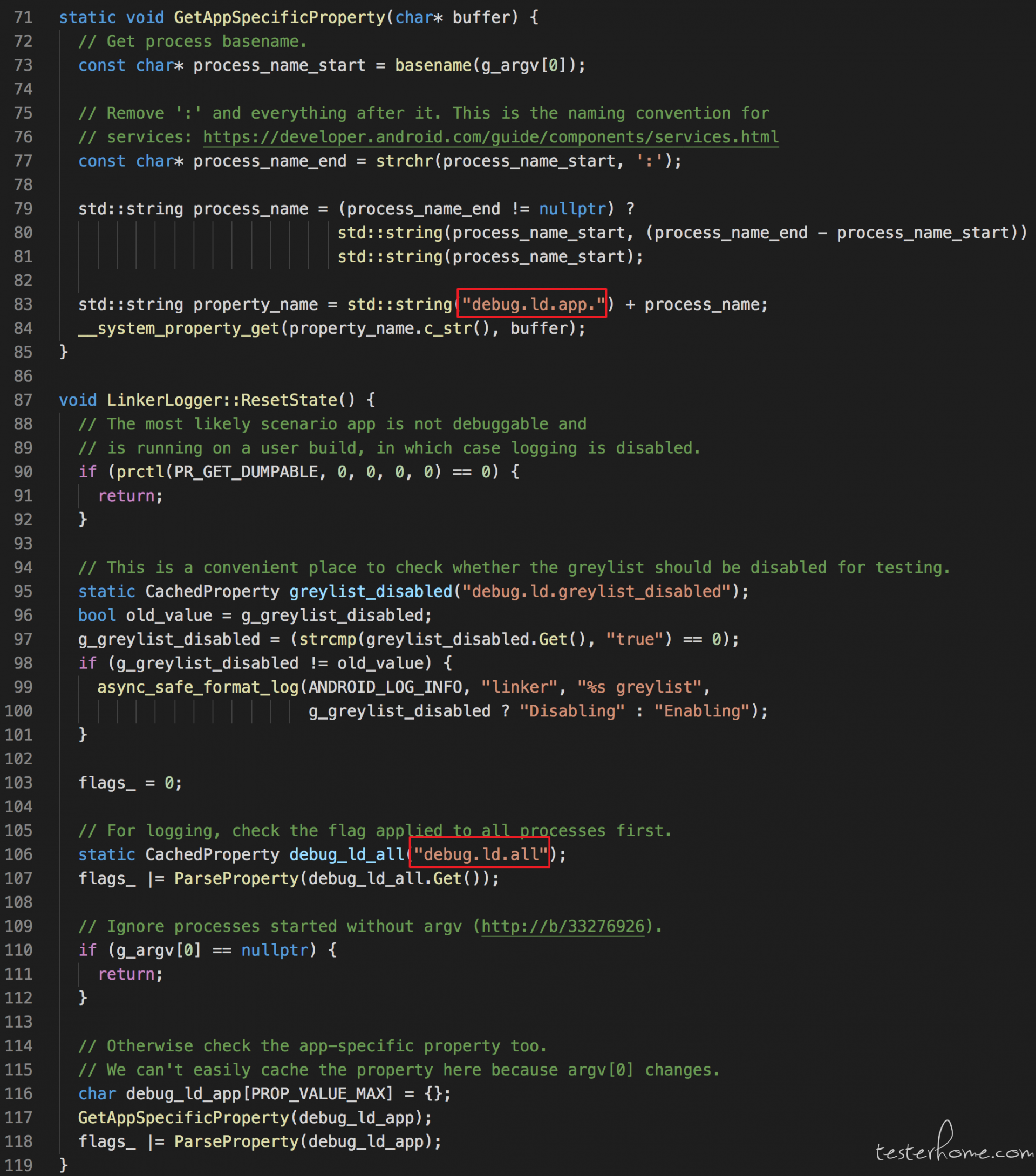
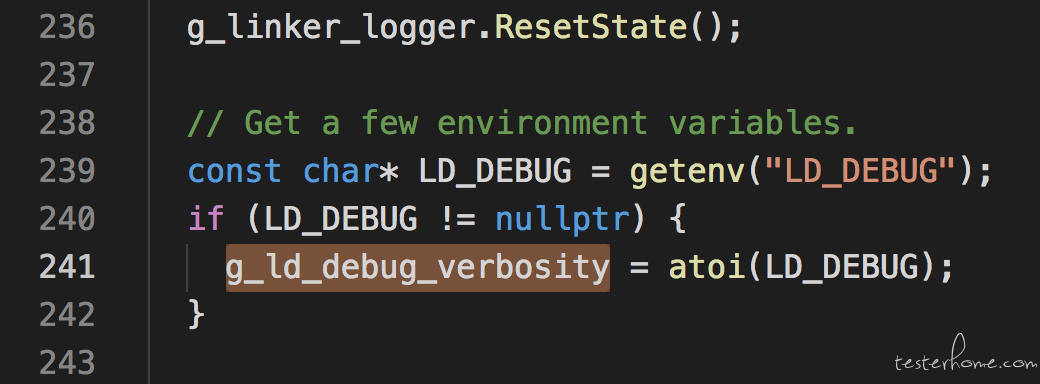
当然我们也可以只针对某个应用开启这个日志(设置系统属性 debug.ld.app.)。另外,为了开启 linker 中更多的日志,比如 DEBUG 打印的信息等,我们只需要在 adb shell 中设置环境变量:
export LD_DEBUG=10
那么,我们重新复现问题,可以看到如下 so 加载过程:
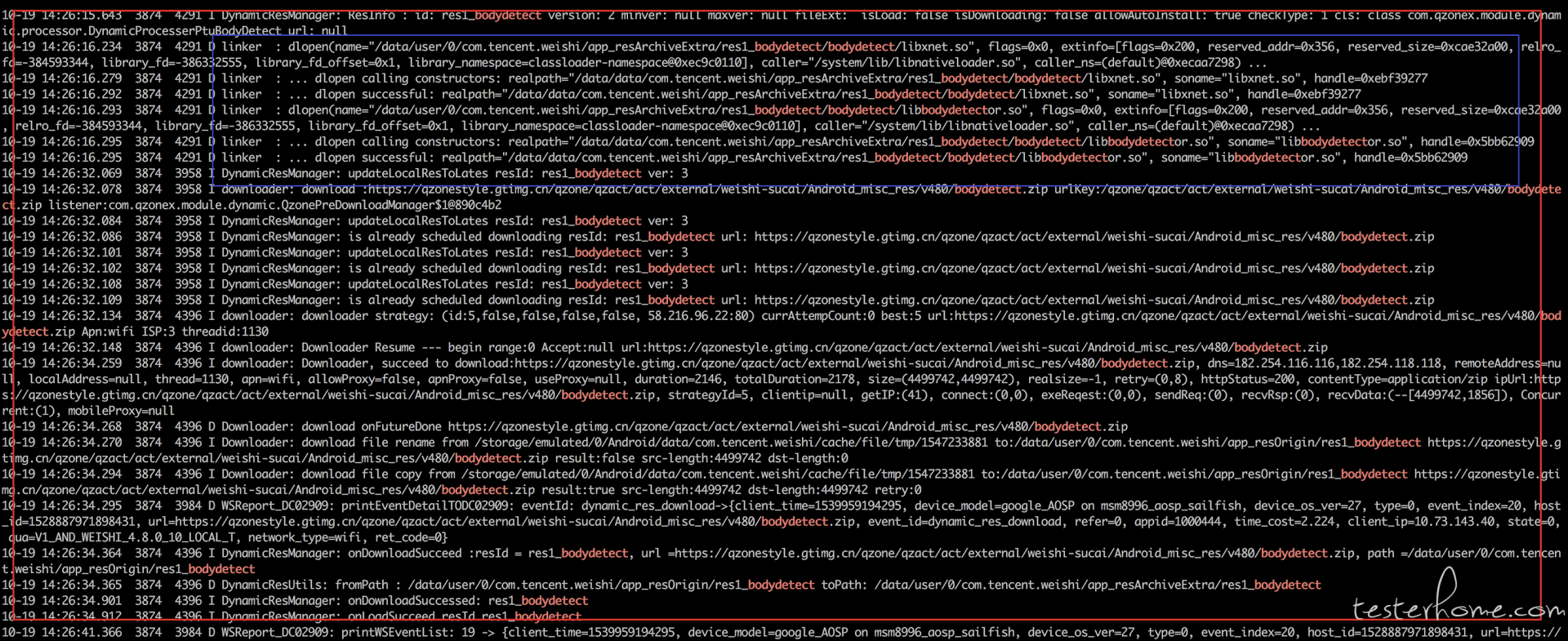
这个过程表明:旧的 so 先被加载了,然后下载了新版本的 so,并进行了替换。
这个过程有什么问题呢?根据《理解 inode》一文我们可以得知,linux 的文件系统使用的 inode 机制支持了 so 文件的热更新(动态更新),即每个文件都有一个唯一的 inode 号,打开文件后使用 inode 号区分文件而不是文件名:
八、inode 的特殊作用
由于 inode 号码与文件名分离,这种机制导致了一些 Unix/Linux 系统特有的现象。
1. 有时,文件名包含特殊字符,无法正常删除。这时,直接删除 inode 节点,就能起到删除文件的作用。
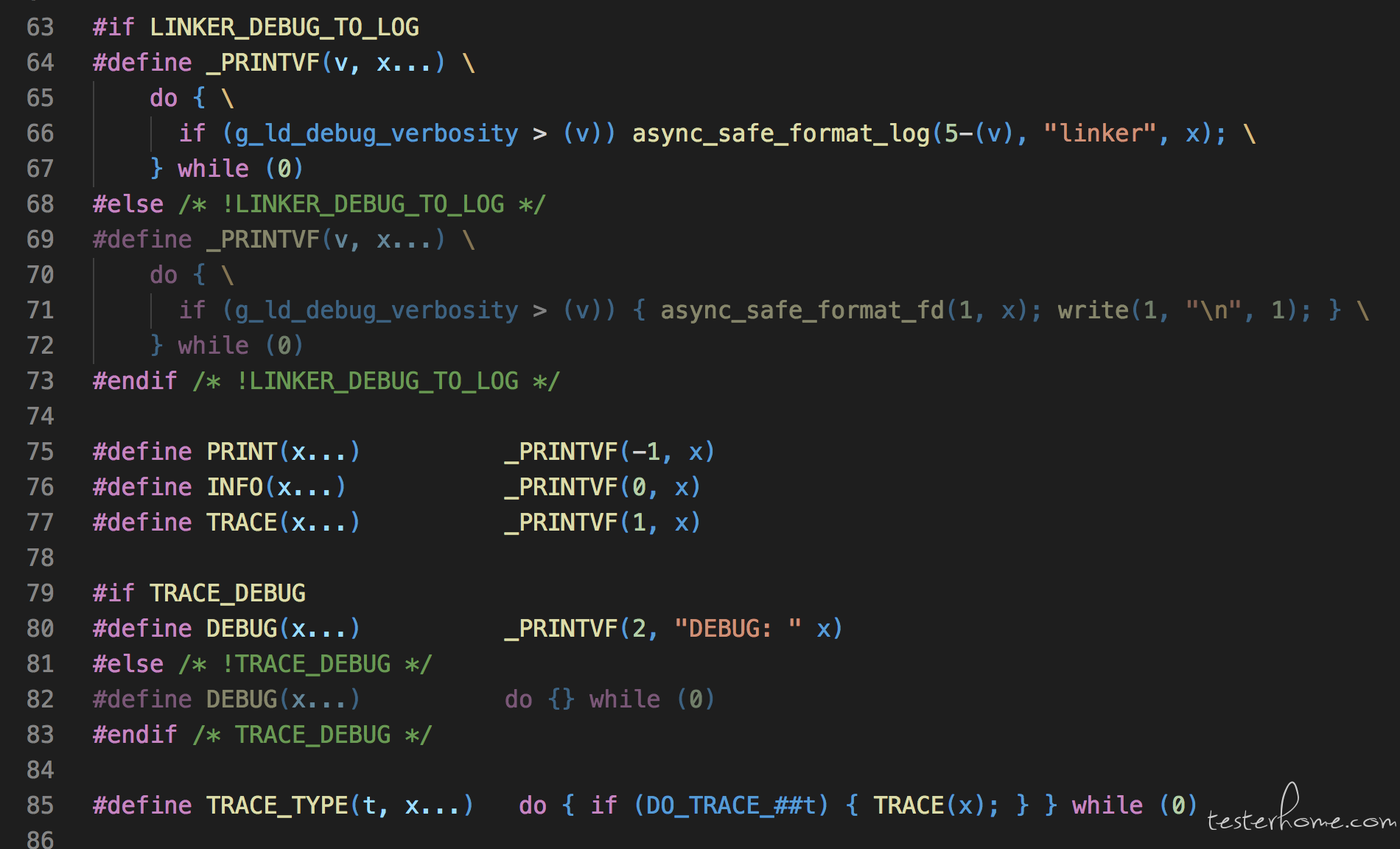
2. 移动文件或重命名文件,只是改变文件名,不影响 inode 号码。
3. 打开一个文件以后,系统就以 inode 号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从 inode 号码得知文件名。
第 3 点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过 inode 号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的 inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的 inode 则被回收。
但是问题就出在这里,如果替换文件使用的是 cp 这样的操作,会导致原来的 so 文件截断,然后重新写入数据,但是 inode 并没有更新号,磁盘与内存中的信息出现不一致,这种情况在 linux 中很常见,比如这篇文章就进行了分析:
cp new.so old.so,文件的 inode 号没有改变,dentry 找到是新的 so,但是 cp 过程中会把老的 so 截断为 0,这时程序再次进行加载的时候,如果需要的文件偏移大于新的 so 的地址范围会生成 buserror 导致程序 core 掉,或者由于全局符号表没有更新,动态库依赖的外部函数无法解析,会产生 sigsegv 从而导致程序 core 掉,当然也有一定的可能性程序继续执行,但是十分危险。
- mv new.so old.so,文件的 inode 号会发生改变,但老的 so 的 inode 号依旧存在,这时程序必须停止重启服务才能继续使用新的 so,否则程序继续执行,使用的还是老的 so,所以程序不会 core 掉,就像我们在第二部分删除掉 log 文件,而依然能用 lsof 命令看到一样。
还有更深入的解释:
Linux 由于 Demand
Paging 机制的关系,必须确保正在运行中的程序镜像(注意,并非文件本身)不被意外修改,因此内核在启动程序后会绑定 内存页
到这个 so 的 inode,而一旦此 inode 文件被 open 函数 O_TRUNC 掉,则 kernel 会把 so 文件对应在虚存的页清空,这样当运行到 so 里面的代码时,因为物理内存中不再有实际的数据(仅存在于虚存空间内),会产生一次缺页中断。Kernel 从 so 文件中 copy 一份到内存中去,a) 但是这时的全局符号表并没有经过解析,当调用到时就产生 segment
fault , b) 如果需要的文件偏移大于新的 so 的地址范围,就会产生 bus error。
那么问题基本清晰了。我们在回去看看微视的代码,这里下载了 so 之后直接 unzip 到原来的路径,并没有先进行 rm 操作。
更近一步,我们自己写个 demo 测试下刚才的问题(2 个按钮,一个加载指定 so,一个调用 so 中的 native 方法):
代码不能再简单了:
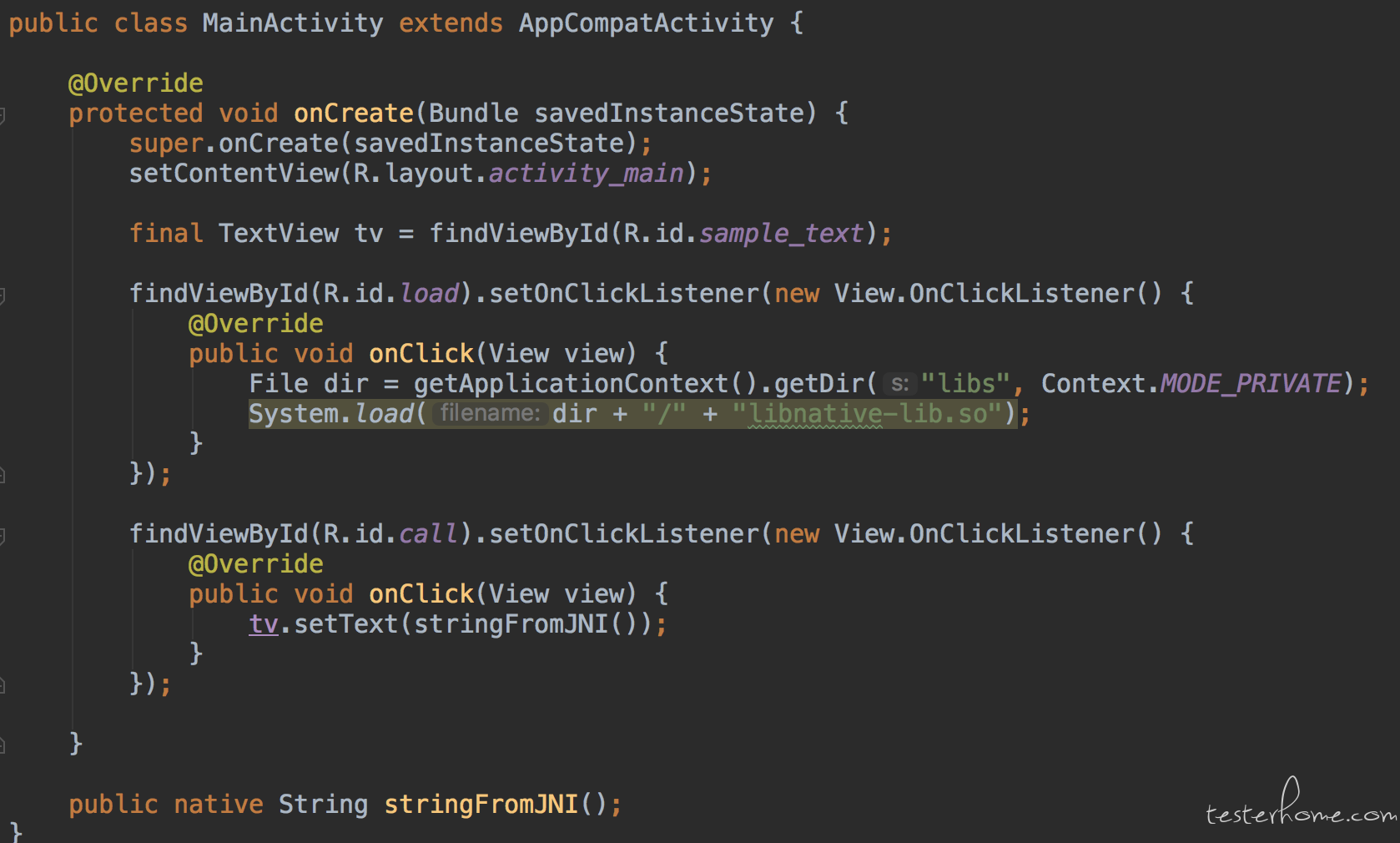
正常加载 so 然后执行 native 方法都是 ok 的,使用 rm+mv 替换或者 adb push 替换也都是 ok 的,最后再按照错误的方法操作,步骤为:
启动 app,点击加载 so;
通过 cp 命令替换 so;
点击执行 native 方法;

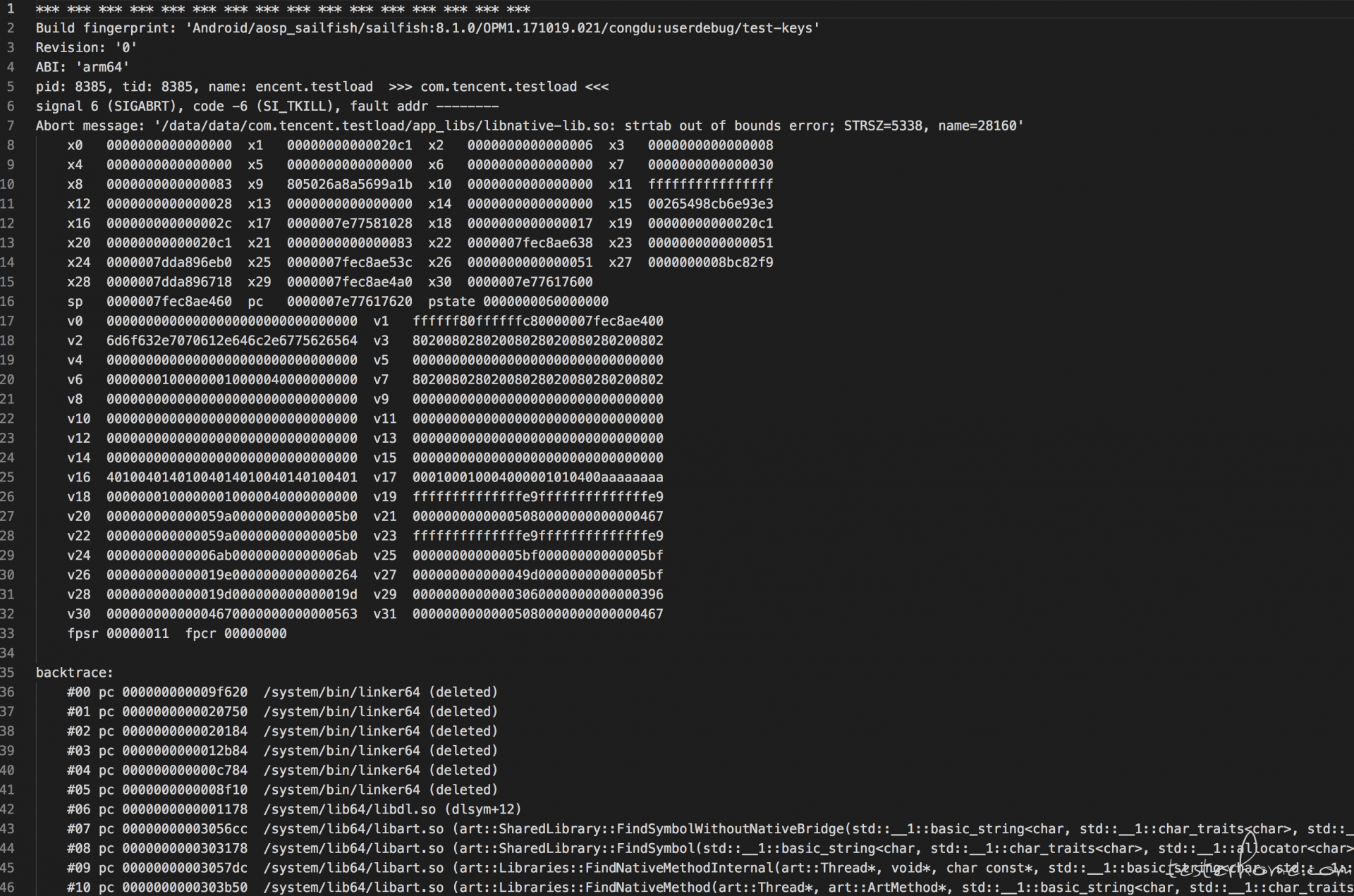
结果确实是 crash 了:
日志如下,是不是很最开始的日志信息一样呢:
到此,我们有两种解决办法:
如果 so 有升级,先不加载旧的 so,等新的 so 下载完成之后再加载;
可以先加载旧的 so,但是下载了新的 so 之后,要删除旧的 so,再进行替换。
引文参考:
https://www.cnblogs.com/cnland/archive/2013/03/19/2969337.html
https://www.cnblogs.com/cnland/archive/2013/03/20/2970537.html
http://www.ruanyifeng.com/blog/2011/12/inode.html
目前,“自动化兼容测试” 提供云端自动化兼容服务,提交云端百台真机,并行测试。快速发现游戏/应用兼容性和性能问题,覆盖安卓主流机型。
点击:https://wetest.qq.com/product/auto-compatibility-testing 即可体验。
如果使用当中有任何疑问,欢迎联系腾讯 WeTest 企业 QQ:2852350015
