本人现在要对一个 API 网关的性能做测试,在搭建环境的时候,遇上了一个让我百思不得其解的问题,想请各位帮忙看一下,能解决当然万分感激,当然能提供解决思路的也十分感谢。
发压机: 云服务器 8 核 8G
被测机: 云服务器 2 核 4G
测试工具:基于 python 的 locust。以下的测试我用 docker 容器起的 locust 和 非 docker 容器起的 locust 都尝试过了,数据还是一样的。
locust 运行模式 都是 master-slave
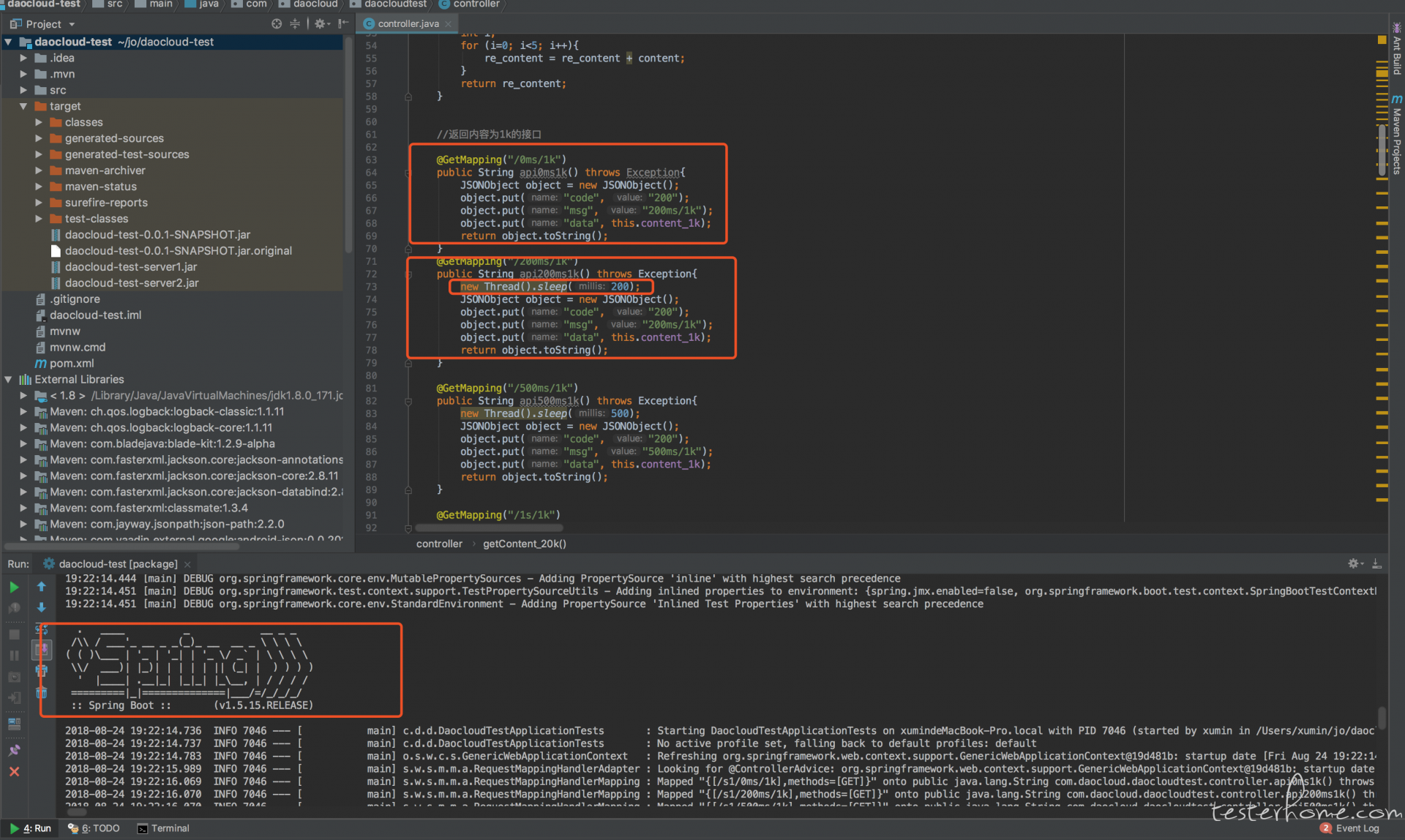
测试接口 1:
http://.../s/0ms/1k
测试接口 2:
http://.../s/200ms/1k
为了方便的调试,用 java 的 spring boot 框架写的测试接口。
测试接口 1 和测试接口 2 之间的不同就是接口测试 2,我加了 200ms 的延迟,测试接口没有任何业务逻辑运算。
测试接口 1:http://.../s/0ms/1k
slave 数:1 个
并发用户:1000 个
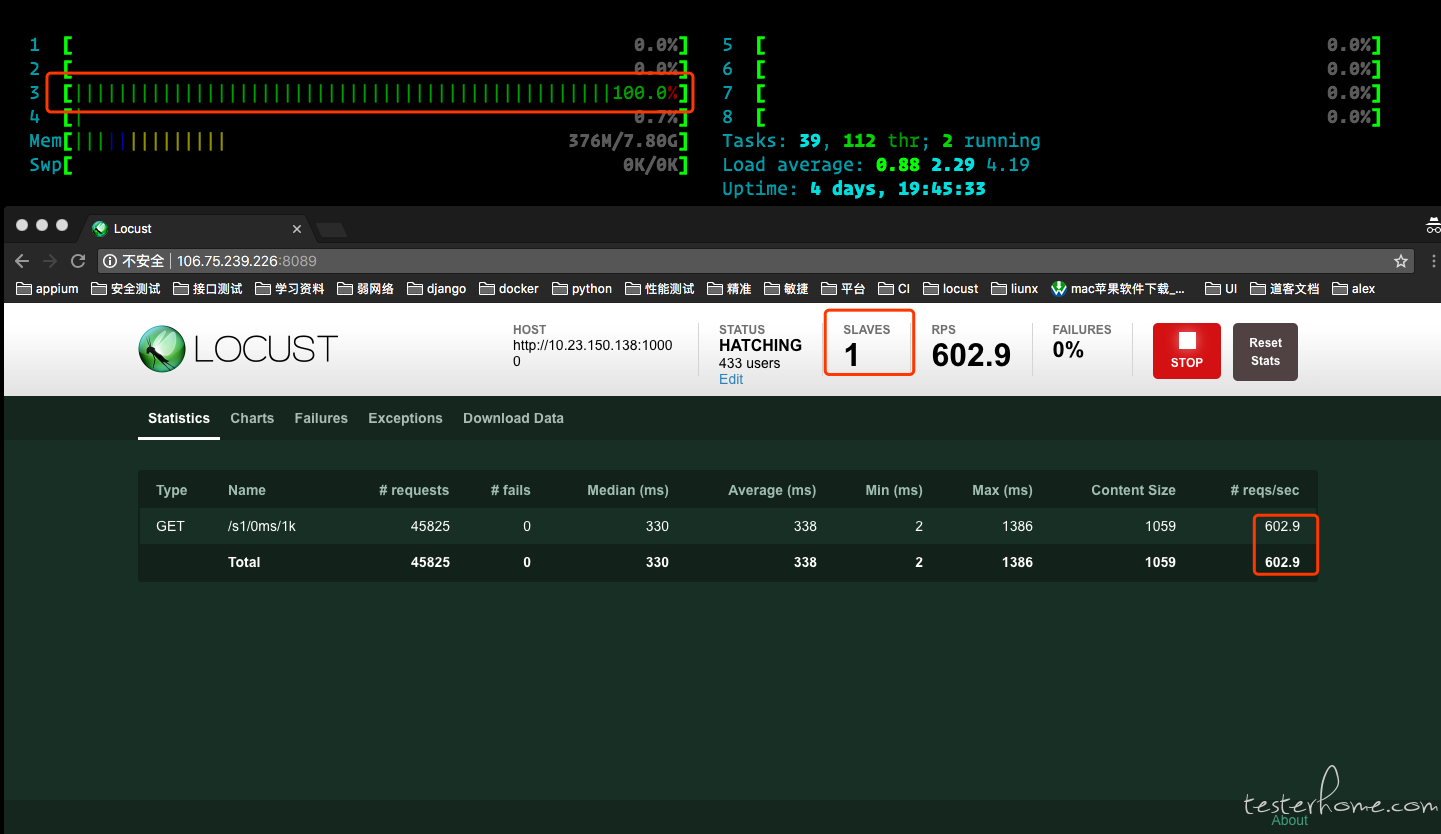
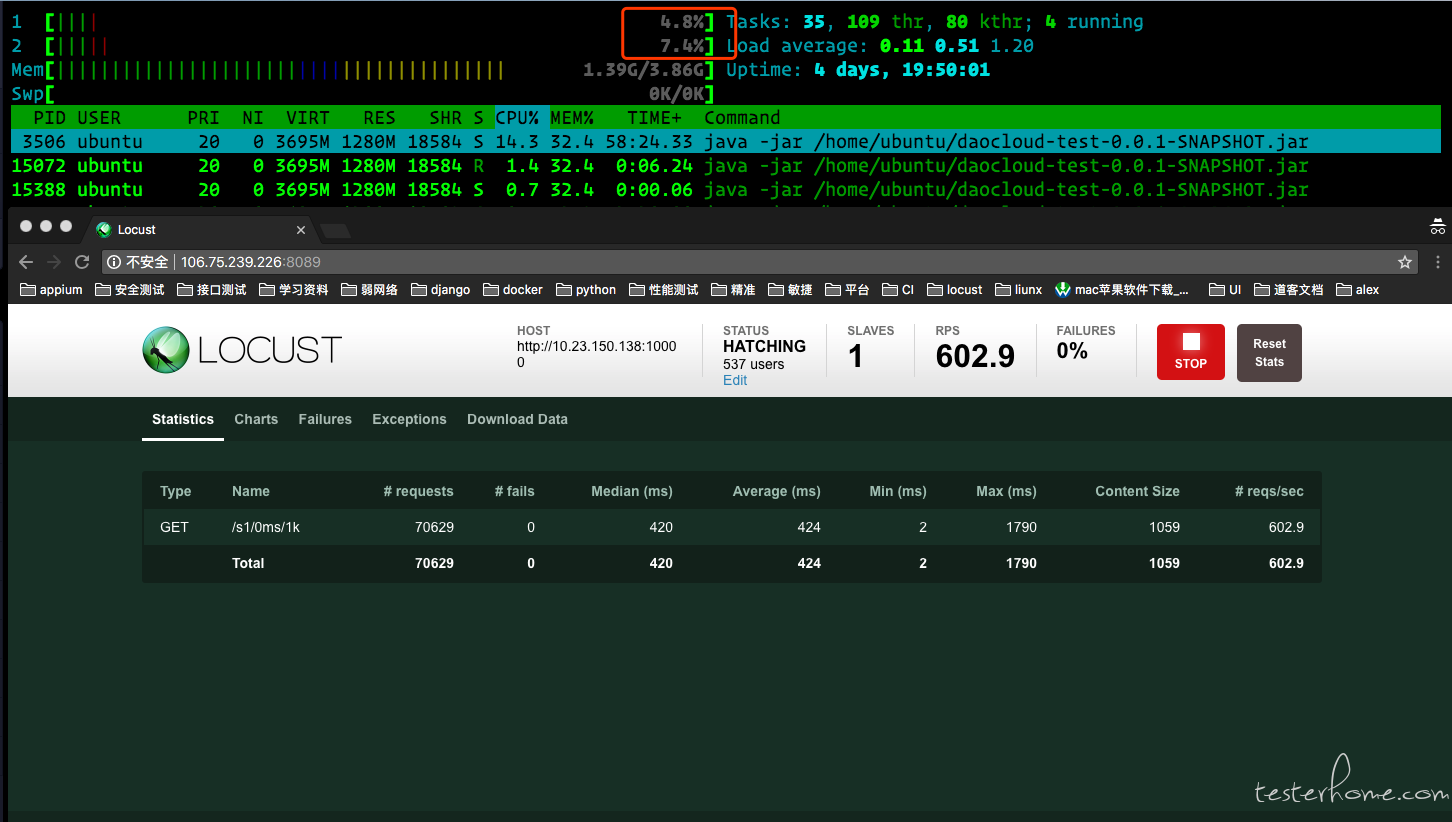
这组数据我得到的信息是一个 slave 的时候,1000 个用户并发下得到的 TPS 是 600 左右,并且是在 linux 服务器上一核满负荷的情况下。被测服务器的 cpu 使用率属于正常。
测试接口 1:http://.../s/0ms/1k
slave 数:8 个
并发用户:1000 个
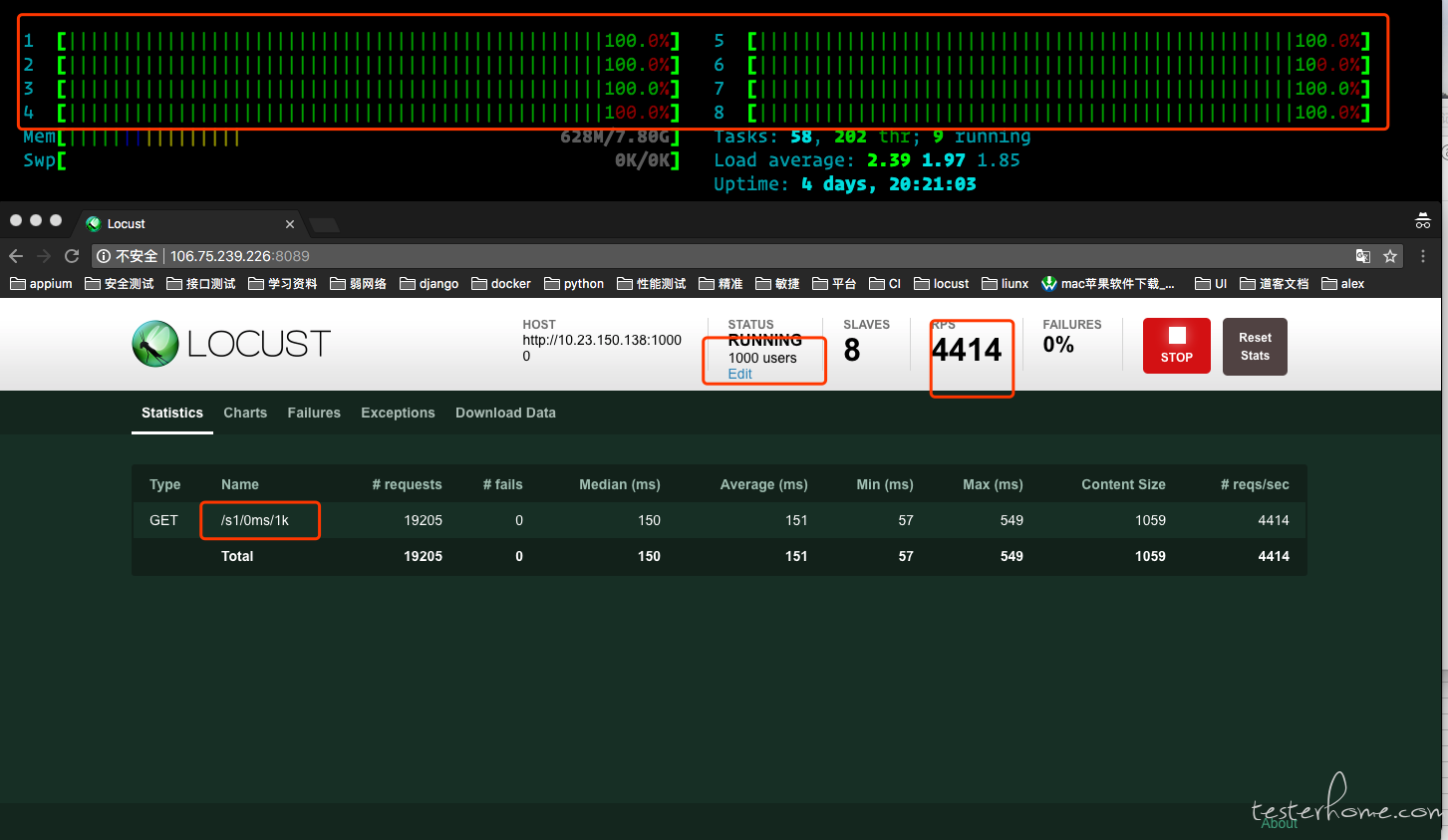
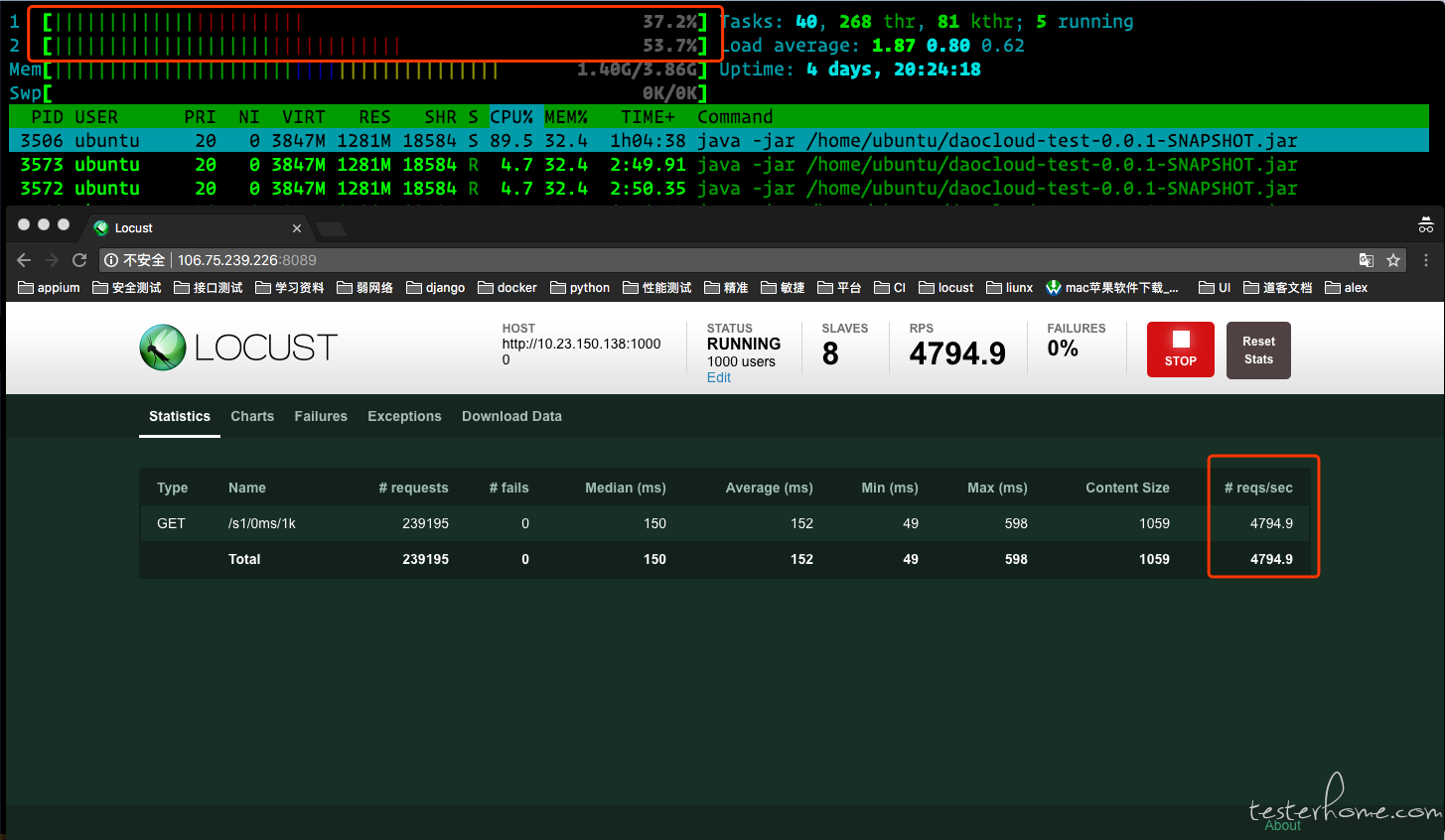
当我把 slave 加到 8 个的时候,1000 个用户并发下,TPS 差不多要 4400 左右了,发压机现在是 8 核满负荷运行。被测服务器的 cpu 使用也从前面的低使用率上升到了快平均 cpu 使用率接近 45% 了。我想说的是 1slave 的极限 tps 数 * slave 的数量 应该等于整体的 tps 的数量。以前测的都是开发写的接口,所以这条规则我是用到现在的。
测试接口 2:http://.../s/200ms/1k
slave 数: 1 个
并发用户: 1000 个

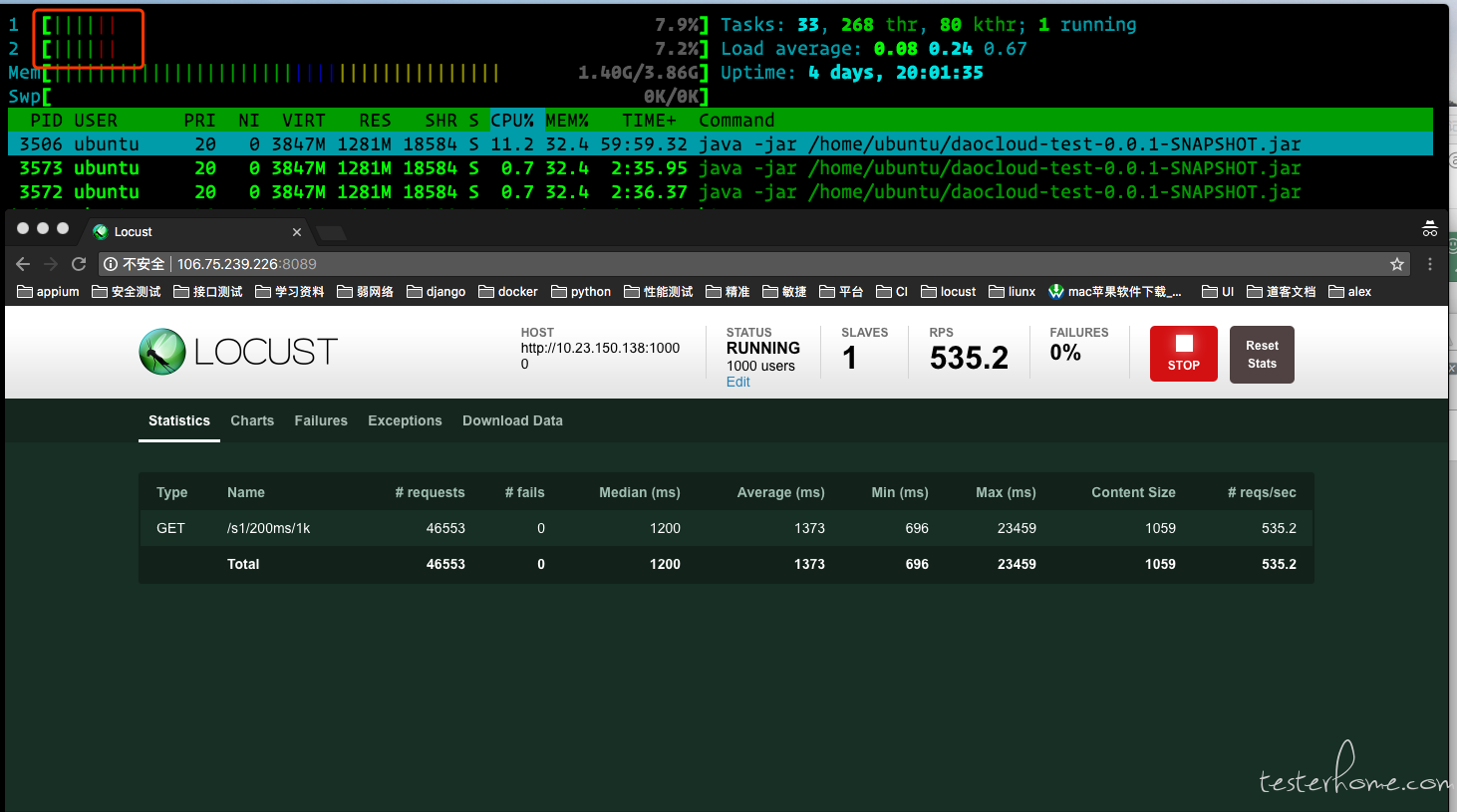
测试接口 2,因为有 200ms 的延迟,所以 1 个 slave 进行请求的时候,我得到的 500 左右 tps。其他情况也正常。
测试接口 2:http://.../s/200ms/1k
slave 数: 8 个
并发用户: 1000 个
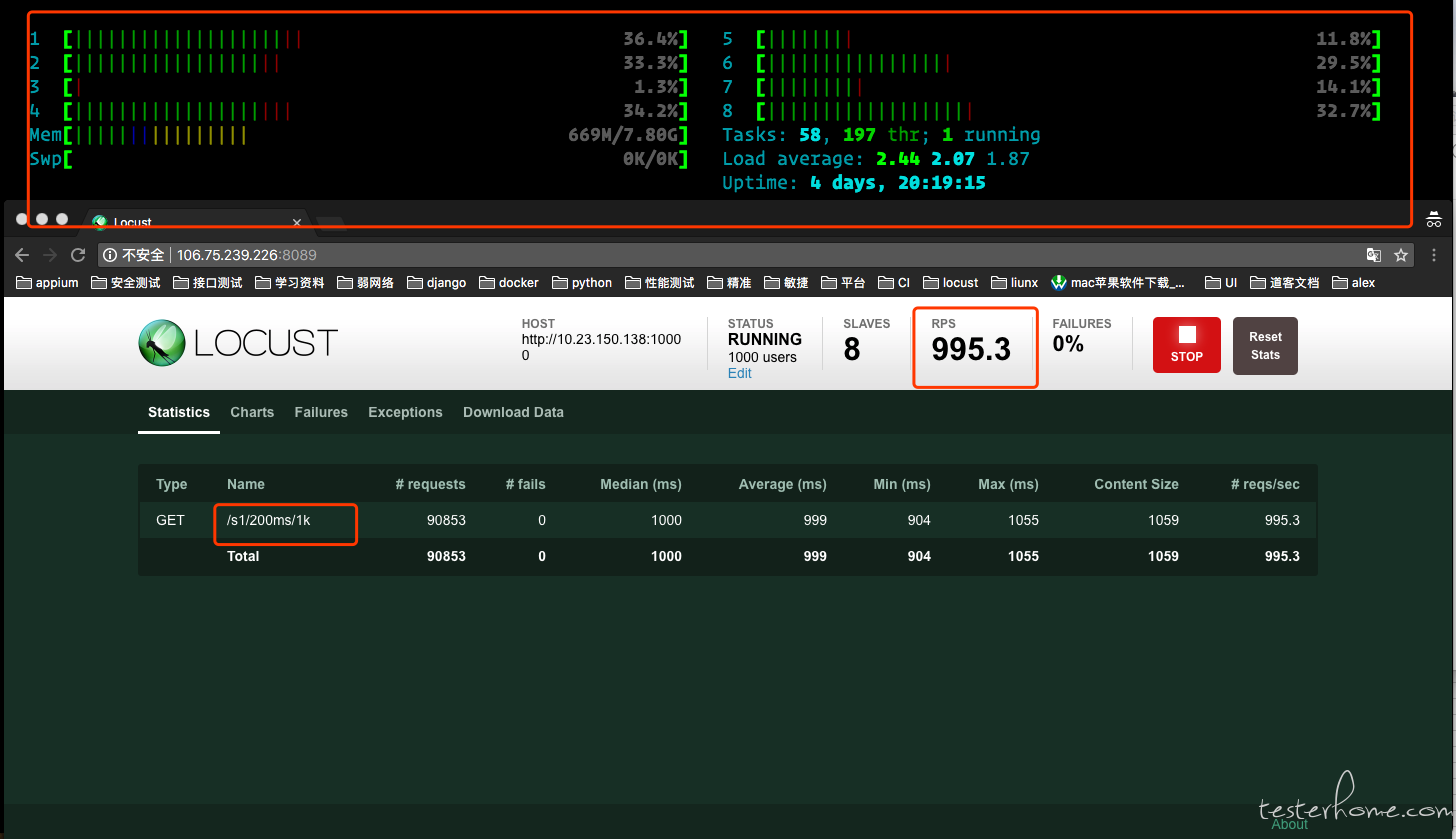
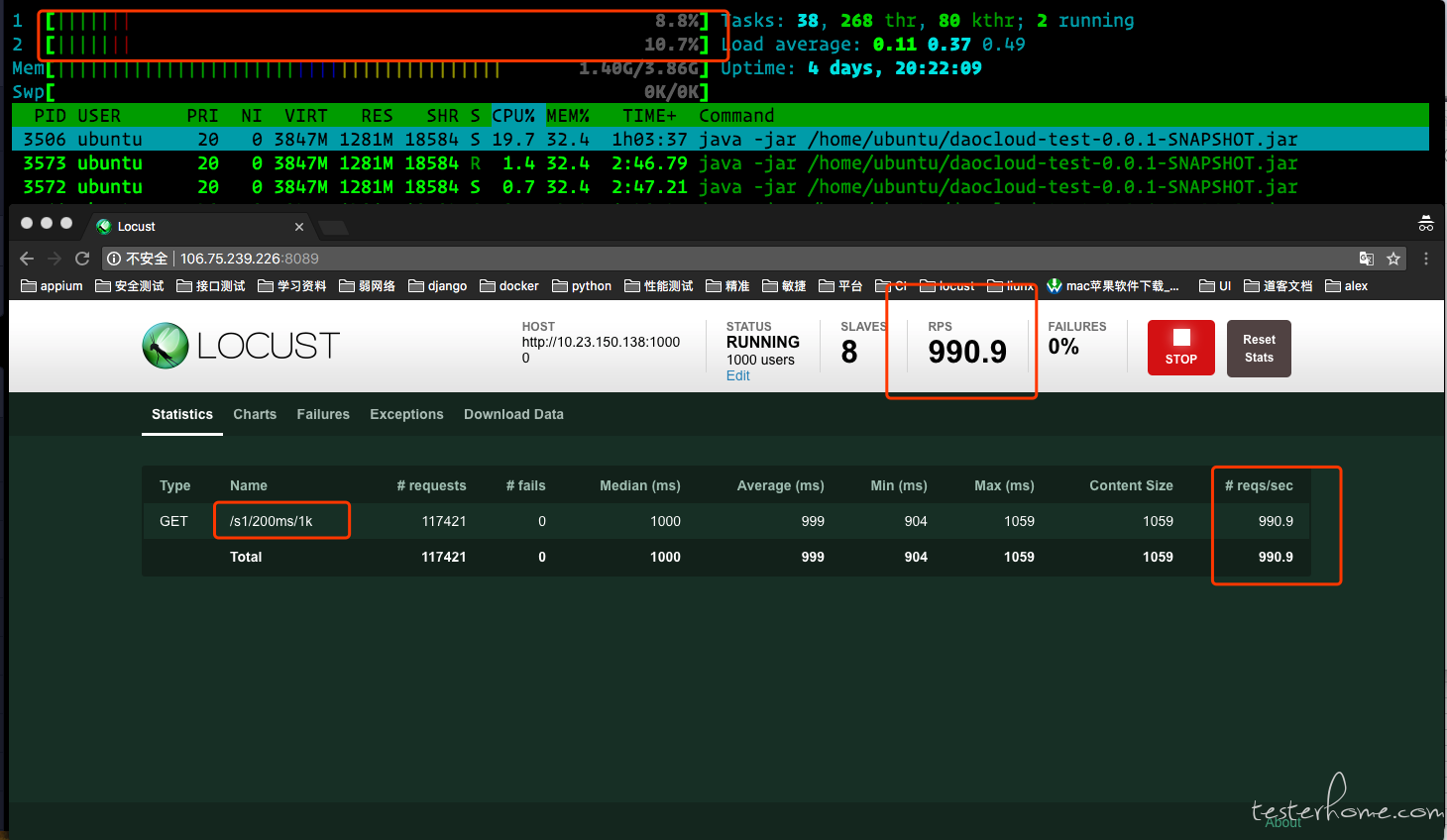
当我把 slave 加到 8 个的时候,问题出现了,就好像突然遇上了什么限制,TPS 在 1000 的时候就到了一个稳定值,如果按照我以往的经验,一个 slave 的 TPS 在 500,那么 8 个 slave 的 TPS 应该在 4000 左右才是比较正确的。在看一下负压机的 cpu,竟然不是满负荷的,十分悠闲的分在 8 个 cpu 上,再看被测服务器这里的 cpu 和 一个 slave 进行压力测试数据差不多。
1.刚开始的时候我以为是因为我用容器启动 locust 的关系,然后在云主机上直接安装 locust,发现结果没有改变。所以就排除了容器的问题。
2.本来我是没有做测试接口 1 的,因为我觉得测试接口 2 的数据和我想的不一样,会不会应该延迟的关系,所以我才加了测试接口 1,但是加了以后,我发现测试接口 1 的数据和我预想的是一致的,那么在 locust 的使用上我没有出问题。
3.那么问题是出在哪里,还是我对压力测的概念没有理解透彻?
4.我现在在尝试用 jmeter 进行测试,这个非 GUI 的还真的要稍微花点时间,不知道在我能够在 liunx 上熟练使用 jmeter 的时候,是否有人能帮忙指点一下。
